
This week, I have attended the PAKDD 2017 conference in Jeju Island, South Korea, this week, from the 23 to 26th May. PAKDD is the top data mining conference for the asia-pacific region. It is held every year in a different pacific-asian country. In this blog post, I will write a brief report about the conference.

Conference location
The PAKDD conference was held in the city of Seogwipo on Jeju island, a beautiful island in South Korea, which is famous for tourism, especially in Asia. Here is a map of the location.
In particular, the PAKDD conference was held at the Seogwipo KAL hotel.

The hotel was well-chosen. It is about 1 km from the city, beside the sea.
Conference proceedings
The proceedings of the PAKDD 2017 conference are published by Springer in the Lecture Notes in Artificial Intelligence series. This ensures a good visibility to the papers published in the proceedings, which are indexed in the main computer science indexes such as DBLP.
The proceedings were given on a USB drive (4 Gb) rather than as a book, as many other conferences have been doing in recent years. Personally, I like to have proceedings as books, but USB drives are probably more friendly for the environment.

In general the quality of the papers at PAKDD conferences is good. This year, 458 papers were submitted. Among those, 45 papers were accepted as long papers and 84 as short papers. Thus, the global acceptance rate was about 28%.
Below, I present various slides from the opening ceremony presentation, which provides information about the PAKDD conference this year.
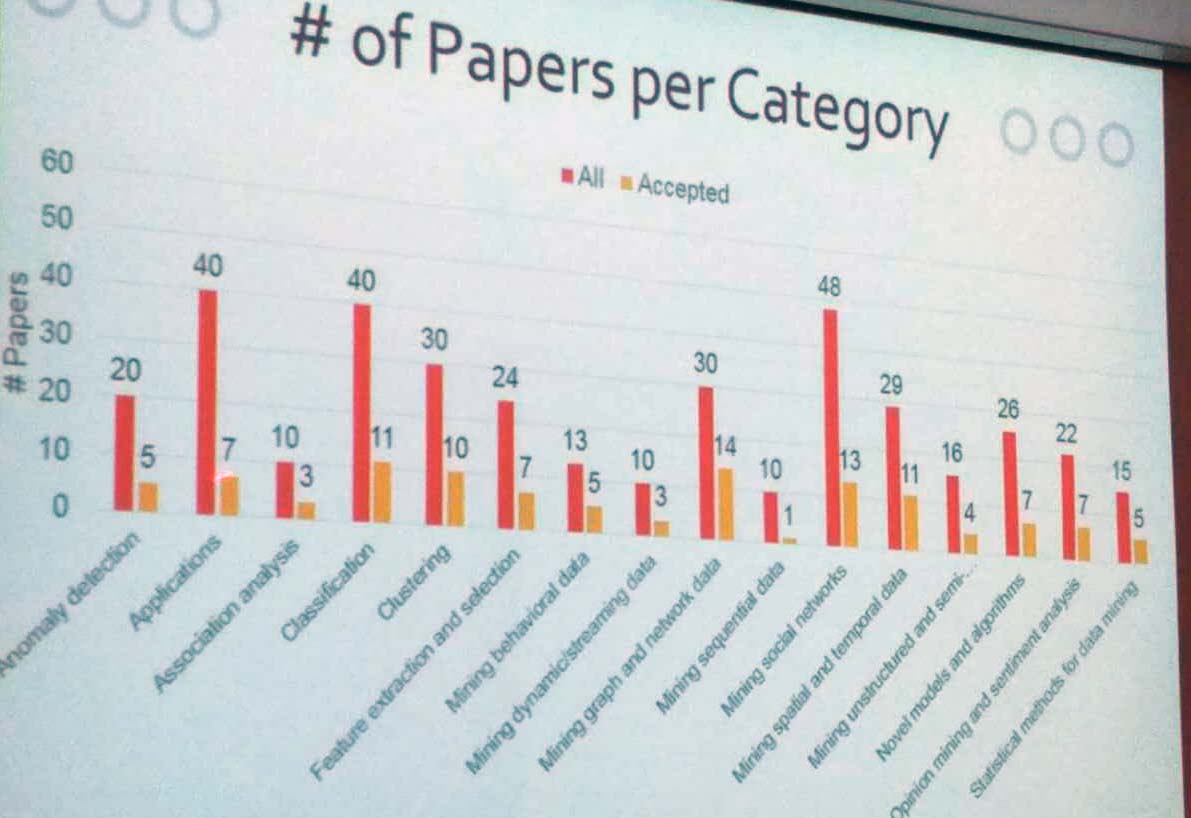
- The number of papers per category (submitted / accepted) is shown below. It is interesting to see that a large amount of applications and social network papers have been rejected. And for the topic of sequential data, only 1 paper out of 10 was accepted.
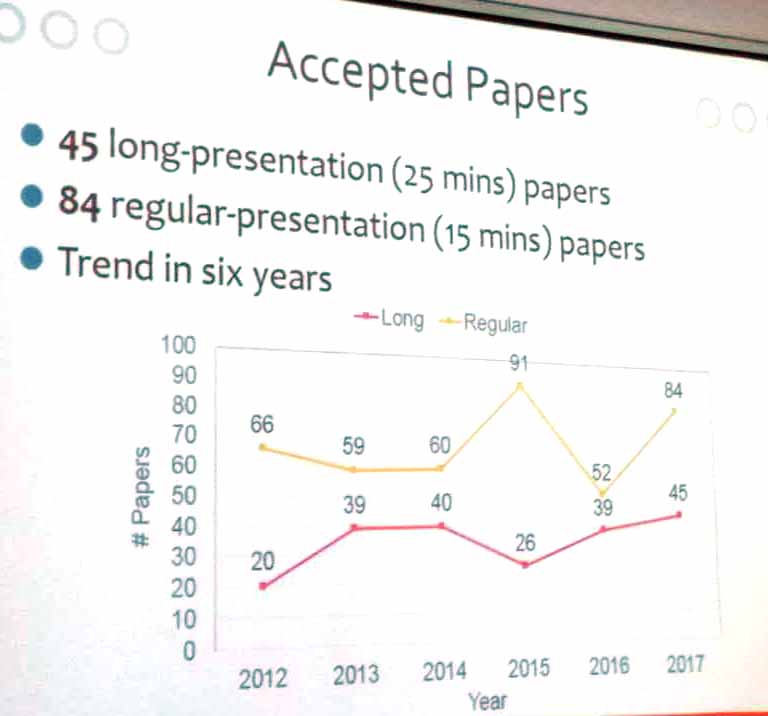
2) The number of accepted long and short papers at PAKDD forthe last six years is presented below.
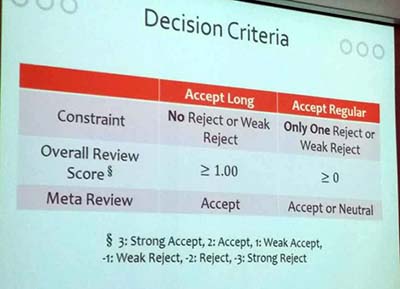
3) The decision criteria for accepting a paper at PAKDD are shown below.
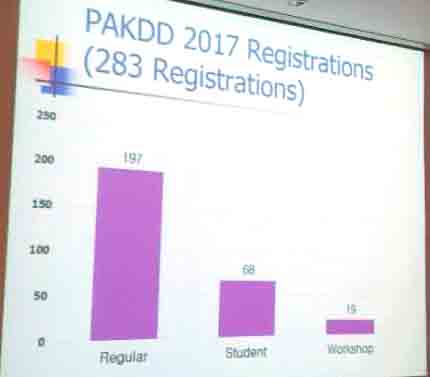
4) There was 283 persons who have registered for PAKDD this year.
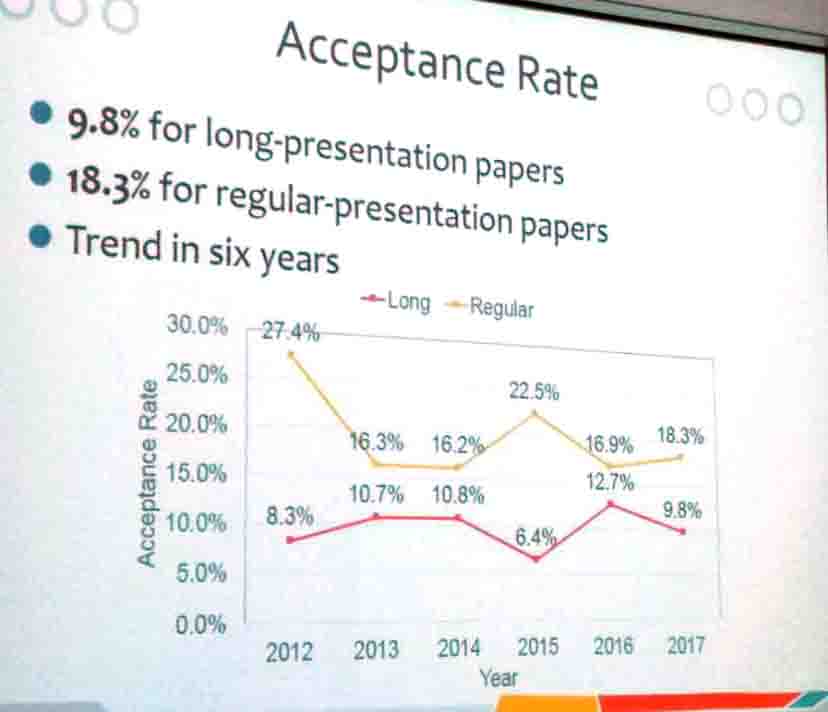
5) The acceptance rate of long and short papers at PAKDD during the last six years
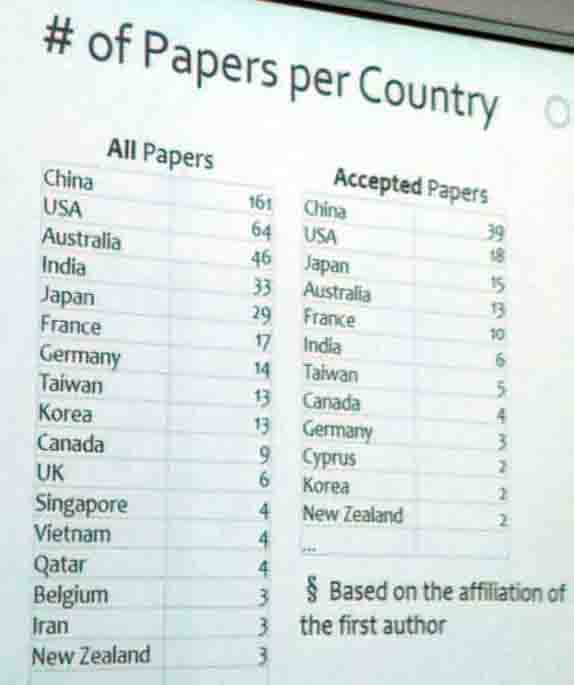
6) The number of submitted vs accepted papers by country this year. We can observe that China has the largest number of papers accepted and submitted.
Day 1 – workshops and tutorials, reception
On the first day, the registration started at 8:00 AM.

It was then followed by various workshops and tutorials. I have attended a workshop about Biologically Inspired Data Mining, a popular topic, which covers the applications of algorithms such as neural networks, bee swarm optimization, genetic algorithms, and ant colony optimization, to solve data mining problems. Evolutionary algorithms are quite interesting as they can find approximate solutions to data mining problems that are quite good solutions, while running much faster than traditional algorithms that find an optimal solution. There was also some tutorials that I did not attend on information retrieval, recommender systems and tensor analysis. Besides, there was workshops on security, business process management, and sensor data analytics.
In the evening, there was a reception, which was a good opportunity for discussing with other researchers.
Day 2 – main conference, opening ceremony
There was an opening ceremony, followed by a keynote by Sang Kyun Cha from the Seoul National University of Korea. The keynote was about a potential fourth industrial revolution that would occurs due to the growth of AI-based services and big data technologies. This would lead to a need for more skilled workers such as engineers or “data scientists”. The talk was interesting but personally I prefer talks that are a little bit more technical. After that, there was multiple sessions of paper presentations.
Besides technical sessions, I also discussed with some representatives from Nvidia who were promoting a new supercomputer specially designed for training deep learning neural networks. It is called NVIDIA DGX-1 and costs around 200,000 $ USD. According to the promotional material, this computer has a eight Tesla P100 GPUs, each with 16 GB of memory, a total of 28672 NVIDIAN CUDA cores, and two dual 20-core Intel Xeon E5-2698 v4 2.2 Ghz processors. But what is the most interesting is that this GPU based system is claimed to be 250 times faster than a conventional CPU-only server for deep learning. I saw that there is also a similar product by IBM called the IBM Minsky, also equipped with NVidia GPUs. This is especially interesting for those working on deep learning related topics.
NVidia DGX1
Day 3 – main conference, excursion, banquet
On the third day of the conference, there was a keynote speech by Rakesh Agrawal, a senior researcher, who is one of the founder of data mining. The talk was about the usage of social data.. The main question addressed in this talk was whether social data from websites such as Twitter is garbage or it can be useful for businesses. R. Agrawal presented a project that he carried a few years ago at Microsoft where he analyzed Twitter data to study the opinion of people about Microsoft products. He also described a work where he compared the results of the Bing and Google search engines, and the result obtained when searching using social data rather than traditional search engines. The conclusion was that social data is certainly useful. R. Agrawal also gave some advices that young researchers should try to choose good research topics that are useful and can have an impact rather than just focusing on publishing a paper as quickly as possible.

On the afternoon, there was an excursion to Seopjikoji beach, Seongsan Sunrise Peak and Seongeup Folk Village.


In the evening, there was a banquet at the Seogwipo KAL hotel, with a musical performance.


Day 4 – main conference, closing ceremony
On the fourth day, there was a keynote by Dacheng Tao, from the University of Sydney Australia about current challenges in artificial intelligence. It was followed by several technical sessions, a lunch and a closing ceremony.
Conclusion
The conference was quite interesting. I had the occasion to meet many interesting people from academia and also from industry (e.g. Microsoft, Yahoo, Adobe, Nvidia). PAKDD is not the largest conference in data mining but it is a quite good conference, especially for the asia-pacific region, and the quality of the papers is quite high. It was announced that next year, the PAKDD 2018 conference will be held in Melbourne, Australia. I will certainly try to attend it.
By the way, I had previously written a report about the PAKDD 2014 conference in Taiwan and PAKDD 2018 conference and recently about PAKDD 2019,PAKDD 2020 and PAKDD 2024). You may have a look also at those reports if you are interested by PAKDD.
Hope you have enjoyed this post!
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.




Pingback: The PAKDD 2015 Conference (a brief report) | The Data Blog
Pingback: PAKDD 2018 Conference (a brief report) | The Data Blog
Pingback: The PAKDD 2019 conference (a brief report) | The Data Blog
Pingback: The PAKDD 2020 conference (a brief report) | The Data Blog