
In this blog post, I will discuss how to check if a data mining algorithm implementation is correct and complete. This is a very important topic for researchers who are implementing data mining algorithms since an incorrect implementation may generate unexpected results. It may be also important for those who want to compare two implementations downloaded on the internet for example. There are a few different ways to check if a data mining algorithm implementation works as expected.
![]()
1) Is it theoretically correct?
The first step is to make sure that the algorithm itself does not contain any errors. This can be done before implementing the algorithm. It happens sometimes that the description of algorithms in research papers contains errors. These errors may be some typo or they may be some more fundamental errors. It is thus important to read the paper carefully and understand it well before implementing the data mining algorithm, to detect these errors, if there are any.
2) Testing the algorithm on a small dataset – debugging by hand
After the algorithm has been implemented, it is time to test it. First, I usually try to run the algorithm with some small dataset. For example, to test a sequential pattern mining algorithm, I may use a dataset that contains 5 sequences instead of a dataset containing 100,000 sequences. Using a small dataset is much easier for debugging. I will run the algorithm on a small dataset and check if the results are correctly calculated by hand. Or if there is an example provided in the paper describing the algorithm, I will try to use the same example. If there are some errors, I will also vary the parameters to see if the behavior is still correct on the small dataset. I will use the debugger to find the problem and fix it. I may also use the debugger and check step by step how the algorithm works to see if there is some weird behavior. During this step, I may also use some paper and a pencil to make some example by hand on paper and check if the results generated by the algorithm is the same.
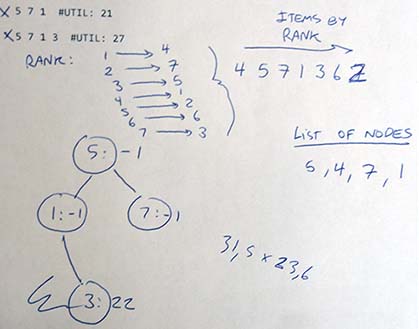
Drawing an example on a piece of paper to debug an algorithm implementation
3) Testing the algorithm on large datasets – comparison with another implementation
Second, I will run the algorithm on larger datasets. The reason is that there are some errors that will only occurs on large datasets. For example, I have recently encountered an integer overflow error that was only occuring when the dataset was very large. To test a sequential pattern mining algorithm, I may use a dataset using 1 million sequences.
If I have some other algorithm implementations for the same problem, I will use them to see if the new implementation generate the same results. A simple way to do that is to take the output file of two implementations and use a software to compare two files such as UltraCompare (not free). These kind of software will quickly highlight the differences between two output file. Then, if there are some differences, I will analyse the results further to see which implementation is incorrect.
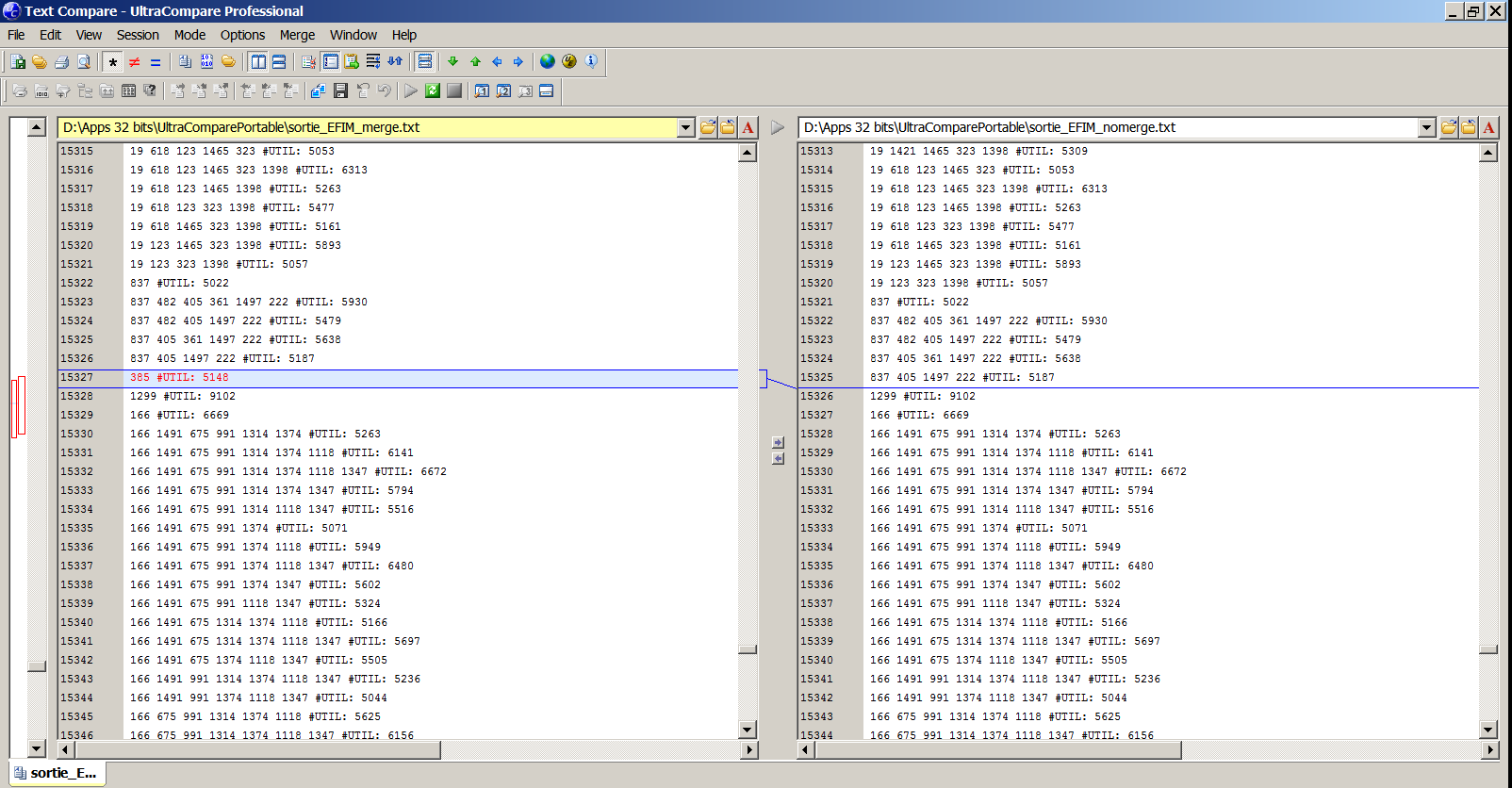
Comparing the output of two algorithm implementations using UltraCompare
4) Testing the algorithm on large datasets – automatic tests
Another way to check if an implementation is correct is to write some automatic tests. The reason is that on large datasets, it is likely impossible to check by hand if all the results are correct. For example, If I run a sequential pattern mining algorithm on a large dataset, it would be too time consuming to check by hand that the support is calculated correctly for all patterns that are found by the algorithm . To address this issue, I will write some code that take each pattern and scan the database to recalculate the support using a brute force approach. This allow to check that the result is correct automatically. And if I find some errors, I will use the debugger to find where they come from, and fix them.
Conclusion
In this blog post, I have discussed how to check if the implementation of a data mining algorithm is correct. It can be quite time-consuming to check if an implementation is correct. Sometimes, I may spend one or two days for debugging. But it is still very important to verify that an algorithm implementation is correct, especially when proposing a new algorithm. If an algorithm is incorrect, it may completely change the results when comparing the algorithm with other algorithms.
==
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 80 data mining algorithms.
If you like this blog, you can tweet about it and/or subscribe to my twitter account@philfvto get notified about new posts.




Thank you so much for your useful topic.
Hi Tai,
Glad you read the blog and it is useful 😉
Best,
Philippe
GOOD BLOG !!