
In this blog post, I will talk about the future of research on pattern mining. I will also discuss some lessons learnt from the decades of research in this field and talk about research opportunities.

What is the state of research on pattern mining?
Over the last decades, many things have been discovered in pattern mining. The field has become more mature. For example, algorithms for pattern mining generally always follow the same general approaches, established more than a decade ago. The main types of algorithms in pattern mining are the Apriori based algorithms, pattern growth algorithms and vertical algorithms. The proposal of these fundamental approaches has facilitated the development of new algorithms.
However, although traditional pattern mining problems have been well-studied such as frequent itemset mining, novel pattern mining problems are constantly proposed, and these problems often have unique challenges that require new tailored solutions. For example, this is the case for subgraph mining, where a subgraph mining algorithm must be able to deal with the problem of subgraph isomorphism checking, which does not exist in traditional pattern mining problems such as itemset mining. Another example is the design of efficient algorithms for novel architecture such as cloud systems, parallel systems, GPUs, and FPGAs, which requires to rethink traditional algorithms and their data structures.
A second observation about the state of research on pattern mining is that not all research areas of pattern mining have been explored equally. For example, some topics such as frequent itemset mining and association have received a lot of attention while other problems such as sequential rule mining and periodic pattern mining have been much less explored. In my opinion, this is not because these latter problems are less useful but perhaps because the problem of frequent itemset mining is simpler.
A third observation is that the field of pattern mining seems to be less popular in the last decade. This is certainly true but it is not something to worry about because there are countless research problems that have not been solved in this field. Besides, all fields of computer science follow some trends that are cyclic. This is the case for example for research on artificial intelligence which currently receives a lot of attention but was previously met with disinterest and lack of funding opportunities during specific time periods in the last decades (the “AI winters”). Besides, although pattern mining may seem to be less studied than before, some subfields of pattern mining are actually becoming more and more popular. For example, this is the case for high utility pattern mining, which has been growing steadily since the last 15 years. Here is a plot of the number of papers per year on utility mining (a figure prepared by Gan et al (2018):
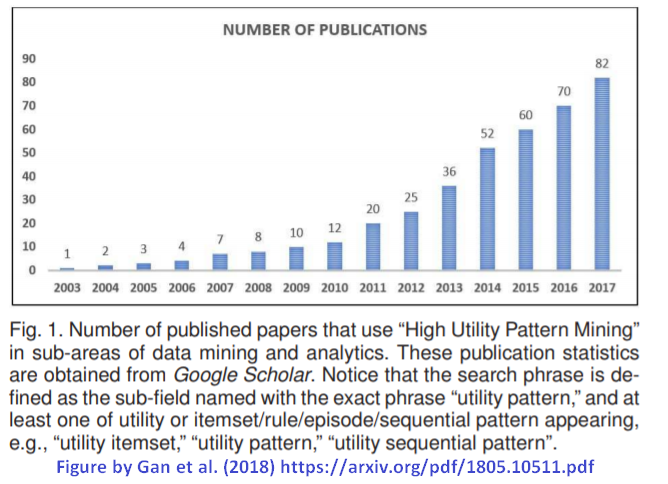
This figure clearly shows a growing interest on the topic of utility pattern mining. Besides, quality papers in the field of pattern mining are still published in top conferences and journals.
What lessons can we learn?
Several lessons can be learnt. The first one is that too much research have in my opinion focused on improving the performance of algorithms in the last decades, while neglecting the applications of these algorithms. Don’t get me wrong. Performance is very important as one does not want to wait several hours to find patterns. However, considering the usefulness of the discovered patterns ensure that these algorithms will actually be used in real applications. If researchers would think more about the usefulness of patterns, I think that this could help grow the field of pattern mining further.
There are several pattern mining problems, which have not been applied in real life. Why? A first reason is that the assumptions of some of these problems are unrealistic or too simple.
For researchers working on pattern mining, I think that potential applications should always be considered first. Working on problems that have many potential applications or are more useful should be preferred. Thus a key lesson is to not forget the user and the applications. If possible discussions with potential users should be carried to learn about their needs. In general, a principle is that the more a problem is specialized, the less likely it will be to be used in real-life. For example, if someone would propose a very specialized problem such as “mining recent high utility episode patterns in an uncertain data streams when considering a sliding window and a gap constraint”, it is certainly less likely to be useful than the more general problem of “mining high utility episodes“.
A second reason why many algorithms are not used in real life is that many researchers do not provide their source code or applications. Sometimes, it is because the authors cannot share them due to restrictions from their institutions or collaborators. And sometimes, it is simply because researchers are worried that someone could design a better algorithm. There are also other reasons such as the lack of time to release the algorithms. But sharing the source code of algorithms could greatly help other researchers and people interesting in using the algorithms. I previously wrote a detailed blog post about why researchers should share their implementations.
Research opportunities
Having discussed the state of research on pattern mining, there are actually many research opportunities such as:
- Proposing faster and more memory efficient algorithms,
- Proposing algorithms having more features or more user-friendly (e.g. interactive algorithms, visualization or algorithms offering to specify additional constraints that are useful for the user)
- Proposing new pattern mining tasks that have novel challenges,
- Proposing new applications of existing algorithms,
- Proposing variations of existing problems (e.g. mining patterns in big data, using parallel architectures, etc.)
I personally think that pattern mining is a good research area because it is challenging and many things can be done.
Conclusion
This is what I wanted to talk about for today. Hope you will have enjoyed this blog post. If you have any other ideas or comments, please leave them in the comment section.
—-
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.



