
In this blog post, I will provide a brief report about the 12th Intern. Conference on Machine Learning and Data Mining (MLDM 2016), that I have attended from the 18th to 20th July 2016 in Newark, USA.
First I have to say, that I was not very happy that the conference was held in Newark, which is one hour away from New York, because the conference had been advertised as being in New York until after our paper got accepted. As you can see on the map below, Newark is about 1 hour away from New York, and there was nothing around the conference location. It was a small hotel surrounded by highways. let me clarify, that the conference was not in New York as advertised, but instead in Newark, which is in a different state, one hour away from Newark by train: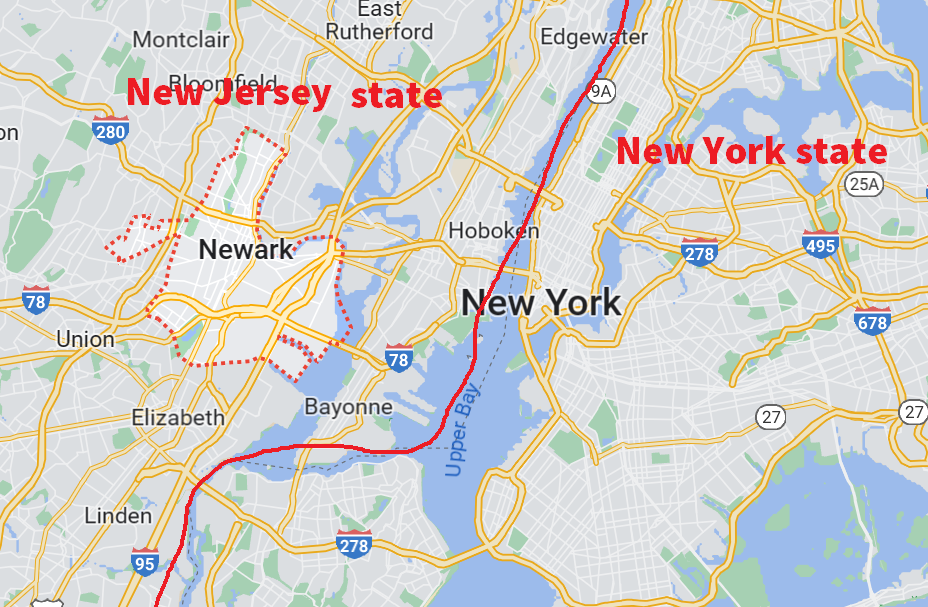
About the conference This is the 12th edition of the conference. The MLDM conference is co-located and co-organized with the 16th Industrial Conference on Data Mining 2016, that I have also attended this week. The proceedings of MLDM are published by Springer. Moreover, an extra book was offered containing two late papers, published by Ibai solutions. On the proceedings book, it is again claimed that the conference is in New York, while it was not.

The MLDM 2016 proceedings
Acceptance rate
The acceptance rate of the conference is about 33% (58 papers have been accepted from 169 submitted papers), which is reasonable.
First day of the conference
The first day of the MLDM conference started at 9:00 with an opening ceremony, followed by a keynote on supervised clustering. The idea of supervised clustering is to perform clustering on data that has already some class labels. Thus, it can be used for example to discover sub-class in existing classes. The class labels can also be used to evaluate how good some clusters are. One of the cluster evaluation measure suggested by the keynote speaker is the purity, that is the percentage of instances having the most popular class label in a cluster. The purity measure can be used to remove outliers from some clusters among other applications.
After the keynote, there was paper presentations for the rest of the day. Topics were quite varied. It included paper presentations about clustering, support vector machines, stock market prediction, list price optimization, image processing, automatic authorship attribution of texts, driving style identification, and source code mining.

The conference room
The conference ended at around 17:00 and was followed by a banquet at 18:00. There was about 40 persons attending the conference in the morning. Overall, there was some some interesting paper presentations and discussion.
Second day of the conference
The second day was also a day of paper presentations.

Second day of the conference (afternoon)
The topics of the second day included itemset mining algorithms, inferring geo-information about persons, multigroup regression, analyzing the content of videos, time-series classification, gesture recognition (a presentation by Intel) and analyzing the evolution of communities in social networks.
I have presented two papers during that day (one by me and one by my colleague), including a paper about high-utility itemset mining.
Third day of the conference
The third day of the conference was also paper presentations. There was various topics such as image classification, image enhancement, mining patterns in cellular radio access network data, random forest learning, clustering and graph mining.
Conclusion
It was globally an interesting conference but I was not very happy about the location, and this conference is rather expensive at around 650 euros.
I have attended both the Industrial Conference on Data Mining and MLDM conference this week. The MLDM is more focused on theory and the Industrial Conference on Data Mining conference is more focused on industrial applications. MLDM is a slightly bigger conference.
Would I attend this conference again? No. I did not appreciate that it was not held in New York. Some other attendees were also unhappy about this.== Philippe Fournier-Viger is a full professor and the founder of the open-source data mining software SPMF, offering more than 110 data mining algorithms. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.




Pingback: Brief report about the 16th Industrial Conference on Data mining 2016 (ICDM 2016) - The Data Mining & Research Blog
Pingback: MLDM 2019… still not in New York! …and not published by Springer! - The Data Mining BlogThe Data Mining Blog