I have often been asked what are some good books for learning data mining. In this blog post, I will answer this question by discussing some of the top data mining books for learning data mining and data science from a computer science perspective.
These books are especially recommended for those interested in learning how to design data mining algorithms and that wants to understand the main algorithms as well as understand some more advanced topics.
“Introduction to data mining” by Tan, Steinbach & Kumar (2006)
This book is a very good introduction book to data mining that I have enjoyed reading . It discusses all the main topics of data mining: clustering, classification, pattern mining and outlier detection. Moreover, it contains two very good chapters on clustering by Tan & Kumar, which are specialists in this domain. What I like about this book is that the chapters explain the techniques with enough details to have a good understanding of the techniques and their drawbacks unlike some other books that do not go into details. Some free sample chapters of the book can be found here. Before buying this book, note that a 3rd edition has been announced to be released soon, although it has been delayed for more than a year.
2. Data Mining: Concepts and Techniques, Third Edition by Han, Kamber & Pei (2013)
This book is another great book that I like. I have also used it for teaching data mining. It covers all the main topics of data mining that a good data mining course should covers, as the previous book. However, this book is more like an encyclopedia. It covers a lot of topics and give a very broad view of the field but does not cover each topics in much details. It is also designed for a computer scientist audience. Besides, it is also written by some top data mining researchers (Han & Pei).
3. Data Mining and Analysis Fundamental Concepts and Algorithms by Zaki & Meira (2014)
This is another great data mining book written by a leading researcher (Zaki) in the field of data mining. It also target computer scientist. This books covers all the main topics of data mining but also has some chapters on some advanced topics such as graph mining, which are very interesting. A version of the book that can be used for personal use only is offered freely here. The algorithms in this books are very detailed and it is possible to implement them by reading the book. In general, some algorithms are presented in each chapter. They are not always the best algorithms but are often the most popular (the classical algorithms).
4. Data Mining: The Textbook by Aggarwal (2015)
This is probably one of the top data mining book that I have read recently for computer scientist. It also covers the basic topics of data mining but also some advanced topics. Moreover, it is very up to date, being a very recent book. It is also written by a top data mining researcher (C. Aggarwal). It also covers many recent and advanced topics such as time series, graph mining and social network mining, not covered in several other books.
5. “The Elements of Statistical Learning” by Freidman et al (2009) This is aquite popular book a little bit more focused toward statistics. It covers both many data mining techiques such as Neural networks, association rule mining, SVM, regression, clustering and other topics. What is interesting about this book is that it is a top book used in many university courses like the others and can be downloaded for free here.
Conclusion
In this blog post, I have discussed some of the top books for learning data mining algorithms for computer scientists. I have tried to discuss about general books that gives a good foundation for learning data mining and that can also be interesting for advanced topics. However, note that if one is interested in specific topics such as recommender systems and text mining, there also exists some specialized books that covers only these topics in details, that may also be interesting.
==
That is all I wanted to write for now. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 52 data mining algorithms.
A while ago, I had written a blog post about How to measure the memory usage of algorithms in Java. Today, I will discuss the topic of optimizing the memory usage of algorithms written in Java to design memory-efficient data mining algorithms. The reason for writing about this topic is that memory consumption is often a challenge in Java for implementing data mining algorithms.
Brief overview of Java memory management
I will first give a brief overview of Java memory management model. In Java unlike in many other language such as C++, the user generally does not have the power to finely control how the memory is managed. The user can allocate memory by create some objects or variables. However, there is no simple way to control when the memory will be freed. In Java, the Garbage Collector (GC) is the process responsible for automatically freeing the memory. Using a GC has the advantage of making programming in Java easier and to avoid memory leaks and other memory related problems. However, using a GC makes the the memory usage much less predictable. The reason is that there is absolutely no guarantee about when the GC will free the memory used by a Java program. The GC periodically checks references to objects and when an object is not referenced anymore, it may be freed. There is a common myth that if someone calls System.gc() the garbage collector will immediately free the memory. However it is not the case.
So how to optimize memory usage in Java?
There many ways to optimize memory usage. I will discuss a few principles for optimizing memory usage in Java below, and I will then provide a detailed example with some Java code.
1) Using memory-efficient data structures. A first principle for optimizing memory usage is to use memory efficient data structures when possible. For example, one may consider using an array of integers instead of an ArrayList because ArrayList introduces some memory overhead. Another example: one may uses int instead of Integer. But there is sometimes a trade-off between memory usage and execution time. Thus, one should not just think about memory when choosing a data structure but also about execution time.
2) Reducing object creation. An important thins to know in Java is that garbage collection is VERY costly. In particular, if a Java program reaches the memory limit of Java, then the program may suddenly become very slow because of the GC (see my previous blog post explaining this issue). Thus, a very good strategy to optimize Java algorithms is to design the algorithms such that variables/objects are reused as much as possible (when it makes sense) rather than creating new variables/objects. If less variables/objects are created, then less memory will be used and the GC will have to work less, which may also improves speed For example, imagine a for loop that is repeatedly creating objects. It is sometimes possible to declare a single variable/object outside the for loop and reuse the same object. Again, whether it should be done or not depends on the overall picture. In general, one should focus on optimizations that are meaningful and not do micro-optimizations. Moreover, performing optimizations should ideally not decrease the code readability or maintainability.
A variable or object that is reused can be called a buffer object.
A detailed example.
I will now present a detailed example showing how the two above principles can be used to improve the memory efficiency of some code. The example that I will provide is abstract and can be applied to most depth-first search pattern mining algorithms. The solution that I will present was applied data mining algorithm implementations of the SPMF data mining library written in java..
Consider the following code. A List of Integer is first created. Then a recursive method is called. This recursive methods copy the list, add an element to the list and then recursively call itself. This method is not memory efficient since every time that it is called it will create a new List object. This can be quite slow because of object creation time. But moreover, the GC will have to free all these objects, which will also slow down the program.
staticpublicvoid main(String[] args){
List<Integer> list = new ArrayList<Integer>();
recursiveMethod(list);
}staticpublicvoid recursiveMethod(List<Integer> list) {// make a copy of the list
List<Integer> copyOfList = new ArrayList<Integer>();
copyOfList.addAll(list);
// Add some new integer to the list
int integer = ... ;
// ...
copyOfList.add(integer);
//.... the method is called recursively in a for loop
recursiveMethod(copyOfList);
}
Now, let’s look at a better solution, below. First, instead of using a List of Integer, an array of integer is used. This is already better in terms of memory since it is a more simple data structure. Second, the array of integers is used as a buffer object. Instead of repeatedly creating List objects, the same buffer is always reused. The buffer is initialized with a large enough size (for example 500 entries). This version of the code is much faster because (1) it is not necessary to always create objects, (2) we don’t copy list anymore, (3) a single item is copied for each recursive call!
staticpublicvoid main(String[] args){
int[] buffer = new int[500];
int currentSize = 0;
recursiveMethod(buffer, currentSize);
}staticpublicvoid recursiveMethod(int[] buffer, int bufferSize) {// Add some new integer to the list
int integer = ...;
buffer[bufferSize++] = integer;
//.... the method is called recursively in a for loop
recursiveMethod(buffer, bufferSize);
}
The above solution is extensively used in algorithm implementations of the SPMF data mining library. In some cases, this allowed to reduce memory usage by half.
Conclusion
In this blog post, I have discussed the problem of designing memory-efficient algorithms in Java. I have presented a few principles and then presented a detailed example of how to optimize data mining algorithms in Java. Hope you have enjoyed that post. In future blog post, I will discuss more examples of memory optimizations, if there is enough interest on this topic!
==
That is all I wanted to write for now. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 52 data mining algorithms.
In this blog post, I will talk about the well-known open-source library of data mining algorithms implemented in Java, which I am the founder of. I will give a brief overview of its history, discuss some lessons learned from the development of this library, and then give a glimpse of what’s next for the development of the library.
A brief history of SPMF
The first version of this library was designed at the end of 2008 as a term project for a data mining course during my Ph.D. at University of Quebec in Montreal. At that time, I had implemented about five algorithms such as Apriori and AprioriClose. The code was not so great and there was no website. And it was just an unnamed project. 😉
Then, in 2009, I started to work on implementing and developing new sequential pattern mining algorithms for my Ph.D. project, and to add them to the same project. I added several algorithms such as PrefixSpan and BIDE. I then launched the SPMF website during the summer of 2009, and choose the name SPMF for the project. At that time, the website had few information. It just provided a few instructions about how to download the library and use it.
Over the years, I have added much more algorithms to the librayr. There are now more than 90 algorithms offered in SPMF. I have implemented many of them in my spare time, some of them for my research, some of them just for my personal satisfaction, and also severalcontributorshave provided source code of algorithms for the library, and have reported bugs, and suggestions, which have also greatly helped the project. I have also added a user graphical interface and command line interface to SPMF in the last few years.
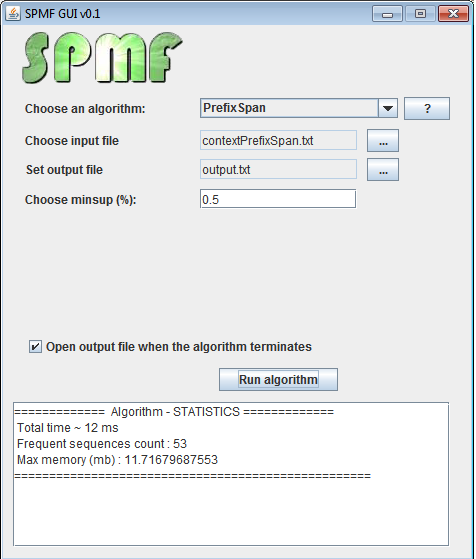
The SPMF graphical user interface
The source code of SPMF has been quite improved over the year. Originally, there was a lot of duplicated code in the project. In the years 2012-2013, I have made a major refactoring of the source code that took about 1 month. I removed as much duplicated code as possible. As a result, the number of source code files in the project was reduced by 25 %, the number of lines of code was reduced by 20 %. Moreover, I added about 10,000 lines of comments during this refactoring. In the last two years, I have also added several optimizations to the source code of SPMF because some code written in the early year was not really optimized as I did not have enough experience implementing data mining algorithms.
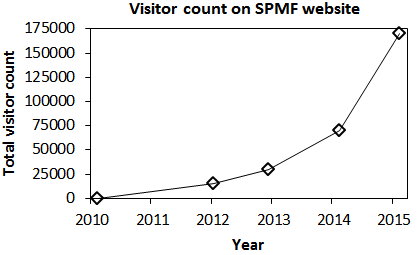
Since then, SPMF has become quite popular. It is an especially important library in the field of pattern mining (discovering patterns in databases). The number of visitors on the website recently reached 190,000. Moreover, SPMF was cited or used in about 190 research papers in the last few years, which is awesome. Here is a brief overview about the number of visitor on the website:
The lessons learned
From the SPMF project, I have learned a few general lessons about providing an open-source project.
It is important to make a high-quality documentation of how to use the library. If there is no appropriate documentation on the website, then users will always ask questions about how to do this or do that, and the developers will spend a lot of time to answer these questions. The users will also be less likely to use the library if it is too complicated to use. On the contrary, if a good documentation is provided, then most users will find answers in it. Thus the reviewers will spend less time always answering the same questions and users are more likely to use the software. Over the years, I have updated the website so that it provides information for the most common questions. I have also added a developpers’s guide, a documentation of how to use each algorithm, etc. to try to make the software as easy to use a possible.
The code should follow standard conventions and be well-documented. To make an open-source project easily reusable and understandable by other users, the code should contain a good amount of comments, be well-structured, and follow commonly used conventions. For example, in Java, there are standard conventions for writing code and documenting code with Javadoc. In SPMF, I have tried to follow these conventions as much as possible. As a result, several users have said to me that the code of SPMF is very easy to understand. It is important to write good code. I understand that many programmers may not like to document their code, but it is important to do it as it makes it much more understandable for users.
It is important to choose an appropriate license for an open-source project. I originally choose theCreative Common License for SPMF in 2009. But I then noticed that it was rarely used for licensing software. I thus then read about several licenses and choose the more commonly used GPL, which I prefers.
Listen to the users. It is important to listen to what users need in terms of features. This gives a good indication of what should be included in the software in the next releases. If many users request a specific feature, it is probably very important to provide it.
What’s next?
So what is next for SPMF? I intend to continue developing this library for at least several years 😉
I have currently implemented several new algorithms that have not yet been released such as: FOSHU, d2Hup, USpan, TS-Houn, HUP-Miner, GHUI-Miner, HUG-Miner mainly for high-utility pattern mining. Also my students have implemented several others for sequence prediction and pattern mining such as: CPT+, CPT, DG, TDAG, AKOM and LZ78, and EFIM and HUSRM. All these algorithms should be released soon in SPMF. I think that several of them may be released in a new major release in September of October. Thus, SPMF should reach the milestone of 100 algorithms before the end of 2015.
Other improvements that I would like to add in the future are to handle more file types as input. For example, it would be great to add a module for converting text files to sequences for sequential pattern mining. Another idea is to add visualization capabilities. Currently, the results of most algorithms offered in SPMF are presented as text files to the user. It would be great to add some visualization modules. Another idea is to add some modules for automatically running experiments for comparing algorithms. This is especially useful for data mining researchers that wish to compare the performance of data mining algorithms.
For the future, I also hope that more collaborators will provide source code to the project. Several researchers have used SPMF in their projects but not many have given back source code to the project. It would be great if more users could provide source code when proposing new algorithms. This would greatly helps the project. If more students or professors would like to contribute to the project, it would be also very welcome.
Also, another important aspect to help the project is to cite the SPMF project in your papers if you have been using it in your research. It should be preferably cited as follows:
Fournier-Viger, P., Gomariz, Gueniche, T., A., Soltani, A., Wu., C., Tseng, V. S. (2014). SPMF: a Java Open-Source Pattern Mining Library. Journal of Machine Learning Research (JMLR), 15: 3389-3393.
Lastly, I would like to say thank you to everyone who has supported the SPMF library over the years either by contributing code, reporting bug, using the software and citing it. This is great!
This is all for today. I just wanted to discuss the current state of SPMF and what is next. Hope that you enjoyed reading this blog post. If you want to get notified of future blog posts, you may follow my twitter account @philfv.
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 80 data mining algorithms.
In this blog post, I will discuss an interesting topic in data mining, which is the topic of sequential rule mining. It consists of discovering rules in sequences. This data mining task has many applications for example for analyzing the behavior of customers in supermarkets or users on a website.
Introduction
Before, discussing this topic, let me talk a little bit about the context. There has been a lot of work in the field of data mining about pattern mining . The goal of pattern mining is to discover useful, novel and/or unexpected patterns in databases. In this blog post, we will be interested by a specific type of database called sequences databases. A sequence database contains some sequences. For example, consider the following database:
A sequence database containing four sequences
This database contains four sequences named seq1, seq2, seq3 and seq4. For our example, consider that the symbols “a”, “b”, “c”, d”, “e”, “f”, “g” and “h” respectively represents some items sold in a supermarket. For example, “a” could represent an “apple”, “b” could be some “bread”, “c” could denote “cake”, etc.
Now, a sequence is an ordered list of sets of items. For our example, we will assume that each sequence represents what a customer has bought in our supermarket over time. For example, consider the second sequence “seq2”. This sequence indicates that the second customer bought items “a” and “d” together, than bought item “c”, then bought “b”, and then bought “a”, “b”, “e” and “f” together.
Sequences are a very common type of data structures that can be found in many domains such as bioinformatics (DNA sequence), sequences of clicks on websites, the behavior of learners in e-learning, sequences of what customers buy in retail stores, sentences of words in a text, etc. It is to be noted that sequence can be ordered by time or other properties (e.g. the order of nucleotides in a DNA sequence).
Discovering sequential patterns in sequences
An important data mining problem is to design algorithm for discovering hidden patterns in sequences. There have been a lot of research on this topic in the field of data mining and various algorithms have been proposed.
In the following, Iwill discuss two types of patterns that can be found. I will first discuss sequential patterns. Then, I will explain some of their limitations and then discuss sequential rules.
A sequential pattern is a subsequence that appear in several sequences of a database. For example, the sequential pattern <{a}{c}{e}> appears in the two first sequences of our database. This pattern is quite interesting. It indicates that customers who bought {a}, often bought {c} after, followed by buying {e}. Such a pattern is said to have a support of two sequences because it appears in two sequences from the database. Several algorithms have been proposed for finding all sequential patterns in a database such as CM-SPADE, PrefixSpan and GSP. These algorithms takes as input a sequence database and a minimum support threshold (minsup). Then, they will output all sequential patterns having a support no less than minsup. Those patterns are said to be the frequent sequential patterns.
For example, for the above example, if we run CM-SPADE with minsup = 3, we will find the following frequent sequential patterns:
<{a}> with a support of 3 sequences
<{a},{e}> with a support of 3 sequences
<{a},{f}> with a support of 3 sequences
<{b},{e}> with a support of 3 sequences
<{b},{f}> with a support of 4 sequences
Sequential patterns can be quite interesting. In the example, we can learn that buying item “b” is followed by buying item “e” in 3 sequences. However, sequential patterns can be misleading. An important limitation of sequential patterns is that there is no assessment of the probability that a pattern will be followed. Let me explain this in more details. For example, if we consider again the pattern <{b},{e}>. This pattern is said to appear in 3 sequences. It may thus seems likely that if someone buy “b”, he will also buy “e” after. But how likely? We can observe that item “b” appears in four sequences. Thus, the probability that “e” appears after “b” is actually 3 / 4 = 75 % (i.e. P(e|b)= 75%). But sequential patterns only indicate how often the pattern appears. They do not provide any indication about this probability.
Discovering sequential rules in sequences
This now lead us to the main topic of this post which is sequential rule mining. Sequential rule mining has been proposed as an alternative to sequential pattern mining to take into account the probability that a pattern will be followed. I will provide a few definitions and then we will look at a full example.
A sequential rule is a rule of the form X -> Y where X and Y are sets of items (itemsets). A rule X ->Y is interpreted as if items in X occurs (in any order), then it will be followed by the items in Y (in any order). For example, consider the rule {a} -> {e,f}. It means that if a customer buy item “a”, then the customer will later buy the items “e” and “f”. But the order among items in {e,f} is not important. This means that a customer may buy “e” before “f” or “f” before “e”.
To find sequential rules, two measures are generally used: the support and the confidence. The support of a rule X -> Y is how many sequences contains the items from X followed by the items from Y. For example, the support of the rule {a} -> {e,f} is 3 sequences because {a} appears before the items from {e,f} in three sequences (seq1, seq2 and seq3).
The confidence of a rule X -> Y is the support of the rule divided by the number of sequences containing the items from X. It can be understood as the conditional probability P(Y|X). For example, the confidence of the rule {a} -> {e,f} is 1 (or 100 % if written as a precentage), because every time that a customer buy item “a”, he then buy “e” and “f” in the example database. Another example is the rule {a} -> {b}. This rule has a support of 2 sequences and a confidence of 0.66 (that is 66%).
A sequential rule mining algorithm such as RuleGrowth, ERMiner and CMRules will output all sequential rules having a support and a confidence respectively no less than some thresholds minsup and minconf set by the user. For example, consider again the example database and suppose that the user set minsup = 0.5 and minconf = 60%. The following rules are found by RuleGrowth:
These rules can be viewed as more interesting than sequential patterns since they give a measure of confidence that they will be followed. For example, it is very informative to know that some rules such as {c} -> {e,f} have a confidence of 100 %.
In the past, I have carried a study with my student to compare the prediction accuracy of sequential patterns and sequential rules. In that study, we found sequential rules can provide a much higher prediction accuracy than sequential patterns when the patterns are used for sequence prediction. The reason is that sequential rules consider the probability (confidence), while sequential patterns do not.
Extensions of the task of sequential rule mining
In the previous paragraphs, I have introduced the topic of sequential rule mining. But note there also exists several extensions of the problem of sequential rule mining. These extensions have been proposed to address specific needs. I will provide a brief overview of a few extensions.
Discovering thetop-k sequential rules. The idea is to discover the k most frequent rules in a dataset having at least a confidence no less than minconf. For example, a user may specify that he wants to find the top 1000 rules having a confidence of at least 75 %. Some algorithms for this task are TopSeqRules and TNS.
Discovering sequential rules with a window size constraint. This algorithm let the user find rules of the form X -> Y where X and Y must be close to each other with respect to time. For example, a user may want to find rules appearing whithin three consecutive itemsets in sequences. This is interesting for example for analyzing sequence of web clicks. An algorithm for this task is TRuleGrowth.
Discovering high-utility sequential rules. Another extension is to discover rules where items may be annotated with quantities in sequences and each item may have a unit profit. For example, we may have a sequence where a customer bought three breads, then two apples and two bottle of milk and these items may have some unit profit of 1$, 2$ and 1.50$. The goal of high-utility sequential rule mining is to find rules that generate a high profit and have a high confidence (high-utility rules). An algorithm for this task is HUSRM.
Open-source implementations and datasets
There exists several algorithms for sequential rule mining and sequential pattern mining that have been proposed. Java implementations of the state-of-the art algorithms are currently offered in my open-source data mining library named –SPMF.
It offers several state-of-the-art algorithms for sequential rule mining such as ERMiner (2014), TNS (2013), RuleGrowth (2011), TopSeqRules (2011), and CMRules (2010). Besides, SPMF offers several algorithms for sequential pattern mining such as CM-SPADE (2014), VMSP (2014), LAPIN (2005) and PrefixSpan (2004). To our knowledge, ERMiner is the fastest sequential rule mining algorithm. But RuleGrowth is still quite fast and consumes less memory. You can try the above algorithms by going to the SPMF website. On the website, you will find instructions about how to run algorithms and some datasets on the dataset page.
Some example of applications of sequential rule mining are e-learning, manufacturing simulation, quality control, web page prefetching, anti-pattern detection in service based systems, embedded systems, alarm sequence analysis, restaurant recommendation. For example, here are a few papers describing such applications:
E-learning
Fournier-Viger, P., Faghihi, U., Nkambou, R., Mephu Nguifo, E.: CMRules: Mining Sequential Rules Common to Several Sequences. Knowledge-based Systems, Elsevier, 25(1): 63-76 (2012)
Toussaint, Ben-Manson, and Vanda Luengo. “Mining surgery phase-related sequential rules from vertebroplasty simulations traces.” Artificial Intelligence in Medicine. Springer International Publishing, 2015. 35-46.
Faghihi, Usef, Philippe Fournier-Viger, and Roger Nkambou. “CELTS: A Cognitive Tutoring Agent with Human-Like Learning Capabilities and Emotions.” Intelligent and Adaptive Educational-Learning Systems. Springer Berlin Heidelberg, 2013. 339-365.
Manufacturing simulation
Kamsu-Foguem, B., Rigal, F., Mauget, F.: Mining association rules for the quality improvement of the production process. Expert Systems and Applications 40(4), 1034-1045 (2012)
Quality control
Bogon, T., Timm, I. J., Lattner, A. D., Paraskevopoulos, D., Jessen, U., Schmitz, M., Wenzel, S., Spieckermann, S.: Towards Assisted Input and Output Data Analysis in Manufacturing Simulation: The EDASIM Approach. In: Proc. 2012 Winter Simulation Conference, pp. 257–269 (2012)
Web page prefetching
Fournier-Viger, P. Gueniche, T., Tseng, V.S.: Using Partially-Ordered Sequential Rules to Generate More Accurate Sequence Prediction. Proc. 8th International Conference on Advanced Data Mining and Applications, pp. 431-442, Springer (2012)
Anti-pattern detection in service based systems,
Nayrolles, M., Moha, N., Valtchev, P.: Improving SOA antipatterns detection in Service Based Systems by mining execution traces. In: Proc. 20th IEEE Working Conference on Reverse Engineering, pp. 321-330 (2013)
Embedded systems
Leneve, O., Berges, M., Noh, H. Y.: Exploring Sequential and Association Rule Mining for Pattern-based Energy Demand Characterization. In: Proc. 5th ACM Workshop on Embedded Systems For Energy-Efficient Buildings. ACM, pp. 1–2 (2013)
Alarm sequence analysis
Celebi, O.F., Zeydan, E., Ari, I., Ileri, O., Ergut, S.: Alarm Sequence Rule Mining Extended With A Time Confidence Parameter. In: Proc. 14th Industrial Conference on Data Mining (2014)
Ileri, Omer, and Salih Ergüt. “Alarm Sequence Rule Mining Extended With A Time Confidence Parameter.” (2014).
Recommendation
Jannach, Dietmar, and Simon Fischer. “Recommendation-based modeling support for data mining processes.” Proceedings of the 8th ACM Conference on Recommender systems. ACM, 2014.
Interestingly, the above work found that sequential rules found by CMRules provided better results than other compared patterns found using FPGrowth and other algorithms.
Jannach, D., Jugovac, M., & Lerche, L. (2015, March). Adaptive Recommendation-based Modeling Support for Data Analysis Workflows. In Proceedings of the 20th International Conference on Intelligent User Interfaces (pp. 252-262). ACM.
Restaurant recommendation
Han, M., Wang, Z., Yuan, J.: Mining Constraint Based Sequential Patterns and Rules on Restaurant Recommendation System. Journal of Computational Information Systems 9(10), 3901-3908 (2013)
Customer behavior analysis
Noughabi, Elham Akhond Zadeh, Amir Albadvi, and Behrouz Homayoun Far. “How Can We Explore Patterns of Customer Segments’ Structural Changes? A Sequential Rule Mining Approach.” Information Reuse and Integration (IRI), 2015 IEEE International Conference on. IEEE, 2015.
What is the difference between sequential rules, association rules and episode rules?
A question that some reader familiar with data mining may have is what is the difference between sequential rules and association rules? The answer is as follows. The sequential rules are found in sequences while association rules are found in records (transactions) containing items that are not ordered. In other words, the order between items such as time is not considered in association rule mining. Some sequential rule mining algorithms such as CMRules will first discover association rules, and then filter out some rules using the sequential ordering to keep only the sequential rules.
It should be noted that there are also some other terms that are used in the research papers. For example, there are a few papers that will talk about “temporal association rules”. This can be viewed as some kind of sequential rules. However, between “temporal association rules” and sequential rules, I prefer the term sequential rules. The reason is that a sequence is not always ordered by time. For example, in a sequence of words, there is an order but it is not based on time. Thus, I think that sequential rules is a better name because it means that there is some order but this order could be based on time or something else, while “temporal” is a name that refers to time.
There are also some other names that are used… Generally, if we find the rules in many sequences, we call them sequential rules. But if we find the rules in only one sequence, some people will call these rules “episode rules”. In SPMF, we recently added some code for discovering episode rules in a single long sequences such as the POERM algorithm. Episode rules can be viewed as a special type of sequential rules for a single sequence.
Conclusion
In this blog post, I have given an overview of the tasks of sequential rule mining and sequential pattern mining, which aims at discovering patterns in sequences. Hope that you enjoyed reading it 😉 For researchers, there are many possibility of research on this topic.
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 80 data mining algorithms.
In this blog post, I will discuss how to check if a data mining algorithm implementation is correct and complete. This is a very important topic for researchers who are implementing data mining algorithms since an incorrect implementation may generate unexpected results. It may be also important for those who want to compare two implementations downloaded on the internet for example. There are a few different ways to check if a data mining algorithm implementation works as expected.
1) Is it theoretically correct?
The first step is to make sure that the algorithm itself does not contain any errors. This can be done before implementing the algorithm. It happens sometimes that the description of algorithms in research papers contains errors. These errors may be some typo or they may be some more fundamental errors. It is thus important to read the paper carefully and understand it well before implementing the data mining algorithm, to detect these errors, if there are any.
2) Testing the algorithm on a small dataset – debugging by hand
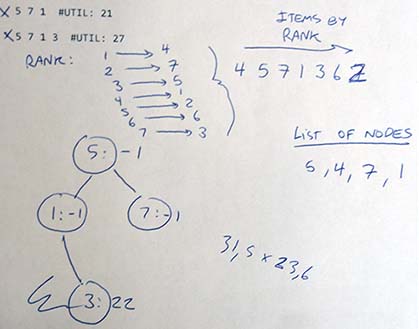
After the algorithm has been implemented, it is time to test it. First, I usually try to run the algorithm with some small dataset. For example, to test a sequential pattern mining algorithm, I may use a dataset that contains 5 sequences instead of a dataset containing 100,000 sequences. Using a small dataset is much easier for debugging. I will run the algorithm on a small dataset and check if the results are correctly calculated by hand. Or if there is an example provided in the paper describing the algorithm, I will try to use the same example. If there are some errors, I will also vary the parameters to see if the behavior is still correct on the small dataset. I will use the debugger to find the problem and fix it. I may also use the debugger and check step by step how the algorithm works to see if there is some weird behavior. During this step, I may also use some paper and a pencil to make some example by hand on paper and check if the results generated by the algorithm is the same.
Drawing an example on a piece of paper to debug an algorithm implementation
3) Testing the algorithm on large datasets – comparison with another implementation
Second, I will run the algorithm on larger datasets. The reason is that there are some errors that will only occurs on large datasets. For example, I have recently encountered an integer overflow error that was only occuring when the dataset was very large. To test a sequential pattern mining algorithm, I may use a dataset using 1 million sequences.
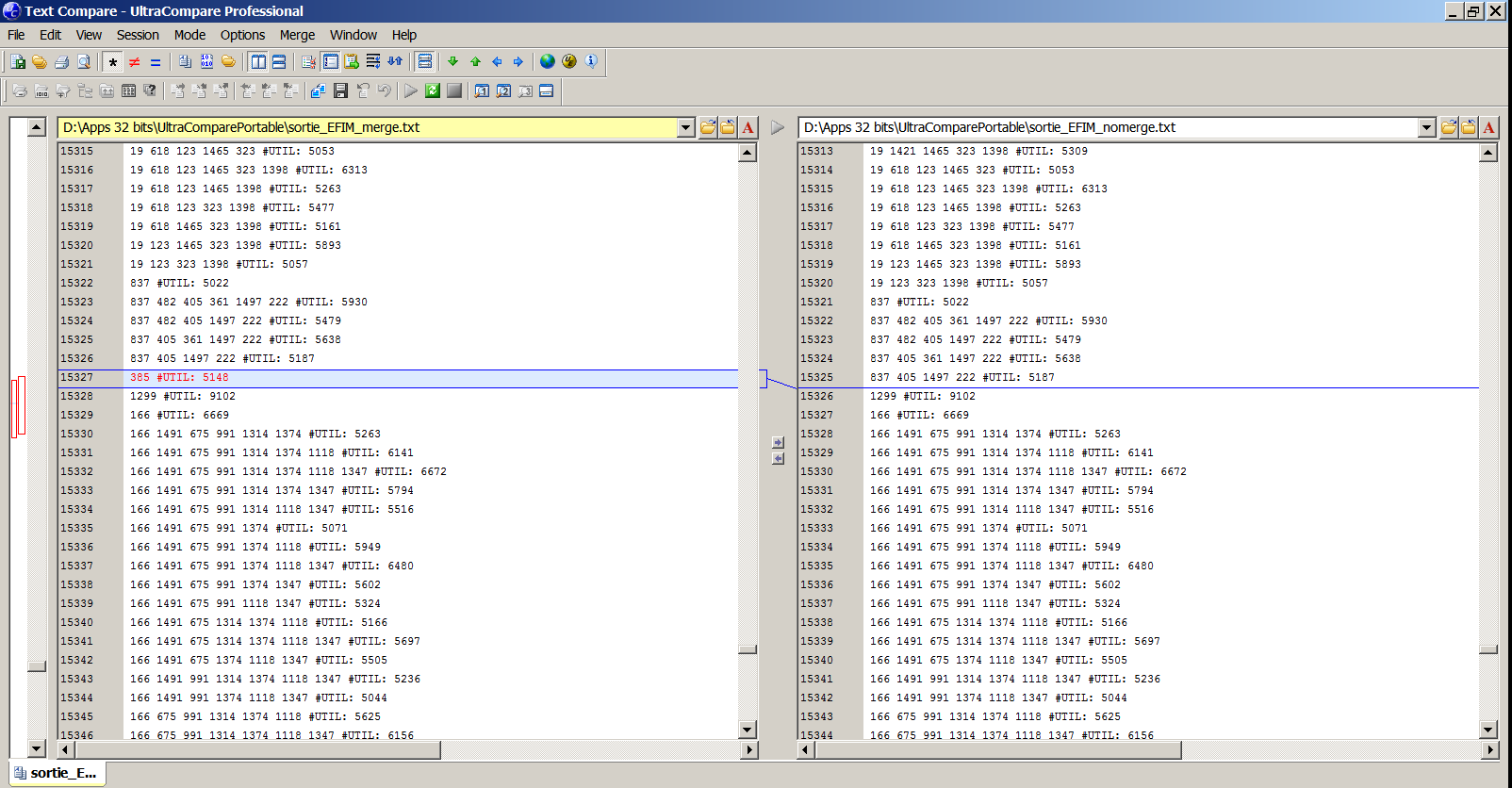
If I have some other algorithm implementations for the same problem, I will use them to see if the new implementation generate the same results. A simple way to do that is to take the output file of two implementations and use a software to compare two files such as UltraCompare (not free). These kind of software will quickly highlight the differences between two output file. Then, if there are some differences, I will analyse the results further to see which implementation is incorrect.
Comparing the output of two algorithm implementations using UltraCompare
4) Testing the algorithm on large datasets – automatic tests
Another way to check if an implementation is correct is to write some automatic tests. The reason is that on large datasets, it is likely impossible to check by hand if all the results are correct. For example, If I run a sequential pattern mining algorithm on a large dataset, it would be too time consuming to check by hand that the support is calculated correctly for all patterns that are found by the algorithm . To address this issue, I will write some code that take each pattern and scan the database to recalculate the support using a brute force approach. This allow to check that the result is correct automatically. And if I find some errors, I will use the debugger to find where they come from, and fix them.
Conclusion
In this blog post, I have discussed how to check if the implementation of a data mining algorithm is correct. It can be quite time-consuming to check if an implementation is correct. Sometimes, I may spend one or two days for debugging. But it is still very important to verify that an algorithm implementation is correct, especially when proposing a new algorithm. If an algorithm is incorrect, it may completely change the results when comparing the algorithm with other algorithms.
==
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 80 data mining algorithms.
If you like this blog, you can tweet about it and/or subscribe to my twitter account@philfvto get notified about new posts.
I have attended the 19th PAKDD 2015conference in Ho Chi Minh City, Vietnam from the 19th to 22nd May. In this blog post, I give some brief comments about the PAKDD 2015conference.
PAKDD( Pacific-Asia Conference series on Knowledge Discovery and Data Mining ) is a top data mining conference, held every year in Asia or the pacific area. The proceedings are published by Springer in the Lecture Notes in Artificial Intelligence series.
The PAKDD 2015 conference was held at the Rex hotel which is centrally located in Ho Chi Minh City.
This year, 405 papers were submitted and 117 papers were accepted, for an acceptance rate of 28.9 %.
The first day had workshops and tutorials, while the following days were paper presentations.
In terms of social activities at PAKDD, there was an excursion to visit some old tunnels used during the Vietnam war, and I also visited the Mekong Delta. I also met some very nice Vietnamese students who used my SPMF software in their research and treated me to restaurant.
Overall, it was a very interesting conference. I feel that Vietnam is a very nice place. I did not write too much on the blog, as I have been quite busy enjoying the conference 😉
== Philippe Fournier-Viger is a professor, data mining researcher and the founder of the SPMF data mining software, which offers more than 150 data mining algorithms.
In this blog post, I will give an introduction about a popular problem in data mining, which is called “high-utility itemset mining” or more generally utility mining. I will give an overview of this problem, explains why it is interesting, and provide source code of Java implementations of the state-of-the-art algorithms for this problem, and datasets.
Frequent itemset mining
The problem of high-utility itemset mining is an extension of the problem of frequent pattern mining. Frequent pattern mining is a popular problem in data mining, which consists in finding frequent patterns in transaction databases. Let me describe first the problem of frequent itemset mining
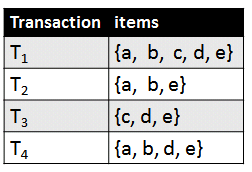
Consider the following database. It is a transaction database. A transaction database is a database containing a set of transactions made by customers. A transaction is a set of items bougth by the customers. For example, in the following database, the first customer bougth items “a”, “b”, “c”, “d” and “e”, while the second one bougth items “a”, “b” and “e”.
A transaction database
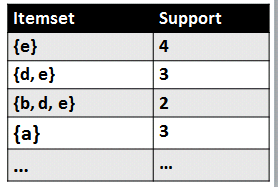
The goal of frequent itemset mining is to find frequent itemsets. Many popular algorithms have been proposed for this problem such as Apriori, FPGrowth, LCM, PrePost, FIN, Eclat, etc. These algorithms takes as input a transaction database and a parameter “minsup” called the minimum support threshold. These algorithms then return all set of items (itemsets) that appears in minsup transactions. For example, if we set minsup = 2, in our example, we would find several such itemsets (called frequent itemsets) such as the following:
some frequent itemsets
For example, consider the itemset {b,d,e}. It is said to have a support of 3 because it appears in three transations, and it is said to be frequent because the support of {b,d,e} is no less than minsup.
Frequent itemset mining has some important limitations
The problem of frequent itemset mining is popular. But it has some important limitations when it comes to analyzing customer transactions. An important limitation is that purchase quantities are not taken into account. Thus, an item may only appear once or zero time in a transaction. Thus, if a customer has bougth five breads, ten breads or twenty breads, it is viewed as the same.
A second important limitation is that all items are viewed as having the same importance, utility of weight. For example, if a customer buys a very expensive bottle of wine or just a piece of bread, it is viewed as being equally important.
Thus, frequent pattern mining may find many frequent patterns that are not interesting. For example, one may find that {bread, milk} is a frequent pattern. However, from a business perspective, this pattern may be uninteresting because it does not generate much profit. Moreover, frequent pattern mining algorithms may miss the rare patterns that generate a high profit such as perhaps {caviar, wine}
High-utility itemset mining
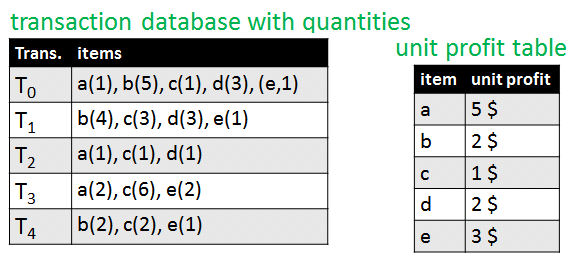
To address these limitations, the problem of frequent itemset mining has been redefined as the problem of high-utility itemset mining. In this problem, a transaction database contains transactions where purchase quantities are taken into account as well as the unit profit of each item. For example, consider the following transaction database.
a transaction database with quantities and unit profit information for items
Consider transaction T3. It indicates that the corresponding customer has bougth two units of item “a”, six unit of item “c”, and two units of item “e”. Now look at the table on the right. This table indicates the unit profit of each item. For example, the unit profit of items “a”, “b”, “c”, “d” and “e” are respectively 5$, 2$, 1$, 2$ and 3$. This means for example, that each unit of “a” that is sold generates a profit of 5$.
The problem of high-utility itemset mining is to find the itemsets (group of items) that generate a high profit in a database when they are sold together. The user has to provide a value for a threshold called “minutil” (the minimum utility threshold). A high-utility itemset mining algorithm outputs all the high-utility itemsets, that is those that generates at least “minutil” profit. For example, consider that “minutil” is set to 25 $ by the user. The result of a high utility itemset mining algorithm would be the following.
high-utility itemsets
For example, consider the itemset {b,d}. It is considered to be a high-utility itemset, because it has a utility of 40$ (generates a profit of 40$), which is no less than the minutil threshold that has been set to 25$ by the user. Now, let’s look into more detail about how the utility (profit) of an itemset is calculated. In general, the utility of an itemset in a transaction is the quantity of each item from the itemset multiplied by their unit profit. For example, consider the figure below. The profit of {a,e} in transaction T0 is 1 x 5 + 1 x 3 = 8 $. Similarly, the profit of {a,e} in transaction T3 is 2 x 5 + 2 x 3 = 16 $. Now, the utility of an itemset in the whole database is the sum of its utility in all transactions where it appears. Thus, for {a,e}, its utility is the sum of 8$ + 16 $ = 24$ because it appears only in transactions T0 and transaction T3.
illustration of how to calculate the utility of itemset {a,e}
Why the problem of high-utility itemset mining is interesting?
The problem of high-utility itemset mining is quite interesting for the following reasons.
First, it may be more interesting from a practical perspective to discover itemsets that generate a high profit in customer transactions than those that are bougth frequently.
Second, from a research perspective, the problem of high-utility itemset mining is more challenging. In frequent itemset mining, there is a well-known property of the frequency (support) of itemsets that states that given an itemset, all its supersets must have a support that is lower or equal. This is often called the “Apriori property” or “anti-monotonicity” property and is very powerful to prune the search space because if an itemset is infrequent then we know that all its supersets are also infrequent and may be pruned. In high-utility itemset mining there is no such property. Thus given an itemset, the utility of its supersets may be higher, lower or the same. For example, in the previous example, the utility of itemsets {a}, {a,e} and {a,b,c} are respectively 20 $, 24$ and 16$.
In this blog post, I will not go into the details of how the high-utility itemset miningalgorithms work. But a key idea is to use upper-bounds on the utility of itemsets that restore the anti-monotonicity propety to be able to prune the search space. This will be the topic of a future blog post.
Open-source implementations and datasets
There exists several algorithms for high-utility itemset mining that have been proposed over the year. Java implementations of the state-of-the art algorithms are currently offered in my open-source data mining library named SPMF. It offers for example, source-code of Two-Phase (2005), UPGrowth (2011), HUI-Miner (2012) and FHM (2014). To our knowledge, FHMis one of the fastest algorithm for this problem. It was shown to be up to six times faster than HUI-Miner, which was shown to be up to 100 times faster than UPGrowth, which was shown to be up to 1000 times faster than Two-Phase. You can try FHM and the other above algorithms by going to the SPMF website. On the website, you will find instructions about how to run algorithms and some datasets on the dataset page. Update: Recently, the EFIMalgorithm was proposed and was shown to outperform FHM by up to 1000 times, and is also offered in SPMF.
In this blog post, I tried to give an overview of the problem of high-utility itemset mining. Hope that you enjoyed it. I will try to keep posting blog posts such as this one about interesting data mining problems in the future. Hope that you enjoyed reading 😉
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.
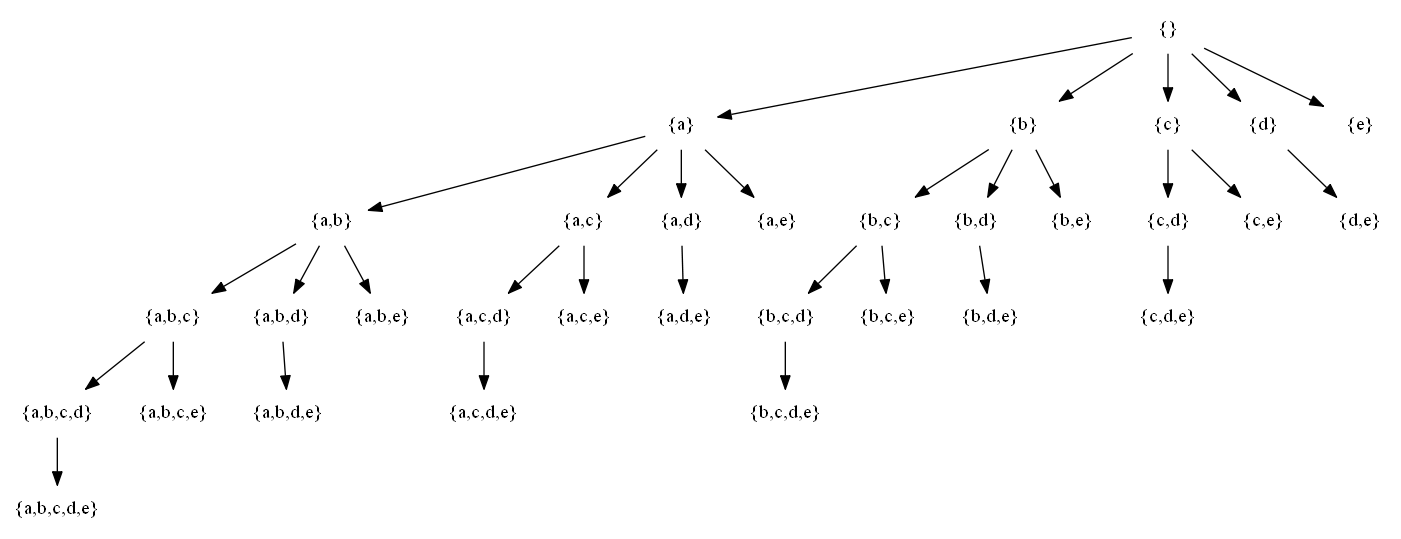
In this blog post, I will explain and provide source code to automatically draw the set-enumeration tree of a set using Java and GraphViz. Drawing a set-enumeration tree is useful in computer science, for example in frequent itemset mining, a subfield of data mining.
What is a set-enumeration tree?
The concept of set-enumeration tree was proposed by Rymon (1992).
Rymon, R. (1992). Search through systematic set enumeration. Proceedings of the International Conference on Principles of Knowledge Representation and Reasoning, Cambridge, MA, Morgan Kauffman.
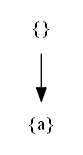
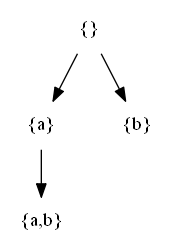
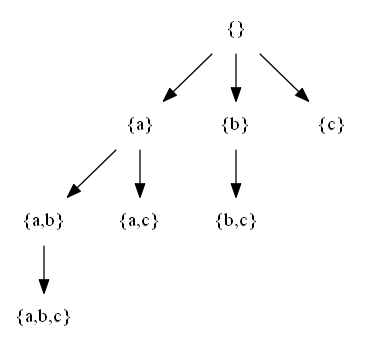
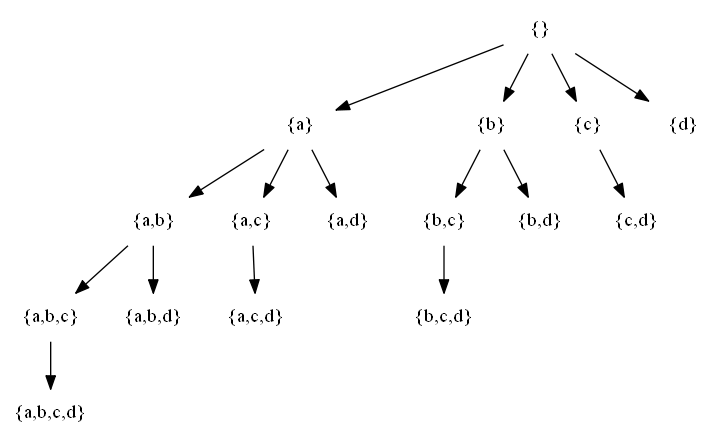
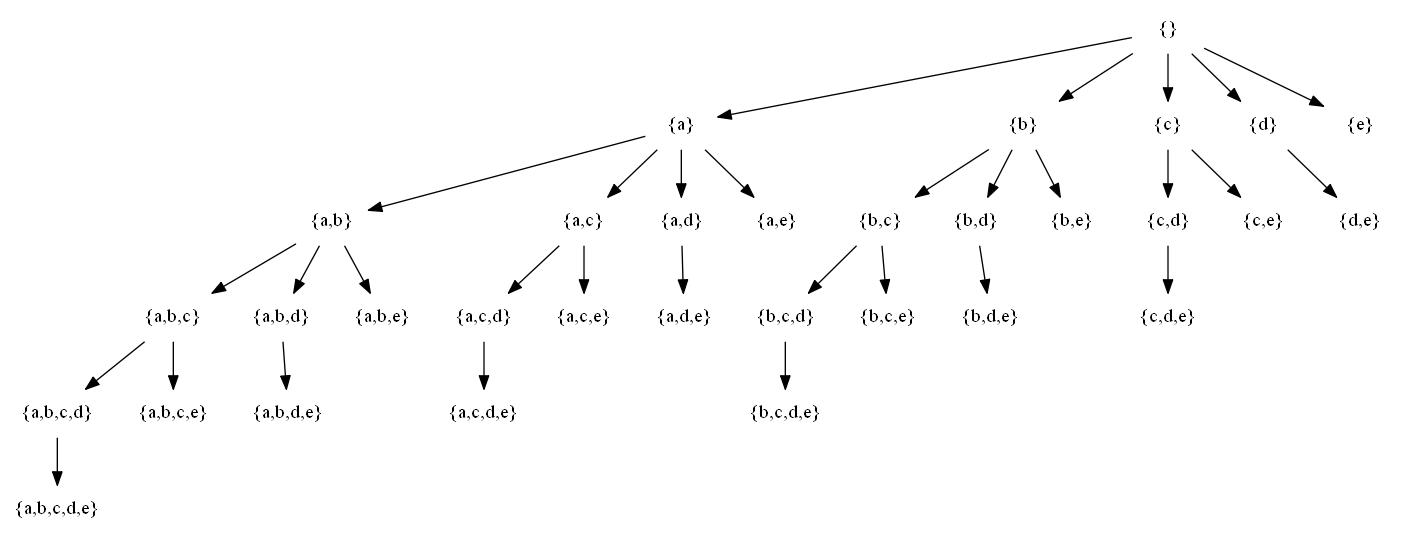
Let be a set X = {a,b,c,d}. A set-enumeration tree for that set is the following structure:
The set-enumeration tree of {1,2,3,4}
Now, I will show how to draw a nice diagram automatically such as the one above.
Step 1. Generate a GraphViz input file
The first step is to have Java installed on your computer and use the following Java program. This Java program will generate a GraphViz input file named “input.dot” for the set-enumeration-tree of {a,b,c,d,e}. Note that you can edit the line String[] set = new String[] { “a”, “b”, “c”, “d”, “e” } to draw the set-enumeration tree of another set. Note also that the Java code below is not fully optimized. But for the purpose of drawing set-eumeration tree, it is ok.
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
/**
* Draw the set enumeration tree of a set using Graphviz
* @author Philippe Fournier-Viger, 2015
*/
public class DrawSetEnumerationTree{
public static void main(String[] arg) throws IOException,
InterruptedException {
// This is the set of integers that we want to draw the powerset of
String[] set = new String[] { "a", "b", "c", "d", "e"};
// output file
String output = "input.dot";
// create the file
BufferedWriter writer = new BufferedWriter(new FileWriter(output));
writer.write("digraph mygraph{" + System.lineSeparator());
writer.write(" node [shape=plaintext]" + System.lineSeparator());
// We will generate all links between subsets with a depth first search
recursive("\"{", set, 0, writer);
// write end of file
writer.write("}");
writer.close();
}
private static void recursive(String currentPrefix, String[] set, int offset, BufferedWriter writer) throws IOException {
String startVertex = currentPrefix + "}\"";
for(int i=offset; i< set.length; i++) {
String concatenate;
if(offset == 0) {
concatenate = currentPrefix + set[i];
}else {
concatenate = currentPrefix + "," + set[i];
}
String endVertex = concatenate + "}\"";
writer.write(" " + startVertex + " -> " + endVertex);
writer.write(System.lineSeparator());
recursive(concatenate, set, i+1, writer);
}
}
}
By running the above program, it will create a file called input.dot containing a content similar to this, which represents the nodes of the graph that will be drawn and the links between nodes.
Step 2. Generating a PNG file of the graph using GraphViz
Then, we can run GraphViz from the command line to generate the graph as a PNG file:
dot -Tpng input.dot > output.png"
This will generate a nice set-enumeration tree:
set-enumeration tree of {a,b,c,d,e}
A few more powersets
I have also generated a few more set-enumeration trees that are commonly used for your convenience so that they can be used directly without running the Java program and Graphviz:
—
Hope that you have enjoyed this post. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 52 data mining algorithms.
Today, I will discuss the topic of how to give a good oral presentation of your research at academic cconferences. This is a very important topic since if a presentation is interesting, more researchers will be interested in your work and it may bring several opportunities such as collaborations with other researchers. So let’s get started!
The key points to giving a good presentations are the following:
1) Prepare your presentation early
The first key point is to prepare your presentation well in advance before the date of the presentation. In other words, you should not create your PowerPoint the night before. Preparing your presentation in advance will let you avoid underestimating the required time for preparation and for rehearshing, and thus ensure that you have a good sleep before the presentation. If your presentation is ready a few days before the date, it will also give you more time to rehearse your presentation, which lead us to the next point.
2) Rehearsal is always needed
One should always rehearse before giving a presentation, although the amount of time necessary may vary. Typically, I will rehearse my presentation at least a few times in the hotel room the day before giving a presentation at a conference. But depending on how much experience you have, it may be safer to rehearse a few days before the date. If you are new to doing academic presentations, it is recommended to first rehearse a few times by yourself and then to rehearse at least once in front of your research advisor or your colleagues. You may also practice about how to answer questions with your colleagues, because most academic presentations are followed by questions from the audience.
If your native language is not English, it is important to rehearse even more. This will help you to feel more comfortable speaking in English and it will allow you to avoid searching for your words and hesitating during the live presentation. Besides, you may practice pronuncing some difficult words before the presentation. I have seen a few times that a presenter did not know how to pronunce a word or pronunced it incorrectly, especially for math terms.
3) Know your audience
Another important point is to know who your audience is. Are you presenting in front of experts in your very specific field or a crowd of researchers that may not be very familiar with your topic? For example, if you are working on data mining algorithms, it is not the same if you present your work at a data mining conference where everyone is familiar with at least basic data mining concepts, an artificial intelligence conference or a general computer science conference. It is important to know your audience because in general, any kind of oral presentations should be adapted to its audience. For example, if you are sure that the audience is familiar with some basic concepts in your field, you do not need to explain them. Or if you think they are not familiar with some topics you may give further explanations.
4) Define your goal, and organize your presentation well
A related point is to clearly know what is the goal of your presentation. What do you want the audience to understand and remember about your work? If you had an infinite amount of time, you could describe your research in very deep details. However, in reality there is always a time limit. For example, at a conference, organizers may give you 15 minutes to present your research. So what should you present during these 15 minutes? Personnally, my goal in such a conference presentation is to give an overview of the research. I want the audience to clearly understand the problem that I want to solve, then I give a rough overview of the technical solution with emphasis on what is new but without going in deep technical details or mathematic formulas. And then, I present experimental results and conclusion. My goal is to make the audience understand the problem, what are the main originalities and the results. If they want to read the deep technical details, proofs of theorems, etc., they may read the conference paper, ask me questions or discuss with me after the presentation for more details. I have often seen some researchers showing slides full of mathematic formulas with many different symbols. In some field, it may be ok to do that. But insome other fields, you may lost your audience if you give too many technical details such as that.
A good organization for your presentation is important. To present a paper at a conference, the presentation may roughly follow the sections of your paper. The key parts are:
Introduction, related work, problem statement: introduce yourself, the topic, and then slowly introduce related work, their limitations and then the problem that you want to solve. You may show some example of the problem that you want to solve
Your solution: explain how you have solved the problem
Experimental validation: this is to show that your solution is good to solve the research problem
Conclusion: A good conclusion should summarize the key points of your presentations (problem, key characteristics of your solution, key experimental results) and then you may talk about limitations and future work. The conclusion is very important. You can think of the conclusion as what are the key points that you want your audience to remember.
5) Test your presentation and prepare solutions for technical problems
Preferably, you should test your presentations in the environment where you will present before the presentations to avoid issues such as software incompatibility issues. Some common problems are:
fonts in your Powerpoint presentation are not available on the provided computer (you may solve this problem by embedding them).
videos in your presentation are not playing properly (e.g. problems with codecs, etc. – generally it may be better to avoid using videos),
the provided computer uses a different software such as Open-Office and your presentation don’t look the same (a solution is to bring with a PDF version of your presentation with you, just in case)
you may need a special cable to plug your laptop to the video projector (e.g. for Apple computers)
…
Personnally, I bring my laptop, and a USB stick with a Powerpoint and also a PDF version of my presentation, just in case. I may also send one copy of my presentation to my e-mail just in case. Also, I try to arrive a little bit earlier to be able to test my presentation on the provided computer if I cannot use my laptop.
6) Make your presentation interesting and interact with your audience
I have seen many boring presentations at academic conferences, not because the topic was boring but because of a poor presentation. Some key points to make a good presentation:
Arrive early at the presentation. Just before starting your presentation, look at the audience, smile at them. This will help you get more comfortable and kill the nervousness. Also breath well. If you are well-prepared, everything will go well.
Talk to your audience. Do not read your presentation. Otherwise, the audience will quickly lose interest. If you are using Powerpoint, you should not put very long sentences in your slides. You should instead only write some very short lines and use them as key points to remember where you are in your presentation rather than as a text to be read. The text may just be some part of sentences rather than full sentences.
Always look at your audience. Look around at the audience as you keep talking by making eye-contact with the audience to keep them interested. Do not always look at the same person (e.g organizer) but look at the whole audience. You may sometimes give a quick look at your laptop to see at which slide you are in your presentation.
Never turn your back to the audience. Turning your back to the audience is one of the worst thing that a presenter can do. In some cases, it may be ok to turn your back for a few seconds to briefly show something using a laser pointer but never do it for more than few seconds, and preferably use the mouse instead of turning your back.
Avoid doing a presentation while sitting. Some people like to sit to give a presentation. But standing will result in a better presentation and you can move more freely and people will see you better if you stand up than if you are sitting. Also stand straight and firm. Have confidence. Avoid unecessary movements that can annoy the audience such a playing with a pen in your hand while talking. Make sure that you are not standing in front of the screen so that people can see your slides.
Avoid using too complicated words or a too large vocabulary. Try to explain your research using simple words. This will allow everyone to better understand, especially for non native speakers.
Don’t speak too fast. The goal is not to explain your whole paper in a short amount of time. But it is to give the main idea about your research. If people are interested in your research they may talk with you after the presentation or read your paper. So carefully select the content beforehand so that you don’t have to speak very fast. Usually, as a rough estimate, I prepare 1 Powerpoint slide for each minute of my presentation (but I also rehearse to check if the time is fine).
You may use some techniques such as changing the tone of your voice to emphasize some words and break monotony. You may also consider telling a short story in the introduction to raise interest in your problem.
Analyse the reaction of your audience. If they look like they are not understanding, you may need to give a few more explanations. If you are not sure, you may ask if everyone understood your explanation (e.g. “is that clear?”). If you feel like they are bored because explanations are too simple, maybe you can skip some basic explanations.
Speak loud enough.
7) Other advices
A few more advices:
Keep your presentation simple. from a technical point of view. It may be tempting to use all the features offered in Powerpoint such as animations, transitions, sound effects, videos, etc. But most of these will just distract your audience and should thus be avoided. Sometimes, animations may be helpful. But only use them when they are really necessary to help understanding.
Take the time to design your Powerpoint slides well. For example, rather than just copying and pasting illustrations from your paper into your slides, you may adapt them so that they look better for a presentation. You should avoid putting too much text on a slide or too many bullet points. Slides should also have a clear title. Do not use too many different fonts, colors. Adding some pictures may make your presentation more interesting. But use them well, when they help to understand and do not put too many of them.
It is great to spend time to create a great Powerpoint. But rehearsing is as important. Therefore, avoid the mistake of spending too much time to create a great Powerpoint but not rehearsing enough.
After a presentation, the audience should generally be given a few minute to ask you some questions. Make sure that you understand a question well before answering it. If someone ask you a question and you don’t understand it, you may ask them to repeat it. Besides, if a question is too complicated to answer or if the person is not able to answer you may just say to come talk to you later (e.g. during the coffee break) to discuss it with you.
There is obviously much more that could be said on this topic. If you present your work for the first time at an academic conference, it is normal to be nervous. But the solution is to prepare yourself well. If you are well-prepared everythng should be fine.
—–
That is all I wanted to write for now. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 52 data mining algorithms.
In this blog post, I will discuss my current trip to the ADMA 2014conference (10th Intern. Conf. on Advanced Data Mining and Applications in China (December 19-21 2014 in Guilin, China). Note that the views expressed in this post are my personal opinion/interpretation about what I have attended at this conference.
Overal impression
There was many interesting paper presentations this year. The conference had a day of workshop and two days of regular conference papers. Overall, the conference was very enjoyable since it is focused on data mining. The location of the conference was also very good in Guilin, reportedly one of the most beautiful place in China.
Guilin, China (pictures obtained on ADMA website)
Impact of the ADMA conference
ADMA is one of the top data mining conferences in Asia. It is certainly not as popular as PAKDD. But it was said at the opening ceremony that in terms of impact (measured by average citations / paper), ADMA had more impact than PAKDD during the last maybe 5 or 10 years, which is surprising but also great for this conference. It was suggested that one of the reason for this high impact may be that ADMA also accepts applied data mining papers (hence the name ADMA: Advanced Data Mining and Applications), while these papers may be less welcome in some other data mining conferences.
Keynote speech by Osmar Zaiane about Big Data (slides)
There was a very interesting keynote speech given by O. Z. at the conference about big data. I will try to report here the main ideas.
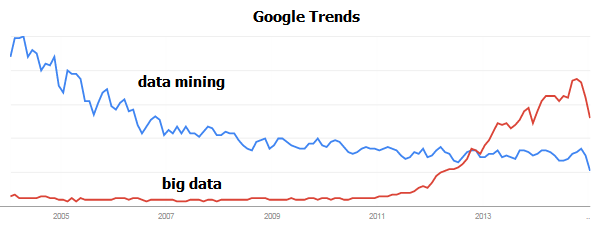
First, O.Z. said that he don’t really like the word “big data” (he prefers Rich Data). By looking at Google Trends, he has shown that the term “big data” may just be a convenient replacement term for “data mining“. In Google Trends, we can see that as the interest in “data mining” decreases, the interest in “big data” increases. It is suggested that one of the reason why the term “data mining” has lost some interest is that it is because of the bad reputation of data mining in the media following the events of 9/11. OZ also compared big data with other terms such as “business intelligence”, saying that unlike “big data”, the term of “business intelligence never really took off but it could have.
Google trends: big data vs data mining
Several statistics were shown that indicates that there is currently a huge hype around big data. The market was evaluated at more than 14 billion $ USD in 2014 and most of the top companies in US are convinced now that they MUST use big data to stay competitive according to some surveys. There is therefore a very huge HYPE around big data. It seems that everybody wants to do big data but maybe it is not always for a good reason or not everybody know why it is appropriate or not.
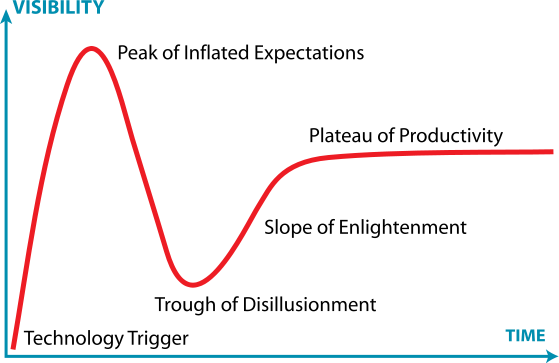
This hype can be compared with the huge hype that occurred around artificial intelligence in the 1970 and end of 1980. Following this hype, there was the AI WINTERS during which people lost interest in AI because there were just too many expectations built on the hype and these expectations could not be met. It was said that a kind of AI winter could happen in the near future for big data because of this huge hype currently happening. And I have to say that I agree about this.
The hype cycle of research and technology is known as the Gartner Hype Cycle. During the AI winters, although a lot of people lost interest in AI, there was always a core group of believer who continued to work on AI despite having less funding. These people have kept AI research alive during this winter. About this observation, my opinion is that it is important to not just jump on the big data trend and forget other important topics of data mining just because of the hype on big data. We certainly have not solved all the problems about “small data” yet.
Gartner Hype Cycle
Another interesting point in this talk is a metaphore about an Elephant and blind peoples based on an old story from China/India. Imagine that several blind peoples are in a room and touching an elephant. Different people may touch different parts of the elephant and have different conclusions about what it is. But none of them can see the global picture. Companies may currently not see the big picture about big data and just jump on the hype because other companies say that it is important. For example, too many people focus on the size of data to define what is big data, while there is many other important characteristics of big data that should not be overlooked
Elephant and blind men (wikipedia)
Some important characteristics of big data are that (1) the data is complex, that (2) we need to solve complex problems requiring machine learning, (3) that we need to integrate various data sources of data that may be heterogeneous and conflictual, (4) that the data may have high velocity, that is coming at high speed (e.g. stream) and that we may need to react very quickly to this data to take decisions, (5) that we may need to assess the reliability of the data, etc.
A challenge is also that data does not provide meaning. Even if we have huge amount of data, it does not mean that we can understand the meaning behind it. So we should always consider the context of the data (metadata) to interpret it properly. An interesting story to illustrate this point is the following. Consider an alien that is coming to earth and that observe humans. The alien may conclude that humans have on average one breast and one testicle. However, this is completely missing the point that there are two genders (male/female). Thus, data as said above does not provide meaning. It is necessary to use critical thinking and context to understand data and perform data analytics.
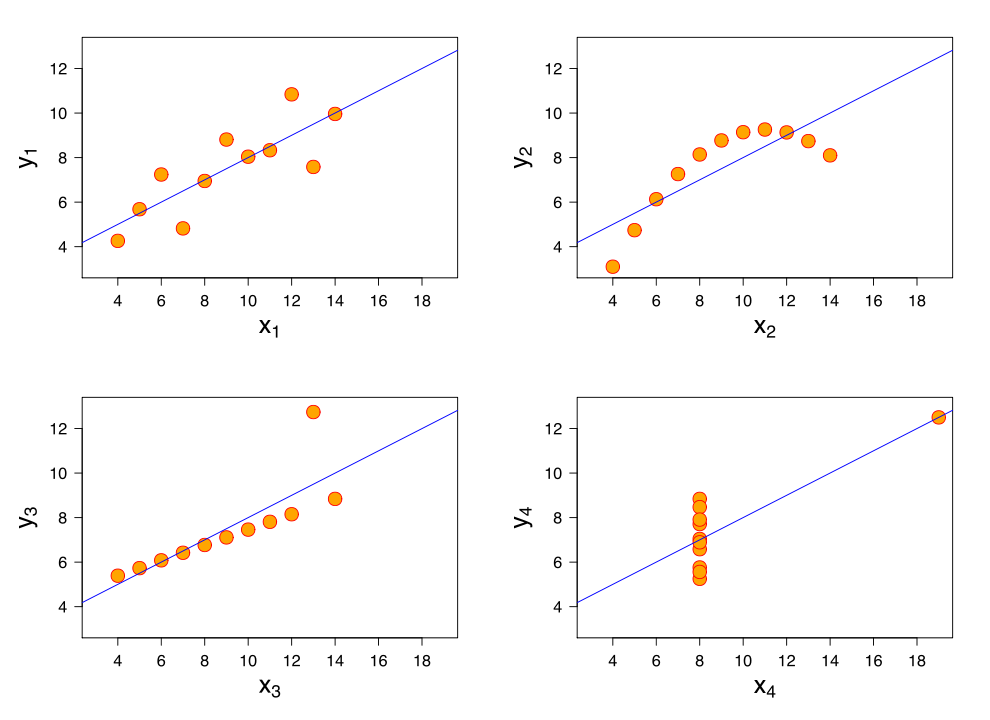
Another very interesting example to illustrate this point is the “Francis Anscombe Quartet“. It is a set of four datasets proposed by Francis Anscombe. These datasets have exactly the same main statistical properties (mean of x = 9, variance = 11, mean of y = 7.5, correlation = 0.816 and same linear regression line. However, these datasets are VERY different if we visualize them in a two dimensional space because of outliers (see picture below). Thus, this example shows that we also need to work on visualization techniques to better understand the data and not just focus on statistical properties that may be misleading.
Francis Anscombe quartet
Another important challenge about big data is “data integration“. An interesting story about this is the story of NetFlix. As most of you probably know, there is a big company for movies renting in the USA that is named NetFlix. This company uses a recommender system to recommend movies to users. A few years ago, NetFlix launched a contest for researchers. The goal was to beat their recommender system by 10 % more accuracy to win 1 million $. However, there was a constraint that participants had to use the provided dataset but could not use any external source of data. The result is that solutions where very complex and have never been used into practice by Netflix, although some of them achieved the 10% improvement. The lesson from this story is that it would have been probably much easier to solve this problem by using external sources of information such as the IMDB movies database and this could have provided more simple solutions. We should thus not be afraid to use different source of data and perform data integration. Moreover there are several research challenges with respect to data integration such as how to deal with conflictual information from various sources of data, etc.
Another challenge related to big data is uncertainty. Consider a person that has an online profile that gives away his age and gender. This kind of information are facts. There is no uncertainty. However, consider that this same person buy some swimming watches. A data mining system could infer that this person is most likely a swimmer. However, it is possible that the person bought the swimming watch as a gift. Thus, in this kind of situations, we should also consider the uncertainty in data to perform data analysis.
There was also a discussion about some pitfalls of big data. It is said that we should train more and more data scientists and also that we should train carefully the manager about what to expect from big data so that appropriate tasks are given to data scientists and that expectations are reasonable.
Another pitfall is that it is tempting to try to find a single solution that could be applied to everything. Currently, in big data, many people think that we need to use Map Reduce to do big data or some very trendy technologies such as deep learning. However, it is very difficult to apply Map Reduce to some particular tasks. Thus, we should not just focus on one technology as a solution to every problems. An interesting analogy is that someone tries to use a screwdriver to fix everything, and even use a screwdriver as a key to start his car. It may works but it is not the most appropriate tool. Actually, we should build some more simple tools that could guide the user to do data analytics without having to learn a lot of complex technologies. It should be as simple as pushing a button. Currently, we can drive a car without understanding everything about how the car works. So why it should not be the same about data analytics? This will certainly require a lot of work, especially on data vizualization.
In conclusion, yes there is a lot of hype about big data. But there is also a real need because currently there is more and more data, and we need to use this data to make decisions.
Keynote speech by Hui Xiong about Big Data and Mobile Recommender System (slides)
A great keynote speak was also given by Hui Xiong. I will try to report some ideas that I have found interesting in this keynote.
It was emphasized that key aspects of Big Data is timely observation, timely analysis and timely solution. What this means is that sometimes we have huge amount of data but we need to make some observation quickly and analyze it very quickly because of time constraints (for example, the user does not want to wait a month to get the result!).
An interesting story about big data is that we can compare it to fishing in a big river. When a human is fishing in a very small river, it is relatively easy to see the fishes since the water is clear, and it is also easy to catch the fishes. However, if we consider a larger river such as the Yangtze river in China, we cannot see the fish anymore and we don’t know what fish to catch. This is the situation of big data.
How to handle big data? It was said that some key points about handling big data are the following. First, we should understand the data characteristics. Second, we should carefully select the features and attributes that are relevant for the analysis that we want to perform. We may have a PB of data. But maybe that just a small part of it is relevant. Third, we should also carefully select the instances in the data to be used for performing the analysis.
Also, it is important to understand business goals to find good research problems. It was reported that H.X. only works with real data for research such as Taxi data or travel data.
Now, for mobile recommender system, there are several challenges. First, the time and cost constraints are important. For example, for a travel recommender system, how much time the user has for travelling? how much can he pay for a travel package? Another challenge is that unlike typical recommender systems such as Collaborative Filtering, in mobile environments, we often need to consider the time dimension or sequence of events. An example that was given to illustrate this point is the work of H.X. about taxi path recommendation (KDD 2009). The goal of this paper was to recommend sequences of locations to the user rather than performing a single recommendation. Other challenges are that data is not uniformly distributed and that data may be heterogeneous.
There was many other points in this talk. But those are the key points that I have noted.
Next year conference
In the opening ceremony of the conference, it was announced that the ADMA 2015conference will be held in Shanghai, and ADMA 2016 will be held in Macau the year after (2016)
Best paper awards
Three best paper awards were given at this conference. Two of them are:
Fournier-Viger, P., Wu, C.W., Tseng, V.S. (2014). Novel Concise Representations of High Utility Itemsets using Generator Patterns. Proc. 10th International Conference on Advanced Data Mining and Applications (ADMA 2014), Springer LNCS 8933, pp. 30-43. (this is my paper! – I’m very happy about that)
Strecht, P., Mendes-Moreira, J., Soares, C. (2014). Merging Decision Trees: A Case Study in Predicting Student Performance. Proc. 10th International Conference on Advanced Data Mining and Applications (ADMA 2014), Springer LNCS 8933, pp. 30-43.
And I don’t remember the third one. Besides, a 10th year most influential paper should be announced soon on the website of the conference because the winner was unable to attend the conference.
==
Philippe Fournier-Viger is an assistant professor in Computer Science and also the founder of the open-source data mining software SPMF, offering more than 80 data mining algorithms.
If you like this blog, you can tweet about it and/or subscribe to my twitter account@philfv to get notified about new posts.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}