This week, besides IEA AIE 2022, I am also participating to the SMARTDSC 2022 conference(5th international conference on Smart Technologies in Data Science and Communication) as general co-chair and keynote speaker. I will give a brief report about this conference in this post.
What is SMART-DSC?
SMARTDSC is a conference organized by the KL (deemed to be) University in India in collaboration with several international researchers. This is the fifth edition of the conference. The conference focuses on data science, communication and smart technologies and the quality is good. This year, over 150 papers have been received and less than 20% have been accepted for oral presentation, which makes this conference competitive. The proceedings are also published by Springer, which ensures indexing and a good visibility for papers.
The accepted papers are from oven ten different states in India and also from 5 other countries. There is also an excellent line-up of eight keynote speakers for the conference from various countries including Turkey, Egypt, China, France, and Malaysia.
The first keynote talk was by Shumaila Javaid affliated to Shanghai Research Institute for Intelligent Autonomous Systems in China. The talk was about medical sensors and their integration for pervasive healthcare. This was a quite interesting topic has it has the real-life applications that may change lives.
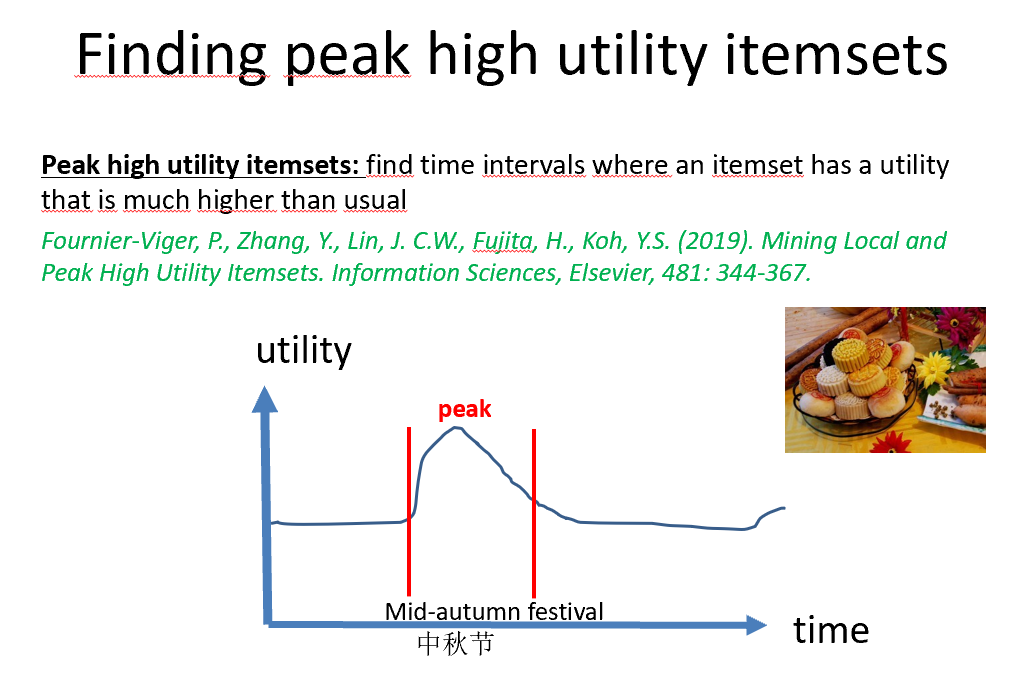
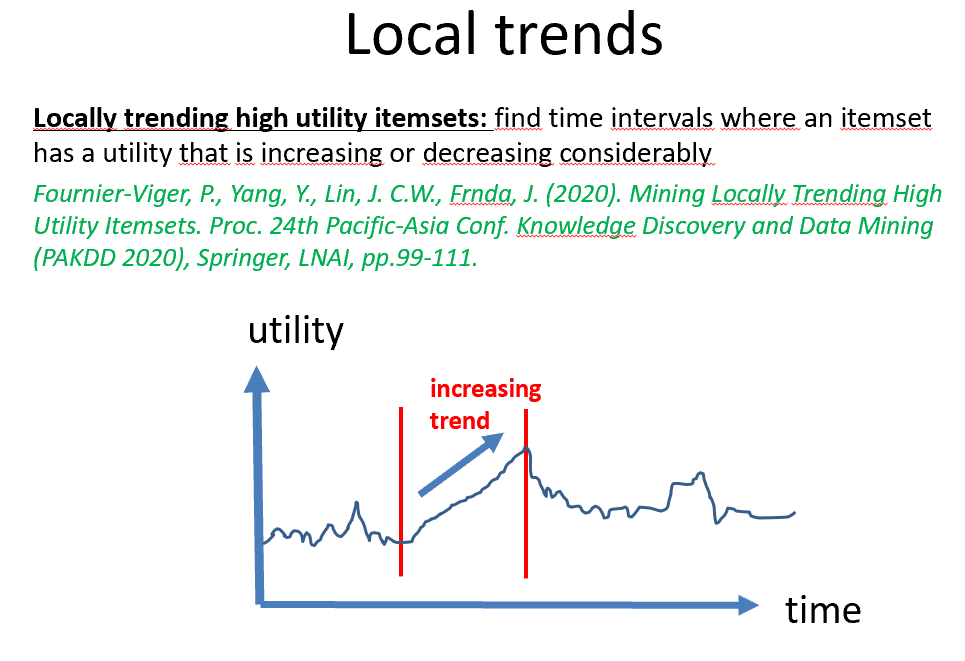
Then, I gave a keynote talk about the automatic discovery of interesting patterns in data. Here are a few slides of my talk where I introduced various topics.
There was then several paper presentations followed by other keynote talks. I will try to add more details about these presentations later, in this blog post. The SMART DSC conference is held for three days. I am attending the conference at different moments during these three days as I have to participate to two conferences at the same time (SMARTDSC 2022 and IEA AIE 2022).
On overall, SMARTDSC 2022 is an interesting conference. It is especially great for participants in India for the convenience of travelling but it is also international with several participants, and keynote speakers from abroad. I am happy to participate to it.
This week, I am attending the 35th International Conference on Industrial, Engineering & Other Applications of Applied Intelligent Systems conference (IEA AIE 2022). I will give a brief report about the conference
Program
This year, the conference received 127 paper submissions, from which 65 have been accepted as full papers, and 14 as short papers. All the papers have been reviewed by at least 3 members from the program committee.
Opening ceremony
The IEA AIE 2022 conference was held in Japan in hybrid mode. I think the majority of attendants were online but there was still many people attending in person. On the first day, there was the opening ceremony. The conference was introduced including the program and other aspects.
Paper presentations
There was several paper presentations, covering many different topics such as: industrial applications, health informatics, optimization, video and image processing, natural language processing, agent and group-based systems, pattern recognition, security.
Here is screenshots from some presentations, that I have attended.
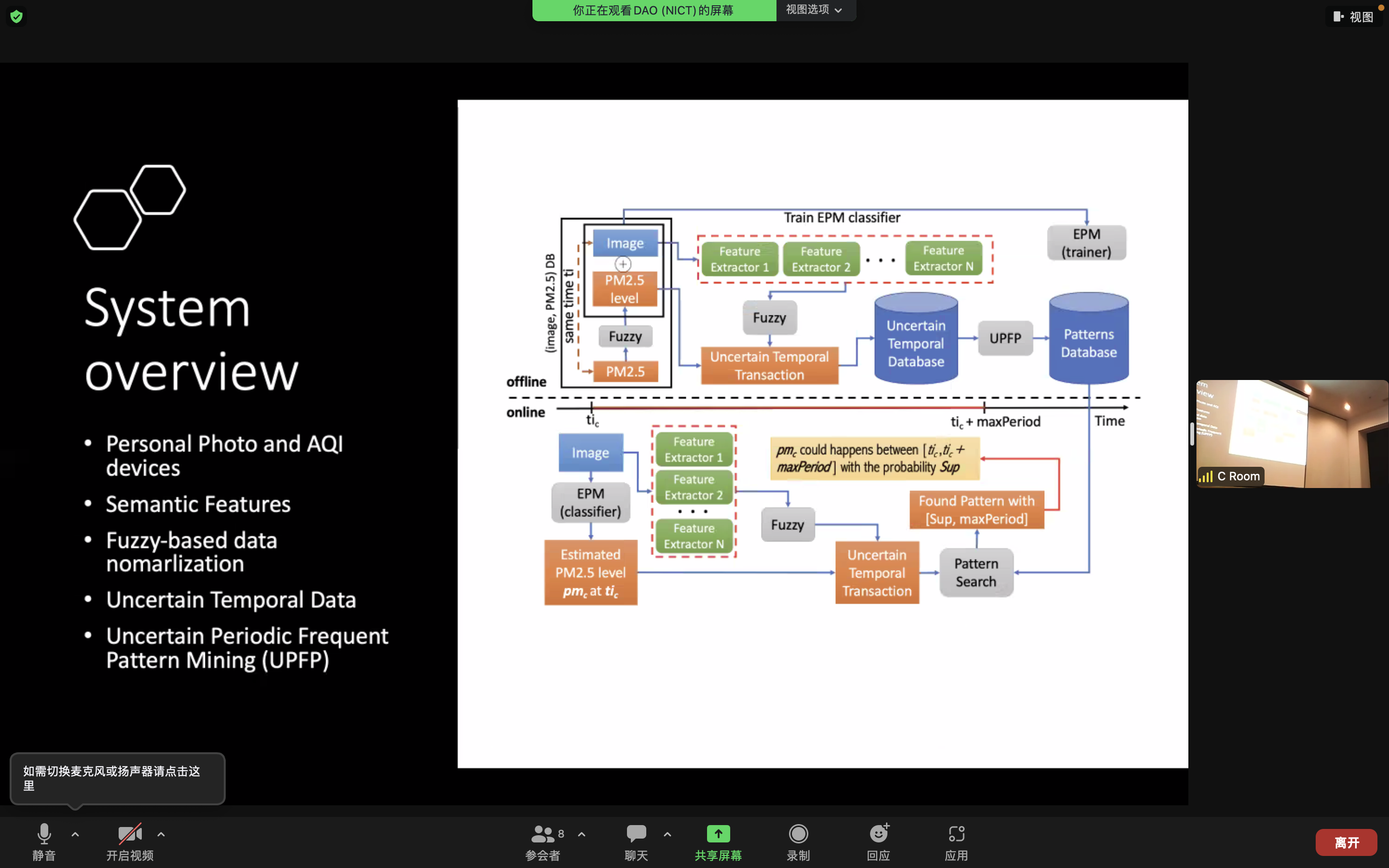
This is a paper about air pollution, which use image processing combined with a periodic pattern mining algorithm to obtain good detection:
Below is a paper from my collaborators aboutparallelhigh utility itemset miningbased on Spark. In that paper some good results are obtained where a parallel version of EFIM and d2HUP provides some good speed-up (up to 20 times) over the sequential versions of those algorithms for mining high utility itemsets.
There was also many other papers that I have listened too. I will not report on all of them.
Keynote talks
At IEA AIE 2022, there was two keynote talks. The first keynote was by Prof. Tao Wu from Shanghai University of Medicine & Health Sciences about health informatics.
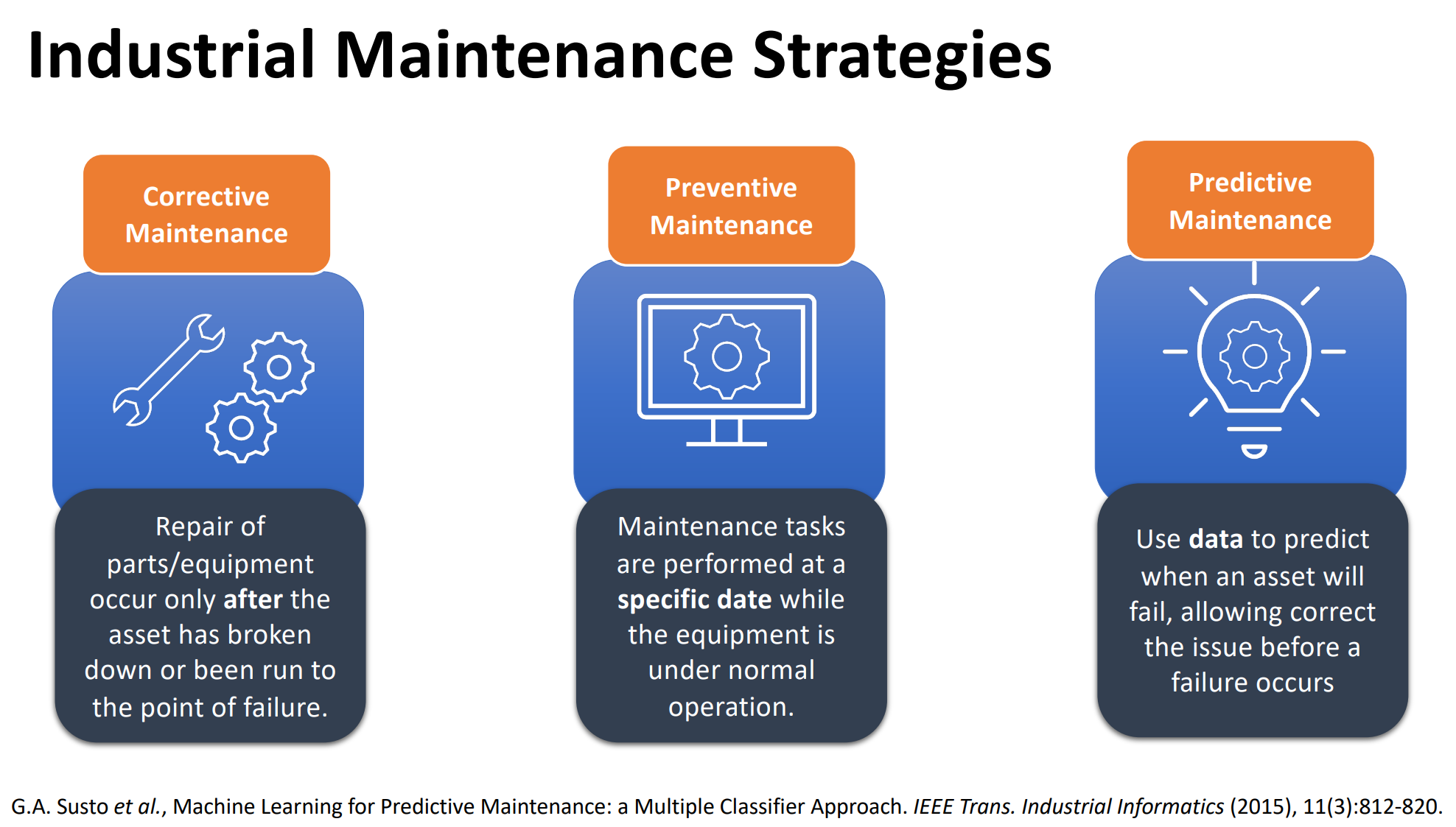
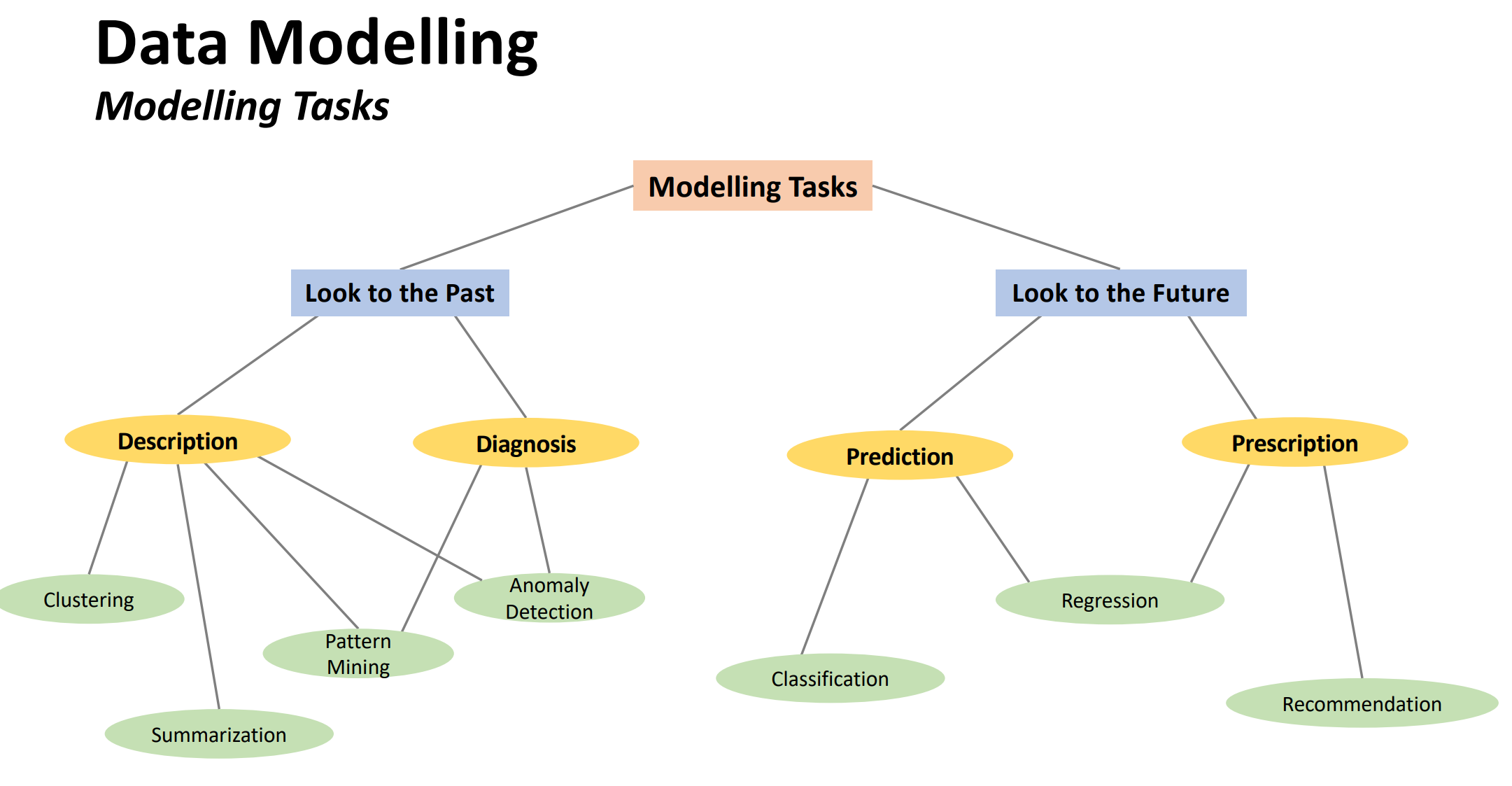
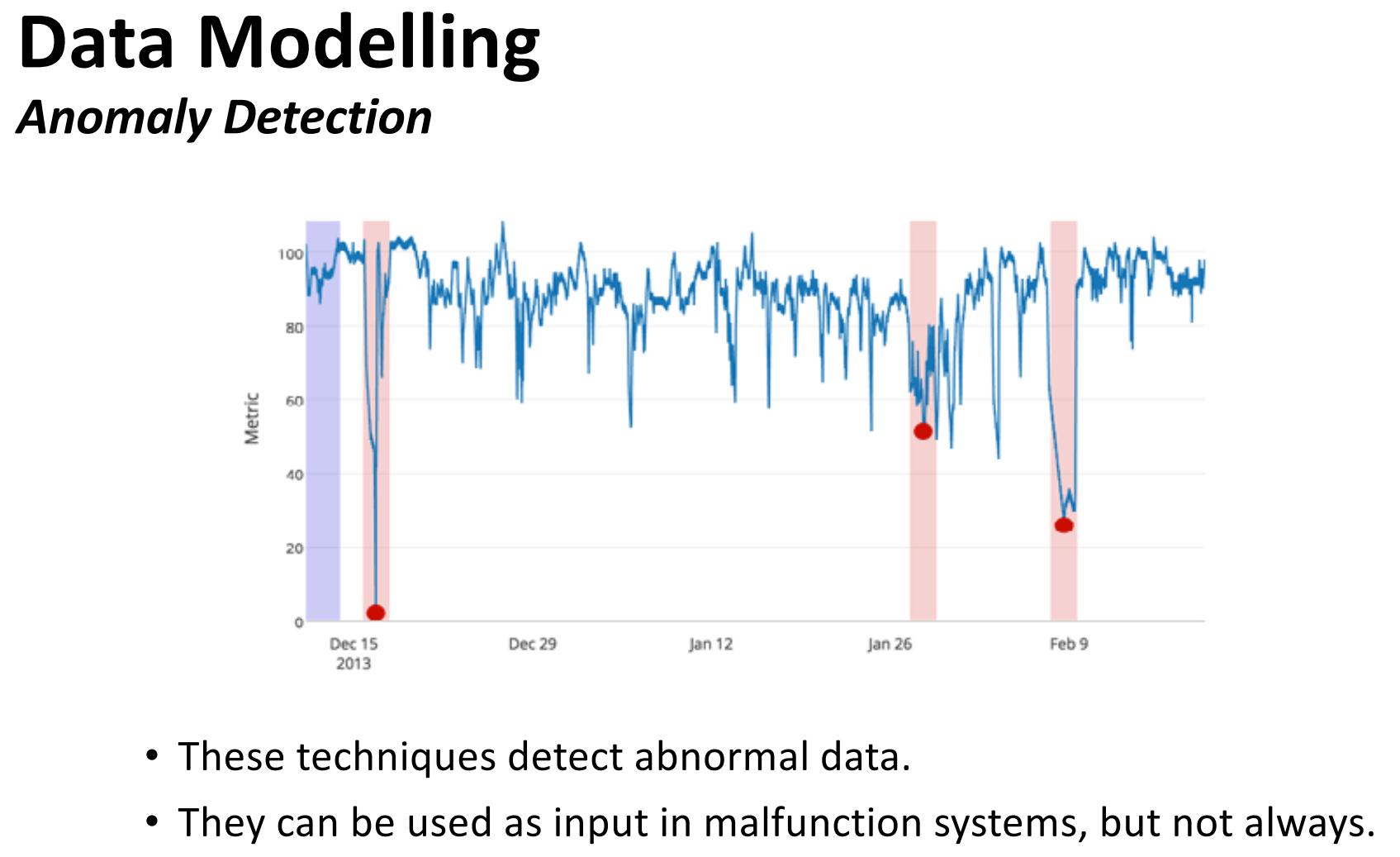
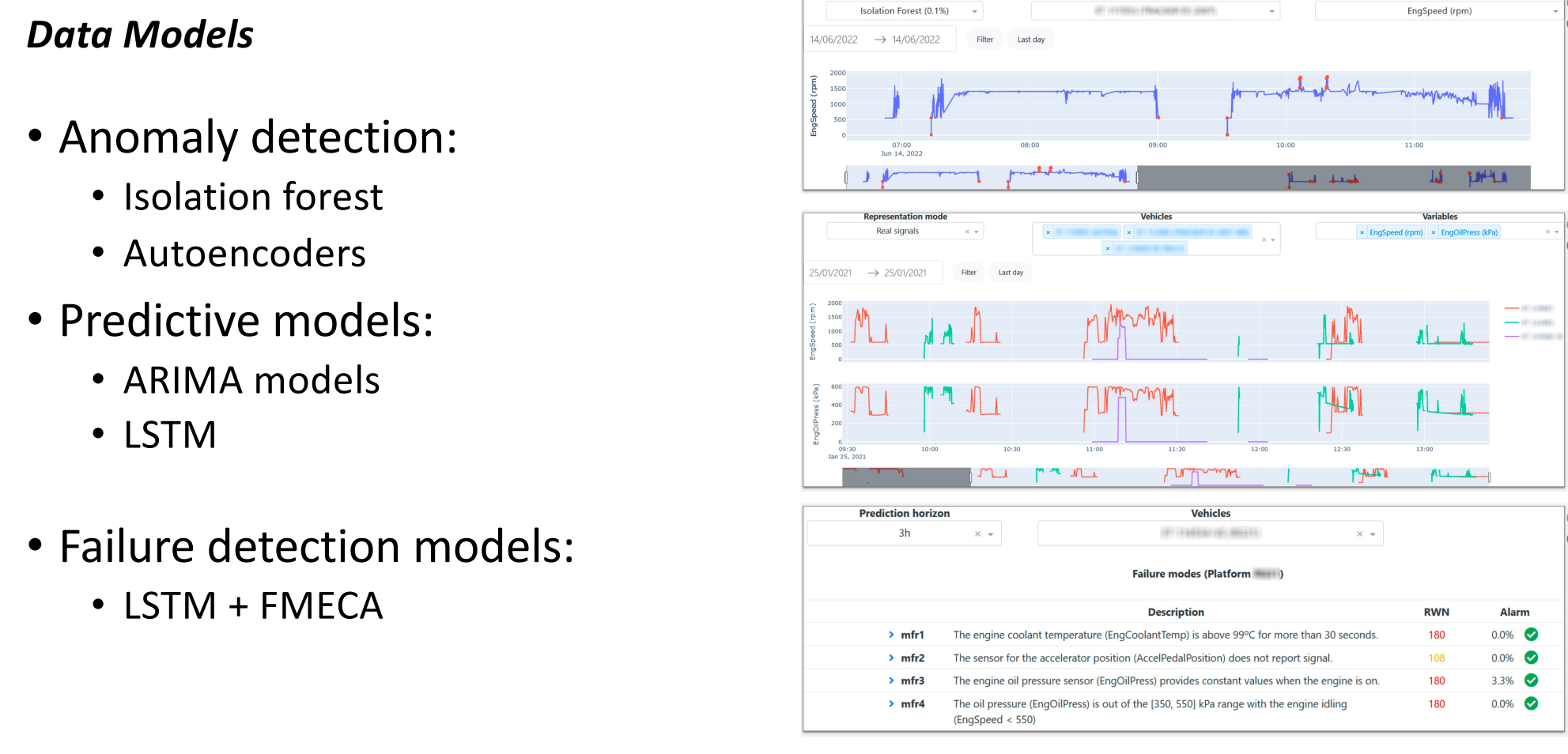
The second keynote talk was by Prof. Sebastian Ventura from University of Cordoba, Spain about Improving Predictive Maintenance with Advanced Machine Learning. He talked about how to build models and systems to prevent failure from happening in industrial systems by doing maintenance in advance (predictive maintenance – PdM). He explained that various techniques can be used such as for outlier detection and classification. Prof. Ventura told that he is doing a project for the maintenance of military vehicles. Following the talk, there was a good discussion with conference participants. Prof. Ventura explained that building simple models is good but it is not necessarily the most important. A complex model can be acceptable if it is explainable. In fact, he said that it is more important to have explainable models because in real-applications, models often need to be verified by domain experts. Here are a few slides from that talk about the introduction:
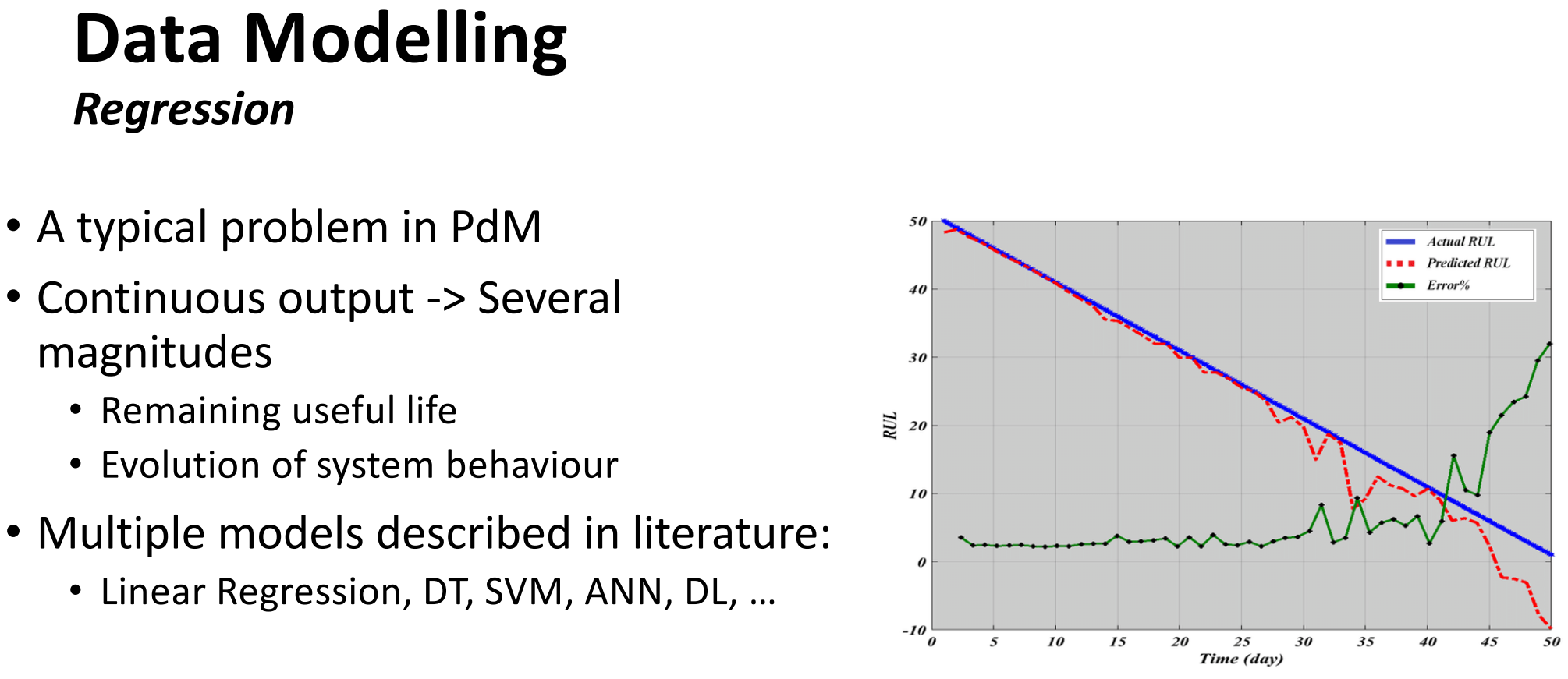
Here are some slides about potential data mining techniques that can be used:
And here are some techniques that have been used in the specific project for predictive maintenance of vehicles:
Here are some challenges and open problems and the conclusion from the talk:
If you are interested by this topic, you may also check the survey paper published recently by Prof. Ventura:
A. Esteban, A Zafra & S. Ventura. Data Mining in Predictive Maintenance Systems. WIREs DMKD. https://doi.org/10.1002/widm.1471
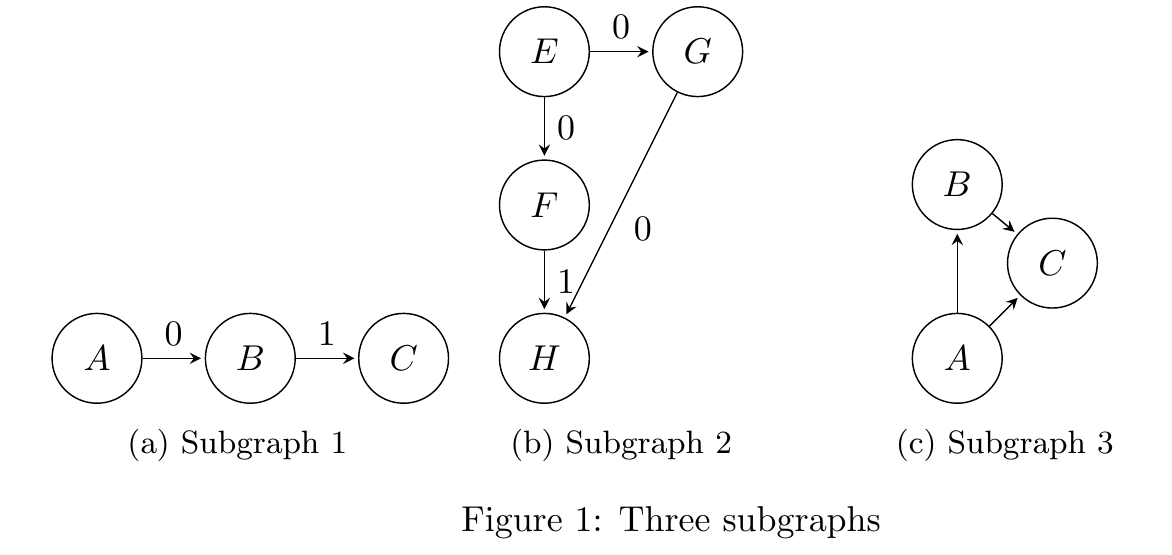
Today, I will give an example of how to draw a figure containing three subgraphs that appear side by side in Latex using the TIKZ library, and where each subgraph has a caption. This can be useful when writing research papers, where we want to discuss different types of subgraphs.
I have made two new videos to explain interesting topics about pattern mining. The first video is an introduction to sequential rule mining, while the second video explains in more details how the CMRules algorithm for sequential rule mining works!
If you want to try these algorithms, you can check the SPMF open-source software, which offers fast implementations of these algorithms.
Hope you will enjoy the videos. I will make more videos about pattern mining soon. By the way, you can also check my website about The Pattern Mining course. It gives videos and slides for a free online course on pattern mining. It explains all the main topics about pattern mining and is good for students who are starting to do research in this area. But this course is in beta version, which means that I am still updating it. More videos and content will be added over time.
Hi all, this is to let you know that I have made another video to explain some interesting pattern mining topics. This time, I will talk about periodic pattern mining.
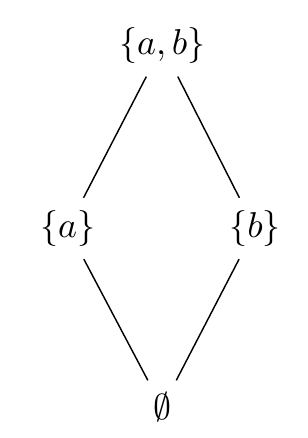
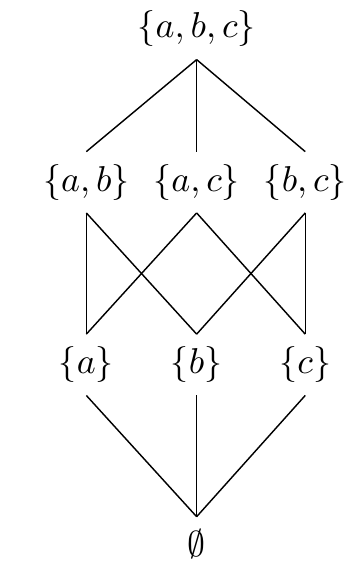
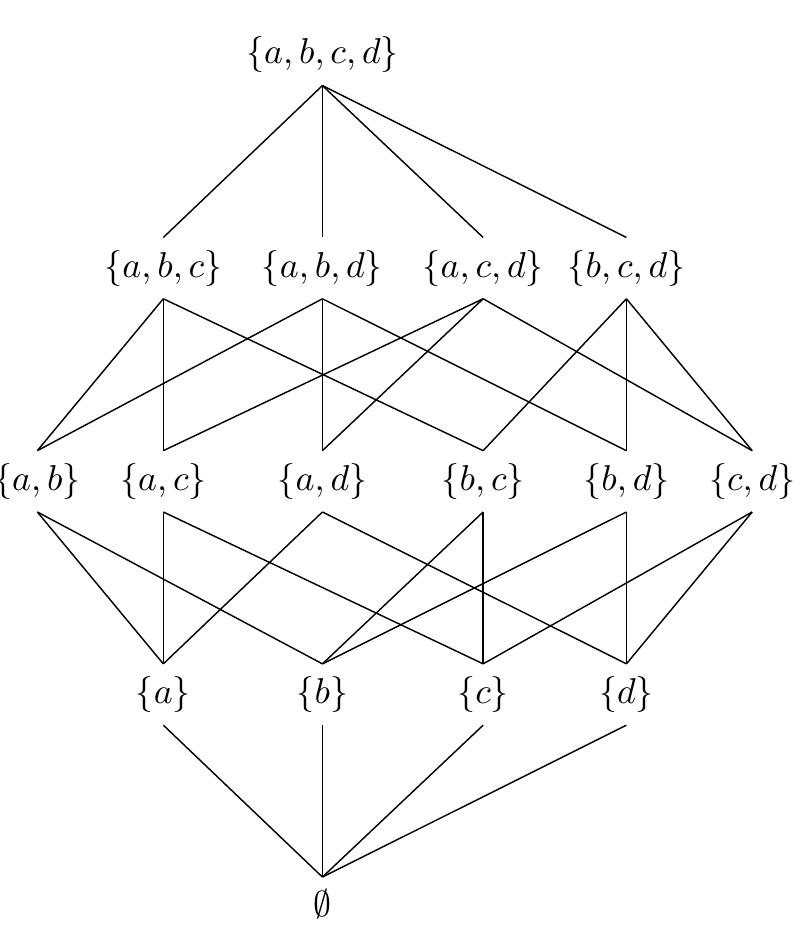
Today, I will show how to draw the powerset of a set using Latex and TIKZ, to produce some nice figures that can be used in paper written using Latex. The code that is shown below is adapted from code from StackOverflow.
First, we will draw the powerset of the set {a,b} as a Hasse diagram:
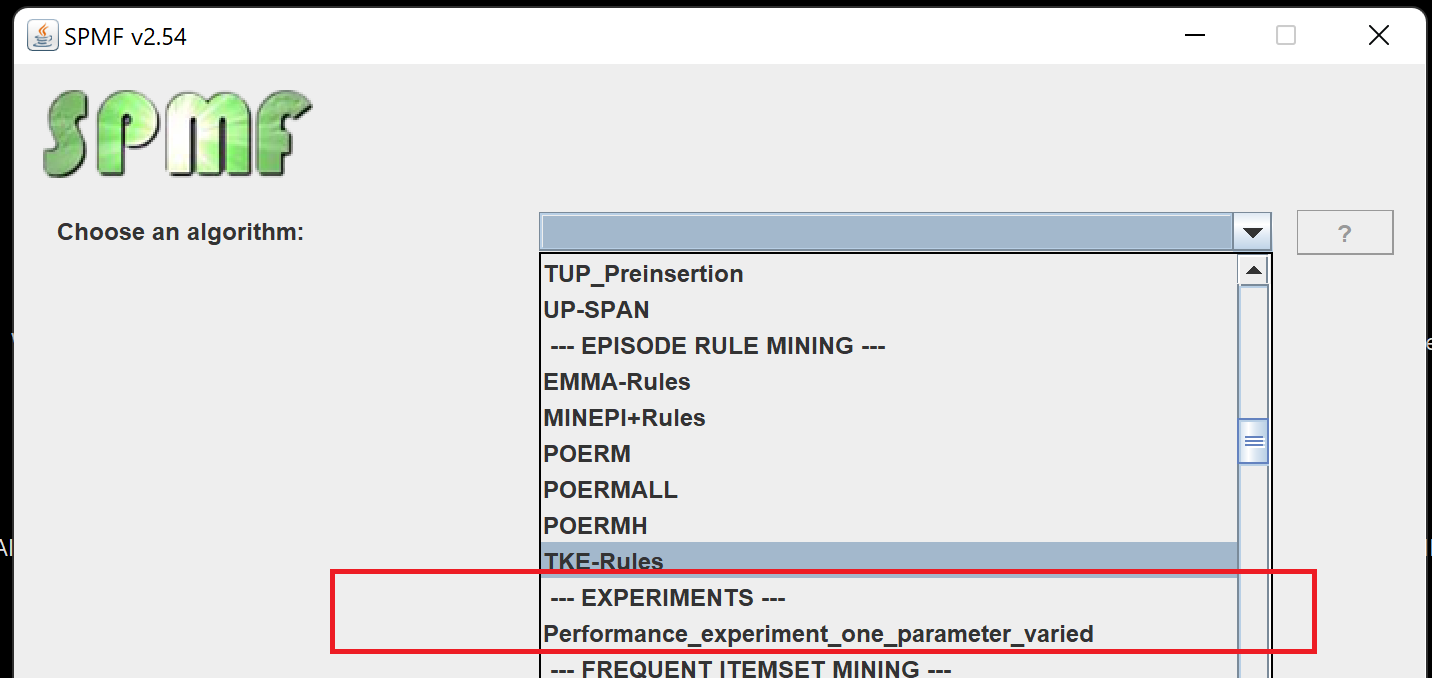
Today, I am happy to announce a cool new feature in SPMF 2.54, which is a tool to automatically run performance experiments to compare several algorithms when a parameter is varied. This is a useful feature to compare algorithms when writing a research paper. The new tool to do performance experiments let you choose oneor more algorithms, indicate default parameter values and that a parameter must be varied. A time-out can be specified to avoid running algorithms for too long. Besides, each algorithm execution is done in a separate Java virtual machine to ensure that the comparison is always fair (e.g. memory will not accumulate from previous algorithm executions). When running the tool, the results can also be easily exported to Excel and Latex to generate charts for research papers. This tool can save a lot of time for performing experimental comparisons of algorithms!
Briefly the main way to use the new tool is to run the graphical user interface of SPMF and then select the tool from the list of algorithms:
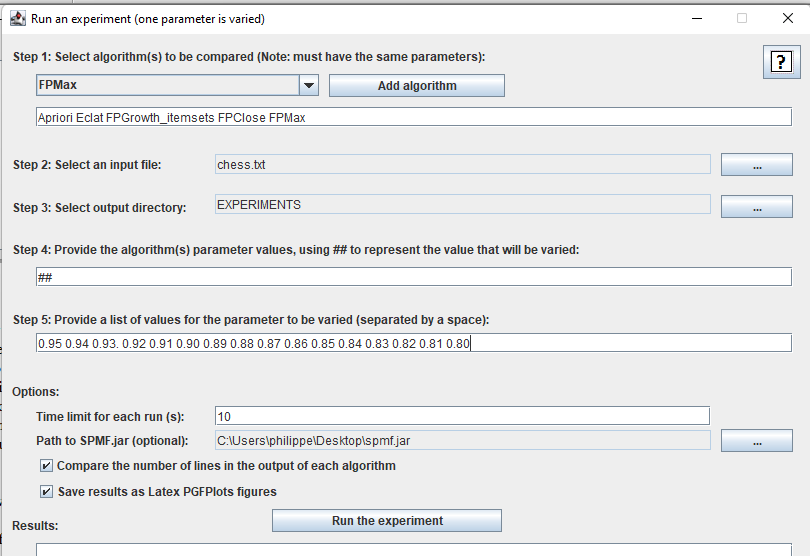
This will open-up a new window, where we can configure the parameters for running the experiment:
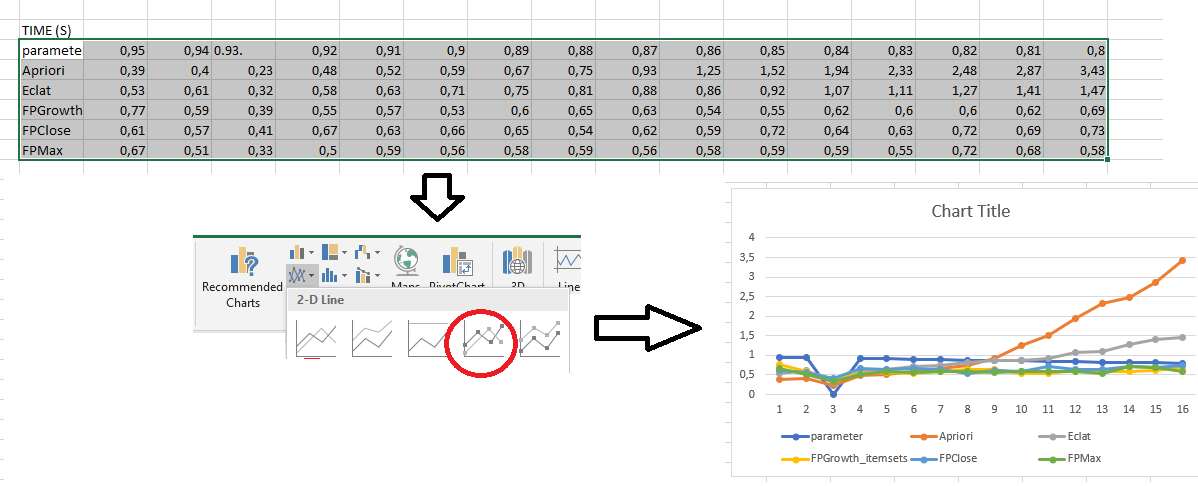
For example, without going into details, here we choose five algorithms called Apriori, Eclat, FPGrowth_itemsets, FPClose and FPMax. We also select an input file called Chess.text on which we will run the algorithms and we select a directory called EXPERIMENTS to save all the results that will be generated to files. We also say that the algorithms have one parameter which will be varied (We indicate that a parameter is varied using a special code ##), and the parameter will be varied from 0.95 to 0.80. We say that the time limit for each execution will be 10 seconds, and we select the option that we want not only to compare time and memory usage but also the number of patterns (lines in the output) and save all results as Latex figures, as well.
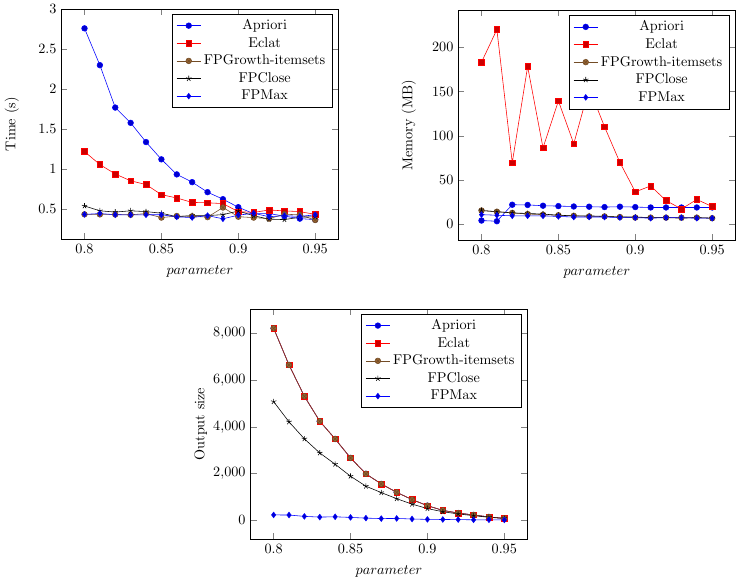
Then we click “Run the experiments” to run the experiments. We will get summarized results as shown below for execution time, memory and number of patterns:
This was generated in just a few seconds. If we would have run these experiments by hand, it would have took us a lot more time. Now, after we have these results, since they are tab-separated we can directly import them into Excel to generate charts:
Besides, since we selected the option to generate PGFPlots figures for Latex, SPMF will have generated latex documents as output, that we can directly compile to use in Latex documents:
I will continue improving this tool to generate experiments in the next few weeks. In particular, I am now working on an option to generate scalability experiments as well, which should be released soon. Also, I will modify the tool to make it easier to compare algorithms from SPMF with algorithms that are not in SPMF.
Today, I will talk about signs that show that something is wrong or suspicious with some researchers based on their Google Scholar profiles. I will talk about this because I have recently received many CVs and while browsing Google Scholar, and I found some very suspicious profiles.
Normal Google scholar profiles
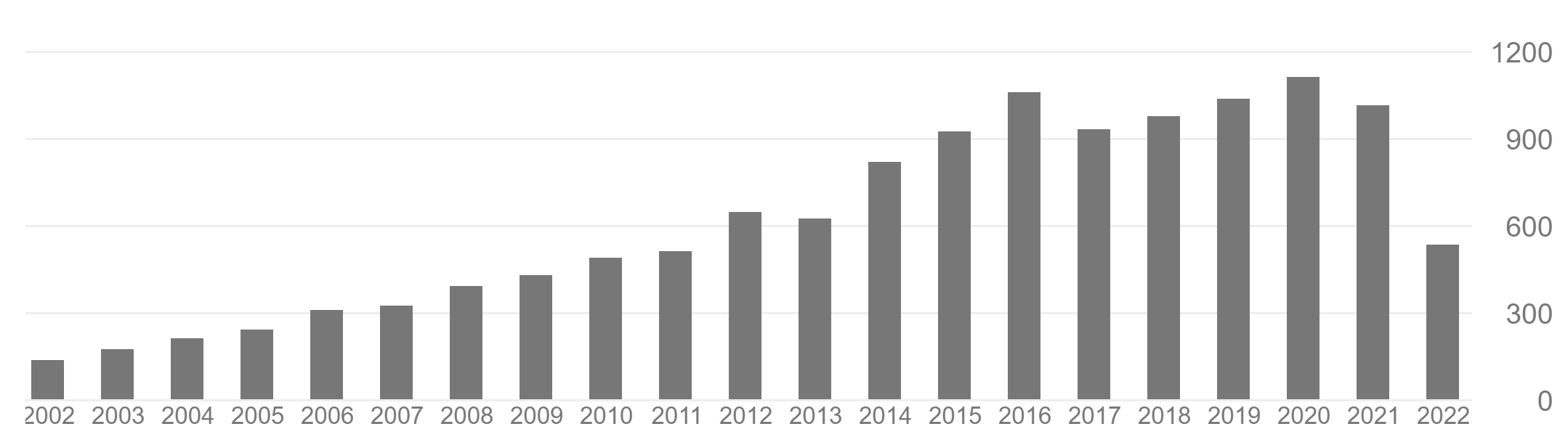
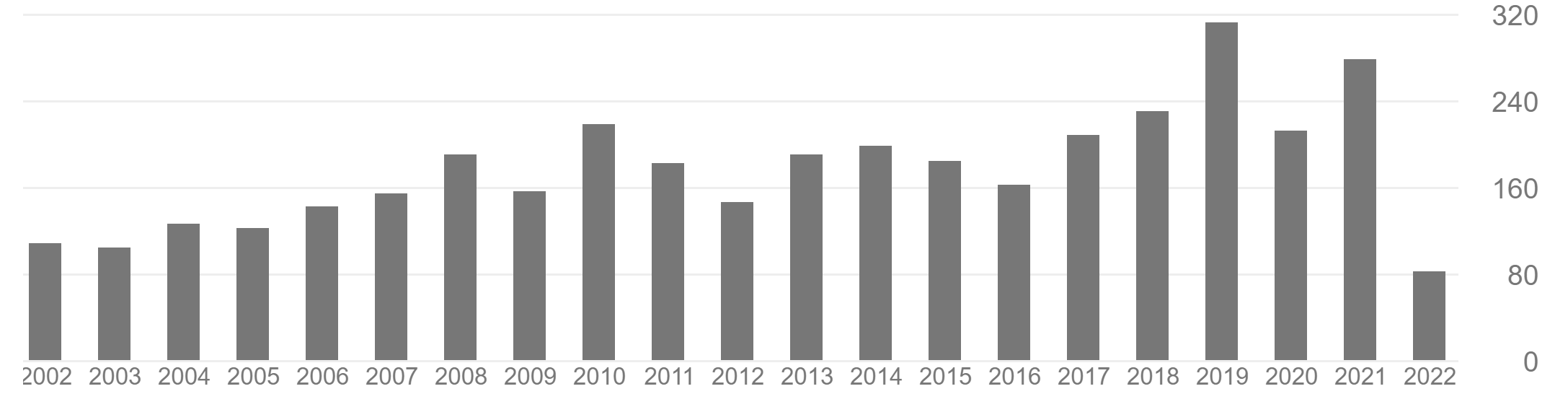
First, lets talk about what is a normal Google Scholar profile. Generally, a normal Google scholar profile shows a slow increase in the number of citations over time, and sometimes it will stagnates or decrease towards the end of the career of a researcher. Here are some examples of normal profiles:
And sometimes, the citations are increasing a bit more quickly due to some great contributions, but still the curve is quite smooth:
Abnormal Google scholar profiles (case 1)
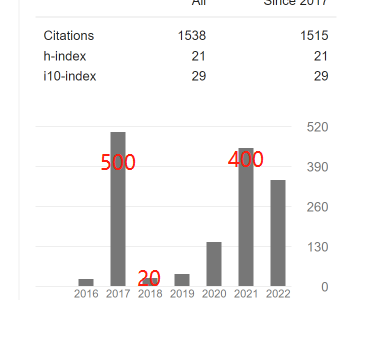
Now let’s talk about some abnormal Google Scholar profiles. Let’s look at a first example:
What is wrong? Well, here we have a researcher that received 500 citations in 2017, and then about 20 citations in 2018, before going back to 400 citations per year in 2021. I don’t see any logical explanation that would explain a big drop like this other than citation manipulation. Even if we assume that the person did not publish any papers for two years, papers should still continue to be cited. So it seems to indicate that there is some manipulation of the citations that has been done.
Abnormal Google scholar profiles (case 2)
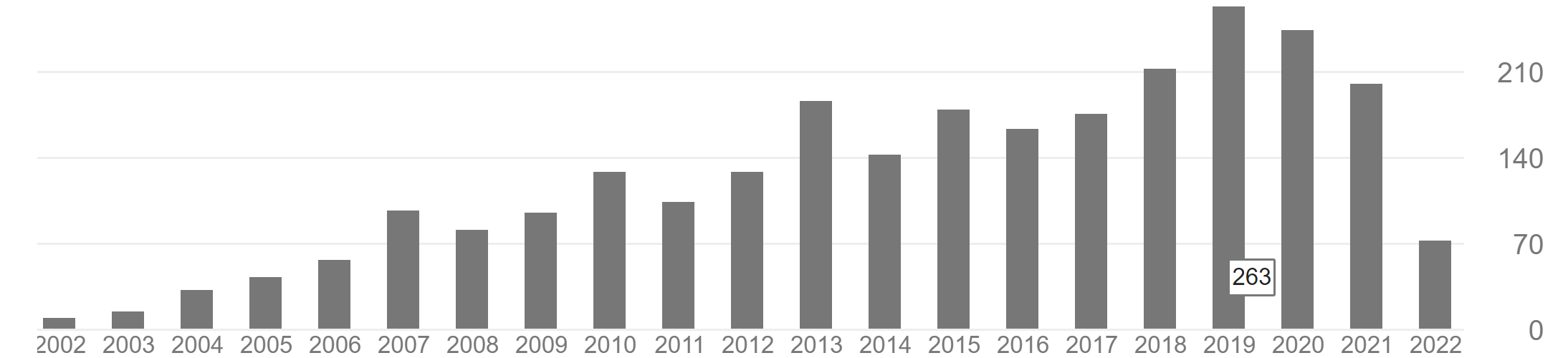
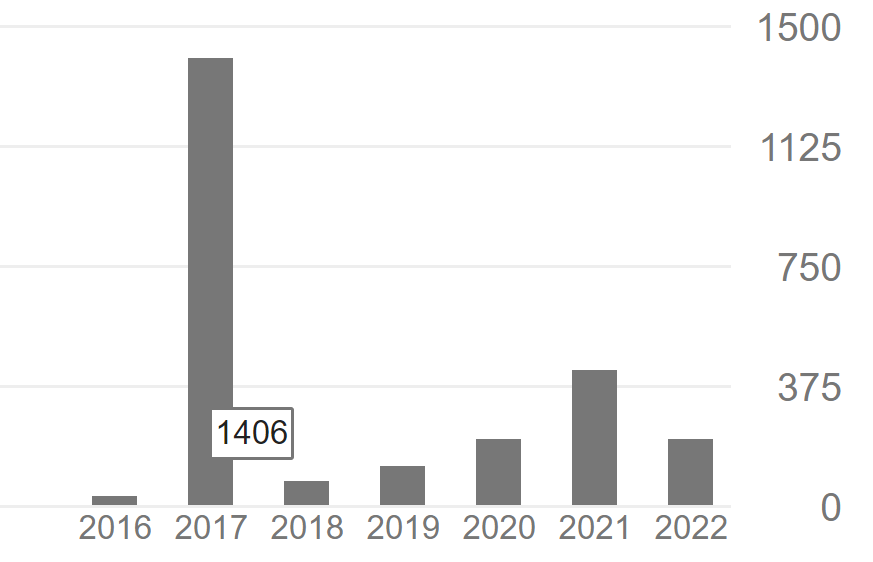
A third example is even more suspicious. Someone who had 1406 citations in 2017 suddenly dropped to 84 citations per year in 2018. I cannot see any reason for this other than some manipulations of citations.
Abnormal Google scholar profiles (case 3)
And here is another suspicious Google Scholar profiles.
Again, why would citations drop like this and never go up again? There is no logical reason other than citation manipulation.
Conclusion
I wrote this blog post to show that the Google Scholar Profiles can reveal many interesting things. Some profiles clearly show something abnormal. I will not write any names. That is not the point of this blog post. My goal is just to show that suspicious behavior can be easily detected in Google Scholar.
For young researcher, my advice is to always be honest, focus on the quality of papers rather than quantity, and do not try to cheat. To become a good researcher, it is important to build a good reputation and this start by doing quality work, being honest and following the rules.
Hope that this has been interesting. If you have any comments, please leave them in the comment section below.
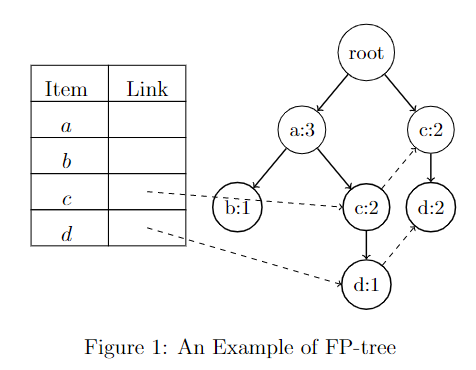
In this blog post, I will show how to draw a beautiful FP-Tree data structure in a Latex document. The FP-Tree is a tree-like structure that was proposed in the FP-Growth algorithm for itemset mining, and is also used in many other pattern mining algorithms. I will show how to draw an FP-tree in Latex using the TIKZ library. An FP-tree consists of a table and a tree that are linked using some pointers (dashed arrows). The result is like this:
I took me a while to obtain this result, so here is the code:
\documentclass[a4paper, 12pt]{article}
\usepackage[utf8]{inputenc}
\usepackage{amssymb}
\usepackage{amsmath}
\usepackage{tikz}
\usetikzlibrary{positioning,matrix}
\begin{document}
\begin{figure}
\centering
\begin{tikzpicture}%%%%% THE TREE
\begin{scope}[->,font=\small,draw,circle, every node/.style={fill=white!10,shape=circle,draw},
edge from parent/.style={black,thick,draw},
level 1/.style={sibling distance=2.5cm},
level 2/.style={sibling distance=2.5cm}]
\node (TREE) {root}
child {node {$a$:3}
child {node {$b$:1} }
child {node {$c$:2}
child {node{$d$:1}}}}
child {node {$c$:2}
child {node {$d$:2}}
};
% Node links within the tree
\draw[->, dashed] (TREE-1-2) -- (TREE-2);
\draw[->, dashed] (TREE-1-2-1) -- (TREE-2-1);
\end{scope}
%%%%% THE TABLE
\begin{scope}[xshift=-5cm,yshift=-2cm,every tree node/.style={shape=rectangle,draw}]
\matrix (TABLE) [matrix of nodes,
row sep=-\pgflinewidth, column sep=-\pgflinewidth,
nodes={draw, text height=5mm,
align=center, minimum width=15mm, inner sep=0mm, minimum height=7mm}]{
Item & Link\\
$a$ & ~\\
$b$ & ~ \\
$c$ & ~\\
$d$ & ~\\
};
\end{scope}
%%%% LINKS FROM THE TABLE TO THE TREE
\draw[->,dashed] (TABLE-4-2.center) to (TREE-1-2.west);
\draw[->,dashed] (TABLE-5-2.center) to (TREE-1-2-1.west);
\end{tikzpicture}
\caption{An Example of FP-tree}
\label{fig:my_label}
\end{figure}
\end{document}
}
Hope that this will be useful! If you like it or if you want to suggest some improvement, please let me know in the comment section below or by e-mail.
The main focus of this workshop is about the concept of utility or importance in data mining and machine learning. The workshop is suitable for papers on pattern mining (e.g. high utility itemsets, frequent pattern mining, sequential pattern mining and other topics) but also for machine learning papers where these is a concept of utility or importance. In fact, the scope of the workshop can be quite broad, so please do not hesitate to submit your papers.
All the accepted papers are published by IEEE in the ICDM Workshop proceedings, which are indexed by EI, DBLP etc. The dates are as follows:
Paper submission deadline: 2nd September 2022
Paper notifications: 23rd September 2022
Camera-ready deadline and copyright forms: 1st October 2022