
This week, I am attending the DEXA 2018 (29th International Conference on Database and Expert Systems Applications) and the DAWAK 2018 (20th Intern. Conf. on Data Warehousing and Knowledge Discovery) conferences from the 3rd to 6th September in Regensburg, Germany.

Those two conferences are well established European conferences dedicated mainly to research on database and data mining. These conferences are always collocated. It is not the first time that I attend these conferences. I previously attended DEXA 2016 and DAWAK 2016 in Portugal.
These conferences are not in the top 5 of their fields but are still quite interesting, usually with some good papers. The proceedings of the conference are published by Springer in the LNCS (lecture notes in Computer Science series, which ensures that the paper are indexed by various academic databases.
Acceptance rates
For DEXA 2018, 160 papers were submitted, 35 have been accepted (22.%) as full papers, and 40 as short papers (25 %).
For DAWAK 2018, 76 papers were submitted, 13 have been accepted (17.%) as full papers, and 16 as short papers (21 %).
Location
The conference is held at University of Regensburg, in Regensburg, a relatively small town with a long history, about 1 hour from Munich. It is a UNESCO world heritage site. The university:

A picture of the old town:

Why I attend these conferences?
This year, my team and collaborators have four papers at these conferences, on topics related high utility itemset mining, periodic pattern mining and privacy preserving data mining:
- Fournier-Viger, P., Zhang, Y., Lin, J. C.-W., Fujita, H., Koh, Y.-S. (2018). Mining Local High Utility Itemsets . Proc. 29th International Conference on Database and Expert Systems Applications (DEXA 2018), Springer, to appear.
- Fournier-Viger, P., Li, Z., Lin, J. C.-W., Fujita, H., Kiran, U. (2018). Discovering Periodic Patterns Common to Multiple Sequences. 20th Intern. Conf. on Data Warehousing and Knowledge Discovery (DAWAK 2018), Springer, to appear.
- Lin, J. C.-W., Zhang, Y. Y., Fournier-Viger, P., … (2018) A heuristic Algorithm for Hiding Sensitive Itemsets. 29th International Conference on Database and Expert Systems Applications (DEXA 2018), Springer, to appear.
- Lin, J. C.-W., Fournier-Viger, P, Liu, Q., Djenouri, Y., Zhang, J. (2018) Anonymization of Multiple and Personalized Sensitive Attributes. 20th Intern. Conf. on Data Warehousing and Knowledge Discovery (DAWAK 2018), Springer, to appear.
The two first papers are projects of my master degree students, who will also attend the conference. Besides, I will also chair some sessions of both conferences.
Another reason for attending this conference is that it is an European conference. Thus, I can meet some European researchers that I usually do not meet at conferences in Asia.
Day 1
I first registered. The process was quick. We receive the proceedings of the conference as a USB drive, and a conference bag.

I attended several talks from both the DEXA 2018 and DAWAK 2018 conference on the first day. Here is a picture of a lecture room.

There was also an interesting keynote talk about database modelling.

In the evening, a reception was held at the old town hall.
Day 2
The second day had several more presentations. In the morning I was the chair of the session on classification and clustering. A new algorithm that enhance the K-Means clustering algorithm was proposed, which has the ability to handle noise. An interested presentation by Franz Coenen proposed an approach were data is encrypted and then transmitted to a distant server offering data mining services such as clustering. Thanks to the encryption techniques, privacy can then be ensured. In the morning, there was also a keynote about “smart aging”. I did not attend it though because I instead had a good discussion with collaborators.
Day 3 – Keynote on spatial trajectory analysis
There was a keynote about “Spatial Trajectory Analytics: Past, Present and Future” by Xiaofang Zhou. It is a timely topic as nowadays we have a lot of trajectory data in various applications.

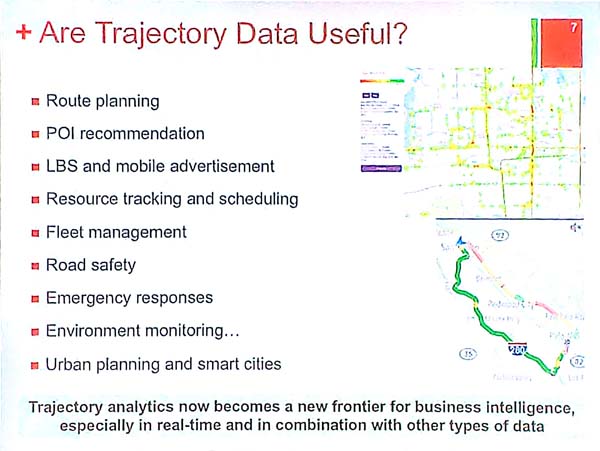
What is trajectory data? It is the traces of moving objects. Each object can be described using time, spatial positions and other attributes. Some examples of trajectory data is cars that are moving. Such trajectory data can be obtained by the GPS of cars. Another example is the trajectory of mobile phones. Trajectory data is not easy to analyze because it samples the movement of an object. Besides, trajectories are influenced by the environment (e.g. a road may be blocked). Other challenges is that data may be inaccurate and some data points may be redundant.

Trajectory data can be used in many useful ways such as route planning, point of itnerest recommendation, environment monitoring, urban planning, and resource tracking and scheduling. Trajectory data can also be combined with other types of data.
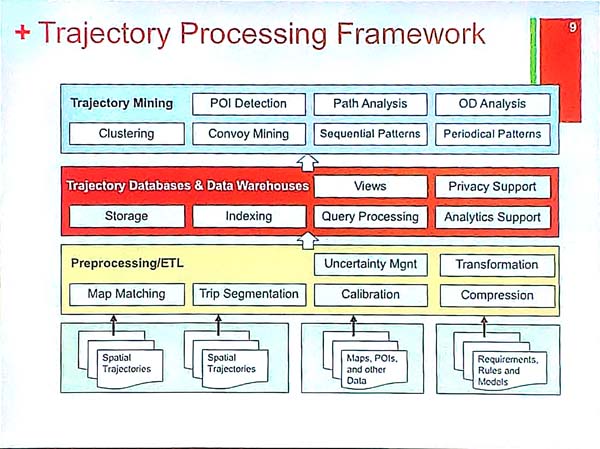
But how to process trajectory data? Basically, we need to monitor the objects to collect the trajectories, store them in databases (which may provide various views, queries, privacy support, and indexing), and then the data can be analyzed (e.g. using techniques such as clustering, sequential pattern mining or periodic pattern mining). Here is a proposed architecture of a trajectory analysis system:
This is a first book written by the presenter in 2011 about spatial trajectory mining:

Here are some important topics in trajectory analysis:
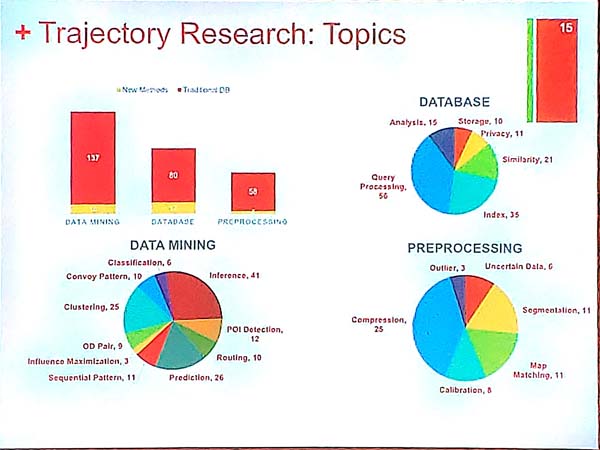
Then, the presenter discusses some specific applications of trajectory data analysis. Overall, it was an interesting introduction to the topic.
Day 3 – Banquet
In the evening, attendees were invited to a tour of a palace, and then to a banquet in a German restaurant.

Day 4
On the last day, there was more paper presentations and another keynote.
Next year
DAWAK 2019 and DEXA 2019 will be hosted in Linz, Austria from the 26th to the 29th August 2019.
Best paper award
The best paper award was given to the paper “Sequence-based Approaches to Course Recommender Systems” by Osmar Zaiane et al. It presents a system to recommend undergraduate courses to student. This system, applies algorithms for sequential pattern mining and sequence prediction among other to select relevant courses.
Conclusion
Overall, the quality of papers was relatively high, and I was able to meet several researchers related to my research. It was thus a good conference to attend.
Update: You may also be interested to read my newer posts about DEXA and DAWAK 2019, and DEXA and DAWAK 2021.
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 150 data mining algorithms.




Pingback: Conference Badges: the Best and the Worst | The Data Mining Blog
Pingback: Brief report about the Dexa 2016 and Dawak 2016 conferences | The Data Mining Blog
Pingback: Brief report about DAWAK 2019 / DEXA 2019 | The Data Mining Blog
Pingback: Brief report about the DEXA 2021 and DAWAK 2021 conferences | The Data Mining Blog