
I have created a new website for students that provides an interactive demo of the Apriori algorithm. It allows to run Apriori in your browser and see the results step by step.
The website is here: Apriori Algorithm Demo
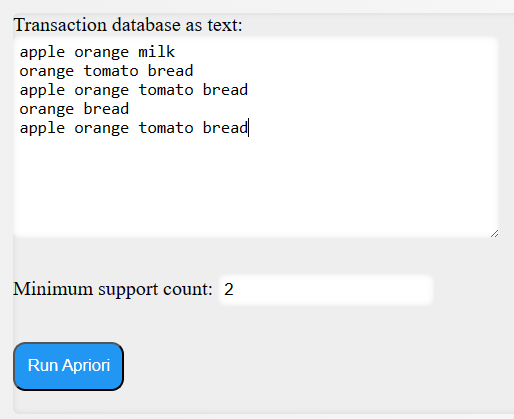
To use it you first have to input some data and choose a minimum support value and then click the Run Apriori button:
Then, all the steps of applying the Apriori algorithm are displayed:
Step 1: Calculate the support of single items
- {apple} (support: 3)
- {orange} (support: 5)
- {milk} (support: 1)
- {tomato} (support: 3)
- {bread} (support: 4)
Step 2: Keep only the frequent items
{milk} was pruned because its support count (1) is less than the minimum support count (2)
- {apple} (support: 3)
- {orange} (support: 5)
- {tomato} (support: 3)
- {bread} (support: 4)
Step 3: Join frequent itemsets to create candidates of size 2
- {apple} and {orange} are joined to obtain {apple, orange}
- {apple} and {tomato} are joined to obtain {apple, tomato}
- {apple} and {bread} are joined to obtain {apple, bread}
- {orange} and {tomato} are joined to obtain {orange, tomato}
- {bread} and {bread} are joined to obtain {bread, orange}
- {bread} and {bread} are joined to obtain {bread, tomato}
Step 4: Calculate the support of candidate itemsets
- {apple, orange} (support: 3)
- {apple, tomato} (support: 2)
- {apple, bread} (support: 2)
- {orange, tomato} (support: 3)
- {bread, orange} (support: 4)
- {bread, tomato} (support: 3)
Step 5: Keep only the candidate itemsets that are frequent
- {apple, orange} (support: 3)
- {apple, tomato} (support: 2)
- {apple, bread} (support: 2)
- {orange, tomato} (support: 3)
- {bread, orange} (support: 4)
- {bread, tomato} (support: 3)
Step 6: Join frequent itemsets to create candidates of size 3
- {apple, orange} and {apple,tomato} are joined to obtain {apple, orange, tomato}
- {apple, bread} and {apple,bread} are joined to obtain {apple, bread, orange}
- {apple, bread} and {apple,bread} are joined to obtain {apple, bread, tomato}
- {bread, orange} and {bread,tomato} are joined to obtain {bread, orange, tomato}
Step 7: Calculate the support of candidate itemsets
- {apple, orange, tomato} (support: 2)
- {apple, bread, orange} (support: 2)
- {apple, bread, tomato} (support: 2)
- {bread, orange, tomato} (support: 3)
Step 8: Keep only the candidate itemsets that are frequent
- {apple, orange, tomato} (support: 2)
- {apple, bread, orange} (support: 2)
- {apple, bread, tomato} (support: 2)
- {bread, orange, tomato} (support: 3)
Step 9: Join frequent itemsets to create candidates of size 4
- {apple, bread, orange} and {apple,bread,tomato} are joined to obtain {apple, bread, orange, tomato}
Step 10: Calculate the support of candidate itemsets
- {apple, bread, orange, tomato} (support: 2)
Step 11: Keep only the candidate itemsets that are frequent
- {apple, bread, orange, tomato} (support: 2)
Step 12: Join frequent itemsets to create candidates of size 5
No more candidates can be generated. Total number of frequent itemsets found: 15
As well as the final result (the frequent itemsets):

That is all. With this tool, you can run the algorithm in your browser and see directly the result, which is useful for students.
If you want to learn more about the Apriori algorithm, you can check my blog post that explains the Apriori algorithm and my video lecture about Apriori ). And if you want to know more about pattern mining, please check my free online pattern mining course. Finally, if you want an efficient implementation of Apriori, please check the SPMF software, which offers highly efficient implementations of Apriori and hundreds of other pattern mining algorithms.
Also, if you are new to itemset mining, you might be interested to check these two survey papers that give a good introduction to the topic:
- Fournier-Viger, P., Lin, J. C.-W., Vo, B, Chi, T.T., Zhang, J., Le, H. B. (2017). A Survey of Itemset Mining. WIREs Data Mining and Knowledge Discovery, Wiley, e1207 doi: 10.1002/widm.1207, 18 pages.
- Luna, J. M., Fournier-Viger, P., Ventura, S. (2019). Frequent Itemset Mining: a 25 Years Review. WIREs Data Mining and Knowledge Discovery, Wiley, 9(6):e1329. DOI: 10.1002/widm.1329
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 250 data mining algorithms.



