
In this blog post, I will discuss the PAKDD 2018 conference (Pacific Asia Conference on Knowledge Discovery and Data Mining), in Melbourne Australia, from the 3rd June to the 6th June 2018.

About the PAKDD conference
PAKDD is an important conference in the data science / data mining research community, mainly attended by researchers from academia. This year was the 22nd edition of the conference, which is always organized in the pacific asia region. In the last few years, I have attended this conference almost every year, and I always enjoy this conference as the quality of research papers is good. If you are curious about previous conferences, I have previously written reports about the PAKDD 2014 and PAKDD 2017 conferences.
The conference was held in the Grand Hyatt Hotel, in Melbourne, Australia, a modern city.

During the opening ceremony, several statistics were presented about the conference. I will share some pictures of some slides below that give an overview of the conference.
A picture of the opening ceremony

This year, more than 600 papers were submitted, which is higher than last year, and the acceptance rate was around 27%.



The papers were published in three books published by Springer in the LNAI (Lecture Notes in Artificial Intelligence) series.


Below is some information about the top 10 topics of the papers that were submittedBelow is some information about the top 10 accepted areas, where more papers have been accepted. For each topic, two values are indicated. The first one indicates the percentage of papers on this topic, while the second one indicates the acceptance rate of the topic.


Below, there is a chart showing the acceptance rates and attendance by countries. The top two countries are the United States and China. Five workshops have been organized at PAKDD 2018, as well as a data competition., and three keynote speakers gave talks.



And here is the list of previous PAKDD conference locations:

It was also announced that PAKDD 2019 will be held in Macau (http://pakdd2019.medmeeting.org/Content/91968 ), China. Moreover, I also learnt that PAKDD 2020 should be in Qingdao, China, and PAKDD 2021 should be in New Dehli, India.
Keynote speech by Kate Smith Miles
A very interesting Keynote speech was given by Kate Smith-Miles with the title “Instance Spaces for Objective Assesment of Algorithms and Benchmark Test Suites“. I think that this presentation was very interesting and can be useful to many, so I will give a brief summary of the key points and provides a few pictures of the slides with comments. What is the topic of this talk? It is about the evaluation of data mining algorithms to determine which algorithm is the best and in which situation(s).

In data mining, usually, when a new algorithm is proposed, it is compared with some state-of-the-art algorithms or baseline algorithm to show that the new algorithm is better. According to the No Free Lunch Theorem, it is quite difficult to design an algorithm that is always better than all other algorithms. Thus, an algorithm is typically better than other algorithms only in some specific situations. For example, an algorithm may perform better on datasets (instances) that have some specific properties such as being dense or sparse. Thus, the choice of datasets used to evaluate an algorithm is important as results will then provides insights on the behavior of the algorithm on datasets having similar features. Thus, to properly evaluate an algorithm, it is important to choose a set of databases (instances) that are diverse, challenging and real-world like.

For example, consider the Travelling Salesman Problem (TSP), a classic optimization problem. On the slide below, two instances are illustrated, corresponding to Australia and United States. The database instance on the left is clearly much easier to solve for the TSP problem than the one on the right.
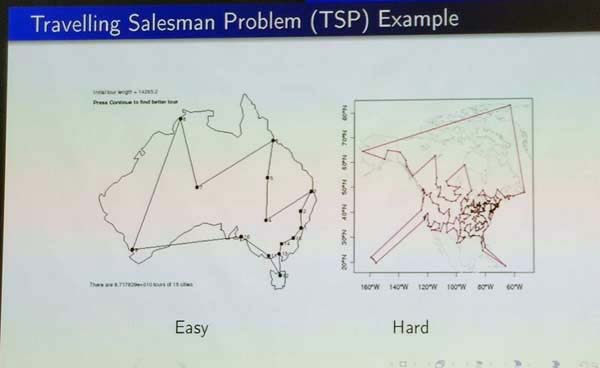
Thus, an important question is how the features of database instances help to understand the behavior of algorithms in terms of weaknesses and instances. Some other relevant questions are how easy or hard are some classic benchmark instances? how diverse are they (do they really allow to evaluate how an algorithm behave in most cases, or does these instances do not cover some important types of databases)? do the benchmark instances are representative of real-world data?

To address this problem, the speaker has developed a new methodology. The main idea is that database instances are described in terms of features. Then, a set of instances can be visualized to see how well they cover the space of all database instances. Moreover, by visualizing the space of instances, it is easier to understand when an algorithm works well and when it doesn’t. Besides, in the proposed methodology, it is suggested to generate synthetic instances using for example a genetic algorithm to have instances with specific features. By doing that, we can ensure to have a set of instances that provide a better coverage of the instance space (that is more diverse) for evaluating algorithms, and thus provide a more objective assessment of the strengths and weaknesses of algorithms.

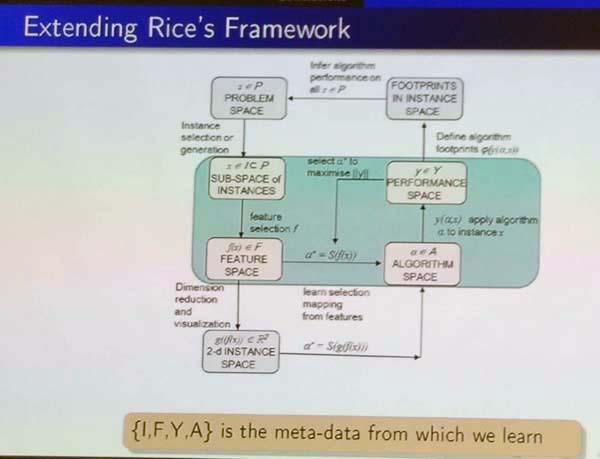

Below, I show a few more slides that provides more details about the proposed methodology. This is the overall view. The first step is to think about why a problem is hard and what are the important features that makes an instance (database) a difficult one. Moreover, what are the metrics that should be used to evaluate algorithms (e.g. accuracy, error rate).



The second step is about creating the instance spaces based on the selected features from the previous step, and determine which ones are more useful to understand algorithm performance. The term step is to collect data about algorithm performance and analyze in which parts of the space and algorithm performs well or poorly. This is interesting because some algorithm may perform very well in some cases but not in others. For example, if an algorithm is the best even in just some specific cases, it may be worthy research.In step 4, new instances are generate to test other cases that have not been tested by the current set of instances. Then, the step 1 can be repeated again based on results to gain more information about the behavior of algorithms.
So this is my brief summary of they key ideas in that presentation. Now, I will give you my opinion. This presentation highlights an important problem in data mining, which is that authors of new algorithms often choose just a few datasets where their algorithm perform well to write a paper but ignore other datasets where their datasets do not perform well. Thus, it sometimes become hard for readers to see the weaknesses of algorithms, although there is always some. This is also related to the problem where authors often do not compare their algorithm with the state-of-the-art algorithms and do not use appropriate measure to compare with other algorithms. For example, in my field of pattern mining, many papers do not report the memory consumption or compare new algorithms with outdated algorithms.
Organization of the conference
The conference is quite well-organized. The location at the Grand Hyatt Hotel is fine, and the city of Melbourne is also a great city with many stores and restaurants, which is interesting and convenient. By registering to the conference, one has access to the workshops, paper presentations, banquet and a welcome reception. Here is a picture of the registration desk, and conference badge:


Keynote by Rajeev Rastogi (director of machine learning at Amazon)
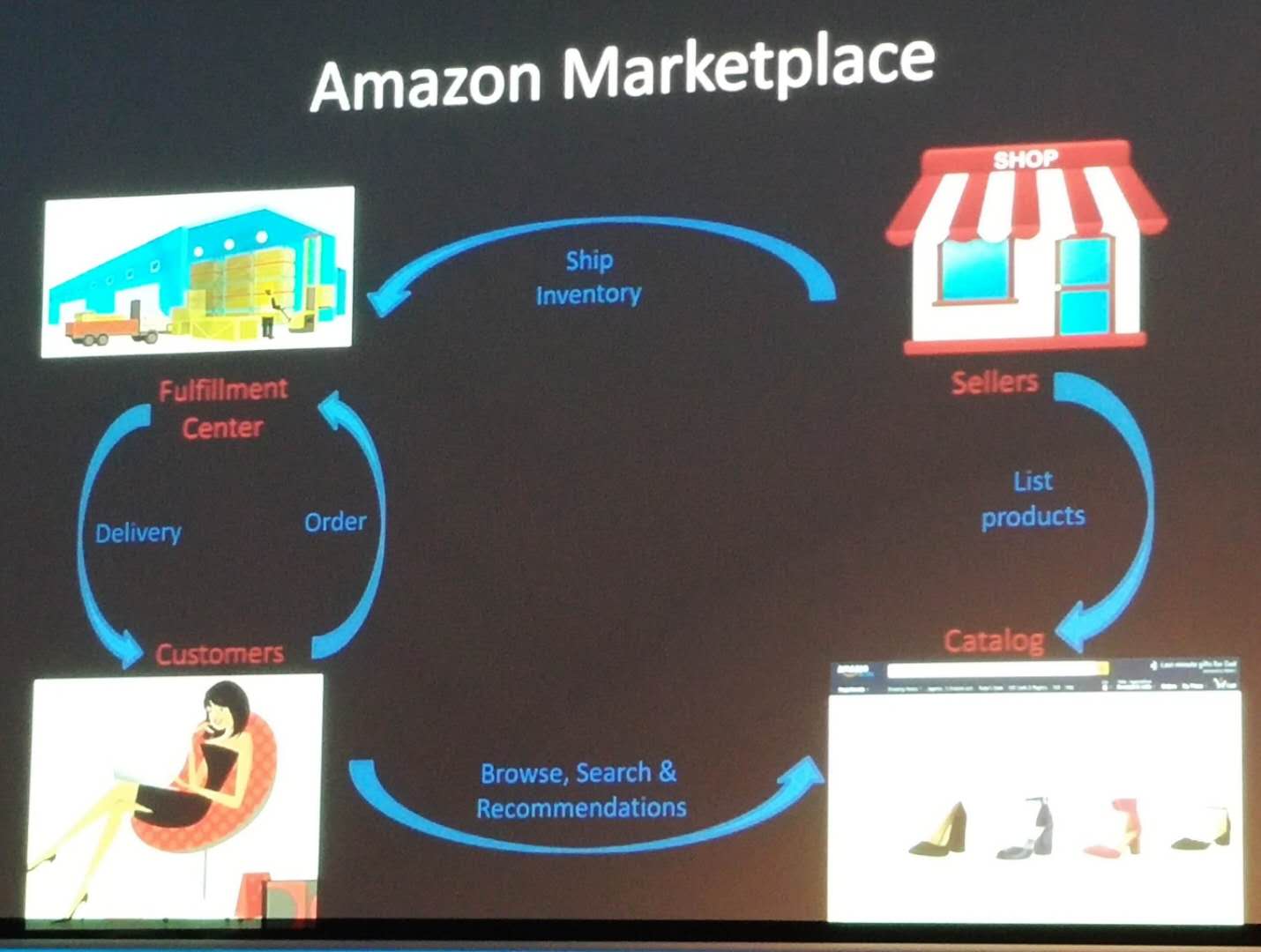
The speaker first gave an overview machine learning applications at Amazon. Then, he discussed question answering and product recommendation. Here is a slide showing the ecosystem of Amazon.
They use machine learning, to increase product selection, lower prices, reduce delivery times to improve customer experience, and maintaining customer trust. Here is an overview:

There is a lot of applications of Machine Learning at Amazon. A first application is product demand forecasting, which consists of predicting the demand of a product up to one year in the future.

For this problem, there is several problems to solve such as the cold start problem (having no data about new products), some products having seasonal patterns, and some products having demand spikes. Demand prediction is used by management to make orders of products, to make sure that products are in stock at least 90% of the time when a user wants to buy it.
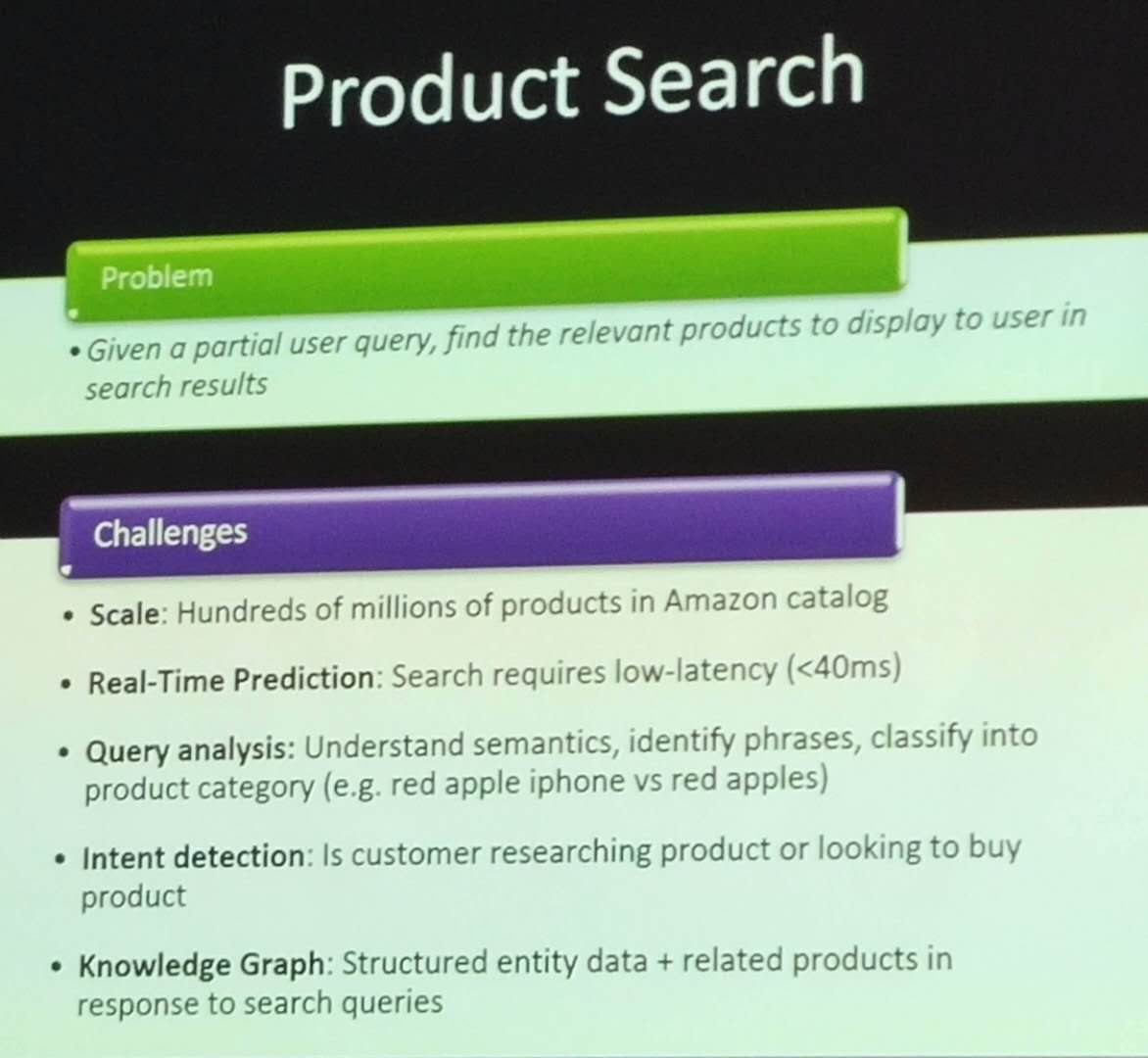
Another key application is product search. Given a query made by a user, the goal is to show relevant products to the user. Some of the challenges are shown below:
Another application is product classification, which given a product description provided by a seller, map it to the appropriate node in a taxonomy of products. Some of the challenges are as follows:

Another application is product matching, which consists of identifying duplicate products. The reason is that if the user sees several times the same products in the search results, it gives a bad user experience. Some of the challenges are:

Another application is information extraction from review. Many products receive thousands of reviews, which a user typically cannot read. Thus, Amazon is working on summarizing reviews, and generating product attribute ratings (ratings of specific features of products such as battery life and camera). Some of the challenges are to identify which attributes of products are relevant, identifying synonyms (sound vs audio), coping with reviews written in an informal way and linguistic style.

Another application is product recommendation, which consists of “recommending the right product to the right customer in the right place at the right time”.
Another application is the use of drones to deliver packages safely to homes in 30 minutes. This requires for example to avoid landing on a dog or child.
Another application is robotics to pick and transport products from shelves to packaging areas in Amazon warehouse, called “fullfillment centers”.
Another application is a visual search app, which let users take a picture of a product to find similar products on Amazon.
Another application is Alexa, which requires voice recognition.

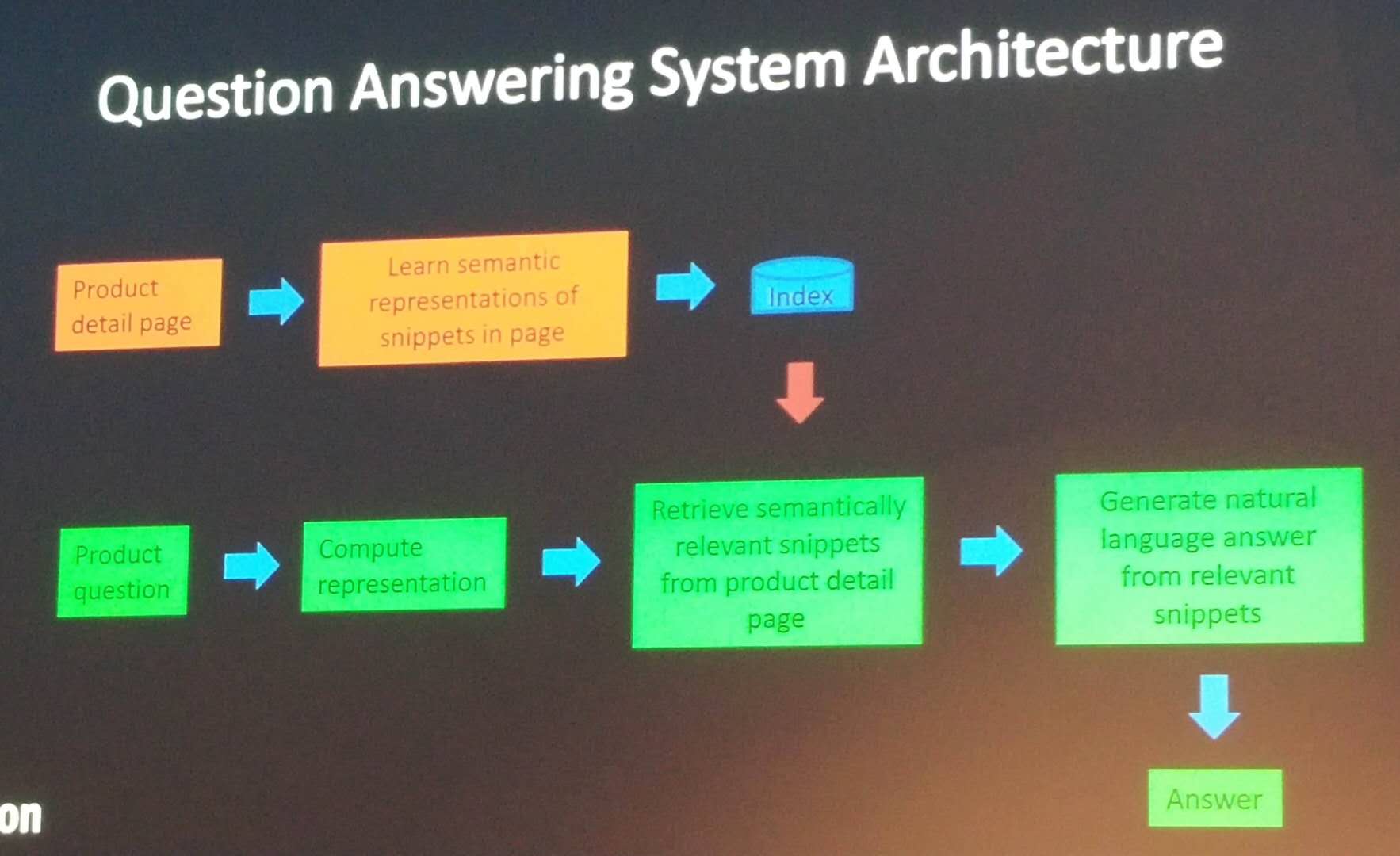
Another application is product question answering. On the Amazon website, users can ask question about products. A first type of questions is about product features such as: what is the weight of a phone? Some of these questions can be answered automatically by extracting the information from the product description or user reviews. Another type of question is about product comparison and compatibility with other products. Some of the challenges related to question answering are:

Here is a very high level overview of the question answering system architecture at Amazon. It relies on neural networks to match snippets of product description or reviews to user questions.
Another problem is product size recommendation to user. This is an important problem because if users make incorrect purchases, they will return the products, which is costly to handle. Some of the challenges are:

The conference banquet
The banquet was organized also at the Grand Hyatt hotel. It was a nice dinner with a performance done by some Australian aboriginal people. Then, it was followed by a brief talk by Christos Faloutsos, and the announcement of several awards. Here is a few pictures.
The performance:





The best paper awards:
Last day
On the last day, there was another keynote, and also results from the PAKDD data competition, as well as more paper presentation
The lack of proceedings
A problem was that the proceedings of PAKDD 2018 were not offered to the attendees, neither as a book or a USB drive.During the opening ceremony, it was said that it was a decision of the organizers to only put the PDF of camera-ready articles on the PAKDD 2018 website. Moreover, they announced that they ordered 30 copies of the proceedings (books) that would be available for free before the end of the conference. Thus, I talked with the registration desk to make sure that I would get my copy of the proceedings before the end of the conference. They told me to send an e-mail to the publication chairs, which I did. But at the end of the conference, the registration desk told me that the books would just not arrive.
So I left Australia. Then, on the 14th June, about 8 days after the conference, the publication chairs sent me an e-mail to tell me that they would receive the books in about two more weeks, thus almost one month after the conference. Moreover, they would not ship the books. Thus, if we want to have the book, we would have to go back to Melbourne to pick it up.
Conclusion
This year, PAKDD was quite interesting. Generally, the conference was well-organized and I was able to talk with many other researchers from various universities and also the industry. The only issue was that the proceedings were not available at the conference. But overall, this is still a small issue. Looking forward to PAKDD 2019 in Macau next year!
Update: You can also now read my reports about PAKDD 2019,PAKDD 2020 and PAKDD 2024.
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.




Pingback: The PAKDD 2017 conference (a brief report) - The Data Mining BlogThe Data Mining Blog
Pingback: Why attending academic conferences is important? | The Data Mining Blog