
This week, I am attending the DASFAA 2022 conference, which is held online from the 11th to the 14th April 2022. In this blog post, I will talk about this event, and will update the blog through the conference.

DASFAA 2022 is the 27th International Conference on Database Systems for Advanced Applications. It is a well-established conference on database and related research areas and applications such as data mining and machine learning. This year, it was supposed to be held in India, but due to the pandemic, it was held in online mode. The conference is organized by IIT Hyderabad, India.
The DASFAA Proceedings
The DASFAA conference proceedings are published by Springer in book(s) of the Lecture Notes in Computer Sciences series. This ensures that papers in DASFAA are indexed and have a good visibility.
This year the DASFAA program includes 5 keynote talks, 143 research papers, 12 industry presentations, a panel, 11 demos, 5 tutorials and 6 workshops (including the PMDB 2022 workshop on pattern mining and machine learning). It is thus a rather large conference. There was 420 registered attendees.
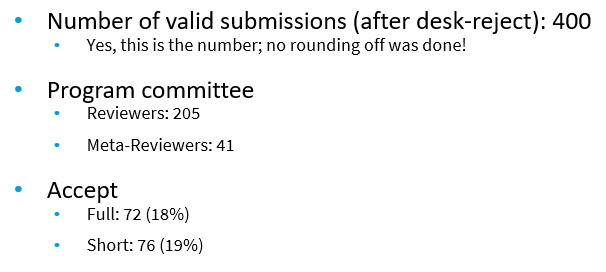
Acceptance rates
For the main track, there was 400 submissions, and 72 were accepted as full papers ( acceptance rate of 18%) and 76 as short papers (19%).
For the industry track, there was 36 submissions, from which there are 7 accepted full papers (19%) and 6 accepted short papers (17%).
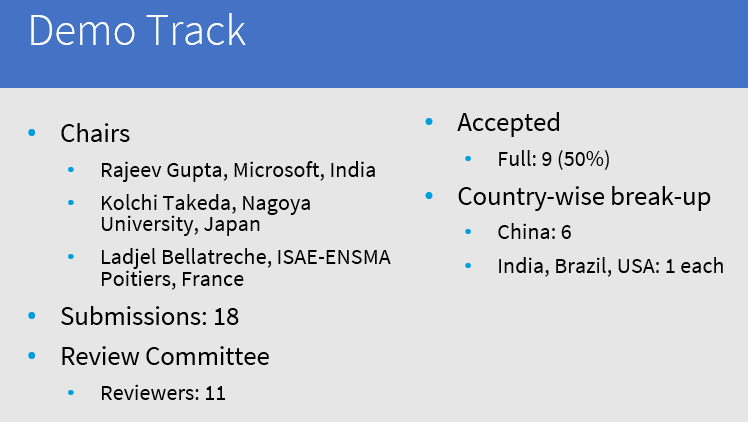
For the demo track, 9 of the 18 submissions were accepted (50%).
For the PhD track, 2 out of 3 submissions were accepted (66%).
The online platform
The conference is held using an online platform called Airmeet. It allows to check the schedule, listen to talks and there are some video chat rooms to socialize with other participants. Here are a few screenshots of that platform. The DASFAA schedule page:
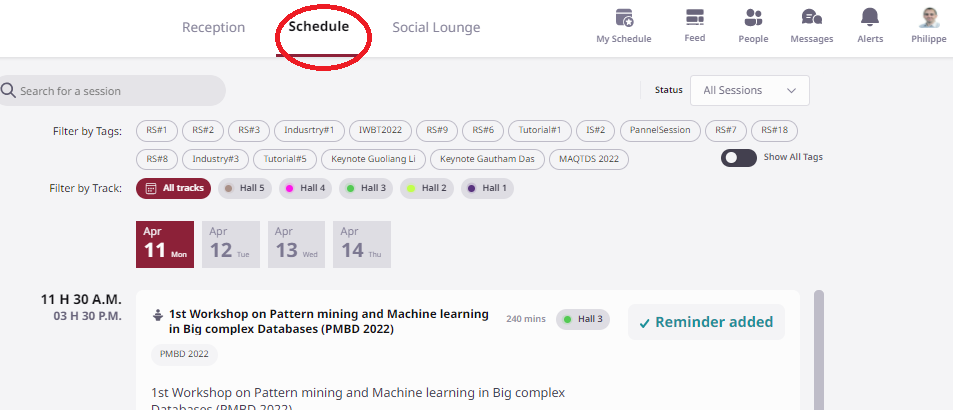
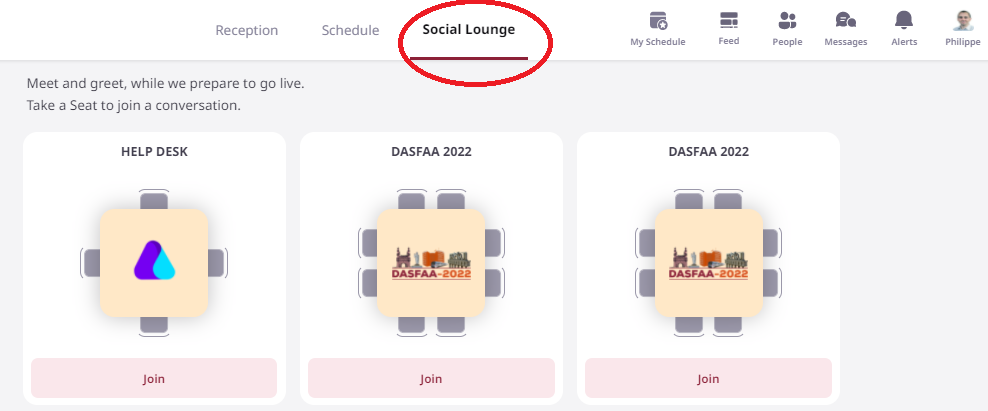
The DASFAA social lounge offering chat rooms:
Day 1 – DASFAA Workshop 1 : PMDB 2022
This year, I have co-organized the PMDB 2022 workshop at DASFAA (1st Workshop on Pattern mining and Machine learning in Big complex Databases). The workshop has 6 papers and a keynote talk by Prof. Joshua Zhexue Huang.
The keynote talk by Prof. Huang, founding director of the big data institute at Shenzhen University was about big data approximate computing. He presented a model called RSP (Random Sample Partition) as an alternative to the popular Hadoop and Spark models. The key idea in RSP is to create distributed data blocks that are random samples of the original data. Then, using these random data blocks, big datasets can be used to train approximate models such as SVM. Using RSP, confidence intervals can be calculated on the errors of approximation. RSP allows to process very large datasets efficiently and provide excellent scalability. In some applications, RSP was shown to have better performance than traditional models such as Hadoop.
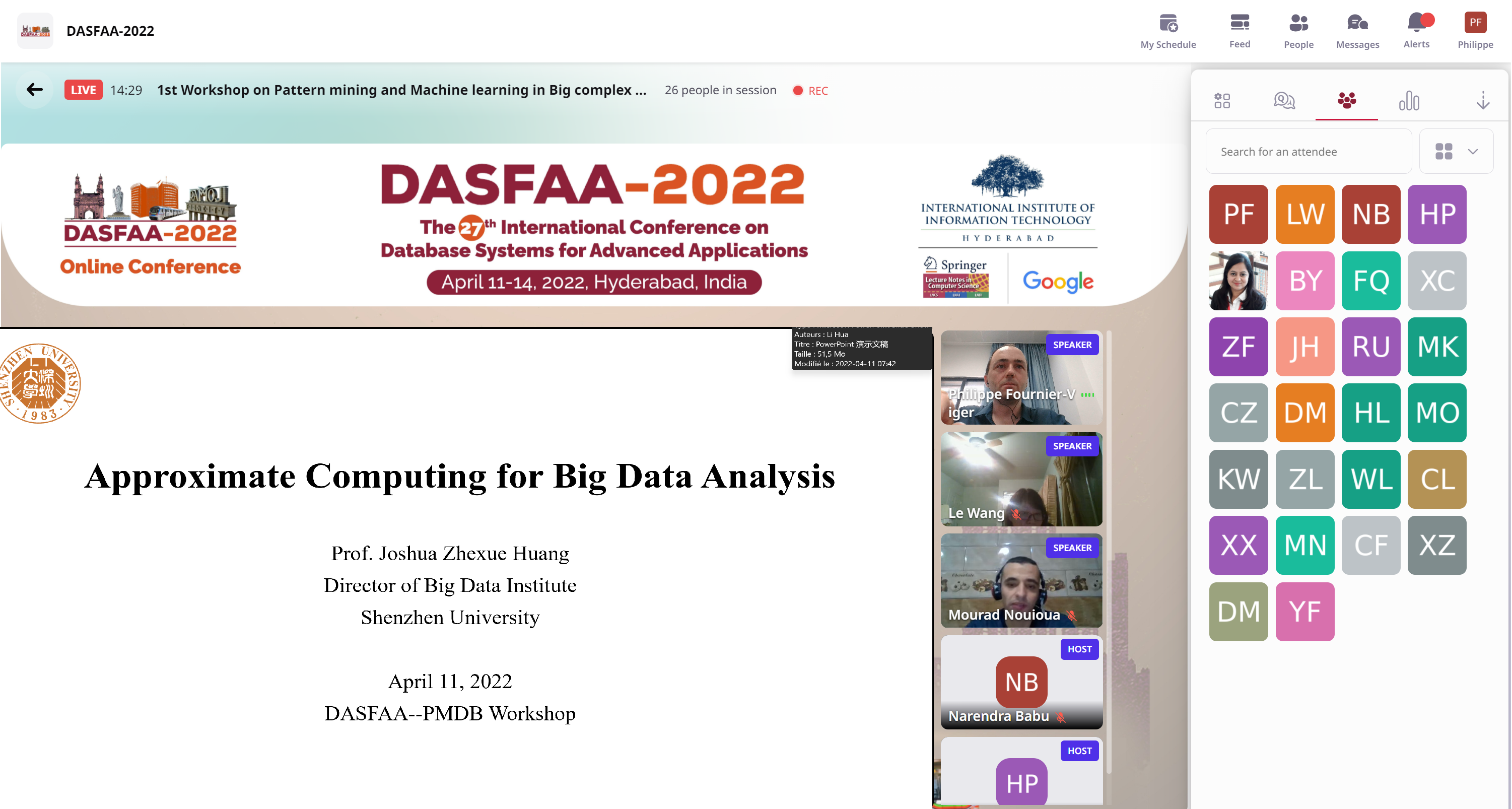
Then, there was 6 accepted papers presentations:
| 9:45 | Paper #2 An Algorithm for Mining Fixed-Length High Utility Itemsets (PDF) Le Wang |
| 10:05 | Paper #3 A Novel Method to Create Synthetic Samples with Autoencoder Multi-layer Extreme Learning Machine (PDF) Qihang Huang, Yulin He, Shengsheng Xu and Joshua Zhexue Huang |
| 10:25 | Paper #4 Pattern Mining: Current Challenges and Opportunities (PDF, video) Philippe Fournier-Viger, Wensheng Gan, Youxi Wu, Mourad Nouioua, Wei Song, Tin Truong and Hai Duong Van |
| 10:45 | Paper #7 Why not to Trust Big Data: Identifying Existence of Simpson’s Paradox (PDF) Rahul Sharma, Minakshi Kaushik, Sijo Arakkal Peious, Mahtab Shahin, Ankit Vidhyarthi and Dirk Draheim |
| 11:05 | Paper #8 Localized Metric Learning for Large Multi-Class Extremely Imbalanced Face Database (PDF) (best paper award) Seba Susan and Ashu Kaushik |
| 11:25 | Paper #9 Top-k dominating queries on incremental datasets (PDF) Jimmy Ming-Tai Wu, Ke Wang and Jerry Chun-Wei Lin |
In particular, something special at this workshop is that we organized a collaborative paper (paper #4) with 7 well-established authors in pattern mining to talk about the current challenges and opportunities in pattern mining. You can watch the video of that talk on Youtube at: https://www.youtube.com/watch?v=CmtXcavZIgM&feature=youtu.be .
The PMDB workshop has been a success. Thus, we aim to organize it again next year and make it larger.
Day 2 – Conference opening
In the conference opening, the conference was presented. There was a lot of interesting information. As I missed one part of the opening, I would to thank Prof. P.K. Reddy for sharing the slides with me. I will provide a few screenshots of interesting content from the opening below.










Keynote 1 : Fairness in Database Querying by Gautam Das
The first keynote of the conference was about fairness for database queries. This is an topic that has made the news in recent years with machine learning models that are for example deemed to be racist or unfair to some groups. Here are a few slides:







Research paper presentations
There was numerous paper presentations. I was busy. Thus I will not specifically report on them.
Next year, DASFAA 2023
DASFAA2023 will be in Tianjin, China during April 2023
Conclusion
I have given a brief overview of the DASFAA 2022 conference. Hope that it has been interesting.
—
Philippe Fournier-Viger is a distinguished professor working in China and founder of the SPMF open source data mining software.



