
In this blog post, I will talk about the well-known open-source library of data mining algorithms implemented in Java, which I am the founder of. I will give a brief overview of its history, discuss some lessons learned from the development of this library, and then give a glimpse of what’s next for the development of the library.
A brief history of SPMF
The first version of this library was designed at the end of 2008 as a term project for a data mining course during my Ph.D. at University of Quebec in Montreal. At that time, I had implemented about five algorithms such as Apriori and AprioriClose. The code was not so great and there was no website. And it was just an unnamed project. 😉
Then, in 2009, I started to work on implementing and developing new sequential pattern mining algorithms for my Ph.D. project, and to add them to the same project. I added several algorithms such as PrefixSpan and BIDE. I then launched the SPMF website during the summer of 2009, and choose the name SPMF for the project. At that time, the website had few information. It just provided a few instructions about how to download the library and use it.
Over the years, I have added much more algorithms to the librayr. There are now more than 90 algorithms offered in SPMF. I have implemented many of them in my spare time, some of them for my research, some of them just for my personal satisfaction, and also several contributors have provided source code of algorithms for the library, and have reported bugs, and suggestions, which have also greatly helped the project. I have also added a user graphical interface and command line interface to SPMF in the last few years.
The SPMF graphical user interface
The source code of SPMF has been quite improved over the year. Originally, there was a lot of duplicated code in the project. In the years 2012-2013, I have made a major refactoring of the source code that took about 1 month. I removed as much duplicated code as possible. As a result, the number of source code files in the project was reduced by 25 %, the number of lines of code was reduced by 20 %. Moreover, I added about 10,000 lines of comments during this refactoring. In the last two years, I have also added several optimizations to the source code of SPMF because some code written in the early year was not really optimized as I did not have enough experience implementing data mining algorithms.
Since then, SPMF has become quite popular. It is an especially important library in the field of pattern mining (discovering patterns in databases). The number of visitors on the website recently reached 190,000. Moreover, SPMF was cited or used in about 190 research papers in the last few years, which is awesome. Here is a brief overview about the number of visitor on the website: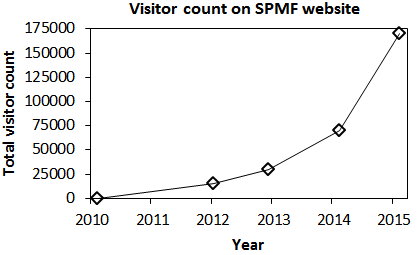
The lessons learned
From the SPMF project, I have learned a few general lessons about providing an open-source project.
- It is important to make a high-quality documentation of how to use the library. If there is no appropriate documentation on the website, then users will always ask questions about how to do this or do that, and the developers will spend a lot of time to answer these questions. The users will also be less likely to use the library if it is too complicated to use. On the contrary, if a good documentation is provided, then most users will find answers in it. Thus the reviewers will spend less time always answering the same questions and users are more likely to use the software. Over the years, I have updated the website so that it provides information for the most common questions. I have also added a developpers’s guide, a documentation of how to use each algorithm, etc. to try to make the software as easy to use a possible.
- The code should follow standard conventions and be well-documented. To make an open-source project easily reusable and understandable by other users, the code should contain a good amount of comments, be well-structured, and follow commonly used conventions. For example, in Java, there are standard conventions for writing code and documenting code with Javadoc. In SPMF, I have tried to follow these conventions as much as possible. As a result, several users have said to me that the code of SPMF is very easy to understand. It is important to write good code. I understand that many programmers may not like to document their code, but it is important to do it as it makes it much more understandable for users.
- It is important to choose an appropriate license for an open-source project. I originally choose theCreative Common License for SPMF in 2009. But I then noticed that it was rarely used for licensing software. I thus then read about several licenses and choose the more commonly used GPL, which I prefers.
- Listen to the users. It is important to listen to what users need in terms of features. This gives a good indication of what should be included in the software in the next releases. If many users request a specific feature, it is probably very important to provide it.
What’s next?
So what is next for SPMF? I intend to continue developing this library for at least several years 😉
I have currently implemented several new algorithms that have not yet been released such as: FOSHU, d2Hup, USpan, TS-Houn, HUP-Miner, GHUI-Miner, HUG-Miner mainly for high-utility pattern mining. Also my students have implemented several others for sequence prediction and pattern mining such as: CPT+, CPT, DG, TDAG, AKOM and LZ78, and EFIM and HUSRM. All these algorithms should be released soon in SPMF. I think that several of them may be released in a new major release in September of October. Thus, SPMF should reach the milestone of 100 algorithms before the end of 2015.
Other improvements that I would like to add in the future are to handle more file types as input. For example, it would be great to add a module for converting text files to sequences for sequential pattern mining. Another idea is to add visualization capabilities. Currently, the results of most algorithms offered in SPMF are presented as text files to the user. It would be great to add some visualization modules. Another idea is to add some modules for automatically running experiments for comparing algorithms. This is especially useful for data mining researchers that wish to compare the performance of data mining algorithms.
For the future, I also hope that more collaborators will provide source code to the project. Several researchers have used SPMF in their projects but not many have given back source code to the project. It would be great if more users could provide source code when proposing new algorithms. This would greatly helps the project. If more students or professors would like to contribute to the project, it would be also very welcome.
Also, another important aspect to help the project is to cite the SPMF project in your papers if you have been using it in your research. It should be preferably cited as follows:
Fournier-Viger, P., Gomariz, Gueniche, T., A., Soltani, A., Wu., C., Tseng, V. S. (2014). SPMF: a Java Open-Source Pattern Mining Library. Journal of Machine Learning Research (JMLR), 15: 3389-3393.
Lastly, I would like to say thank you to everyone who has supported the SPMF library over the years either by contributing code, reporting bug, using the software and citing it. This is great!
This is all for today. I just wanted to discuss the current state of SPMF and what is next. Hope that you enjoyed reading this blog post. If you want to get notified of future blog posts, you may follow my twitter account @philfv.
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 80 data mining algorithms.



