
In this blog post, I will give an introduction to an interesting data mining task called frequent subgraph mining, which consists of discovering interesting patterns in graphs (a pattern mining task). This task is important since data is naturally represented as graph in many domains (e.g. social networks, chemical molecules, map of roads in a country). It is thus desirable to analysze graph data to discover interesting, unexpected, and useful patterns, that can be used to understand the data or take decisions.
What is a graph? A bit of theory…
But before discussing the analysis of graphs, I will introduce a few definitions. A graph is a set of vertices and edges, having some labels. Let’s me illustrate this idea with an example. Consider the following graph:
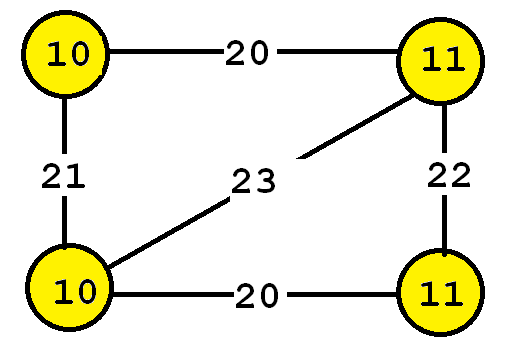
This graph contains four vertices (depicted as yellow circles). These vertices have labels such as “10” and “11”. These labels provide information about the vertices. For example, imagine that this graph is a chemical molecule. The label 10 and 11 could represent the chemical elements of Hydrogen and Oxygen, respectively. Labels do not need to be unique. In other words, the same labels may be used to describe several vertices in the same graph. For example, if the above graph represents a chemical molecule, the labels “10” and “11” could be used for all vertices representing Oxygen and Hydrogen, respectively.
Now, besides vertices, a graph also contains edges. The edges are the lines between the vertices, here represented by thick black lines. Edges also have some labels. In this example, four labels are used, which are 20, 21, 22 and 23. These labels represents different types of relationships between vertices. Edge labels do not need to be unique.
Types of graphs: connected and disconnected
Many different types of graphs can be found in real-life. Graphs are either connected or disconnected. Let me explain this with an example. Consider the two following graphs:
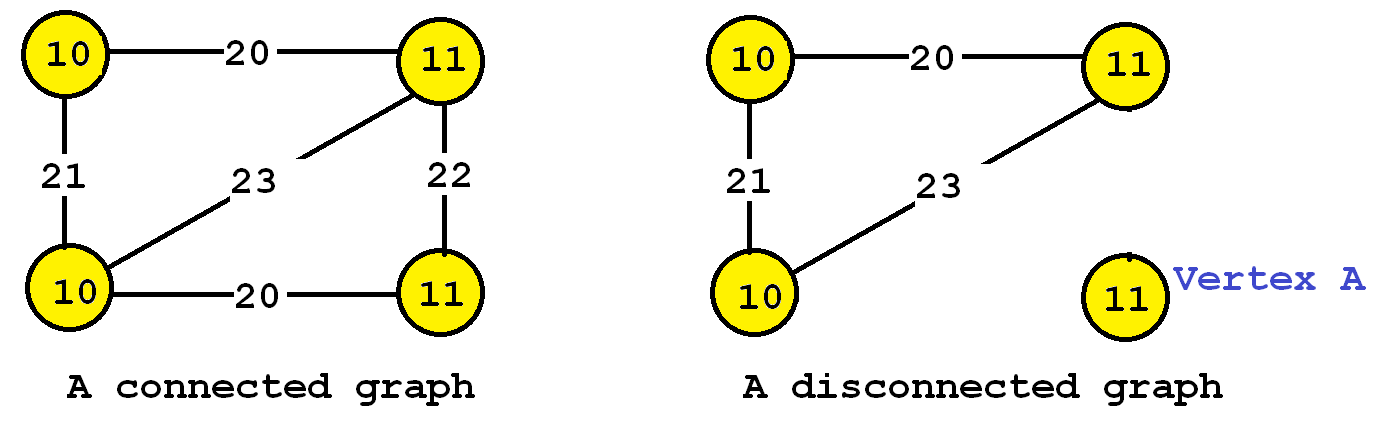
The graph on the left is said to be a connected graph because by following the edges, it is possible to go from any vertex to any other vertices. For example, imagine that vertices represents cities and that the edges are roads between cities. A connected graph in this context is a graph where it is possible to go from any city to any other cities by following the roads. If a graph is not connected, it is said to be a disconnected graph. For example, the graph on the right is disconnected since Vertex A cannot be reached from the other vertices by following the edges. In the following, we will use the term “graph” to refer to connected graphs. Thus, all the graphs that we will discuss in the following paragraphs will be connected graphs.
Types of graphs: directed and undirected
It is also useful to distinguish between directed and undirected graphs. In an undirected graph, edges are bidirectional, while in a directed graph, the edges can be unidirectional or bidirectional. Let’s illustrate this idea with an example.
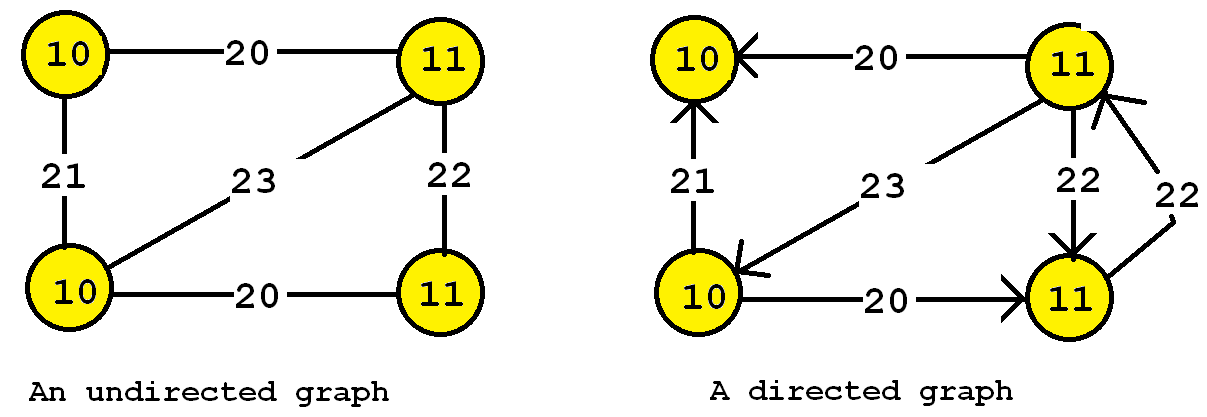
The graph on the left is undirected, while the graph on the right is directed. What are some real-life examples of a directed graph? For example, consider a graph where vertices are locations and edges are roads. Some roads can be travelled in both directions while some roads may be travelled in only a single direction (“one-way” roads in a city).
Some data mining algorithms are designed to work only with undirected graphs, directed graphs, or support both.
Analyzing graphs
Now that we have introduced a bit of theory about graphs, what kind of data mining task can we do to analyze graphs? There are many answers to this question. The answer depends on what is our goal but also on the type of graph that we are analyzing (directed/undirected, connected/disconnected, a single graph or many graphs).
In this blog post, I will explain a popular task called frequent subgraph mining. The goal of subgraph mining is to discover interesting subgraph(s) appearing in a set of graphs (a graph database). But how can we judge if a subgraph is interesting? This depends on the application. The interestingness can be defined in various ways. Traditionally, a subgraph has been considered as interesting if it appears multiple times in a set of graphs. In other words, we want to discover subgraphs that are common to multiple graphs. This can be useful for example to find association between chemical elements common to several chemical molecules.
The task of finding frequent subgraphs in a set of graphs is called frequent subgraph mining. As input the user must provide:
- a graph database (a set of graphs)
- a parameter called the minimum support threshold (minsup).
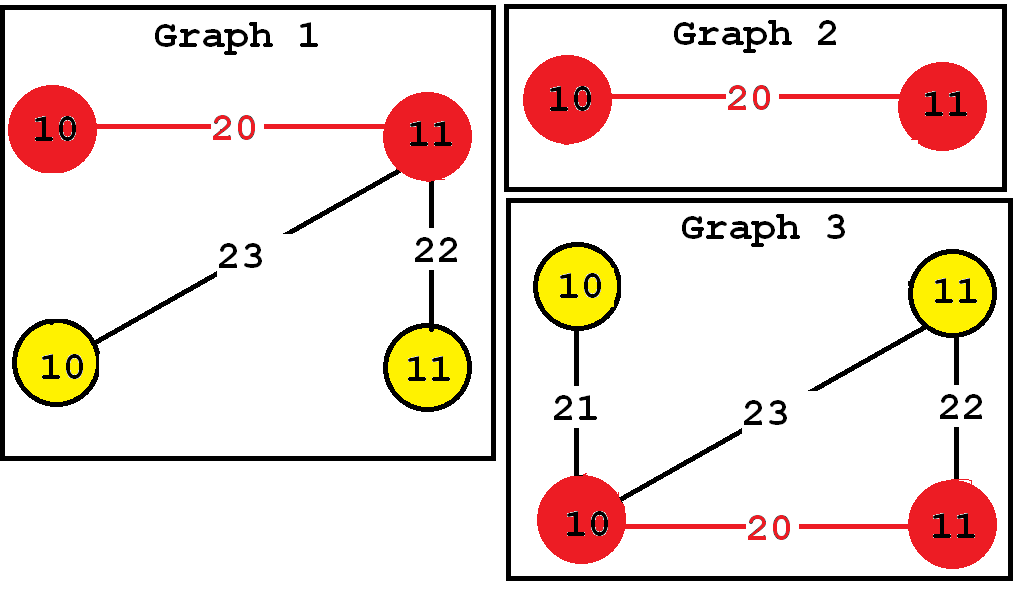
Then, a frequent subgraph mining algorithm will enumerate as output all frequent subgraphs. A frequent subgraph is a subgraph that appears in at least minsup graphs from a graph database. For example, let’s consider the following graph database containing three graphs:
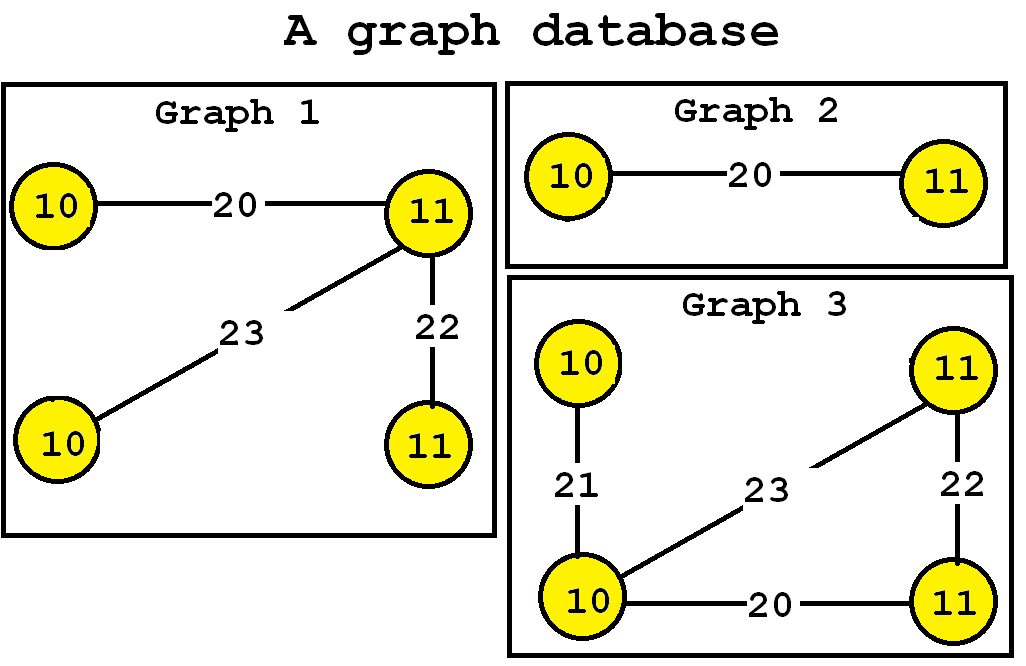
Now, let’s say that we want to discover all subgraphs that appear in at least three graphs. Thus, we will set the minsup parameter to 3. By applying a frequent subgraph mining algorithm, we will obtain the set of all subgraphs appearing in at least three graphs:
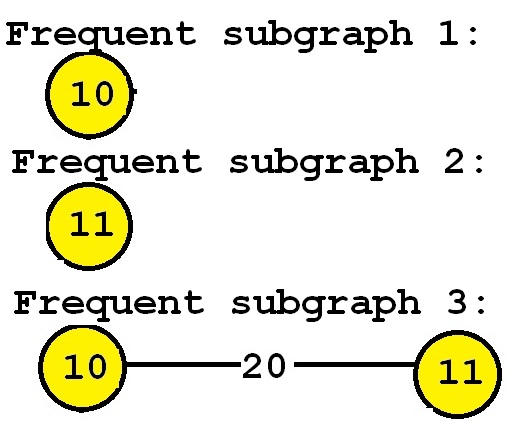
Consider the third subgraph (“Frequent subgraph 3”). This subgraph is frequent and is said to have a support (a frequency) of 3 since it appears in three of the input graphs. These occurrences are highlighted in red, below:
Now a good question is how to set the minsup parameter? In practice, the minsup parameter is generally set by trial and error. If this parameter is set too high, few subgraphs will be found, while if it is set too low, hundred or millions of subgraphs may be found, depending on the input database.
Now, in practice, which tools or algorithms can be used to find frequent subgraphs? There exists various frequent subgraph mining algorithms. Some of the most famous are GASTON, FSG, and GSPAN.
Mining frequent subgraphs in a single graph
Besides discovering graphs common to several graphs, there is also a variation of the problem of frequent subgraph mining that consists of finding all frequent subgraphs in a single graph rather than in a graph database. The idea is almost the same. The goal is also to discover subgraphs that appear frequently or that are interesting. The only difference is how the support (frequency) is calculated. For this variation, the support of a subgraph is the number of times that it appears in the single input graph. For example, consider the following input graph:
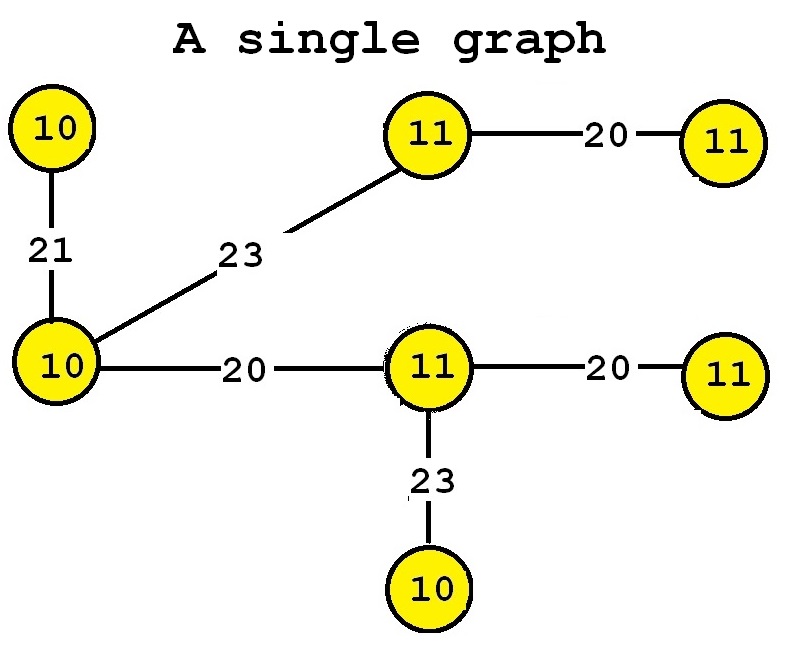
This graph contains seven vertices and six edges. If we perform frequent subgraph mining on this single graph by setting the minsup parameter to 2, we can discover the five following frequent subgraphs:

These subgraphs are said to be frequent because they appear at least twice in the input graph. For example, consider “Frequent subgraph 5”. This subgraph has a support of 2 because it has two occurrences in the input graph. Those two occurrences are highlighted below in red and blue, respectively.
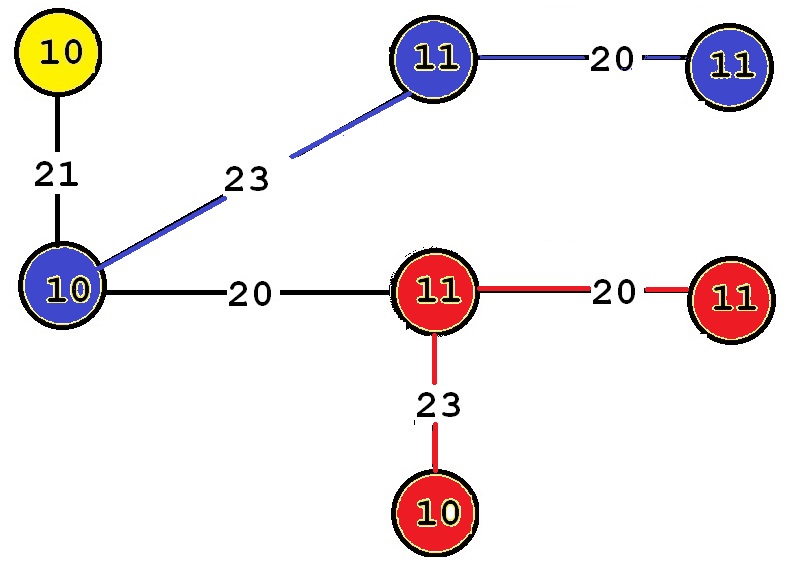
Algorithms to discover patterns in a graph database can often be adapted to discover patterns in a single graph.
Want to try frequent subgraph mining?
If you want to try frequent subgraph mining algorithms, some public fast Java open-source implementations of TKG for top-k frequent subgraph mining and gSpan are available in the SPMF data mining library. The SPMF library also offers algorithms for many other pattern mining tasks such as high utility itemset mining, sequential pattern mining, sequential rule mining and periodic pattern mining.
Conclusion
In this blog post, I have introduced the problem of frequent subgraph mining, which consists of discovering subgraphs appearing frequently in a set of graphs. This data mining problem has been studied for more than 15 years, and many algorithms have been proposed. Some algorithms are exact algorithms (will find the correct answer), while some other are approximate algorithms (do not guarantee to find the correct answer, but may be faster).
Some algorithms are also designed to handle directed or undirected graphs, or mine subgraphs in a single graph or in a graph database, or can do both. Besides, there exists several other variations of the subgraph mining problem such as discovering frequent paths in a graph, or frequent trees in a graph.
Besides, in data mining in general, many other problems are studied related to graphs such as optimization problems, detecting communities in social networks, relational classification, etc.
In general, problems related to graphs are quite complex compared to some other types of data. One of the reason why subgraph mining is difficult is that algorithms typically need to check for “subgraph isomorphisms“, that is to compare subgraphs to determine if they are equivalent. But nonetheless, I think that these problems are quite interesting as there are several research challenges.
I hope that you have enjoyed this blog post. If there is some interest about this topic, I may do another blog post on graph mining in the future.
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.




Pingback: Subgraph mining datasets | The Data Mining Blog
Pingback: A brief report about the Big Data Analytics 2019 conference (BDA 2019) | The Data Mining Blog
Pingback: The SPMF data mining library v.2.40 is released! | The Data Mining Blog
Pingback: The future of pattern mining | The Data Mining Blog
Pingback: An Introduction to Sequential Pattern Mining | The Data Mining Blog
Pingback: An Overview of Pattern Mining Techniques (by data types) | The Data Mining Blog
Thanks for this great educational post!
Pingback: New videos about pattern mining | The Data Mining Blog
Pingback: How to Analyze the Complexity of Pattern Mining Algorithms? | The Data Mining Blog
Pingback: 频繁子图挖掘算法介绍 | The Data Mining Blog
Pingback: SPMF Upcoming feature: Graph viewer | The Data Mining Blog
Pingback: On the correctness of the FSMS algorithm for frequent subgraph mining | The Data Mining Blog