
Today, I will write about a ranking called CSRankings, which is used by some people to rank computer science programs from different universities. That ranking has some interesting aspects such that its code and data is open to the public, but it is in my opinion biased for several reasons. I previously wrote a blog post about the shortcomings of CSRankings.
Some shortcomings are that it only considers conference papers, while journal papers are more important in several countries, and that CSRankings is US-centric in its methodology. But a bigger problem, as I explained last time, is that CSRankings is biased towards some subfields of computer science. For example, that ranking has a category for robotics with some conferences such as ICRA that have a very high acceptance rate (~49%), while some other categories have conferences with a much lower acceptance rate (~10%), and some subfields of computer science are basically ignored such as data mining.
About data mining, in my previous blog post, I pointed out that the KDD conference, which is arguably the #1 conference in data mining with an acceptance rate of around 10%, was deactivated by default in CSRankings. Here is a screenshot:
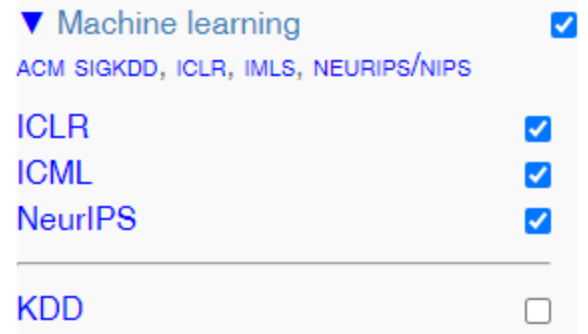
This is quite baffling given that KDD is highly regarded, even with top companies and universities regularly publishing in this conference. Other data mining conferences are also omitted from that ranking. So basically, we could say that the field of data mining does not exist in that ranking, and that would be somewhat true. There is a category called “database” but it also excludes ICDE by default.

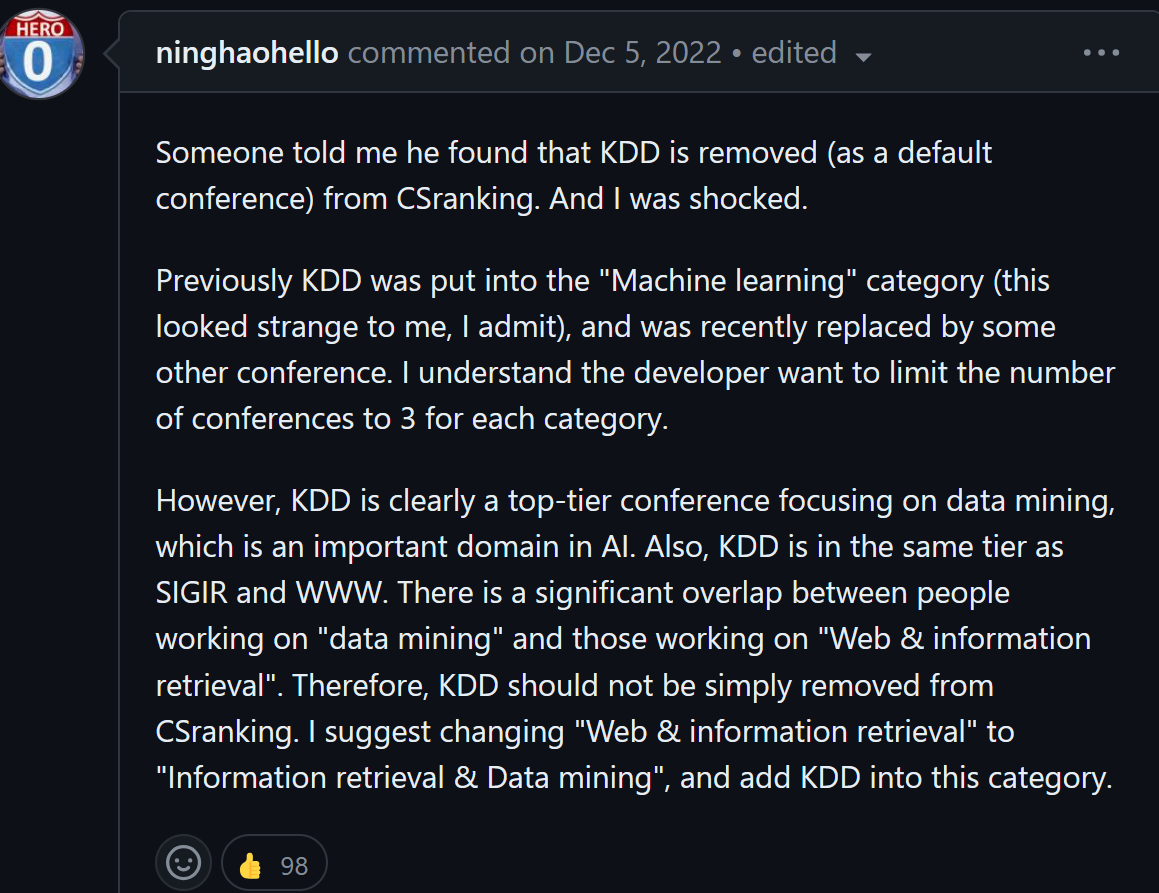
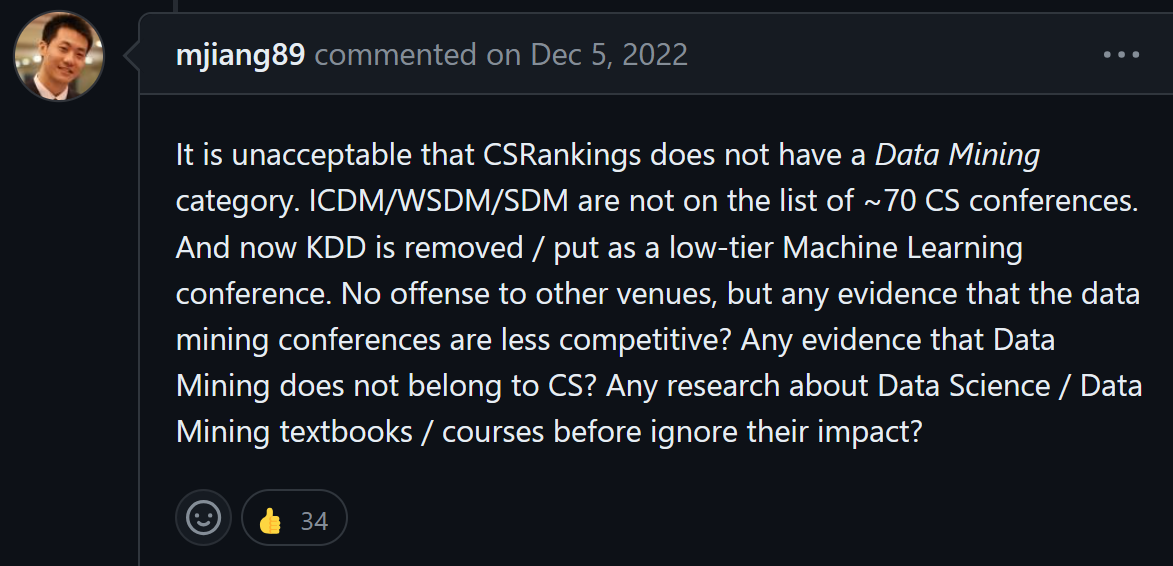
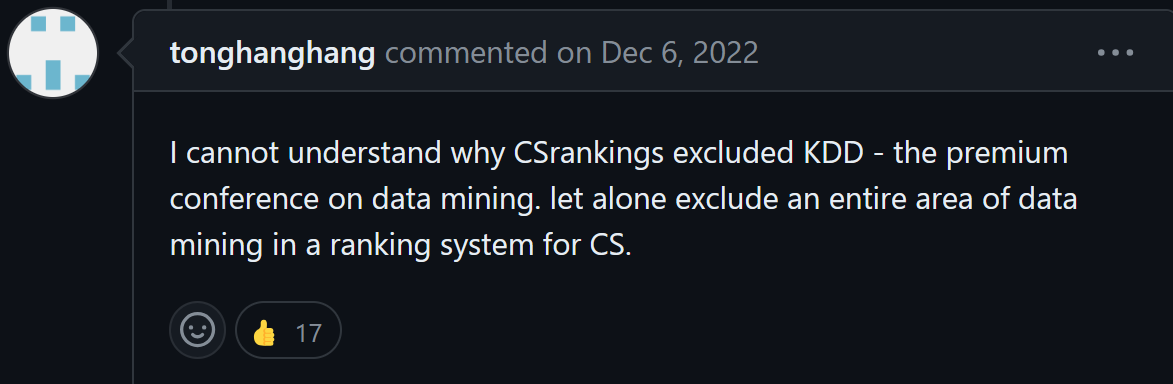
On the Github page of CSRankings, several people have complained that KDD has been removed from CSRankings, as obviously several people are unhappy with this (source: github.com/emeryberger/CSrankings/issues/5397):
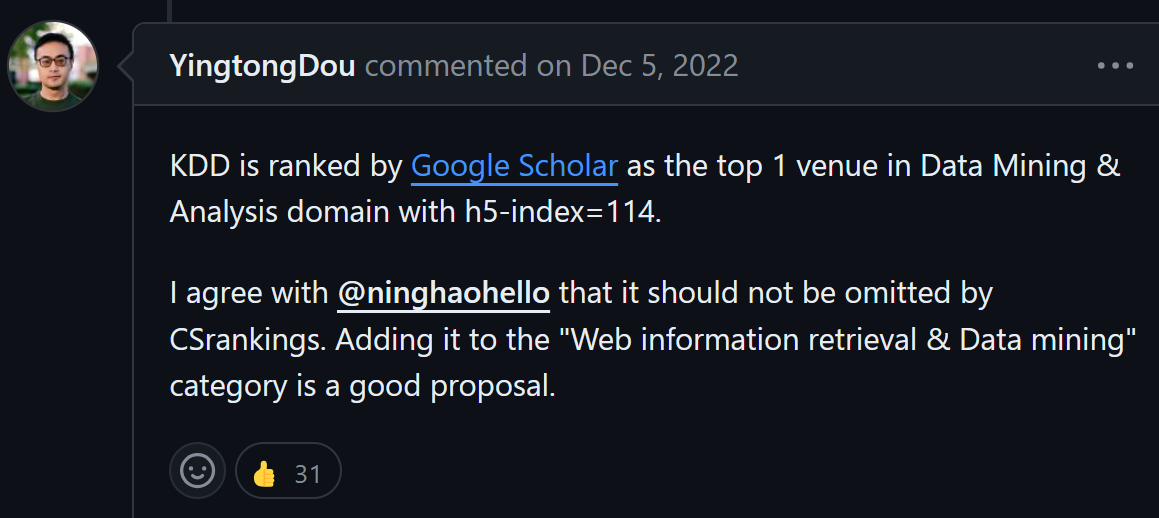
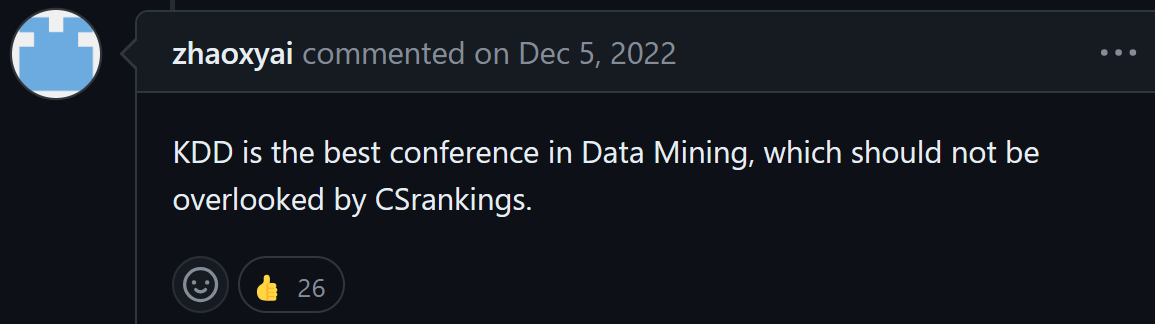
Some other supporting messages are as follows:
There was a message from one of the CSRankings owner announcing that this might change:

However, more than a year has passed and nothing has changed.
I wrote this blog post to raise awareness about this issue with CSRankings. So how to fix it? In my opinion, the best solution would be to add a “data mining” category with KDD and ICDM at least. Then, it would be more fair for the data mining community, which has been thriving for almost three decades. Data mining should not be wiped-out just like that from a ranking.
Or another solution would be that someone clone the code and data of CSRankings (since it is open-source) to start a more fair ranking that would fix these problems because CSRankings might not fix them. Of course, no ranking is perfect, but I think that some obvious improvements could be done in this case. Who is willing to do it?
That is all for today. By the way, note that the content of this blog post represents my personal opinion.



