
In this report, I will talk about the 24th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2020), from the 11th to 14th May 2020.

The PAKDD conference
PAKDD is a top international conference on data mining / big data in the Pacific-Asia part of the world. I have attended this conference times and written reports about several editions of the conference. If you are interested, you can read these reports here: PAKDD 2014, PAKDD 2015, PAKDD 2017, PAKDD 2018 and PAKDD 2019.
PAKDD Proceedings
As usual, the conference proceedings of PAKDD 2020 are published by Springer in the Lectures Notes on Artificial Intelligence (LNAI) series. This ensures that the proceedings are indexed in DBLP and other major indexes, and gives good visibility to papers.

This year, there was 628 submissions to PAKDD 2020. From those, 135 papers have been accepted, which means an acceptance rate of 21.5%.
The conference went online
This year, the PAKDD 2020 conference was planned to be held in Singapore. But due to the unforeseen COVID-19 virus pandemic around the world, the PAKDD 2020 conference was held online instead. Part of the registration fee was re-imbursed to the authors because organizers saved money by doing the conference online. And of course, since the conference was online, all social events like banquet, reception were cancelled.
All authors were asked to submit a pre-recorded 13 minute video of their paper in 720p resolution with their slides, before the conference. Then during the conference, authors had to be available to answer questions online after the presentation of their paper. Thus, each paper was alloted a total of 17 minutes. This is somewhat less than previous years where long presentations had about 30 minutes, if I remember well.
The conference could be accessed through the Zoom online meeting system. To attend the different sessions, a password was required, which was made available to registered attendees.
Some video ettiquette tips were given to authors

As for proceedings, since the conference was online, proceedings were made for download from the conference website in PDF format.
Day 1 – Tutorials and workshop day
On the first day, there was 5 workshops and 2 tutorials.
I first went to have a look at the literature based discovery workshop using Zoom. There was about 22 persons in that workshop at 9:26 AM, watching this presentation about using evolutionary algorithms for matching biodemical ontologies.
Then, I popped in the Data Science for Fake News workshop at 9:40 AM to see how it was. Although, it was supposed to start at 9 AM, the workshop had not started. Using the chatroom, I asked and was answered that it was delayed until 10 AM (perhaps some technical problem or someone missing due to time zones?).
Thus, I went next to check the Game Intelligence & Informatics workshop at 9:50. There was about 11 persons watching the presentations at 9:47 AM. Game intelligence is a quite interesting topic. Here is a screenshot from that workshop, where game strategies were analyzed:
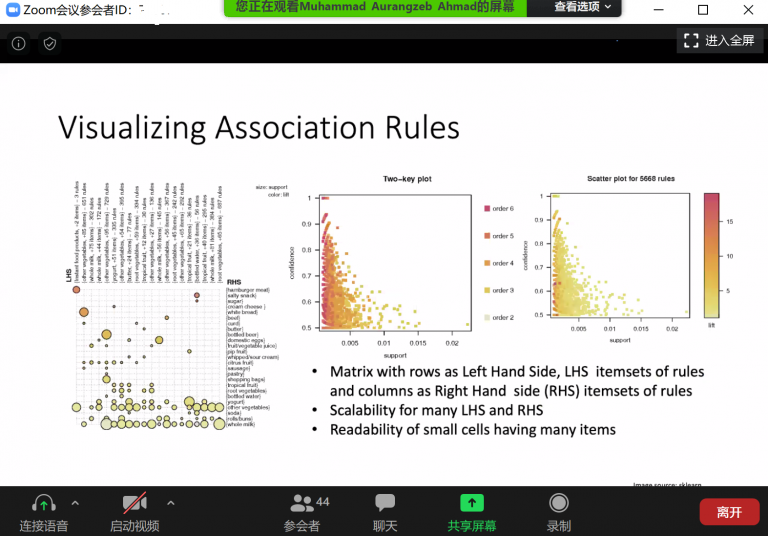
Then, at 9:57 AM I went to have a quick look at the Tutorial on Deep Explanations in Machine Learning via Interpretable Visual Methods, which was in the fourth parallel session. There was about 44 persons watching it, so it seemed to be the most popular session. This topic is interesting as neural networks can be very effective but are mostly black-box models . In that tutorial, they talked about how to interpret such models, and they also discussed some other ways of interepreting knowledge in data mining such as how to visualize association rules (screenshot below).
So far, all of this was quite interesting. And there was some good questions in the sessions that I have attended.
In the afternoon at 2PM, I attended the 9th Workshop on Biologically Inspired Data Mining (BDM 2020). This is a workshop that has been running for many years at PAKDD, that I personally like as it cover various topics such as genetic algorithms, particle swarm optimization (PSO), ant colony optimization, and also applications of such algorithms. There was about 18 persons attending the workshop at 2:11 PM. First, the organizer Shafiq Alam gave an overview of the motivations for biologically inspired data mining by explaining that optimization algorithms like genetic algorithms can be used to quickly find an approximate solutions to hard problems, if we can accept to lose a little bit about the accuracy. Then, some results were about using PSO for clustering and recommendation. Then, there was some paper presentations, and a discussion about current trends.

At the same time in the afternoon, there was a Tutorial on deep Bayesian network that had about 31 attendees at 2:19 PM, and a workshop on Learning Data Representations for clustering, which had about 14 attendees at 14:21 PM. Overall, it seems that the tutorials were the most popular sessions during this first day.
Day 2
At 8:30 to 9:00 AM, there was the conference opening. There was about 59 persons in that session at 8:58 AM. Some awards were announced:

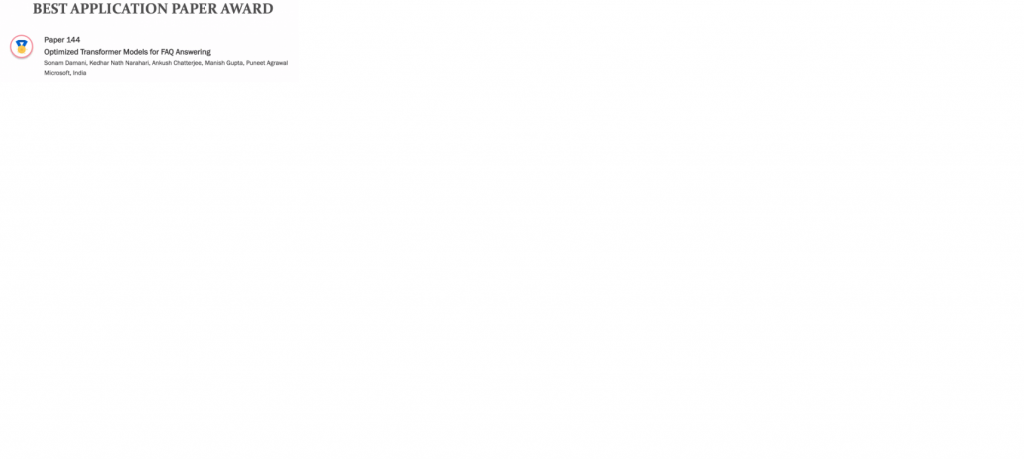


It was followed by a keynote from Prof. Bing Liu about open-world AI and “continual learning”, which discusssed the need for software that can continuously learn. Here are a few slides:


This was followed by two Industry talks, one by Ussama Fayyad and another by Ankur Teredesai. Below is a few slides from the talk of A. Teredesai about AI for health, which was watche. He discussed how data mining and AI can help for healthcare. In particular, he talked about epidemiological models for diseases such as COVID-19. At 11:18 AM, there was about 27 persons in that session. That talk interesting but there was some internet connection problems at some point such that the audio was hard to hear for a few minutes. But then, it was OK.

Then, in the afternoon, there was paper presentations.
Day 3
On the morning 8:30 AM, there was a keynote talk by Inderjit S. Dhillon about multi-output prediction. There was about 42 persons watching at 8:51 AM. Here is a screenshot of that talk:

In the afternoon, there was a keynote talk by Prof. Samuel Kaski titled “Data Analysis with Humans” about how humans can participate in the machine learning process. There was about 34 persons attending the talk at 2:08 PM. He first illustrated that different problems (and method) require different levels of human intervention.
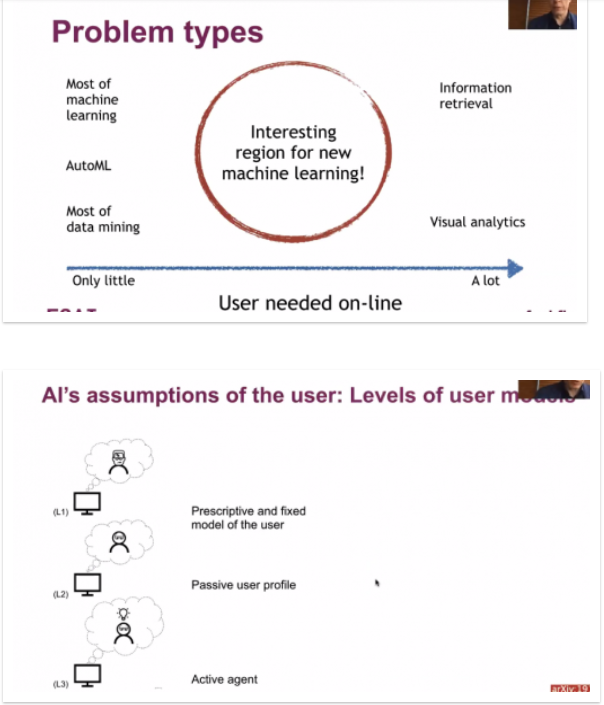
Generally, the user can participate in different ways in the machine learning of data mining process.
First the user can be a passive data source. Second the user can participate more actively in the process of machine learning or data mining to guide the software program.

Here is a slide from approach 1).
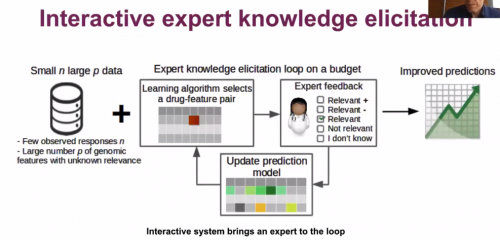
Then, there was more slides and details but I did not take note of everything.
Then, after that there was more paper presentations.
Day 3
On Day 3, there was the most influential paper talk, a keynote talk by Prof. Jure Leskovec in the afternoon, and more paper presentations.
Papers about pattern mining
Now I will talk a little bit about papers related to pattern mining, as it is one of my topics of interest. I presented a paper about a new algorithm named LTHUI-Miner to discover high utility itemsets that are trending in non predefined time periods in customer transaction databases. This is the work of my master degree student:
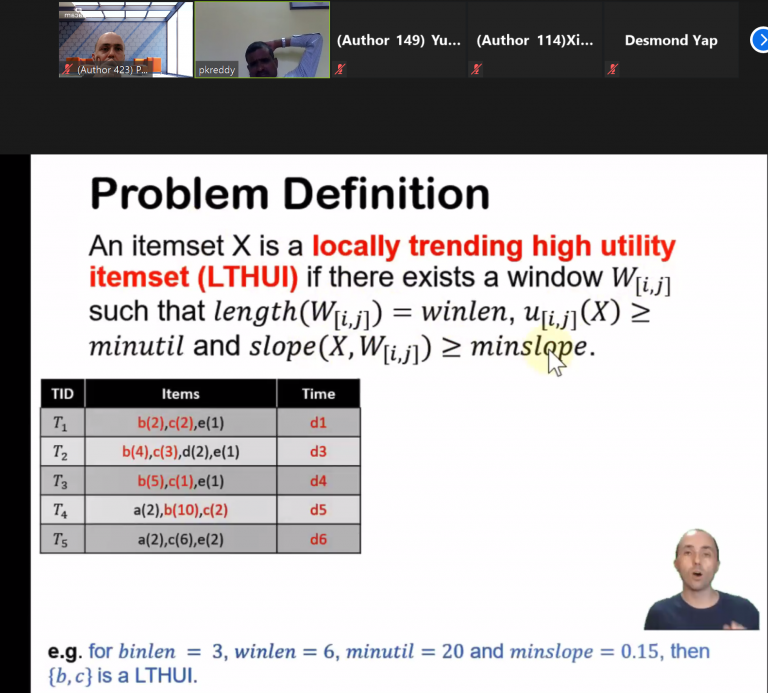
| Fournier-Viger, P., Yang, Y., Lin, J. C.W., Frnda, J. (2020). Mining Locally Trending High Utility Itemsets. Proc. 24th Pacific-Asia Conf. Knowledge Discovery and Data Mining (PAKDD 2020), Springer, LNAI [video] |
You can watch the video of my presentation here.
Also another paper related to pattern mining that was published in PAKDD this year is about discovering frequent subsequences in a set of sequences using an algorithm called Tree-Miner:
Tree-Miner: Mining sequential patterns from SP-Tree. Redwan Ahmed Rizvee (University of Dhaka), Chowdhury Farhan Ahmed (University of Dhaka), Mohammad Fahim Arefin (University of Dhaka)
Is this online format a success?
Overall, the online format of this conference is fine. But I miss the social activities of an offline conference like the coffee breaks, where we can talk with other researchers to exchange ideas and meet new people. For me, this is perhaps the most interesting parts of a conference. For me, this is one of the most interesting aspects of a conference.
Also, as a suggestion, it would have been nice if there was a playback feature to watch presentations that we have missed. In my case, I am in the same time zone as Singapore so it was convenient for me to watch the presentations, but I can imagine that people from some other countries (e.g. some part of Canada with a 12 hours time difference) would have a harder time to watch some presentations.
Special journal issues
Some papers were invited for a special issue in the JDSA journal. This is always interesting to be invited in a special issue. However, although this journal is published by Springer, a problem is that this journal is still quite new, and as such it is to my knowledge not indexed in databases like SCI or EI. In some countries like where I work, this is important and papers not indexed do not have so much value. So for this reason I had to decline the invitation to extend my paper. I would have prefered to be invited in a special issue in a more established journal like some other conferences do.
In the call for papers, there was also a mention that some papers would be invited for an issue in the KAIS journal. This is a quite good journal, but apparently it was only for the few very best papers.
Conclusion
Overall, it was an interesting conference. Due to the virus situation, the conference was held online. The organizers manage to organize the conference very well in this situation. Looking forward to PAKDD 2021 next year.
Update: You can now also read my report about PAKDD 2024 in Taipei.
—
Philippe Fournier-Viger is a computer science professor and founder of the SPMF open-source data mining library, which offers more than 170 algorithms for analyzing data, implemented in Java.




Pingback: Real Conferences VS Virtual Conferences | The Data Mining Blog
Pingback: A Brief Report about ACIIDS 2021 (13th Asian Conference on Intelligent Information and Database Systems) | The Data Mining Blog
Pingback: The PAKDD 2019 conference (a brief report) | The Data Mining Blog
Pingback: The PAKDD 2015 Conference (a brief report) | The Data Blog