
In this blog post, I will give an overview of some of the main pattern mining tasks, to explain what kind of patterns can be found in different types of symbolic data. I will describe some main types of data and list some main types of patterns that can be found in the data using pattern mining algorithms. This list is not exhaustive but covers some of the main problems studied by researchers in pattern mining and some variations.

To find patterns in your data, there are many data mining algorithms that can be used. To apply the algorithms described below, you may find fast, efficient and open-source implementations of pattern mining algorithms in the SPMF software/library (which I am the founder), which offers over 200 algorithms.
1.Finding Patterns in Binary Records
Data description: This first common type of data is a table containing a set of records described using a set of binary attributes. For example, a binary table is shown below. This table contains four records called T1, T2, T3 and T4, which are described using four five attributes (a,b,c,d,e)

This type of data is very common in many fields. For example, it can be used to represent:
- what some customers have purchased in a store (record = customer, attributes = purchased items)
- the words appearing in text documents (record = text document, attributes = appearance of a word)
- the characteristics of animals (record = animal, attributes = characteristics such as has fur?)
What kind of patterns can be found in this data?
The main type of patterns that can be discovered in a binary table are:
- frequent itemsets: a frequent itemset is a set of values that appear in many records. For example, by using some algorithms such as FPGrowth, we can find that the itemset {a,b} appears three times in the above table, as well as other itemsets such as {d,e}, {e}, {a}, {d} and others. In a real application, someone could for example find that many people buy bread and milk together in a store.

- association rules: an association rule indicate some strong relationship between some attributes. It is has the form of a rule X –> Y indicating that if some attribute values X are found in a record, they are likely associated with some other values Y. For example, in the above database, it can be found that {a,b}–> {e} is a strong association rules because (1) it is frequent (appears many times in the database), and also it has a high confidence (or conditional probability), that is everytime that {a,b} appears, {e} also appears.
- rare itemsets: Those are sets of values that do not appear many times in the data but are still strongly correlated.
2. Finding Patterns in a Sequence of Binary Records
Data description: This is a sequence of records, where each record is described using binary attributes. Records are ordered by time or other factors. For example, a binary table where records are ordered is shown below. This table contains four records called T1, T2, T3 and T4, which are described using four five attributes (a,b,c,d,e)
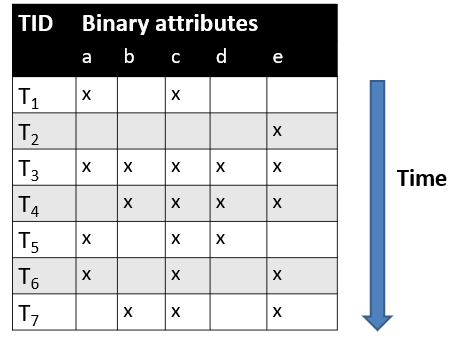
This type of data is common in various fields. For example, it can be used for
- representing what a customer has purchased in a store over time (record = each transaction made by a customer, attributes = purchased items, ordered by purchase time)
- the words appearing sentences of a text document (record = word in a sentence, attributes = appearance of a word, ordered by sentences)
- a sequence of locations visited by a person in a city (record = the position at a given time, attribute = the point of interest or location)
- a DNA sequence (record = a nucletoride, attribute: the nucleotide type such as ACGT, ordered by appearance) such as COVID-19 sequences
The main type of patterns that can be discovered in a sequence of binary records are:
- frequent episodes: an episode is of values that often appear close to each other. For example, an episode can be <{e}{c}> indicating that e is often followed by c, shortly after. To discover frequent episodes some algorithms are MINEPI, WINEPI, EMMA and TKE. (see a survey of episode mining for more details)
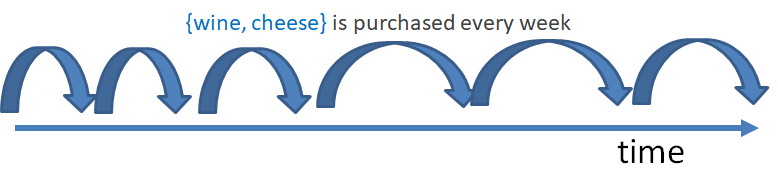
- periodic itemsets: a periodic itemset is a set of values that is always re-appearing over time in a sequence of records. For example, in the above example, the itemset {a,c} always re-appear every one or two transactions, and hence can be called “periodic”. This type of patterns can be found by algorithm such as PFPM an others. An example application of finding periodic patterns is to study the behavior of customers in a store. It could be find that someone regularly purchase wine and cheese together.
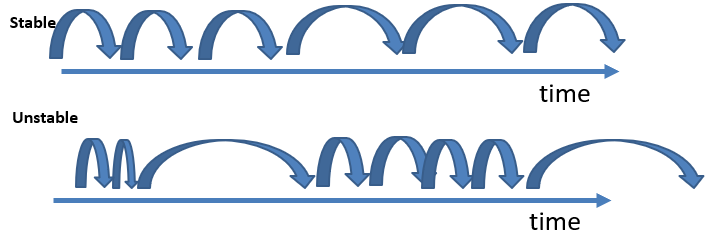
- stable patterns: a stable patterns is a periodic patterns that has a stable periodic behavior over time. This means that the time between each occurrence of the pattern is more or less stable. The SPP-Growth algorithm can be used for this task. Here is an intuitive illustration of the concept of stability:
- recently frequent patterns: The goal is to find patterns that have appeared many times recently rather than in the past. Algorithms such as EstDec can be used for this.
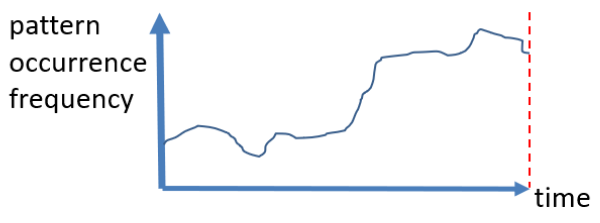
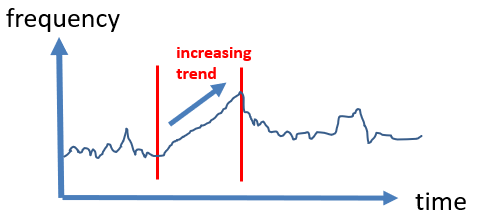
- trends: Some algorithms are also designed to find increasing or decreasing trends. For example, some set of values may have may have an occurrence frequency that is slowly increasing during some time period. Such patterns can be found using some algorithms such as LTHUI-Miner.
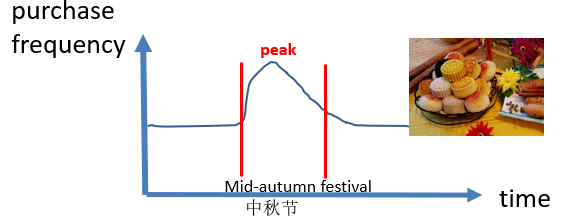
- peaks: another interesting type of patterns that can be found in a sequence of records is peaks. A peak means that some set of values appears much more often than usual during some time interval. Some algorithm to find peak in a sequence of records is PHUI-Miner. For example, the picture below show that some type of food called “moon cakes” have a sale peak during some specific time period of the year in China, which is the mid-autumn festival.
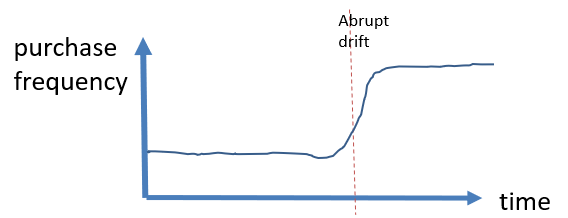
- concept drifts: A concept drift is an abrupt of slow changes that happens over time. For example, it could be found in customer data, that the sales of some products as suddenly increased a lot due to the products being advertised on TV. This is illustrated with a picture:
3.Finding Patterns in a Sequence Database
Data description: Another type of data that is very common is a database of sequences of records. This is the same as the above data type except that instead of having a single sequences, we have a database containing multiple sequences. Below is an example, sequence database containing four sequences called s1, s2, s3 and s4. The first sequence indicates that some value a is followed by a value b, which is followed by c, and then by a, then b, then e, and finally f.

This type of data is common in various fields. For example, it can be used for
- representing what a set of customers have each purchased in a store over time (sequence = the sequence of transaction made by a customer, values = purchased items)
- the words appearing in sentences of a text document (sequence = a sentence where values represent words, each sentence is a sequence).
- the sequence of locations visited by tourists in a city (sequence = the list of tourist spots visited by a tourist, each sequence represents a tourist)
- and more..
The main type of patterns that can be discovered in a sequence of binary records are:
- sequential patterns: a sequential pattern is a subsequence that appears in many sequences of the input database. In the above example, a sequential pattern is <{a},{b},{a}> because this patterns appear in the four sequences. Some algorithms for this tasks are GSP, CM-SPAM and CM-SPADE. It is also possible to add various constraints such as whether gaps are allowed or not between values in a sequential patterns. Some example of application is to find frequent sequence of locations visited by tourists and frequent sequence of purchases made by customers:

- sequential rules: A sequential rule indicate some strong relationship between some values in several sequences. It is has the form of a rule X –> Y indicating that if some attribute values X appears, they are likely to be followed by some other values Y. For example, in the above database, it can be found that {a,b}–> {f} is a strong sequential rules because (1) it is frequent (appears many times in the database), and also it has a high confidence (or conditional probability), that is {a,b} is always followed by {f} . There are many algorithms for discovering sequential rules such as RuleGrowth, CMRules, and RuleGen. Some offer additional features or constraints such as to handle data with timestamps.
4.Finding Patterns in a Graph, Trees and Dynamic Graphs
Data description: Another type of data that is quite popular aregraphs. They can be used to represent various data types such as social networks and chemical molecules. There are various types of graphs and some algorithms to analyze them. Some main graph types are shown below (taken from this survey):

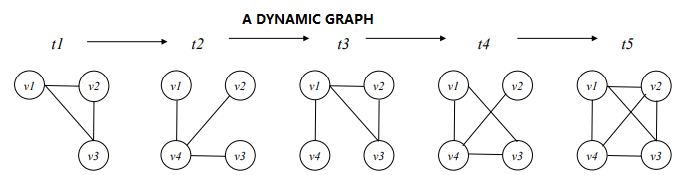
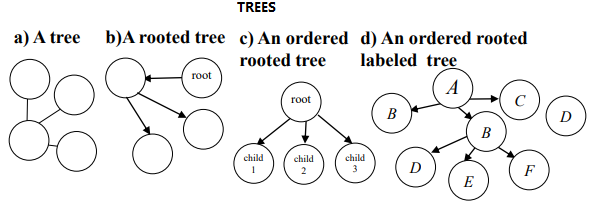
Some main type of patterns that can be discovered in one or more graphs are:
- frequent subgraphs: those are subgraphs that appear many times in a large graph, or subgraphs that appear in many graphs. Some algorithms for this task are Gaston, GSPAN and TKG. Some illustrations are given below:
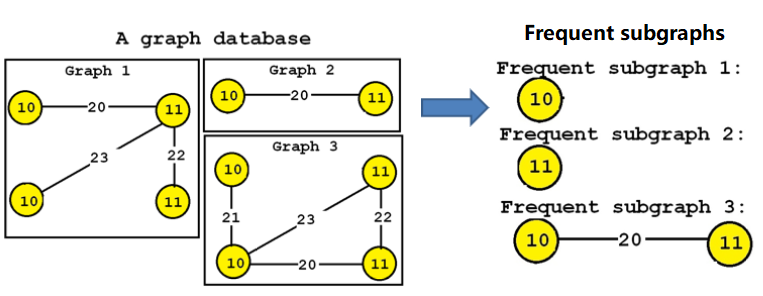
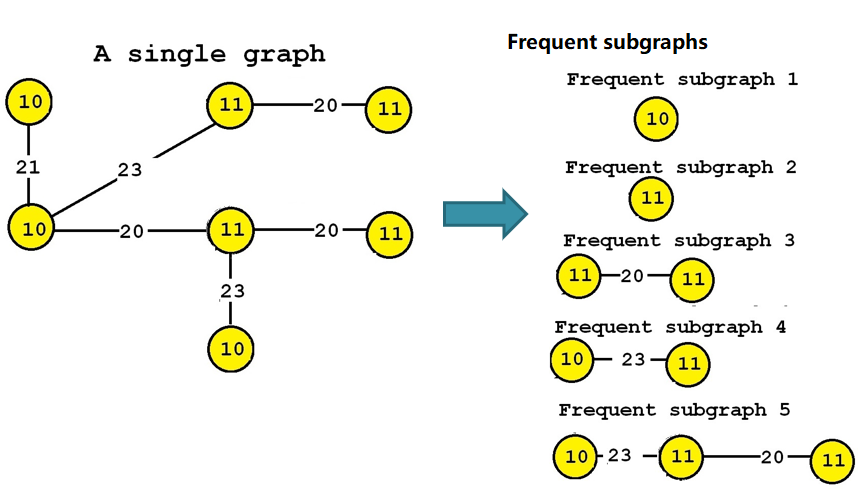
- frequent subtrees: the goal is to find trees that appear in many trees or many times in a large tree.
- dynamic patterns: various types of patterns can be found in a graph that is evolving over time such as trend sequences, attribute evolution rules, etc. Those patterns can reveal how a graph is evolving. Some recent algorithms are AER-Miner and TSeqMiner.
5.Finding Patterns in Time Series
Data description: Another type of data is time series. A time series is a sequence of numbers. It can be used to represent data such as daily weather observations about the temperature or wind speed, or the daily price of stocks. Here is some example of time series, where the X axis is time and the Y exist represents the temperature (celcius):
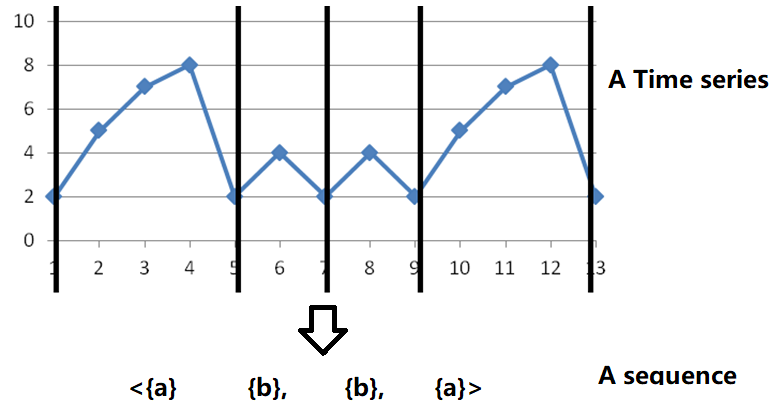
To analyse a time series, some methods like shapelet mining are specifically designed to analyze time series. They can find shapes that appear frequently in a time series. Another solution is simply to transform a time series into a sequence of symbols using an algorithm such as SAX, and then to apply an algorithm to find patterns in a sequence of records as previously described.
6. Some other variations
There are also several other data types that are variations of the ones that I have described above. A popular type of data in recent year is a table of record where attributes can have numeric values. For example, the database below show a transaction database with quantities:

This database can for example indicate what a customer has made five transactions (T1 to T5) in a retail store. For instance, the first transaction may indicate that the customer has purchased 1 unit of item a (apple) with 5 units of item b (bread), 1 unit of item c (cake), 3 units of item d, 1 unit of item e, and 5 units of item f. It is also possible to have another table to indicate the profit yield by the sale of each item such as below:

This table indicates that item a yields a 5$ profit, item b yield a 2$ profit and so on. By analyzing such database, it is possible for example to find a type all the sets of items purchased together that yield a lot of money. This problem is called high utility itemset mining and is actually quite general. It can be applied to other types of data as well, and can be generalized to sequences. Many researchers have been working on this topic in recent years.
Conclusion
In this blog post, I have given some overview of some main pattern mining problems for analyzing mainly symbolic data such as database of records, sequences of records, graphs and sequence databases.
If you are interested by this, you can consider using the SPMF open-source library that I have founded, which offers implementations of over 200 pattern mining algorithms: SPMF software/library. On the website, you can also find datasets to play with those types of algorithms.
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.




Pingback: A brief report about the IEA AIE 2020 conference | The Data Mining Blog
Pingback: Why Journal Special Issues are Popular? | The Data Mining Blog
Pingback: An Introduction to Episode Mining | The Data Mining Blog
Pingback: High Utility Itemset Mining with a Taxonomy | The Data Mining Blog
Pingback: An Introduction to High Utility Quantitative Itemset Mining | The Data Mining Blog
Pingback: Finding short high utility itemsets! | The Data Mining Blog
Pingback: Brief report about the DEXA 2021 and DAWAK 2021 conferences | The Data Mining Blog
Pingback: Towards SPMF v3.0… | The Data Mining Blog
Pingback: Common limitations of pattern mining papers | The Data Mining Blog
Pingback: What is a good pattern mining algorithm? | The Data Mining Blog
Pingback: Brief report about UDML 2021 (4th International Workshop on Utility-Driven Mining and Learning | The Data Mining Blog
Pingback: How many association rules in a dataset? | The Data Mining Blog
Pingback: Brief report about ADMA 2021 | The Data Mining Blog
Pingback: Brief report about the BDA 2022 conference | The Data Mining Blog
Pingback: Discovering the Top-K Stable Periodic Patterns in a Sequence of Events | The Data Blog
Pingback: An Introduction to Sequential Rule Mining | The Data Blog
Pingback: An Introduction to High-Utility Itemset Mining | The Data Blog
Pingback: Free Pattern Mining Course | The Data Blog
Pingback: Introduction to Rare Itemset Mining | The Data Blog
Pingback: Test your knowledge about pattern mining! | The Data Blog