
Today, I will talk a little bit about the recent improvements and future direction for the SPMF data mining library.

How SPMF started?
SPMF is a software project that I started around 2008 when I was a Ph.D student in Montreal, Canada. The short story of that software is as follows. I was taking a Ph.D course on data mining at University of Quebec at Montreal. For that course, I had to implement a few data mining algorithms as homework. I implemented some simple algorithms in Java such as Apriori and some code for discovering association rules. Then, I decided to clean the code, and add more algorithms during my free time, including those made for my PhD research. My idea was to make something for the pattern community in Java. In fact, most of the code that I could see online was written in C++… I wanted to change this so as to use my favorite language, Java. Besides, I wanted to share pattern mining code so that other researchers could save time by not having to implement again the same code. This is why all the code is open-source. Thus, it is around that time, in early 2009 that I created the website for SPMF and put the first version online. That version was simple. The code was not so efficient. Then, over the years the code has been optimized and more algorithms have been added, and luckily many researchers have joined this effort by providing code for many other algorithms such that today there are over 200 algorithms, many not available in other software programs. Besides, many other researchers have reported bugs and provided feedback to improve the software, which has been very useful to make the software very stable and bug-free. It is thanks to all contributors and SPMF users that the software is what it is today! Thanks!
What is the future?
The SPMF software is still very active. Just in the first eight months of 2021, about 20 algorithms have been added already. But there is many things to do to further improve the software:
- I have been working on a plugin system that is not finished but will likely appear in a future version of SPMF when it is stable enough. This will allow to download plugins as jar files from online repositories and integrate them with SPMF. I have some version that is almost working but I want to make sure it is well-tested before it is released.
- I also want to integrate some additional tools to automatically run experiments in SPMF to make it more convenient for researchers who want to compare algorithms.
- There is also a need to add more algorithms to SPMF. Initially, SPMF was focused on frequent itemset mining, association rules and sequential patterns. In recent years, I have added code for many other related topics such as periodic patterns, sequential rules, frequent episodes, class association rules, pattern mining with a taxonomy, quantitative itemset mining, sequence prediction, high utility itemset mining and subgraph mining. But there are still several interesting topics that are not covered in SPMF and I would like to add in the future. For this, I need your help 😊 If anyone has code of algorithms in Java that is well implemented, you may let me know, and I may try to integrate your code in SPMF. It is not something difficult and you can become a contributor of SPMF too 😊.
- I will eventually redesign the user interface to further improve it with more capabilities. The user interface has always been quite simple as the focus of the software is to provide an extensive library of algorithms. But it is perhaps time to add more functionalities to the user interface such to allow the user to combine several algorithms as a pipeline to process data, and to save that pipeline to a file.
Here is a picture of the system architecture of SPMF, including the planned plugin system:
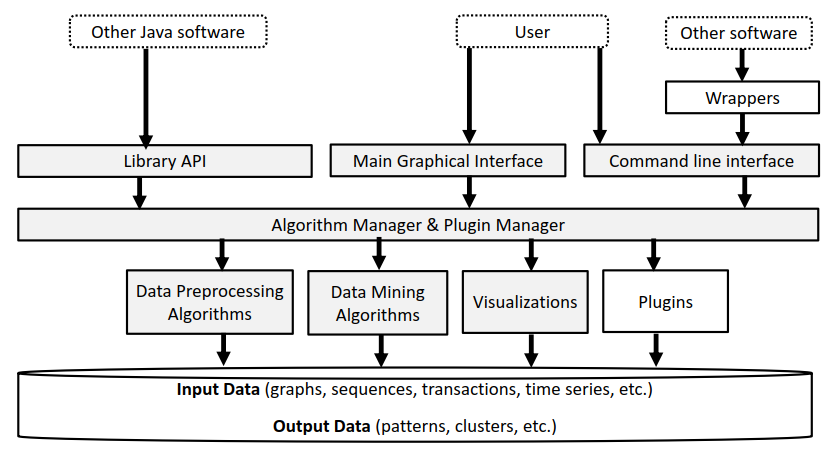
Next step: SPMF 3.0
It is already a few years that SPMF 2.0 was released. The next major version shall be SPMF 3.0 and hopefully it will be released early in 2022.
For SPMF 3.0, I will also publish a new research paper about SPMF. For the version 0.9, a paper on SPMF was published in the Journal of Machine Learning Research. For the version 2.0, I published a paper in PKDD 2016. For version 3.0, I will also make a paper for another top journal or conference. The people who have contributed the most to SPMF in recent years will be invited to co-author that paper (as much as possible due to limitations on the number of authors).
For those who have observed, the convention for numbering versions of SPMF have changed quite a lot over the years. At the beginning, I started at 0.49, and incremented the numbers by 0.01. But I did not want to reach version 1.0 too early, so I then started to add letters like 0.96b, 0.96c,… 0.96r and then even some numbers after that like 0.96r2, 0.96r3, 0.96r4 to stay away longer from 1.0. The last version before 1.0 was 0.99j. Then after that I jumped to version 2.0 for the PKDD paper, and now I continued as 2.01, 2.02… 2.50. The next jump will be to 3.0 in the next few months.
Conclusion
In this blog post, I have talked a little bit about the early development and future direction of SPMF. Hope it has been interesting!
Thanks again to all contributors and users of SPMF for supporting the software through all these years. I really appreciate your support.
—
Philippe Fournier-Viger is a distinguished professor of computer science and founder of the SPMF open-source data mining library, which offers over 200 algorithms for pattern mining.



