Today, I will talk about pattern mining, a subfield of data mining, that aims at discovering interesting patterns in data. In particular, I will talk about why several papers from that field do not have much impact. This is generally because of some of the following limitations:
Irrealistic problem definition: Several papers on pattern mining defines a problem that is irrealistic and has no real application or few applications. For example, I have seen many papers about proposing algorithms for mining some types of patterns, but never saw any papers that have applied these algorithms to do anything in real life.
A problem definition that is too narrow or an algorithm that is not flexible. Another issue is that many papers propose algorithms for problem definitions that are too specialized or too simple to be used in real-life. For example, there are a lot of papers that talk about analyzing customer shopping data but fail to consider many important data such as the customer profile, the categories of items, the cost and profit, and the time of purchase. Without considering such data, many pattern mining model are not useful.
Incremental contributions. Too many papers in pattern mining provide simple ideas that are just a simple combination of existing ideas. It is important to come up with original research ideas.
Focusing too much on performance. A lot of papers on pattern mining focus on performance. While performance is important and it is exciting to design fast algorithm, it is not always the most important for the user. A user may rather want to have more flexibility and to have the ability to set constraints on patterns to be found.
Poor or limited experiments. Another problem of many pattern mining papers is that poor or limited experiments are carried out to evaluate the algorithms. The experiments often focus on performance but do not show that interesting patterns are discovered or that the patterns are useful in real-life. This is important to show that the algorithms are useful for something.
Poor presentation. Another issue is a poor presentation. Even if an idea is very good, if it is poorly presented in a paper, it will have a limited impact.
Incorrect and imcomplete algorithms. Several pattern mining algorithms are claimed to be correct and complete but are not. Generally this is because no proofs are made in the papers and the authors forget some important cases when designing the algorithms. This is something to be careful about.
Approach that is not reasonable or well-justified. Another problem in several pattern mining papers is that there is not enough justifications about the design of the algorithm to convince the reader that the approach is reasonable and innovative.
That was just a short blog post! Hope it has been interesting. Leave a comment below, if you want to add something else or give your opinion.
In this blog post, I will share three videos about pattern mining describing three research papers from from my team. These videos are not very long, as they are designed to just give a brief overview about the papers. Hope it will be interesting.
In this blog post, I will write briefly about the 18th Pacific Rim International Conf on Artificial Intelligence (PRICAI 2021) conference, which was held from November 8–12, 2021, in Hanoi, Vietnam, and online.
What is PRICAI ?
PRICAI is an artificial intelligence (AI) conference that is well-established and is always held in Asia since over 30 years. PRICAI was previously held in various locations such as:
Nagoya (1990), Seoul (1992), Beijing (1994), Cairns (1996), Singapore (1998), Melbourne (2000), Tokyo (2002), Auckland (2004), Guilin (2006), Hanoi (2008), Daegu (2010), Kuching (2012), Gold Coast (2014), Phuket (2016), Nanjing (2018), Fiji (2019), and Yokohama (2020, online).
The proceedings of the conference are published as three proceedings books in the Springer Lecture Notes in Artificial Intelligence (LNAI) series, which ensures good visibility.
This year, there was 382 submissions, from which 92 regular papers were accepted (24.8% acceptance rate), and 28 short papers. Thus the combined acceptance rate for all papers is 31.41%.
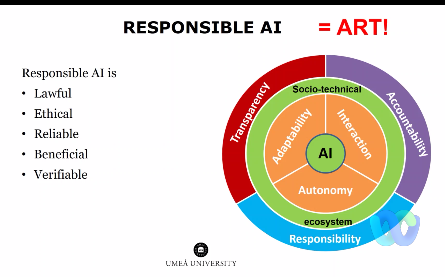
Keynote talk by Prof. Virginia Dignumabout responsable AI
There was an interesting keynote talk by Prof. Virginia Dignum about responsible artificial intelligence, what is it, and how it is relevant for today’s society.
She first said that AI is still not intelligent as smart as we would like it to be, and that three important components of AI are : adaptability, autonomy and interactions.
She then said that responsible AI is about understanding that AI systems are not alone. There are users, institutions and other systems around these AI systems, and we need to consider them.
There are several dilemnas. For example, should we just focus on optimizing the accuracy of AI systems or should we consider other criterias such as biases and energy consumption. We can view this as different objectives and we cannot optimize all of them. Thus, what should be prioritized?
There are various issues about AI that should be considered such as transparency, accountability and responsability:
The speaker also talked about other things but I will not report everything. If you are interested by this topic, she has published some papers on that subject.
Paper presentation
There was numerous paper presentations on various artificial intelligence topics. In particular, I participated to a paper that was presented to the conference, about high utility itemset mining:
Song, W., Zheng, C., Fournier-Viger, P. (2021). Mining Skyline Frequent-Utility Itemsets with Utility Filtering. Proc. 18th Pacific Rim Intern. Conf on Artificial Intelligence (PRICAI-2021), Springer LNCS, to appear.
Best papers
The best paper awards went to these two papers:
Best Paper:Ning Dong and Einoshin Suzuki, GIAD: Generative Inpainting-Based Anomaly Detection via Self-Supervised Learning for Human Monitoring
Best Student Paper: Bojian Wei, Jian Li, Yong Liu, and Weiping WangFederated Learning for Non-IID Data: From Theory to Algorithm
Conclusion
This was just a brief report about the PRICAI conference. Since my schedule is quite busy this week, I did not attend all the talks. But on overall, it was an interesting conference. It is a medium size conference that had some good talks.
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.
This blog has been created about 8 years ago (in 2013) for the purpose of talking about research, academia, and data mining.
Today, I just saw that the counter of visitors to this blog has passed 2,000,000. This is of course just a number, but still it is nice to see this. Thus, I would like to say thank you to all the readers of this blog.
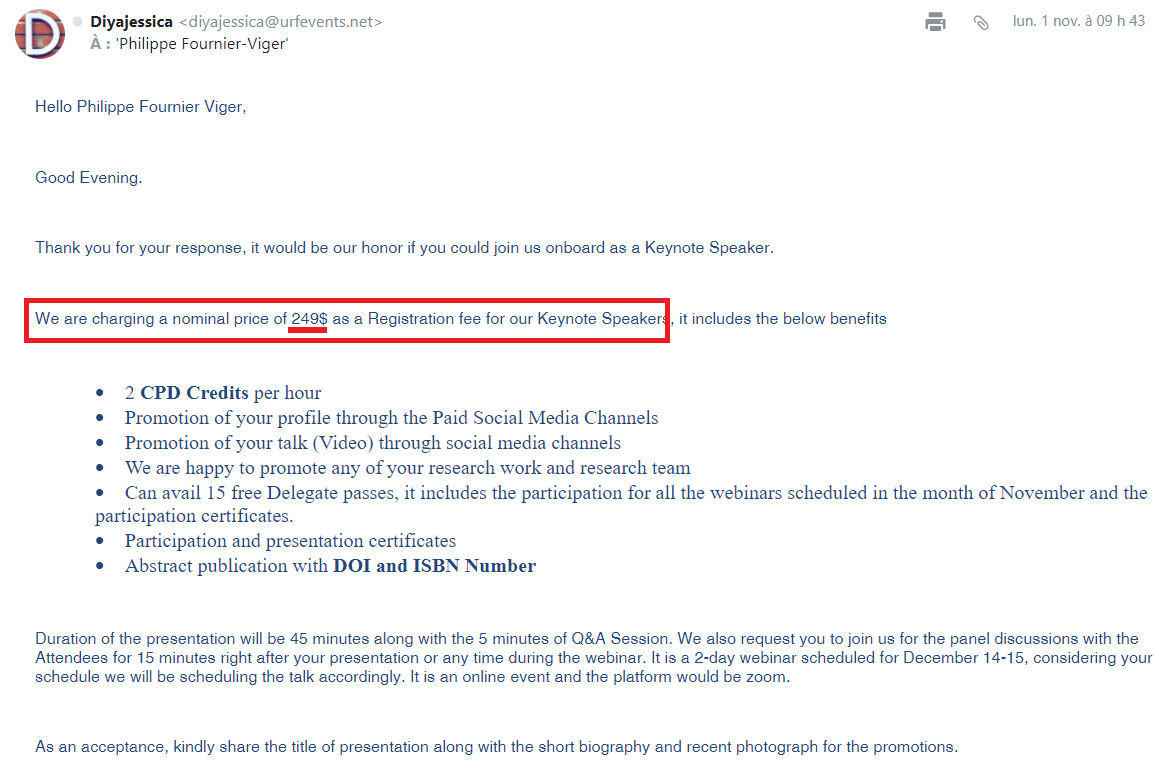
Recently, I received an e-mail from the organizer of an event in the UK called “International Conference on Artificial Intelligence and Machine Learning ” from a website called UnitedResearchForum, where the organizers asked me to participate as a keynote speaker:
From that e-mail, I thought that it was some SPAM as I have never heard about this event before. But just to make sure, I sent an e-mail to ask how much they would pay me to give the keynote speech:
Then, I got their answer, which is quite amazing. They tell me that to be a keynote speaker at their event, I would need to pay 249$ USD:
This is quite ridiculous. In general, a keynote speaker must be paid by the conference. Not the other way around. A keynote speaker is supposed to be a special guest, and generally a conference will pay hotel and airplane plus some salary to their keynote speaker.
This conference should not call their speakers “keynote speakers” if they ask them to pay by themselves for the registration fee. This seems to just be a tactic to get attention.
Thus, I clicked the button in my e-mail inbox to report the e-mail as SPAM.
Conclusion
This is just another example of academic SPAM. I do not recommend publishing there.
In recent days, I see many posts on Linkedin about researchers that mention that they are in the list of the top 2% most influential scientists of 2020 according to Stanford. Here is an example:
I understand why people post about this. The reason is that they are happy to be in the ranking and to see that their research is impactful.
I see that my name is also in that ranking, somewhere around rank #48,000. But this is not very important for me. Let’s talk instead about the data.
The data is provided as Excel files and there is also some Python code that was used to generate the ranking.
In the Excel files, it is interesting to see that each author is described by numerous metrics such as the number of citations as first author, the number of citation as corresponding author, the number of self-citations, the percentage of self-citations, etc.
Of course, all these metrics are not perfect. For example, in some fields it is easier to be cited than in some other fields and some researchers will try to manipulate these metrics for example by asking other researchers to cite their papers rather than deserving the citations. Thus, a higher rank does not necessarily mean that someone is a better researcher in real-life. But nonetheless, it is still interesting to look at this data.
By looking at the data for year 2020, I make a few observations that I find interesting.
After sorting the authors by the year of their first paper, I find that some authors have published papers for more than 180 years. For example, below, Marshall, William S. had his first paper in 1834 and his last paper in 2020. I guess that it must be some error in the data and that two persons must have the same name.
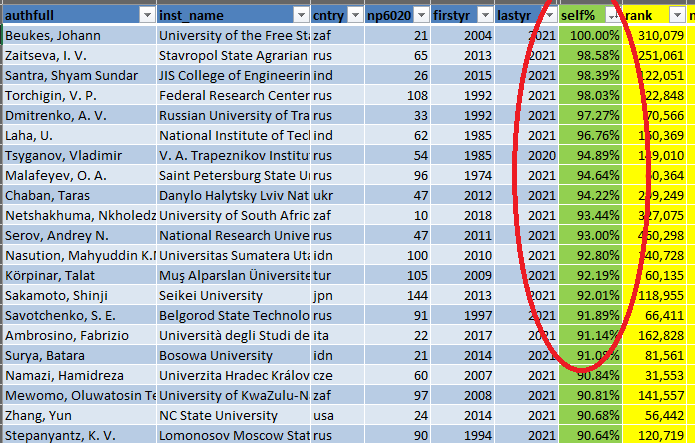
2. The attribute that I perhaps find the most interesting is “self %” which indicates the percentage of self-citations. If I sort from largest to smallest, I can see that some persons have from 90% to 100% self-citations in year 2020, which appears to be very high. Some of these persons also have a quite high “rank”. There can be some reasons for these high percentages… It perhaps that these authors work in some smaller research communities or on very specialized research topics.
If I look more closely at the data (year 2020), I find that: – about 0.6% of the researchers have more than 50% self-citations, – about 4.2% have more than 30% citations – about 13.7% have more than 20% self-citations – about 48% have more than 10% self-citations
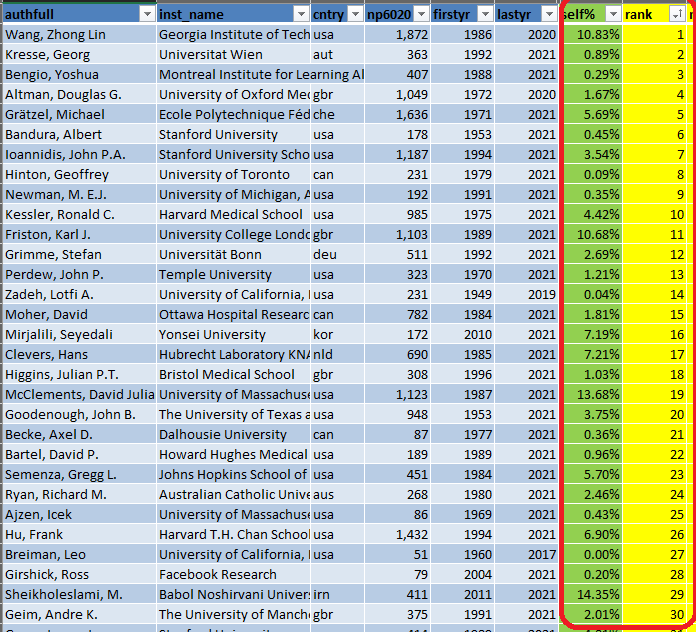
If I look at the top 30 persons in the ranking, the self-citations percentage is all below 15% and sometimes even below 1 %:
For me this makes sense. I think a young researcher will typically have more self-citations while a very famous researcher should have less self-citations and more from other people.
That is the most interesting thing that I have found so far in this data.
I did not do a very deep analysis of this data, as I am quite busy. But I just wanted to share a few observations. It would be interested to go beyond that and look for example at the data by countries or to draw some charts to see the distribution of values for different attributes, and to measure the correlation between attributes.. If you find something interesting in this data, you may share it in the comment section below!
— Philippe Fournier-Viger is a distinguished professor working in China and founder of the SPMFopen source data mining software.
Today, I attended the EITCE 2021 conference, which was held in Xiamen, China from the 22nd to 24th October 2021. The conference was held virtually and I participated as an invited keynote speaker. In this blog post, I will talk about the confernce.
About the conference
This is the 5th International Conference on Electronic Information Technology and Computer Engineering (EITCE 2021). It is a conference focused on computer science, that has been held in different cities in China such as Xiamen, Shanghai and Zhuhai.
The proceedings are published by ACM, and all papers are indexed by EI Compendex.
The conference was well organized, in part by a company called GSRA, and professors from Jimei University and Shanghai University of Engineering Science.
The website of the EITCE conference is : http://eitce.org/
Schedule of the first day
On the first day, there was five keynote speeches followed by paper presentations.
The first keynote was by Prof. Sun-Yuan Kung from Princeton University (USA) and was about deep learning, and in particular neural architecture search (NAS). He discussed techniques to search for a good neural network architecture using reinforcement learning or other techniques.
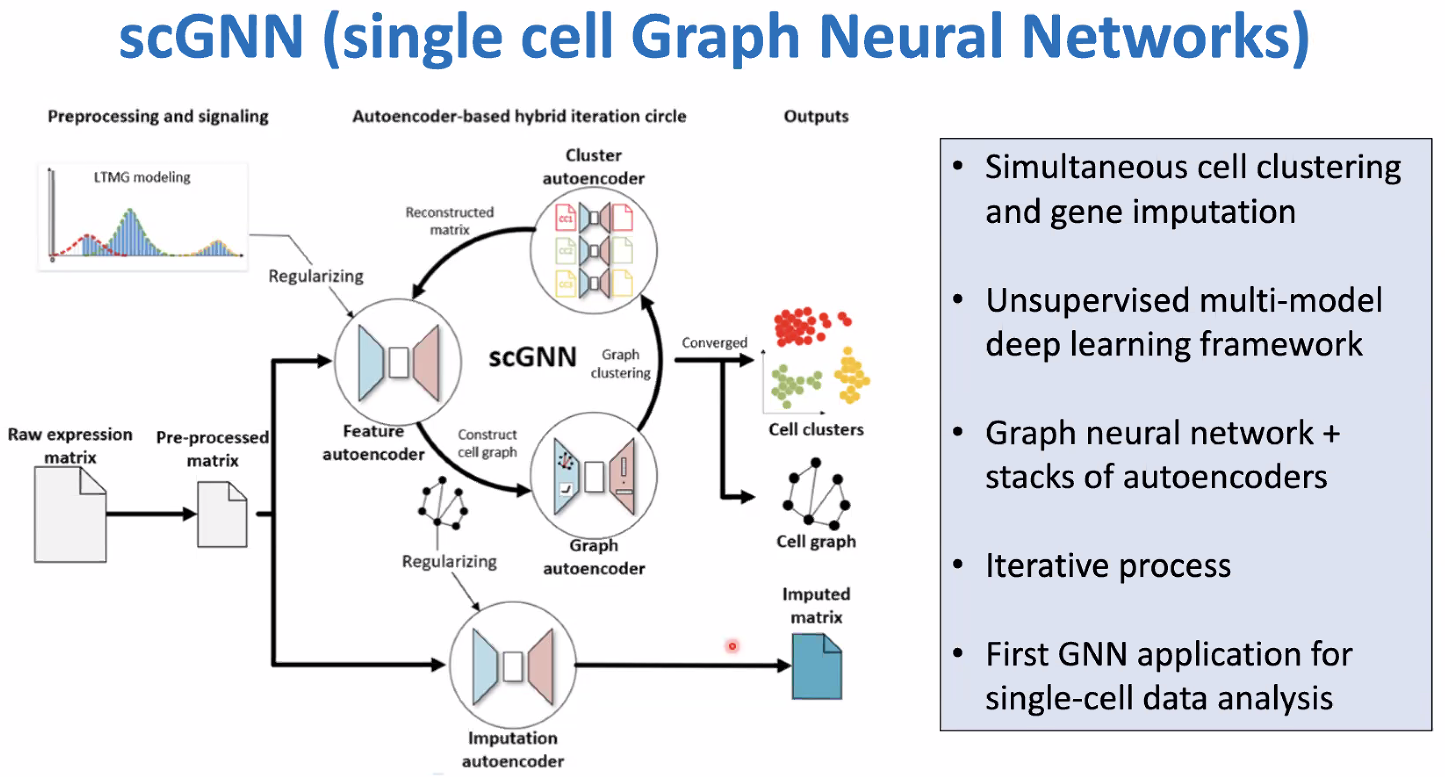
The second keynote speaker was Prof. Dong Xu, from University of Missouri. It was about using graph neural networks for single cell analysis. This talk was more about bioinformatics, which is a bit far from what I do, but was interesting as an application of machine learning.
The third keynote speaker was Prof. Yuping Wang fromTulane University, USA. The talk was about Interpretable multimodal deep learning for brain imaging and genomics data fusion. A highlight of this talk was to say that interpretability is a challenge but is also very important for research on neural networks applied to real applications.
Then, there was my keynote (Prof. Philippe Fournier-Viger) about discovering interesting patterns in data using pattern mining algorithms.
The fifth keynote was by Prof. Yulong Bai.
Conclusion
That was an interesting conference, and I was happy to participate to it.
— Philippe Fournier-Viger is a distinguished professor working in China and founder of the SPMFopen source data mining software.
PMDB 2022 aims at providing a place for researchers from the fields of machine learning, pattern mining and database to present and exchange ideas about how to adapt and develop techniques to process and analyze big complex data.
The scope of PMDB 2022 encompasses many topics that revolves around database technology, machine learning, data mining and pattern mining. These topics include but are not limited to:
Artificial intelligence, machine learning and pattern mining models for analyzing big complex data
Database engines for storing and querying big complex data
Distributed database systems
Data models and query languages
Distributed and parallel algorithms
Real-time processing of big data
Nature-inspired and metaheuristic algorithms
Multimedia data, spatial data, biomedical data, and text
Unstructured, semi-structured and heterogeneous data
Temporal data and streaming data
Graph data and multi-view data
Uncertain, fuzzy and approximate data
Visualization and evaluation of big complex data
Predictive models for big complex data
Privacy-preservation and security issues for big complex data
Explainable models for big complex data
Interactive data analysis
Open-source software and platforms
Applications in domains such as finance, healthcare, e-commerce, sport and social media
The deadline for submiting papers is the 30th November 2021.
All accepted papers of PMDB 2022 will be published in Springer LNCS together with other DASFAA workshops. This will ensure good indexing in DBLP etc.
Hope to see your papers!
— Philippe Fournier-Viger is a distinguished professor working in China and founder of the SPMFopen source data mining software.
Today, I will talk a little bit about the recent improvements and future direction for the SPMFdata mining library.
How SPMF started?
SPMF is a software project that I started around 2008 when I was a Ph.D student in Montreal, Canada. The short story of that software is as follows. I was taking a Ph.D course on data mining at University of Quebec at Montreal. For that course, I had to implement a few data mining algorithms as homework. I implemented some simple algorithms in Java such as Apriori and some code for discovering association rules. Then, I decided to clean the code, and add more algorithms during my free time, including those made for my PhD research. My idea was to make something for the pattern community in Java. In fact, most of the code that I could see online was written in C++… I wanted to change this so as to use my favorite language, Java. Besides, I wanted to share pattern mining code so that other researchers could save time by not having to implement again the same code. This is why all the code is open-source. Thus, it is around that time, in early 2009 that I created the website for SPMF and put the first version online. That version was simple. The code was not so efficient. Then, over the years the code has been optimized and more algorithms have been added, and luckily many researchers have joined this effort by providing code for many other algorithms such that today there are over 200 algorithms, many not available in other software programs. Besides, many other researchers have reported bugs and provided feedback to improve the software, which has been very useful to make the software very stable and bug-free. It is thanks to all contributors and SPMFusers that the software is what it is today! Thanks!
What is the future?
The SPMF software is still very active. Just in the first eight months of 2021, about 20 algorithms have been added already. But there is many things to do to further improve the software:
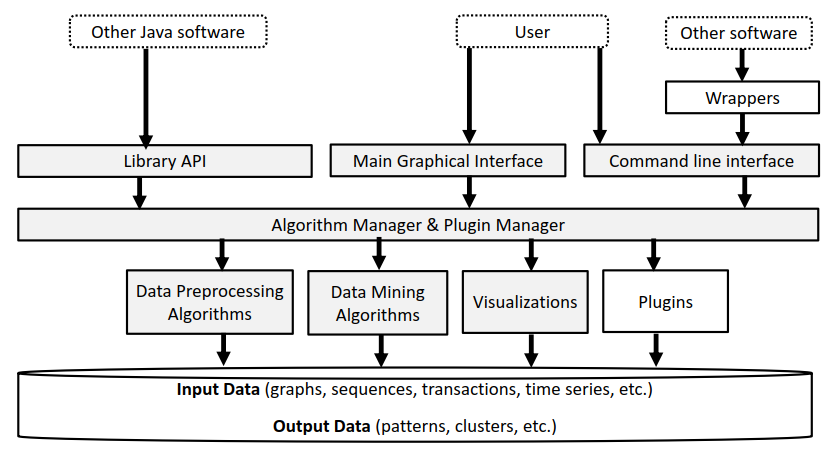
I have been working on a plugin system that is not finished but will likely appear in a future version of SPMF when it is stable enough. This will allow to download plugins as jar files from online repositories and integrate them with SPMF. I have some version that is almost working but I want to make sure it is well-tested before it is released.
I also want to integrate some additional tools to automatically run experiments in SPMF to make it more convenient for researchers who want to compare algorithms.
I will eventually redesign the user interface to further improve it with more capabilities. The user interface has always been quite simple as the focus of the software is to provide an extensive library of algorithms. But it is perhaps time to add more functionalities to the user interface such to allow the user to combine several algorithms as a pipeline to process data, and to save that pipeline to a file.
Here is a picture of the system architecture of SPMF, including the planned plugin system:
Next step: SPMF 3.0
It is already a few years that SPMF 2.0 was released. The next major version shall be SPMF 3.0 and hopefully it will be released early in 2022.
For SPMF 3.0, I will also publish a new research paper about SPMF. For the version 0.9, a paper on SPMF was published in the Journal of Machine Learning Research. For the version 2.0, I published a paper in PKDD 2016. For version 3.0, I will also make a paper for another top journal or conference. The people who have contributed the most to SPMF in recent years will be invited to co-author that paper (as much as possible due to limitations on the number of authors).
For those who have observed, the convention for numbering versions of SPMF have changed quite a lot over the years. At the beginning, I started at 0.49, and incremented the numbers by 0.01. But I did not want to reach version 1.0 too early, so I then started to add letters like 0.96b, 0.96c,… 0.96r and then even some numbers after that like 0.96r2, 0.96r3, 0.96r4 to stay away longer from 1.0. The last version before 1.0 was 0.99j. Then after that I jumped to version 2.0 for the PKDD paper, and now I continued as 2.01, 2.02… 2.50. The next jump will be to 3.0 in the next few months.
Conclusion
In this blog post, I have talked a little bit about the early development and future direction of SPMF. Hope it has been interesting!
Thanks again to all contributors and users of SPMF for supporting the software through all these years. I really appreciate your support.
— Philippe Fournier-Viger is a distinguished professor of computer science and founder of the SPMF open-source data mining library, which offers over 200 algorithms for pattern mining.
Today, I will talk about pattern mining. I will explain a topic that is in my opinion very important but has been largely overlooked by the research community working on high utility itemset mining. It is to integrate length constraints in high utility itemset mining. The goal is to find patterns that have a maximum size, defined by the user (e.g. no more than two items).
Why do this? There are two very important reasons.
First, from a practical perspective, it is often unnecessary to find the very long patterns. For example, let’s say that we analyze shopping data and find that a high utility pattern is that people buy {mapleSyrup, pancake, orange, cheese, cereal} together and that this yield a high profit. This may sound like an interesting discovery, but from a business perspective, it is not useful as this pattern contain too many items. For example, it would not be easy for a business to do marketing to promote buying 5 items together. This has been confirmed in my discussion with a business in real-life. I was told by someone working for a company that they are not interested in patterns with more than 2 or 3 items.
Second, finding the very long patterns is inefficient due to the very large search space. They are generally too many possible combinations of items. If we add a constraint on the length of patterns to be found, then we could save a huge amount of time to focus on the small patterns that are often more interesting for the user.
Based on these motivations, some algorithms like FHM+ and MinFHM have focused on finding the small patterns that have a high utility using two different approaches. In this blog post, I will give a brief introduction to the ideas from those algorithms, which could be integrated in other pattern mining problems.
First, I will give a brief introduction about high utility itemset mining for those who are not so familiar with this topic and then I will explain the solutions to find short patterns that are proposed in those algorithms.
High utility itemset mining
High utility itemset mining is a data mining task that aim at finding patterns in a database that have a high importance. The importance of a pattern is measured using a utility function. There can be many applications of high utility itemset mining, but the classical example is to find the sets of products purchased together by customers in a store that yield a high profit (utility). In that setting, the input is a transaction database, that is a set of records (transactions) indicating the items that some customers have bought at different times. For example, consider the following transaction database, which contains seven transactions called T1, T2, T3… T5:
The second transaction T2 indicates that a customer has bought 4 units of an item “b” which stands for Bread and 3 units of an item “c”, which stands for Cake, 3 units of an item “d” which stands for Dates, and 1 unit of an item “e”, which stands for “Egg”. The second transaction contains 1 unit of an item “a”, denoting “Apple”, 1 cake and 1 unit of Dates. Besides, that table, another table is provided indicating the relative importance of each item. In this example, that table indicate the unit profit of each item (how much money is earned by the sale of 1 unit):
This table for example indicates that the sale of 1 Apple yields a 5$ profit, the sale of 1 bread yields 2$ profit, and so on.
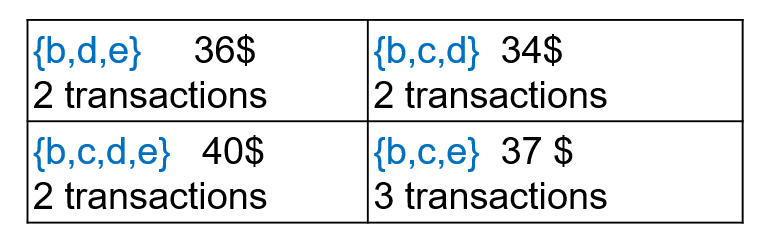
To do the task of high utility itemset mining, the user must set a threshold called the minimum utility threshold (minutil). The goal is to find all the itemsets (sets of items) that have a utility (profit) that is no less than that threshold. For example, if the user set the threshold as minutil = 33$, there are four high utility itemsets:
The first itemset {b,d,e} means that customers buying Bread, Dates and Eggs together yield a total utility (profit) of 36$ in this database. It is a high utility itemset because 36$ is no less than minutil = 33$. But how do we calculate the utility of an itemset in a database? It is not very complicated. Let me show you. Let’s say that we take the itemset {b,d,e} as example. These items are purchased together in the transactions T1 and T2 of the database, which are highlighted below:
To calculate the utility of {b,d,e}, we need to multiply the quantities associated with b,d,e in T1 and T2 by their unit profit. This is done as follow:
In T1, we have: (5 x 2) + (3 x 2) + (1 x 3) = 19 $ because the customer bought 5 breads for 2$ each, 3 dates for 2 $ each and 1 egg for 1 $.
In T2, we have (4 x 2) + (3 x 2) + (1 x 3) = 17 $ because the customer bought 5 breads for 2$ each, 3 dates for 2 $ each and 1 egg for 1 $.
Thus, the total profit of {b,d,e} for T1 and T2 is 19$ + 17 $ = 36 $.
The problem of high utility itemset mining has been widely studied in the last two decades. Besides the example of shopping above, it can be applied to many other problems as the letters like a,b,c,d,e could represent for example webpages or words in a text. There has been many efficient algorithms that have been designed for high utility itemset mining such as IHUP, UP-Growth, HUI-Miner*, FHM, EFIM, ULB-Miner and REX to name a few. If you are interested by this topic, I wrote a good survey that introduce the problemin more details and it is easy to understand for beginners in this field.
Finding the Minimal High Utility Itemsets with MinFHM
As I said in the introduction, a problem with high utility itemset mining is that many high utility itemsets are very long and thus not useful in practice. This leads to finding too many patterns and to very long runtimes.
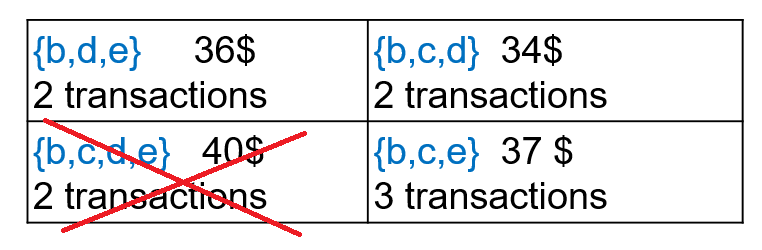
The first solution to this problem was proposed in the MinFHM algorithm. It is to find the minimal high utility itemsets. A minimal high utility itemset is simply a high utility itemset that is not a subset of a larger high utility itemset. This definition allows to focus on the smallest sets of items that yield a high utility (e.g. profit in this example). For example, if we take the same database and minutil = 33$, there are only threeminimal high utility itemsets:
The itemset {b,c,d,e} is not a minimal high utility itemsets because it has subsets such as {b,d,e} that are high utility itemsets.
To find the minimal high utility itemsets, MinFHM is a modified version of the FHM algorithm. It relies on search space reduction techniques that are specially designed to find the minimal high utility itemsets. This led to not only finding less patterns than FHM but also on having much faster runtimes. On some benchmark datasets, MinFHM was for example up to 800 times faster than FHM and could find up to 900,000 times less patterns.
For researchers, something interesting about the problem of minimal high utility itemsets is the following two properties, which are somewhat special for this problem:
I will not talk too much about the details of this as my goal is just to give some introduction. For more details about MinFHM, you can see the paper, powerpoint, video presentation and source code, below:
Fournier-Viger, P., Lin, C.W., Wu, C.-W., Tseng, V. S., Faghihi, U. (2016). Mining Minimal High-Utility Itemsets. Proc. 27th International Conference on Database and Expert Systems Applications (DEXA 2016). Springer, LNCS, pp. 88-101. [ppt][source code]
DOI: 10.1007/978-3-319-44403-1_6
Finding the High Utility Itemsets with a length constraint with FHM+
Now, let me talk about another solution to find the short high utility itemsets. This solution consists of simply adding a new parameter that sets a maximum length on the patterns to be found. For example, if take the same example and say that minutil = 33$ and the maximum length is 3, then the following three high utility itemsets are found:
In this example, the results is the same as the minimal high utility itemsets but it is not always the case.
To find the high utility itemsets with a length constraint, a naïve solution is to filter out the high utility itemsets that are too long as a post-processing step after applying a traditional high utility itemset mining algorithm such as FHM. However, that would not be efficient. For this reason, I have proposed the FHM+ algorithm in previous work. It is a modified version of FHM. The key idea is as follows. The FHM algorithm just like other high utility itemset mining algorithms uses upper bounds on the utility to reduce the search space such as the TWU and remaining utility (which I will not explain here). These upper bounds are defined by assuming that all items of a transaction could be used to create high utility itemsets. But if we have a length constraints and know that lets say we don’t want to find patterns with more than 3 items, then we can greatly reduce these upper bounds. This allows to reduce a much larger part of the search space and thus to have a much faster algorithm!
In the FHM+ paper, I have shown that using these ideas, the memory usage can be reduced by up to 50%, the speed can be increased by up to 4 times and up to 2700 times less patterns can be discovered, on benchmark datasets!
This is just a brief introduction, and these ideas could be used in other pattern mining problems. For more details, you may see the paper, powerpoint presentation and code below:
In this blog post, I have explained why it is unnecessary to find the very long patterns in high utility itemset mining for some applications such as analyzing customer behavior. I have also shown that if we focus on short patterns, we can greatly improve the runtimes and also reduce the number of patterns shown to the user. This can bring the algorithms for high utility itemset mining closer to what users really need in real-life. I have discussed two solutions to find short patterns, which are to find minimal high utility itemsets and using a length constraint.
That is all for today!
— Philippe Fournier-Viger is a distinguished professor of computer science and founder of the SPMF open-source data mining library, which offers over 200 algorithms for pattern mining.