
In this blog post, I will give an introduction about a popular problem in data mining, which is called “high-utility itemset mining” or more generally utility mining. I will give an overview of this problem, explains why it is interesting, and provide source code of Java implementations of the state-of-the-art algorithms for this problem, and datasets.
Frequent itemset mining
The problem of high-utility itemset mining is an extension of the problem of frequent pattern mining. Frequent pattern mining is a popular problem in data mining, which consists in finding frequent patterns in transaction databases. Let me describe first the problem of frequent itemset mining
Consider the following database. It is a transaction database. A transaction database is a database containing a set of transactions made by customers. A transaction is a set of items bougth by the customers. For example, in the following database, the first customer bougth items “a”, “b”, “c”, “d” and “e”, while the second one bougth items “a”, “b” and “e”.
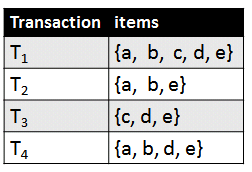
A transaction database
The goal of frequent itemset mining is to find frequent itemsets. Many popular algorithms have been proposed for this problem such as Apriori, FPGrowth, LCM, PrePost, FIN, Eclat, etc. These algorithms takes as input a transaction database and a parameter “minsup” called the minimum support threshold. These algorithms then return all set of items (itemsets) that appears in minsup transactions. For example, if we set minsup = 2, in our example, we would find several such itemsets (called frequent itemsets) such as the following:
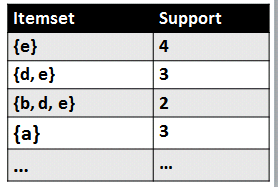
some frequent itemsets
For example, consider the itemset {b,d,e}. It is said to have a support of 3 because it appears in three transations, and it is said to be frequent because the support of {b,d,e} is no less than minsup.
Frequent itemset mining has some important limitations
The problem of frequent itemset mining is popular. But it has some important limitations when it comes to analyzing customer transactions. An important limitation is that purchase quantities are not taken into account. Thus, an item may only appear once or zero time in a transaction. Thus, if a customer has bougth five breads, ten breads or twenty breads, it is viewed as the same.
A second important limitation is that all items are viewed as having the same importance, utility of weight. For example, if a customer buys a very expensive bottle of wine or just a piece of bread, it is viewed as being equally important.
Thus, frequent pattern mining may find many frequent patterns that are not interesting. For example, one may find that {bread, milk} is a frequent pattern. However, from a business perspective, this pattern may be uninteresting because it does not generate much profit. Moreover, frequent pattern mining algorithms may miss the rare patterns that generate a high profit such as perhaps {caviar, wine}
High-utility itemset mining
To address these limitations, the problem of frequent itemset mining has been redefined as the problem of high-utility itemset mining. In this problem, a transaction database contains transactions where purchase quantities are taken into account as well as the unit profit of each item. For example, consider the following transaction database.
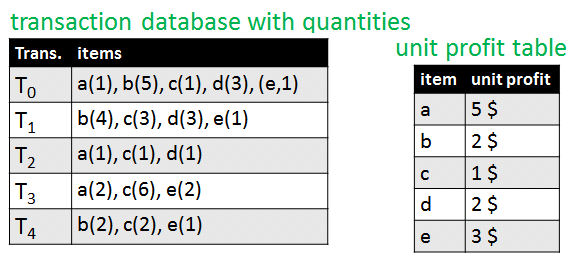
a transaction database with quantities and unit profit information for items
Consider transaction T3. It indicates that the corresponding customer has bougth two units of item “a”, six unit of item “c”, and two units of item “e”. Now look at the table on the right. This table indicates the unit profit of each item. For example, the unit profit of items “a”, “b”, “c”, “d” and “e” are respectively 5$, 2$, 1$, 2$ and 3$. This means for example, that each unit of “a” that is sold generates a profit of 5$.
The problem of high-utility itemset mining is to find the itemsets (group of items) that generate a high profit in a database when they are sold together. The user has to provide a value for a threshold called “minutil” (the minimum utility threshold). A high-utility itemset mining algorithm outputs all the high-utility itemsets, that is those that generates at least “minutil” profit. For example, consider that “minutil” is set to 25 $ by the user. The result of a high utility itemset mining algorithm would be the following.

high-utility itemsets
For example, consider the itemset {b,d}. It is considered to be a high-utility itemset, because it has a utility of 40$ (generates a profit of 40$), which is no less than the minutil threshold that has been set to 25$ by the user. Now, let’s look into more detail about how the utility (profit) of an itemset is calculated. In general, the utility of an itemset in a transaction is the quantity of each item from the itemset multiplied by their unit profit. For example, consider the figure below. The profit of {a,e} in transaction T0 is 1 x 5 + 1 x 3 = 8 $. Similarly, the profit of {a,e} in transaction T3 is 2 x 5 + 2 x 3 = 16 $. Now, the utility of an itemset in the whole database is the sum of its utility in all transactions where it appears. Thus, for {a,e}, its utility is the sum of 8$ + 16 $ = 24$ because it appears only in transactions T0 and transaction T3.

illustration of how to calculate the utility of itemset {a,e}
Why the problem of high-utility itemset mining is interesting?
The problem of high-utility itemset mining is quite interesting for the following reasons.
First, it may be more interesting from a practical perspective to discover itemsets that generate a high profit in customer transactions than those that are bougth frequently.
Second, from a research perspective, the problem of high-utility itemset mining is more challenging. In frequent itemset mining, there is a well-known property of the frequency (support) of itemsets that states that given an itemset, all its supersets must have a support that is lower or equal. This is often called the “Apriori property” or “anti-monotonicity” property and is very powerful to prune the search space because if an itemset is infrequent then we know that all its supersets are also infrequent and may be pruned. In high-utility itemset mining there is no such property. Thus given an itemset, the utility of its supersets may be higher, lower or the same. For example, in the previous example, the utility of itemsets {a}, {a,e} and {a,b,c} are respectively 20 $, 24$ and 16$.
In this blog post, I will not go into the details of how the high-utility itemset mining algorithms work. But a key idea is to use upper-bounds on the utility of itemsets that restore the anti-monotonicity propety to be able to prune the search space. This will be the topic of a future blog post.
Open-source implementations and datasets
There exists several algorithms for high-utility itemset mining that have been proposed over the year. Java implementations of the state-of-the art algorithms are currently offered in my open-source data mining library named SPMF. It offers for example, source-code of Two-Phase (2005), UPGrowth (2011), HUI-Miner (2012) and FHM (2014). To our knowledge, FHM is one of the fastest algorithm for this problem. It was shown to be up to six times faster than HUI-Miner, which was shown to be up to 100 times faster than UPGrowth, which was shown to be up to 1000 times faster than Two-Phase. You can try FHM and the other above algorithms by going to the SPMF website. On the website, you will find instructions about how to run algorithms and some datasets on the dataset page. Update: Recently, the EFIM algorithm was proposed and was shown to outperform FHM by up to 1000 times, and is also offered in SPMF.
SPMF also offers many other algorithms to identify other pattern types such as sequential rules, sequential patterns, frequent itemsets and high utility itemsets.
Note that there also exists several variations of the problem of high-utility itemset mining, which I will not cover in this blog post.
To know more: key papers, glossary, and video lectures
You may also be interested in reading my list of key research papers on high utility itemset mining and the glossary of high utility itemset mining, or watch my video lectures on this topic.
Conclusion
In this blog post, I tried to give an overview of the problem of high-utility itemset mining. Hope that you enjoyed it. I will try to keep posting blog posts such as this one about interesting data mining problems in the future. Hope that you enjoyed reading 😉
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.




Dear Prof. Philippe,
Thank you for your effort and time to write this post which provides a clear and informative introduction of HUIM. It is really useful for people who initially do research on this problem.
Recently, many variations of frequent itemsets have been proposed such as high-utility itemsets, erasable itemsets, top-rank-k frequen itemsets, and so on. Do you think frequent itemset mining and its extension is still a hot and common topic with a high potential of publication in good journals/conferences?
Best,
Dang Nguyen
Hi Dang,
Glad you enjoy this blog post. I’m thinking about writting a Part 2 on utility mining in the future.
I think that it depends. To publish in a good journal/conferences, novel ideas need to be shown. A work that is “incremental” (just combine two ideas in a straightforward way, will usually not be accepted in a good conference and journals. For example, I personally don’t like the problem of erasable itemset because it is not a challenging problem. I had implemented one algorithm for SPMF and it is basically the same thing as Apriori, whithout any challenge. I did not read the recent paper on that topic, but at least the one that I read was straigthforward. In my opinion, high utility mining is probably the best topic among those. It offers some new challenges because we need to use upper-bounds to solve the problem. Of course, it is still possible to do some incremental work on this topic which are not important. But there is also potential to create something new.
Another possibility is to create some new problems related to pattern mining and show that they are useful and have some real applications (it would be better).
So I would say, it depends more on what you can do on the topic than the topic itself and some topics are more challenging. Going for a more challenging topic is always better, because it raises challenges and at the same time force to think about new solutions.
Best,
Philippe
Dear Prof. Philippe,
Thank you for sharing your opinion. I totally agree that publishing papers in high quality journals/conferences often requires novel ideas and significant contributions. That is also one of my goals during my PhD tenure ahead 🙂
Recently, I am working on the problem of frequent subgraph mining. It would be great if you post an overview of this topic.
Looking forward to reading the part 2 and hope to see you one day 🙂
Best,
Dang Nguyen
Hi Dang,
You are welcome. Thanks for reading and commenting on the blog 😉
Subgraph mining looks like a good topic. Graph are a more complicated structure than transactions so there should be more challenges than something more simple like itemset mining. Also, there are less work on subgraph mining in my opinion than itemset mining, so many problems have not been solved for graphs.
I’m not an expert on graph mining. I have only read a few papers on this topic.
If you are in Vietnam and want to meet me, I will be at PAKDD 2015 in Ho Chi Minh City for a week in May. Are you in that city? or will you attend this conference?
Best,
Philippe
hello sir ,
I’m little bit confused because i want to do my M-Tech final year project in data mining so as u said high utility item set mining is better to go with or subgraph mining is good what is the complexity of each of the topic and which topic will be welcome by the experts
How complex depends on what you want to do in these research area and how difficult depends also on your background. I would say that you should rather choose a topic that you like.
sir can i get some input from u regarding subgraph mining
i searched for a title ,your post is helped me thanks …
Dear Sir,
Can u give me some challenging problems in high utility itemset mining/ high utility sequential pattern mining. Actually I inspired by your research in high utility itemset mining.So I have chosen HUI as my research topic, but now I am unable to define problem statement in it.So Plz Sir can u help me to identify challenging problem in HUI
Hi, There is a lot of possible problems on this topics. You can actually combine high utility itemset mining with any other topic from pattern mining to create a new topic. For example, authors have previously combined high utility itemset mining with top-k pattern mining to do top-k high utility pattern mining. This is an example. But you can combine any topic with high utility pattern mining to create a new topic.
Best,
Can u give more details about upper bound of HUI
It would be a little bit long to explain. I would need to write another blog post on this topic but I don’t have time now. Maybe i’ll do it later.
The main idea is that unlike the support, the utility is not anti-monotonic. Thus, the supersets of an itemset may have a utility that is the same, lower or higher. For this reason, the utility cannot be directly used to prune the search space. To avoid this problems, high utility itemset mining algorithms introduces some upper-bounds. For example, if you read the Two-Phase paper, you will see that they are using the TWU upper bound. The TWU is a measure that is always equal or greater than the utility. This is why it is called an upper-bound. Why is it interesting? Because the TWU is anti-monotonic. Thus it can be used to prune the search space. Besides, the TWU, better upper-bounds have been introduces. For example, in HUI-Miner and FHM, the “remaining utility” is used to calculate an upper-bound
Best,
Thank u so much for your reply sir, which helps me a lot. Sir, I need some more information about HUI like combinations of HUI. Can you give details about it. I need a specific problem related to it.Plz help me Sir
To find topics that are combinations, you would need to search for some papers on pattern mining such as itemset mining and see what has not been done in high utility mining. I cannot really do that for you because it takes time, I’m busy, and actually I can only do that for my own students.
Dear Sir,
Thank you for such an informative blog. I am doing my research in utility mining. Your blog and your SPMF is really helpful. Thanks for your wonderful contribution.
I also request you to post more blogs related to negative utility, on shelf utility, incremental utility etc.
Sir, Can you list any other tools to calculate high utility itemset.
Thanks.
Hi, Thanks for reading the blog and commenting. Glad you like it and you are using SPMF. Ok. I will try to write more about high utility pattern mining in the future. As you have seen, I have worked quite a lot on this topic in the recent years, so yes, I could write more on this topic. Now, I’m a little bit busy, but in the next few weeks I might have time for putting more content on this topic. I will remember that request.
Best regards
Dear authors, anyone able to give me suggestion for finding complexity of algorithms used in utility mining, I.e. UP GROWTH, UPGROWTH + etc etc
Dear Sir,
How we differentiate utility mining algorithms like UP Growth, UP Growth + etc etc as in P,NP , NP complete or NP Hard?
If there is no complexity analysis provided in the paper, you may do your own analysis of the complexity of these algorithms. Personally, I don’t have time to do it. Some algorithms like UPGrowth are based on FPGrowth so you could check the complexity of FPGrowth which has likely been analyzed.
TwoPhase is based on Apriori. You may get a discussion of the complexity of Apriori here:
M. Hegland, “The Apriori Algorithm – A Tutorial”, Mathematics and Computation in Imaging Science and Information Processing, vol. 11, pp. 209-262, World
Scientific Publishing Co., 2007.
The EFIM algorithm which is the fastest high-utility itemset mining algorithm, do most of its operations in linear time for each pattern in the search space. Thus its complexity is roughly linear with the number of patterns in the search space.
Thank you so much for your reply…
Pingback: Brief report about the 12th International Conference on Machine Learning and Data Mining conference (MLDM 2016) - The Data Mining & Research Blog
Pingback: Brief report about the 16th Industrial Conference on Data mining 2016 (ICDM 2016) - The Data Mining & Research Blog
Respected Sir,
it is really nice post.
thanks for clearing very broad topic with few words
thank you so much sir.
sir now i am going to start one project for mtech can you please guide me which topic should i prefer.
I searched many IEEE paper regarding high utility mining.
sir can you please suggest.
Thanks and Regards
Hi,
Glad you like this blog post and that it has been useful.
I think that you could start from the source code of high utility mining algorithms in SPMF. You will then save a lot of time because many algorithms are already implemented and you also have the datasets for doing experiments on the website. Some topics ideas could be to modify the algorithm to add some novel ideas. For example, here are some possibilities:
– adapting FHM or EFIM to discover rare high utility itemsets by combining ideas from rare itemset mining with high utility mining
– adapting HUSRM for mining high utility sequential rule with a windows constraint by combining HUSRM with ideas similar to TRuleGrowth
– adapting the EFIM algorithm for mining the periodic high utility itemsets
– adapting HUSRM for top k high utility sequential rule mining
….
There are a lot of possibilities. I have just listed a few examples.
Philippe
What are the applications of high utility itemset mining, how it is used in that applications?
Hi, The most important application of high utility itemset mining is to analyze customer transaction data. For example, if you have a database of customer transactions, where each transaction indicates the items bought in a store by a customer, you can find the itemsets that generates the most money using high utility itemset mining. This is interesting from a marketing perspective. For examle, if you know that the itemset {tomato,cheese,pita} generates a lot of money, the retail store manager may consider co-promoting these products or offering some discount to try to sell even more of these products. So basically, it can be used to analyze customer behavior by finding the most profitable itemsets. Then, this information can be used to take decision such as decisions related to marketing.
High utility itemset mining could also be used in other domains. For example, let’s say that you have a factory where each part of some products has a cost. Then assume that some machines assemble the parts to build some products that are sold. You could use high utility itemset mining to find the sets of parts that are the most costly. Then, knowing these, you could try to replace these sets of parts by a single part that is cheaper to produce to reduce the cost of building products. This is just some example that I thought about right now. If you use your imagination you can transpose high utility mining to other problems. For example, in some papers about high utility itemset mining, people often cite that it has been also applied in bioinformatics and for analyzing web page click streams. I did not read these papers though. But you could find them.
Hope this answers your question.
Thank you for your answers. I understood that concept sir. High utility itemset mining used in bioinformatics and web page click streams, i search some papers, but i do not get any description, how it is used, send me the related papers , so kindly send me any papers are there.
Some reference are: “mobile commerce (Tseng et al, 2013), click stream analysis (Ahmed et al, 2010; Thilagu et al, 2012), biomedicine (Liu et al, 2013) and cross-marketing (Ahmed et al, 2009; Tseng et al, 2013).”
Tseng VS, Shie BE, Wu CW, Yu PS (2013) Efficient algorithms for mining high utility itemsets from transactional databases. IEEE Transactions on knowledge and data engineering, 25(8):1772–1786
Ahmed CF, Tanbeer SK, Jeong B (2010) Mining High Utility Web Access Sequences in Dynamic Web Log Data. Proceedings of the international conference on software engineering artificial intelligence networking and parallel/distributed computing, IEEE, London, UK, June 2010, pp. 76–81
Thilagu M, Nadarajan R (2012) Efficiently Mining of Effective Web Traversal Patterns With Average Utility. Proceedings of the international conference on communication, computing, and security, CRC Press, Gurgaon, India, September 2016, pp. 444–451
Liu Y, Cheng C, Tseng VS (2013) Mining Differential Top-k Co-expression Patterns from Time Course Comparative Gene Expression Datasets. BMC Bioinformatics, 14(230)
Ahmed CF, Tanbeer SK, Jeong BS, Lee, YK (2009) Efficient tree structures for high-utility pattern mining in incremental databases. IEEE Transactions on Knowledge and Data Engineering 21(12):1708–1721
I did not read these papers recently, so you may have a look by yourself to see the content.
Sir i have one doubt, in utility mining, utility means importance or profitable to whom sir either user or vendor. I hope profitable to the vendor, it is correct or wrong sir. give me some example sir
Hello, Normally, it is understood as profitable to the vendor. A high utility itemset is an itemset that generates a lot of profit for the vendor (the retail store).
But high utility itemset mining is a quite general problem. Basically you have a transaction database that contains transactions with quantities, and where items have unit profit values. You can always transpose this problem to other domains. As I answered you to your other message, it can also be applied to other domain. So, i think it would be possible to also apply it for finding patterns in terms of money saved by the customer, rather than the profit obtained by the vendor. In that case, instead of having profit value for each item, we would store the amount of money saved by a customer for each item bought. The database would hence be different.
Sir, it is good idea sir, please send me one related paper on finding patterns interms of money saved by the customer rather than profit obtained by the vendorn and the related dataset. Give me some examples also sir.
You can find papers on Google Scholar.
what is utility itemset mining with negative item values? give some examples sir. Where it is used?
In high utility itemset mining, it is assumed that all items have positive utility values. If we consider applying high utility itemset mining to analyze a customer transaction database, this means that all items must always generate a positive profit. So for example, if a retail store sell some apples, tomatoes, some milk, etc., or any other items, it must always generate a positive profit.
But this assumption is not realistic in real-life retail store. For example, many big stores such as Wal-Mart and others will sell products at a loss. This means, that they will maybe sell you some milk and lose money (the profit will be negative). The reason is that by selling products at a loss, they will try to make you come to their store and hope that you will buy other more expensive products. If you apply traditional high-utility itemset mining algorithms on a database that contains negative unit profits, it was shown that these algorithm can generate an incorrect result. Thus, some algorithms such as FHN have been designed to discover high utility itemsets in databases which contain positive and negative profit values.
The link for downloading the conference paper about FHN is here:
http://www.philippe-fournier-viger.com/FHN.pdf
Besides, you can find the source code here:
http://www.philippe-fournier-viger.com/spmf/
And if you want more information, send me an e-mail at philfv8 AT yahoo.com and I will send you a copy of the longer journal paper about FHN that will be published in the Knowledge-Based Systems journal (about 30 pages).
Hai sir
It is some what difficult for me to understand FHN, please provide me some more information to understand FHN(High utility itemset mining with negative item values) with examples. I sent a mail to you sir.
I sent you the journal paper of FHN to your e-mail. You may read it.
my mail id is: srinumtechcse2007@gmail.com
what is the difference between real,synthetic, sparse, dense datasets?
A real dataset is some data that come from the real-life. For example, it can be some data from a retail store.
A synthetic dataset is some fake data. The dataset has been generated just for the purpose of comparing algorithms. Using synthetic dataset is useful for comparing algorithms because you can increase the size of the dataset for example to see how they perform when the size increase or other characteristics are changed.
A sparse dataset is a dataset where entries (records) are not very similar with each other. For example, let’s say that you have some data from a retail store and few customers buy the same thing.
A dense dataset is a dataset where entries (records) are highly similar. For example, let’s say that you have data from a retail store and that everybody buy almost the same thing all the time.
Typically, when comparing the performance of algorithms (especially for itemset mining and other pattern mining problems), researchers will use both dense and sparse datasets.
Thank you for your reply sir. It is very useful for me for comparing algorithms.
how can you obtain datasets for high utility itemset mining with or with out negative values. In spmf, i am not getting full description of the datasets with attribute values, where we are getting datasets with full description such as records,attributes.
If you want real shopping data with attribute values, you could look at the Foodmart and Chainstore datasets. Chainstore comes from a database provided with MySQL 2000, while Foodmart comes from the NU MineBench software. On the SPMF website they do not contains attribute values because we have converted these databases to text file. But you could download the original databases and check the attribute values.
Note that these two datasets have utility values, but may not have negative values, though.
As for how to obtain MySQL 2000 and NUMinebench you can look on Google. I don’t have any information about how to use them and how they were converted to text file.
What is the difference between on-shelf utility mining and periodic utility mining? both are same or not. In both we are considering time periods.
No, they are different. If you read the papers you will find the problem definition of both of these papers.
Periodic: try to find something that appears periodically: e.g. a customer buy bread every week
On shelf: the goal is different. The idea is to find what makes the most money as in high utility itemset mining. But it consider the fact that some items are for example only sold during the summer. Thus it consider the shelf time of items when calculating the utility. It consider time but the itemsets found are not necessarily periodic. That is not the goal.
is on-shelf high utility itemset mining is advanced to high utility itemset mining? i hope that my answer is yes. is it correct or not sir?
Yes, it can be seen as an extension of high utility itemset mining
Dear Sir,
First of all I thank you for your formative blog. I am doing my research in utility mining.
I would like to know about post utility mining methods i.e after retrieving high utility itemsets. This would help me in my research work. Thanks in advance.
Hello,
Glad you like the blog 😉 I don’t know much work on post utility mining, so I think that you have chosen a good topic. It could be about how to vizualize the itemsets. If you search a little bit about itemset mining in general, association rules and other kinds of patterns, you will see that there are some works about how to visualize the patterns found. This is something that you could do for high utility itemsets. Besides that, it is certainly possible to use the itemset found in other ways for some specific application domains. For example, once the high utility itemsets are found, they could be used for classification, recommendation, etc. But I did not see much work on that. So If you work on this, I think you have many possibilities.
Regards,
Thank you for your suggestion sir. I planed to choose classification based on association rules. Could you please suggest me, what is the purpose of classification based on association rules? and Why we need to classify the rules.
Classification is when you have a set of instances and you want to determine to which class they belong to.
For example, if you have data about some bank customers, you may want to predict if some new customers will belong to the class “good customer” or “bad customer that go bankrupt”.
In classification by association rules, you do not classify the rules. You are classifying the instances.
For example, if you have a database about bank customers where you have several attributes such as age, gender, income / year, etc., you could extract some association rules from this database that are specific to the class “bad customer” or “good customer”
Then you could use these rules to classify some new instances (customers) as either good or bad customers.
This is the main idea about classification in data mining. We do not classify the rules. But we use the rules for performing classification. There are a lot of other classification models by the way such as decision trees, neural networks, etc.
Thank you very much sir.
Dear sir,
I am not good at programming but highly interested in utility mining. Could you please suggest some areas that doesn’t need implementation.
Hello,
If you do not want to do programming, then the only thing that you could to is apply the existing algorithms on some data to get the result. You can try different algorithms and see what kind of results they generate for your data.
This can be interesting from an application perspective.
However, if you are looking for a project for a master degree in computer science, I would not consider this as a good project because a master degree in computer science should involve programming.
Best,
Philippe
Hello,
Thanks for this blog post.
Just wondering the scalability of FHM algorithm : is it fine to run on 100millions transaction dataset at reasonable memory/computation time?
Thanks
Hello,
It would be better to use the EFIM algorithm, which is faster than FHM and uses less memory.
I am not sure that it would support 100 millions transactions. But you could try with a subset. For example, you might use a week long of transactions or a month instead of using the full dataset, or you could use sampling if needed to reduce the size of the dataset.
Besides, the performance of the algorithm actually depends on the “mininum utility” parameter. The lower the parameter is set, the more difficult the task becomes. For this type of problem, if you had 100 VERY long transactions, if you set the parameter very low, it may never be able to terminate because of the extremely large search space, but it may also run on millions on transactions without problems if the parameter is higher. So, what I mean is that it depends on the parameter. The search space can increase exponentially when the parameter is lower.
In experiments described in the research paper, we run these algorithms on about 1 million transactions from a retail store. So I am confident that it could run on a least 1 million transactions.
By the way, if you want to use this in a live environment, there is many way that the algorithm could be tweaked to improve performances depending on your need. For example, if you add some additional constraints such as a length constraint, the algorithm will become much faster. Besides, the algorithm could be rather easily parallelized if needed.
Best regards,
Dear sir,
Could you please suggest applications of utility mining in banking industry. Which property can be taken as utility measure? Thanks in advance.
Thank you so much sir..
your way of explanation is too good
Thanks. Glad you like it.
Pingback: Report about the DEXA 2018 and DAWAK 2018 conferences - The Data Mining BlogThe Data Mining Blog
Pingback: A brief report about the Big Data Analytics 2019 conference (BDA 2019) | The Data Mining Blog
Pingback: Report about the 2018 International Workshop on Mining of Massive Data and IoT | The Data Mining Blog
Pingback: Report about the ICGEC 2018 conference | The Data Mining Blog
Pingback: A Brief Report about the IEEE ICDM 2020 Conference | The Data Mining Blog
Pingback: An Overview of Pattern Mining Techniques (by data types) | The Data Mining Blog
Pingback: A Brief Report about ACIIDS 2021 (13th Asian Conference on Intelligent Information and Database Systems) | The Data Mining Blog
Pingback: Approximate Algorithms for High Utility Itemset Mining | The Data Mining Blog
hello dear sir,
plz explain me the concept of one phase and two phase in High utility item sets mining but not the difference? because i know that in two phase algorithms the TWU is calculated in first phase and the exit utility of itemset is find in second phase. and in one phase these are calculated in one phase. but i did not know the actually the meaning of phase.
Hi, I am sorry to answer late. I just saw your message now. The meaning of “phase” is a step. Two phases means two steps. One phase means one step.
In a two phase algorithm, the first step is to find candidate. Then the second step is to calculate the exact utility of these candidates to keep the high utility itemsets. A problem with this approach is that in the first step there can be a lot of candidate itemsets that will be discarded in the second step. Thus a lot of time is wasted.
In a one phase algorithm, there is no need to keep a big set of candidate itemsets in memory and then to evaluate them in a next step. This is why we call these algorithms “one phase”
Hope that this help a bit.
Regards
Pingback: Brief report about the IEA AIE 2021 conference | The Data Mining Blog
Pingback: New version of SPMF (2.44): 4 new algorithms, datasets and features | The Data Mining Blog
Pingback: Key Papers about High Utility Itemset Mining | The Data Mining Blog
Pingback: Towards SPMF v3.0… | The Data Mining Blog
Pingback: An Introduction to High Utility Quantitative Itemset Mining | The Data Mining Blog
Pingback: Brief report about the PRICAI 2021 conference | The Data Mining Blog
Pingback: High Utility Itemset Mining with a Taxonomy | The Data Mining Blog
Pingback: The future of pattern mining | The Data Mining Blog
Pingback: Brief report about UDML 2021 (4th International Workshop on Utility-Driven Mining and Learning | The Data Mining Blog
Pingback: Upcoming book: High Utility Itemset Mining: Theory, Algorithms and Applications | The Data Mining Blog
Pingback: Brief report about ADMA 2021 | The Data Mining Blog
Pingback: SPMF 2.52 is released | The Data Mining Blog
Pingback: New videos about pattern mining | The Data Mining Blog
Pingback: The HUIM-Miner and FHM algorithms (video) | The Data Mining Blog
Pingback: Brief report about the CACML 2022 conference | The Data Mining Blog
Pingback: Key Papers about Periodic Pattern Mining | The Data Mining Blog
Pingback: A brief report about the IEA AIE 2020 conference | The Data Mining Blog
Respected Prof. Philippe sir,
We appreciate your blog’s wealth of information. I’m studying High utility Pattern mining right now. Your SPMF and blog are both very beneficial. We appreciate your fantastic Contribution.
I inspired by your research in high utility pattern mining. So I have chosen HUPM as my research topic, but now I am unable to define problem statement in it. So Plz Sir can u help me to identify challenging problem in HUPM on uncertain data. & can you please explain the term uncertain data in brief?
I also request you to post more blogs related to High utility Pattern mining on uncertain data.
Thank You
Good evening,
I am happy that SPMF and the blog have been helpful to learn about high utility pattern mining (HUPM). And nice to know that you are working on this topic. There are many possibilities for working on this and doing the research.
The goal of high utility pattern mining is to find patterns in data that have a high value. The classical example is about shopping data, where a high value means a high profit and we want to find the sets of items that people buy and yield a high profit.
Uncertain pattern mining is another research topic where the data is uncertain. This means that we have some data but we are no sure about whether the values that have been recorded in a database are correct or not. For example, let’s say that you use a machine to collect weather data. It is possible that this machine does not work well and that you are not sure that the readings are correct. In that case, you could assign some probability to the readings like the machine has observed a high temperature with a probability of 80%. That would be some uncertain data.
Another classical example of uncertain data is the medical data. Lets say that a patient goes to hospital. The doctor may observe the patient and make some observations but without being totally sure about them. For example, a doctor may think that it is 70% likely that the patient has COVID and 30% likely that the patient has the flu. This is also some uncertain data because we are not sure about the values that are recorded in the database. We say that this data is uncertain.
This is different from data such as shopping data, where generally the data is not uncertain. For example, in a store, either you buy an apple or you don’t buy an apple. I don’t see any uncertainty in this type of data.
Now, I need also to say that there are different ways of modelling uncertainty. If you read the paper on uncertain pattern mining you will see that. The most common model that I am familiar with is where the values have probabilities as I explained. But there also exist other models.
About the idea of combining uncertain pattern mining with high utility pattern mining, I think there are some papers about this like this one:
Lin, J. C.-W., Gan, W., Fournier-Viger, P., Hong, T.-P., Tseng, V. S. (2016). Efficiently Mining Uncertain High-Utility Itemsets. Soft Computing, Springer, 21:2801-2820.
or this:
Baek, Y., Yun, U., Yoon, E., Fournier-Viger P. d(2019). Uncertainty based Pattern Mining for Maximizing Profit of Manufacturing Plants with List Structure. IEEE Transactions on Industrial Electronics, IEEE. 67(11):9914-9926.
So I think it is certainly possible to combine these two topics. Some researchers have done it, like in the papers above. And there are also some other papers on that topic as well.
But if you like that topic, you could try to make something new related to this. What could be a good topic?
Well, you would have to think about it. There are many possibilities, but you need to think about something challenging and also about some application scenario where it would be useful (to convince people that your work is useful).
An easy way to find a topic is to combine two topics together like A + B.
For example, if you combine high utility sequential rule mining + uncertain pattern mining = high utility sequential rule mining in uncertain data. That could be an interesting topic.
Other you can try to make a more efficient algorithm, make a distributed algorithm, extend some problem with some new constraints, design an incremental algorithms, a data stream algorithm, etc. There are many many possibilities. But as I said better think about if it is challenging and if it would be useful in real life.
Personally, I do not like too much the topic of uncertain data because I rarely see the datasets with uncertain data so I am not sure whether any of this is really useful in real life. That is my opinion. However, as a research problem, many papers are published on uncertain data, so still it is an interesting research area for researchers.
Wish you good luck
Pingback: Brieft report about the MIWAI 2022 conference | The Data Mining Blog
Pingback: Brief report about the BDA 2022 conference | The Data Mining Blog
Pingback: Key Papers about Episode Mining | The Data Mining Blog
Pingback: Free Pattern Mining Course | The Data Blog
Pingback: An introduction to frequent pattern mining | The Data Blog
Pingback: An introduction to frequent subgraph mining | The Data Blog
Pingback: Finding short high utility itemsets! | The Data Blog
Pingback: SPMF 2.48 | The Data Blog
Thank you sir for your valuable guidance. In frequent itemset mining problem, for discovering frequent patterns, Input: a transaction database and a parameter minsup>=1.Please, tell me why minsup set to >=1?
( or In your blog, In example minsup=2, why minsup set to 2? Please, explain in detail)
also could you please suggest me which pattern extraction algorithms are suitable for mining high utility patterns from certain data based on hierarchical data structures??
Good afternoon,
Thanks for reading the blog and posting your questions 🙂
In frequent itemset mining, the goal is to find patterns that appear frequently in the data (the frequent itemsets). The classical example is for shopping. Lets say that you have a database of customer transactions, where each transaction indicates the items (products) that some customer has purchased. Using frequent itemset mining, we want to find what people have bought together frequently. To do frequent itemset mining, we need a transaction database and to set a parameter called the minimum support threshold. The minimum support threshold indicates the minimum number of times that an itemset should appear to be considered frequent.
For example, if you set minsup = 3, it means that you want to find the products that have been purchased in at least three customer transactions.
And if you set minsup = 1, then it means that you want to find all the sets of products that have been purchased in at least one customer transaction.
Obviously, it is not meaningful to set minsup = 0, because it would mean that you would want to find everything that has been purchased ZERO or more times, which would mean everything.
Now, how to set the minsup threshold? It really depends on the application. Lets say that you have 1 million customer transactions. Then, in this case setting minsup = 1 would be probably too low because you would find probably millions of patterns and some of them would appear perhaps just once (have a support of 1). But having a support of 1 is not really meaningful. If something appeared only once, it could just appear by chance…
So generally, if you have a really big database like a million transaction, you could set that parameter to a larger value like minsup = 5000 or more. Actually, you may try different values and see how the result is.
In the blog, I use minsup =2 because I use a small example for teaching purposes where there is only maybe 4 or 5 transactions. So you may consider this to be a toy example for teaching 😉 But on the SPMF website, you can find datasets with millions of transactions. And if you use such datasets, you should not use minsup =1. You should use larger values.
For your second question, if you want to find high utility itemsets and you have a hierarchy of items like a category food, that contains a category dairy products, which contains a category milk, containing various types of milks, then you could consider the CLH-Miner. It is one of the most efficient algorithms (designed by my team), and it is also relatively simple. You can also find the code in SPMF, which is open source, as well as different real life datasets with hierarchy, if you want to use this for research. There are also other algorithms, but maybe the source code is not public. With CLH-Miner if you want to do research, you can start quickly and you will save time because you will have already the code and data for trying it.
Best regards
Thank you for your reply sir. Could you please tell me, CLH-Miner is suitable for extracting high utility patterns from certain data based on tree data structure?
Pingback: (video) The EFIM algorithm | The Data Blog