
In this blog post, I will talk about pattern mining (finding patterns in data) data mining task called episode mining. It aim at discovering interesting patterns in a long sequence of symbols or events. Sequence data is an important type of data found in many domains. For instance, a sequence can encode data such as a sequence of alarms produced by a computer system, a sequence of words in a text, and a sequence of purchases made by a customer. Using episode mining, patterns can be discovered in a sequence. These patterns can then be used to understand the data, and support decision making.

I will first define what is an event sequence. Then, I will introduce the basic problem of episode mining. Then, I will discuss some extensions and software for episode mining.
What is an event sequence?
An event sequence (also called a discrete sequence) is a list of events, where each event has a distinct timestamp. For example, consider the following event sequence:
<(t1, {a,c}), (t2, {a}), (t3, {a,b}), (t6,{a}),(t7,{a,b}), (t8, {c}), (t9, {b}), (t11, {d})>
In that sequence, each letter (a,b,c,d) is an event type and t1, t2, … t11 are timestamps. The above sequence indicates that event “a” and “c” occurred at time t1, was followed by event “a” at time t2, then by events “a” and “b” at time 3, then followed by event “a” at time t6, and so on. A visual representation of this sequence is shown below:
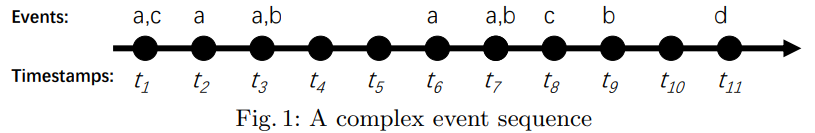
If an event sequence contains some events that occur simultaneously (have the same timestamp), it is said to be a complex event sequence. Otherwise, it is said to be a simple sequence.
As previously said, sequence data is found in many domains. For example, the above sequence could represent the purchases made by a customer in a store over time where “a”, “b”, “c” and “d” represents different types of products such as “apple”, “bread”, “cake” and “dattes”. Another example is a sequence of locations visited by a person in a city, where “a”, “b”, “c” and “d” could represent the home, a restaurant, the university and the gym. Another example is a sequence of words in a text, where “a”, “b”, “c” and “d” represent different words.
Frequent Episode mining
To analyze such sequence of events or symbols, a popular data mining task is frequent episode mining. The aim is to find all the episodes (subsequences of events) that appear frequently in a sequence over time. An episode is said to be frequent if it appears at least minsup times, where minsup is a parameter set by the user.
The task of finding these frequent episodes is called frequent episode mining. It was proposed by Toivonen and Mannila in 1995 to analyze alarm sequences in this paper:
Mannila, H., Toivonen, H., Verkamo, A.I.: Discovering frequent episodes in sequences. In: Proc. 1st Int. Conf. on Knowledge Discovery and Data Mining (1995)
Toivonen and Manila proposed two algorithms called WINEPI and MINEPI to discover frequent episodes (sets of events frequently appearing in an event sequences). These two algorithms have the same goal of finding episodes but these algorithms adopt different ways of counting how many times an episode appear. Thus, the output of the two algorithms is different. After the WINEPI and MINEPI algorithms were proposed, several other algorithms have been introduced to discover episodes more efficiently such as MINEPI+ and EMMA. Here I will explain the problem as it is defined for the EMMA algorithm. The paper proposing the EMMA algorithm is:
Huang, K., Chang, C.: Efficient mining of frequent episodes from complex sequences. Inf. Syst. 33(1), 96–114 (2008)
The goal of episode mining is to find frequent episodes. An episode E is a sequence of event sets of the form E = <X1, X2, . . . , Xp>. This notation indicates that a set of events X1 occurred, was followed by another set of events X2, and so on, and finally followed by a set of events Xp.
If we look at the sequence of Fig. 1 an example of episode is <{a},{a,b}> which contains two event sets: {a} and {a,b}. This episode <{a},{a,b}> means that the event “a” appears and is followed by the events “a” and “b” at the same time. This episode can observed many times in the example sequence of Fig. 1. Below, I have highlighted the six occurrences of that episode:
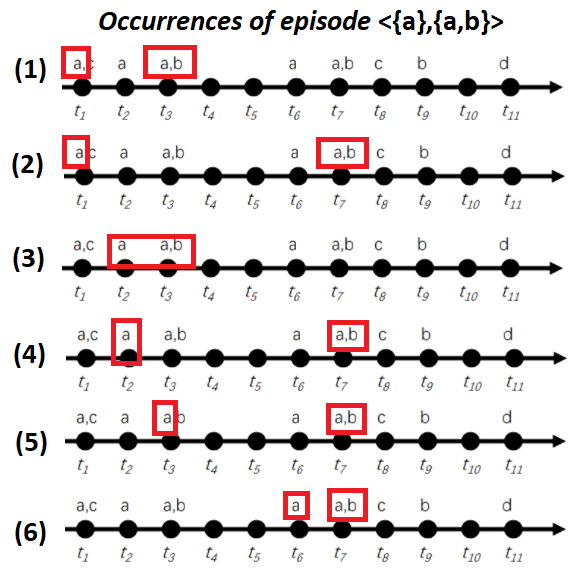
In the EMMA algorithm, the user must set two parameters to find frequent episodes. The first parameter is the window length (winlen). This parameter is used to filter out occurrences that are spanning over a too long period of time. For example, if the parameter winlen is set as winlen = 3, it means that we are only interested in counting the occurrences of episodes that last no more than 3 time units. In the above example, only three occurrences of episode <{a},{a,b}> satisfy this criterion:
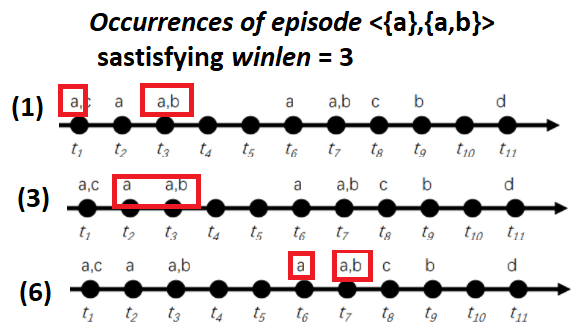
For instance the first occurrence (1) has a duration of 3 time units., while the occurrence (3) has a duration of two time units.
The second parameter that must be set to find frequent episodes in a sequence is called the minimum support threshold (minsup). This parameter indicates the minimum number of occurrences that an episode must have to be considered as a frequent episode. Let say that this parameter is set to 3. Then the goal of episode mining is to find all frequent episodes that have at least three occurrences having a duration that is no more than winlen. The number of occurrences of an episode is called its support.
Before showing an example, I should also say that the EMMA algorithm has a particular way of counting occurrences. It is that if two or more occurrences start at the same timestamp, EMMA will count this as only one occurrence. For example, the occurrences (1) and (2) of episode <{a},{a,b}> are counted as only one occurrence because they both start at the timestamp t1. It was argued in the paper of EMMA that this counting strategy is more appropriate than the counting methods used by MINEPI and WINEPI for real applications.
Now, let me show you what is the result of frequent episode mining with EMMA. For instance, if we apply EMMA on the above sequence with winlen = 2 and minsup = 2, the seven frequent episodes are discovered:

These frequent episodes indicate sequential relationships between events (or symbols) in the sequence. If we assume that the sequence of Fig. 1 is a sequence of events on a computer network, these patterns may be useful for someone doing the maintenance of the network, as it indicates for example that event “a” is often followed by events “a” or “b” within a short period of time.
An improvement: Top-K Frequent Episode Mining
Although frequent episode mining is useful, a problem is that it is not always intuitive to set the minsup parameter. For example, for some sequences setting minsup = 2 may result in finding only a few episodes while on other sequences, millions of episodes may be found for minsup = 2. But the user, typically dont have time to look at millions of episodes, and tuning the minsup parameter to just find enough episodes can be time-consuming (it is done by trial and error).
To address this issue, the task of frequent episode mining was recently redefined as the task of top-k frequent episode mining. Rather than using the minsup parameter, the user can direclty indicate the number of patterns k to be found, which is much more convenient and intuitive. The TKE algorithm is the first algorithm for discovering the top-k most frequent episodes in a sequence. It adopts the same definition of episode as the EMMA algorithm, which was presented above. But it let the user directly specify how many episodes must be discovered.
For example, if we run the TKE algorithm with k = 3 and winlen = 2, it is found that the top 3 most frequent episodes in the sequence of Fig. 1 are <{a},{a}>, <{a}> and <{b}>.
The TKE algorithm was presented in this paper:
Fournier-Viger, P., Wang, Y., Yang, P., Lin, J. C.-W., Yun, U. (2020). TKE: Mining Top-K Frequent Episodes. Proc. 33rd Intern. Conf. on Industrial, Engineering and Other Applications of Applied Intelligent Systems (IEA AIE 2020), pp. 832-845. [source code] [ppt]
An extension: Episode Rules
Although frequent episodes are interesting for some applications, it is sometimes more desirable for decision making to find patterns that have the form of a rule such as IF something happens THEN something else will happen.
To address this issue, several algorithms have been designed to find episode rules. The concept of episode rule is based on the concept of episode, as traditionally, episode rules are derived from frequent episodes. An episode rule was first defined by Manila and Toivonen (1995) as having the form X –> Y indicating that if an episode X is observed, it is likely to be followed by another episode Y.
To find interesting episode rules, several measures can be used. The two most popular are the support and confidence. The support of an episode rule X–> Y is the number of times that the rule appeared. The confidence of a rule X–> Y is the number of times that X is followed by Y, divided by the number of times that X was observed. Then, the task of episode rule mining is to find all the episode rules that appear at least minsup times and have a confidence that is no less than minconf, where minsup and minconf are parameters set by the user. Besides, as for frequent episode mining, it is expected that rules appear whithin a maximum window length (time duration) called winlen.
For instance, a rule can be <{a,b}> –> <{c}> indicating that event “a” and “b” appear together and are followed by “c”. If winlen = 2, then this rule has only one occurrence, shown below:

Thus, the support of that episode rule <{a,b}> –> <{c}> is said to be 1. Now, if we want to calculate the confidence of that episode rule, we need to also count the number of times that its antecedent, episode {a,b}, appears. There are two occurrences of episode {a,b}, displayed below:

The confidence of the episode rule <{a,b}> –> <{c}> is the number of times that <{a,b}> –> <{c}> appears divided by the number of times that <{a,b}> appears, that is 1 / 2 = 0.5. This means that 50 % of the times <a,b> is followed by <{c}>.
This is just a brief description of traditional episode rules. There is also another type of episode rules that has been recently proposed called partially-ordered episode rules and was argued to be more useful. The idea of partially-ordered episode rules comes from the observation that traditional episode rules require a very strict ordering between events. For example, the rule <{a,b}> –> <{c}> is viewed as different from <{a},{b}> –> <{c}>, or the rule <{b},{a}> –> <{c}>. But in practice, these three rules only have some small variations in the order between events, and may thus be viewed as describing the same relationship between events “a”, “b” and “c”. Based on this observation, the concept of partially-ordered episode rules was proposed. The aim is to simplify the rule format such that the ordering constraint between events in the left part of a rule is removed, as well as the ordering constraint between events in the right part of the rule. Thus, an episode rule has the form X –> Y where X and Y are two sets of events, but the events in X are unordered and the events in Y are also unoredered. For example, a partially ordered episode rule is {a,b} –> {c} which means that if “a” and “b” appear in any order, they will be followed by “c”. This rule replaces the three traditional rules mentioned previously and can thus provide a good summary to the user.
To discover episode rules, there are two ways. To discover traditional episode rules, the main approach is to first apply a frequent episode mining algorithms such as TKE, EMMA, WINEPI and MINEPI. Then, the episode rules are derived from these episodes by combining pairs of episodes. To discover partially-ordered episode rules, the process is slightly different. It is not required to first discover frequent episodes. Instead, rules are extracted directly from a sequence using a tailored algorithm such as POERM or POERMH. The POERM algorithm is presented in this paper:
Fournier-Viger, P., Chen, Y., Nouioua, F., Lin, J. C.-W. (2021). Mining Partially-Ordered Episode Rules in an Event Sequence. Proc. of the 13th Asian Conference on Intelligent Information and Database Systems (ACIIDS 2021), Springer LNAI, pp 3-15 [video] [software] [ppt]
High utility episode mining
Another popular extensions of the episode mining problem is high utility episode mining. This problem is a generalization of frequent episode mining where each event can be annotated with a utility value (a number indicating the importance of the event), and the goal is to discover episodes having à high utility (importance). An example of application of high utility episode mining is to find sequence of purchases made by customers that yield a high profit in a sequence of customer transactions.
If you are interested by this topic, you may check the HUE-SPAN algorithm which was shown to outperform previous algorithm. It is described in this paper:
Fournier-Viger, P., Yang, P., Lin, J. C.-W., Yun, U. (2019). HUE-SPAN: Fast High Utility Episode Mining. Proc. 14th Intern. Conference on Advanced Data Mining and Applications (ADMA 2019) Springer LNAI, pp. 169-184. [ppt] [software]
Software for episode mining
If you want to try episode mining with your data or do research on episode mining, the most complete software for episode mining is by far the SPMF data mining library.
SPMF is an open-source software implemented in Java, which has a simple user interface and can be called from the command line. Morevoer, there exists some unofficial wrappers to call SPMF from other programming languages such as Python. The SPMF library offers more than 200 algorithms for pattern mining, including a dozen algorithms for discovering frequent episodes such as TKE, MINEPI and EMMA, and also several algorithms for episode rule generation such as POERM. Besides, several algorithms for high utility episode mining are implemented such as HUE-SPAN.
SPMF also offers algorithms to find other types of patterns in sequences. For example, it is possible to find sequential patterns and sequential rules (patterns appearing in multiple sequences instead of only one sequence), and to find periodic patterns (patterns that are periodically appearing in a sequence). Other interesting tasks that can be done with a sequence is sequence prediction.
Conclusion
That is all for today. I just wanted to give a brief introduction about episode mining, as it is a fundamental task for analyzing sequences of events or symbols. If you have comments, please share them in the comment section below. I will be happy to read them.
—
Philippe Fournier-Viger is a full professor working in China and founder of the SPMF open source data mining software.




Pingback: An Introduction to Data Mining | The Data Mining Blog
Pingback: Key Papers about Episode Mining | The Data Mining Blog
Pingback: How many possible association rules in a dataset? | The Data Mining Blog
Pingback: How to draw a sequence in latex? | The Data Mining Blog
Pingback: Brieft report about the MIWAI 2022 conference | The Data Mining Blog
Pingback: Towards SPMF v3.0… | The Data Mining Blog
Pingback: (video) Introduction to episode mining | The Data Blog