
This week, I am participating to the KDD 2018 ( 24th ACM SIGKDD Intern. Conference on Knowledge Discovery and Data Mining), in London, UK from the 19th to 23rd August 2018.

The KDD conference is an international conference, established 24 years ago. It is the top conference in the field of data mining / data science / big data. The proceedings are published by ACM. This year, more than 3,000 persons were registered at the conference, which is huge. Many researchers from the industry are attending the conference. KDD was held at the Excel convention center:

Day 1 – Registration
On the first day, the registration started at 7:00 AM and the tutorials started at 8:00 AM. I arrived at around 7:45 and had to wait about 20 min in line to register. The problem was that there was hundreds of people who all wanted to register at the same time and maybe only six volunteers to serve them. Thus, several people arrived late at the tutorials. However, I don’t blame the organizers because this is something hard to avoid for such big conferences, and this year it is a record for attendance. This is the waiting lines:


The registration desk:

We receive a conference bag containing a USB stick with the proceedings, a pen, notebook and various promotional materials from businesses.
An APP called Whova was offered for our cellphones. This APP allows to see all the attendees from the conference, to create discussion groups and to see the schedule of the conferences. These three features are respectively shown in the three screenshots below.
Day 1 – Tutorials
After registration, I attended a tutorial about data mining in online retail stores, organized by JD.com (jingdong). I also attended a tutorial on fact checking in the afternoon and part of the workshop on explainable models for healthcare. Actually, there was more than 10 tutorials at the same and many seem interesting but I could not attend all of them!
Day 2 – The 1st International Workshop on Utility-Driven Mining (UDM 2018)
This year, I co-organized the first UDM 2018 workshop on utility mining. The workshop is about finding patterns in databases that have a high utility or importance (e.g. high profit). The workshop program included a keynote by Nitesh Chawla about decision-making, which was unfortunately cancelled due to unexpected events. However, we still had a great workshop with seven paper presentations. The published papers can be found on the workshop page. Among these papers, here is a brief description of some interesting ideas:
- A paper “Mining High Average-Utility Itemsets Based on Particle Swarm Optimization” by Song et al. proposed a swarm intelligence algorithm to solve the high average utility itemset mining problem.
- A paper “EHUSM: Mining High Utility Sequences with a Pessimistic Utility Model” by Tin Truong Chi et al. redefined the problem of high utility sequential pattern mining to use the minimum utility measure instead of the maximum utility measure. The idea is that measure provides a more pessimistic perspective, which may be more suitable for businesses.
- A paper “Discovering Low-Cost High Utility Patterns.” by Jiaxuan Li et al. was presented about measuring the cost of high utility patterns to find patterns that have a low cost (e.g. time, effort, money spent) but yield a high utility (e.g. profit). The paper defines three problems and a case study on e-learning where interesting patterns are found. The presenter is actually my student.
- A paper by Hong et al. about fuzzy itemset mining.
- A paper by Stirling et al. about profit-driven analysis for churn prediction using the EMP measure.
- A paper about pollution prediction in India using various features by Chaudary et al.
- A paper from a team of researchers at Toshiba by Maya et al. about transfer learning.
All the presentations have been recorded and will be made available online in the future. Besides, a special issue in a Springer journal is being organized for the best papers, and a Springer book is planned for the proceedings of the workshop.
Day 2 – Opening ceremony
The opening ceremony was also on the second day. Here is some pictures about the location and some interesting slides about the conference.




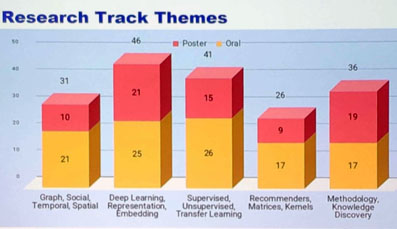
Some statistics about the “Applied data science” track:
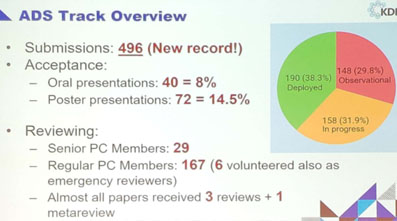
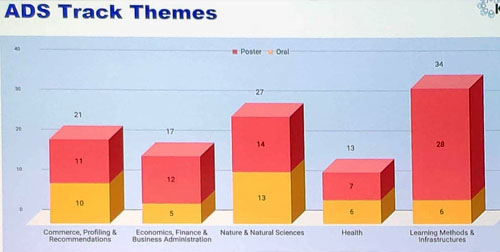
Day 2 – poster session
On the evening of the second day, there was also a poster session, which is always good to meet new researchers and have research discussion.

Day 2 – Evening with Jingdong
I was invited to a special private event, which is an evening with JD.com (jingdong). JD.com is one of the top online retail company in China, and also one of the biggest technology company in the world. There was a panel with several high profile researchers such as Philip. S. Yu, Jiawei Han, Jian Pei, and Christos Faloutsos, as well as presentations of research and products at JD.com. Moreover, there was live music, a dinner and drinks. I had good discussions with people from JD.com and it allowed to establish several relationships with people from JD.com. I am quite impressed with what they are doing. A few pictures from that event:





Day 3 – Deep learning with Keras, hands-on tutorial by Google
I attended this event to see what is going on in the deep learning area. But I was disappointed by this event. I arrived 30 minutes before to reserve a seat and then realized that we had to download about 5 GB of material for the tutorial on our laptops. This was however not possible on a 40 k/s WIFI connection. I expected that I could at least look at some live demo or tutorial on the screen. But that was not the case. The presenter basically just talked for five minutes with maybe 5 slides, and then let everyone work by themselves (which we could actually do by ourself at home). After 1 hour, it was now clear that the presenter would not do any live demo or explain much on the screen. Thus, I left. Here is a picture from that tutorial:

Day 3 – Panel on what is a data scientist
I attended a panel discussion about what is a data scientist with panelists from both academia and the industry.

I noted a few key points of that discussion, which I report below. Hopefully, my notes are accurate 😉
- Hamit Hamotcu (Analytics center):
- There is some confusion and many different titles. Some people are even using the same title in the same company but have very different backgrounds such as a bachelor in economics with an online degree in data science, and a PhD. in machine learning. These persons are certainly not doing the same thing.
- Ravi Kumar (Google):
- Data scientist may be a casual term that is more general than other terms like machine learning expert.
- Kjersten Moody (State Farm Insurance):
- Data analyst is more about reporting.
- Narendra Mulani (Accenture):
- At Accenture, “data scientist” is defined using a set of competencies. If Accenture recruits someone having a software engineering, optimization, or machine learning background, Accenture will then help him develop his competencies with time and training to turn him into a data scientist.
- He would like that curriculum are standardized across universities.
- Claudia Perlich (Two Sigma):
- She do not want to debate what is or not is a data scientist. She is more interested that the “stuff” can gets done.
- Jeanette Wing (Columbia University):
- It is not good to have a plethora of titles that are meaningless. There should be some effort to standardize the titles. There should be some dialogue between industry and academia to achieve that.
- “To be honest, I don’t know what is the difference between data scientist, data analyst, data engineer, etc. ” But in their program, they have computer science courses (machine learning, computer systems, distributed systems etc.) and others about statistics. Data science is more than an agglomeration of computer science and statistics. Students in their program must do a project with real data.
- There are now over 200 programs in data science in the US. We should have some minimum requirements about what is the skillset of a data scientist. The ACM is interested in coming up with a standardized curriculum.
- Some people from Spotify in the audience:
- What is the difference between “Research scientist” and “Data scientist”?
Location of KDD 2019 and KDD 2020
It was announced that KDD 2019 will be held in the city of Anchorage (Alaska), USA. Then, KDD 2010 will be held in San Diego, USA. In other words, the two next KDD conferences will be in the USA. Personally, I would have prefered that it would be in different countries.
Day 4
On the fourth day, there was again several activities and talks. In the afternoon, I attended the presentation of a company called Yixue which has an intelligent e-learning system for students in China. Their system is quite impressive.
Then, in the evening I attended the banquet. It was a buffet. It was reasonably good but the choice of food was quite limited. But the most important is that I had some good discussions with other researchers.
Then, after the banquet I went to a cocktail organized by a leading artificial intelligence company from Montreal, Canada called Element AI at an hotel nearby. This was a great event.
Day 5
On the fourth day, there was again more talks. I also visited again the exhibition of company products. Then, this was the end of the conference.
Conclusion
Overall, this was a great conference. For me, what I like about KDD is that there are many companies. For those in academia, it is good to see what is happening in the industry, and for those from the industry, it is good to learn about the latest research from academia. Besides, KDD is so big that it is possible to talk with many researchers.
Hope you have enjoyed reading this post. In about 1 week, I will be going to the DEXA and DAWAK conferences. I will also write blog posts about these conferences. Then, later this autumn, I should attend the ICDM conference.
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 150 data mining algorithms.




Pingback: Brief report about UDML 2021 (4th International Workshop on Utility-Driven Mining and Learning | The Data Mining Blog
Pingback: The Upcoming 3rd Utility Mining and Learning Workshop (UDML 2020!) at IEEE ICDM 2020 | The Data Mining Blog
Pingback: Expensive Academic Conferences – the case of ICDM | The Data Mining Blog