On this blog, I have previously given an introduction to a popular data mining task called high utility itemset mining. Put simply, this task aims at finding all the sets of values (items) that have a high importance in a database, where the importance is evaluated using a numeric function. That sounds complicated? But it is not. A simple application is for example to analyze a database of customer transaction to find the sets of products that people buy together and yield a lot of money (values = purchased products, utility = profit). Finding such high utility patterns can then be used to understand the customer behavior and take business decisions. There are also many other applications.
High utility itemset mining is an interesting problem for computer science researchers because it is hard. There are often millions of ways of combining values (items) together in a database. Thus, an efficient algorithm for high utility itemset mining must search to find the solution (the set of high utility itemsets) while ideally avoid exploring all the possibilities.
To efficiently find a solution to a high utility itemset mining problem (task), several efficient algorithms have been designed such as UP-Growth, FHM, HUI-Miner, EFIM, and ULB-Miner. These algorithms are complete algorithms because they guarantee finding the solution (all high utility itemsets) However, these algorithms can still have very long execution times on some databases depending on the size of the data, the algorithm’s parameters, and the characteristics of the data.
For this reason, a research direction in recent years has been to also design some approximate algorithms forhigh utility itemset mining. These algorithms do not guarantee to find the complete solution but try to be faster. Thus, there is a trade-off between speed and completness of the results. Most approximate algorithms for high utility itemset mining are based on optimization algorithms such as those for particle-swarm optimization, genetic algorithms, the bat algorithm, and bee swarm optimization.
Recently, my team proposed a new paper in that direction to appear in 2021, where we designed two new approximate algorithms, named HUIM-HC and HUIM-SA, respectively based on Hill Climbing and Simulated Annealing. The PDF of the paper is below:
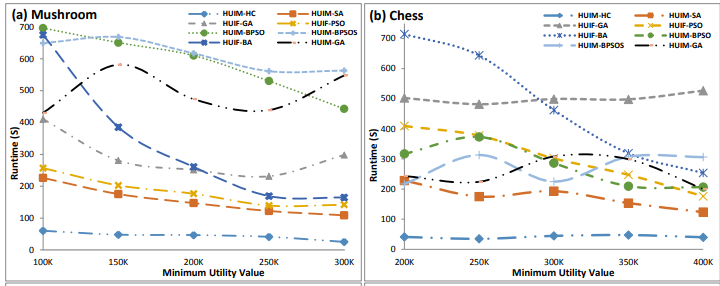
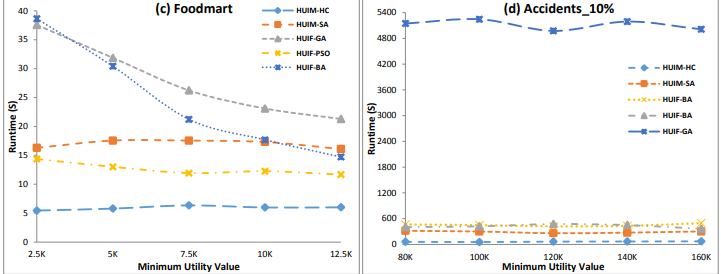
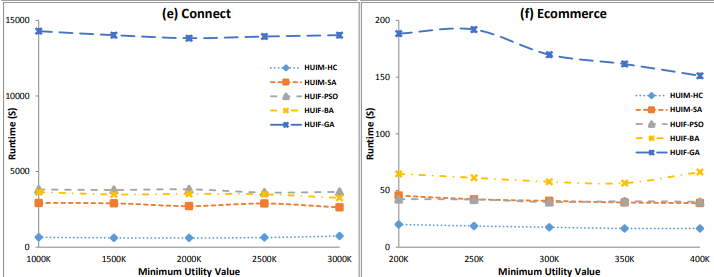
In that paper, we compare with many state-of-the art approximate algorithms for this problem (HUIF-GA, HUIM-BPSO, HUIM-BA, HUIF-PSO- HUIM-BPSOS and HUIM-GA) and observed that HUIM-HC all algorithms on the tested datasets. For example, see some pictures from some runtime experiments below on 6 datasets:
In this picture, it can be observed that HUIM-SA and HUIM-HC have excellent performance. In a) b) c) d), e), f) HUIM-HC is the fastest, while HUIM-SA is second best on most datasets (except Foodmart).
In another experiment in the paper it is shown that although HUIM-SA is usually much faster than previous algorithms, it can find about the same number of high utility itemsets, while HUIM-HC usually find a bit less.
If you are interested by this research area, there are several possibilities for that. A good starting point to save time is to read the above paper and also you can find the source code of all the above algorithms and datasets in the SPMF data mining library. By using that source code, you do not need to implement these algorithms again and can compare with them. By the way, the source code of HUIM-HC and HUIM-SA will be included in SPMF next week (as I still need to finish the integration).
Hope that this blog post has been interesting! I did not write so much on the blog recently because I have been very busy and some unexpected events occurred. But now I have more free time and I will start again to write more on the blog. If you have any comments or questions, please write a comment below.
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.
Hi all, This is to let you know that the UDML workshop on utility driven mining and learning is back again this year atICDM2021, for the fourth edition.
The topic of this workshop is the concept of utility in data mining and machine learning. This includes various topics such as:
Utility pattern mining
Game-theoretic multiagent system
Utility-based decision-making, planning and negotiation
Models for utility optimizations and maximization
All accepted papers will be included in the IEEE ICDM 2021 Workshop proceedings, which are EI indexed. The deadline for submiting papers is the 3rd September 2021.
I am glad to announce that I am co-organizing a new workshop called MLiSE 2021(1st international workshop on Machine Learning in Software Engineering), held in conjunction with the ECML PKDD 2021 conference.
Briefly, the aim of this workshop is to bring together the data mining and machine learning (ML) community with the software engineering (SE) community. On one hand, there is an increasing demand and interest in Software Engineering (SE) to improve quality, reliability, cost-effectiveness and the ability to solve complex problems, which has led researchers to explore the potential and applicability of ML in SE. For example, some emerging applications of ML for SE are source code generation from requirements, automatically proving the correctness of software specifications, providing intelligent assistance to developers, and automating the software development process with planning and resource management. On the other hand, SE techniques and methodologies can be used to improve the ML process (SE for ML).
The deadline for submiting papers is the 23rd June 2021, and the format is 15 pages according to the Springer LNCS format.
All papers are welcome that are related to data mining, machine learning and software engineering. These papers can be more theoretical or applied, and from academia or the industry. If you are interested to submit but are not sure if the paper is relevant, feel free to send me an e-mail.
The papers will be published on the MLiSE 2021 website. Moreover, a Springer book and special journal issue are being planned (to be confirmed).
Hope that this is interesting and that I will see your paper submissions in MLiSE 2021 soon:-)
In this blog post, I will share the video of our most recent data mining paper presented last week at ACIIDS 2021. It is about a new algorithm named POERM for about analyzing sequences of events or symbols. The algorithm will find rules called “episode rules” indicating strong relationships between events or symbols. This can be used to understand the data or do prediction. Some applications are for example, to analyse sequence of events in a computer network or analyze the purchase behavior of customers in a store. This paper received the best paper award at ACIIDS 2021!
In this blog post, I will give a brief report about the ACIIDS 2021 conference, that I am attending from April 7–10, 2021.
What is ACIIDS?
ACIIDS is an international conference focusing on intelligent information and database systems. The conference is always held in Asia. In the past, it was organized in different countries such as Thailand, Vietnam, Malaysia, Indonesia and Japan. This year, the conference was supposed to be in Phuket, Thailand. However, due to the coronavirus pandemic, it was held online using the Zoom platform. It is the first time that I attend this conference. This year, the timing was good so I have decided to submit two papers, which were accepted.
Here is the list of countries where ACIIDS was held in previous years:
Conference programof ACIIDS 2021
The conference has received 291 papers, from which 69 papers were selected for oral presentation and published in the proceedings, and about 33 more papers were published in a second volume. This means an acceptance rate of 23 %for the main proceedings, which is a somewhat competitive. The papers cover various topics such as data mining techniques and applications, cybersecurity, natural language processing, decision support systems, and computer vision. The conference ACIIDS is now in the CORE B ranking.
The main proceedings of ACIIDS 2021 is published by Springer in the Lecture Notes in Artificial Intelligence series, which ensures good visibility and indexing. The second proceedings books was published in another series of books from Springer.
There was four keynote speakers, that gave some interesting talks:
Opening ceremony
The conference started in the afternoon in Asia with the opening ceremony.
First day paper presentations
During the first day, I listened to several presentations. My team presented two papers:
During that session, there was not so many people (likely due to the different time zones) but I had some good discussions with other participants. In the first paper (video here), we presented a new algorithm for discovering episode rules in a long sequence of events. In the second paper, we investigated the importance of crossover operators in genetic algorithms for a data mining task calledhigh utility itemset mining.
ACIIDS, a well organized virtual conference
The organization of the ACIIDS conference was very well-done. Over the last year, I have attended several virtual conferences such as ICDM, PKDD, PAKDDand AIOPS, to just name a few . In general, I think that virtual conferences are not as enjoyable as “real” conferences (see my post: real vs virtual conferences), because it is harder to have discussions with other attendees and many attendees will not attend much of the conference.
Having said that, I think that ACIIDS organizers did a good job to try to make it an interesting virtual event to to increase the participation of attendees in the activities. What did they do? First, before the conference, they sent an e-mail to all attendees to collect pictures of us giving our greetings to the ACIIDS conference to then make a video out of it. Second, the organizers also created a contest where we could submit a picture of an intriguing point-of-interest in our city, and there was a vote about the best one during the conference. Third, there was several interesting activities such as a live Ukelele show. Fourth, the organizers gave several awards to paper including some more or less serious, including a award called the “most intelligent paper”. Fifth, to increase participation, an e-mail was sent everyday to attendees to remind them about the schedule.
Here are a few pictures from some of the virtual social activities:
The Ukulele show at ACIIDS 2021
Greetings from all around the world at ACIIDS 2021
Here are some pictures of some of the “Top 3” awards given to authors (some are serious and some not serious and just based on a statistical analysis):
The paper from my student, received the “most internationalized paper award” as we have authors from three continents:
Last day: more paper presentations, awards and closing ceremony
On the last day of the conference, there was more paper presentations, which were followed by the best paper award ceremony and the closing ceremony. It was announced that my student paper received the best paper award:
Next year: ACIIDS 2022
It was announced that ACIIDS 2022 would be organized next year in Almaty, Kazakhstan around June. Almaty is the biggest city in Kazakhstan, so that should be interesting.
Registration fees
The registration fee for this year at ACIIDS were lower than usual, perhaps due to the conference being online. This makes the conference more attractive and affordable this year. Here is a comparison with previous years:
That is all for this blog post about ACIIDS 2021. Overall, it was an enjoyable conference. I did not attend all the sessions as I was quite busy this week, but what I saw was good. Thus, looking forwards to ACIIDS 2022.
In this blog post, I will talk about a great resource that can help to improve your academic writing. It is a website, called the Academic Phrasebankcreated by Dr. John Morley from the University of Manchester. This website, also published as a book, contains lists of sentences that are commonly used in research papers, each categorized according to its functions and the section of the paper where it appears. This bank of common sentences is very useful for authors who don’t know how to express their ideas, or would like to get some inspiration or find different ways of writing their ideas.
Below, is a screen shot of the main menu of the website:
There are six categories corresponding to the different sections of a typical research paper. Consider the first category, which is called “Introducing Work“. Lets say that we click on it to find out about common sentences to be used in the introduction of a paper. Then, some sub-categories are shown such as:
Establishing the importance of the topic for the world or society
Establishing the importance of the topic for the discipline
Establishing the importance of the topic as a problem to be addressed
Explaining the inadequacies of previous studies
Explaining the significance of the current study
Describing the research design and the methods used
…
Then, lets say that we choose the first sub-category. This will show us a list of common sentences for establishing the importance of a research topic. Here are a few of those sentences:
X is fundamental to …
X has a pivotal role in …
X is frequently prescribed for …
X is fast becoming a key instrument in …
X plays a vital role in the metabolism of …
X plays a critical role in the maintenance of …
Xs have emerged as powerful platforms for …
X is essential for a wide range of technologies.
X can play an important role in addressing the issue of …
Xs are the most potent anti-inflammatory agents known.
There is evidence that X plays a crucial role in regulating …
… and many others…
I will not show more examples but you can try the website to have a look at other categories
My opinion: I think that this website is quite rich and useful. I write many research papers and tend to always use more or less the same sentence structures. But by looking at this phrase bank, it gives me some ideas about how I could try using other types of sentences as well. I think that this can help improve my writing style a bit in future papers!
That is all for today. I just wanted to share this useful resource for academic writing!
Recently, there has been some debate on the Machine Learning sub-Reddit about the reproducibility or I should say the lack of reproducibility of numerous machine learning papers. Several Reddit users complained that they spent much time (sometimes weeks) to try to replicate the results of some recent research papers but simply failed to obtain the same results.
To address this issue, some Reddit user launched a website called Papers Without code to list all papers that are found to have results that cannot be reproduced. The goal of this website is apparently to save time by indicating which papers cannot be reproduced and perhaps even to put pressure on the authors to make reproducible papers in the future. On the website, someone can submit a report about a paper that is not reproducible by indicating several information such as how much time was spent on trying, what is the title of the paper and its authors. Then, the owner of the website first send an e-mail to the first author of the paper to give a chance to provide an explanation before the paper is added to the list of non-reproducible papers.
The list of papers without code can be found here. At the time of writing this blog post, there are only four papers on the list. For some of thes papers on that list, some people mentioned that they even tried to contact the authors of papers but got some dodgy responses and that some promised to add the code to GitHub with a “coming soon” notice, before eventually deleting the repository.
Personally, I am not sure that creating such website is a good idea because some papers may be added to this list and it may be undeserved in some cases, and have an impact on the reputation of some researchers. But at the same time, there are many papers that simply cannot be reproduced and many people may waste time trying to reproduce them. The website owner of PapersWithoutCode has indicated on Reddit that s/he will at least take some steps to prevent problems from happening such as to verify the information about the sender, and to inform the first author of a paper and giving him at least one week to answer before adding it to the list.
On Reddit a comment was that it is “Easier to compile a list of reproducable” papers. In fact, there is a website called Paper with Code that does that for machine learning, although it is not exhaustive. And some people claimed on Reddit that at least 50% to 90% of papers are not reproducible based on their experience. I don’t know if it is true, but there are certainly many. An undergraduate student on Reddit also said that he does not understand why providing code is not a requirement when submiting a paper. This is a good point, as it is not complicated to create an online repository and upload code…
Why I talk about this? While, I am not convince that this website is a good idea, I think that it raises an important debate about reproducibility of research. In some other fields such as cancer research, it was pointed out that several studies are difficult to reproduce. However, in computer science, this should not be so much of a problem as code can be easily shared. Unless there is some confidential or commerical restrictions on research projects, it should be possible for many researchers to publish their code and data at the time of submiting their papers. Thus, a solution could be to make this requirements more strict for conferences and journals at the time of submission.
Personally, I release the source code and data of almost all the papers where I am the corresponding author. I put the code and data in my open-source SPMF software, unless it is related to a commercial project and that I cannot share the code. This has many advantages: (1) other people can use my algorithms and compare with them without having to spend time to re-implement the same algorithms again, (2) people can use my algorithms for some real applications and it is useful to them, (3) this increase the number of citations of my papers and (4) it convince reviewers that results in my papers can be reproduced.
Another reason why I share the code of my research is that as a professor, much of my research is funded by the government through the university or grants. Thus, I feel that it is my duty to share what I do as open-source code (when possible).
What do you think? I would like to read your opinion in the comment section below.
In this blog post, I will give an overview of some of the main pattern mining tasks, to explain what kind of patterns can be found in different types of symbolic data. I will describe some main types of data and list some main types of patterns that can be found in the data using pattern mining algorithms. This list is not exhaustive but covers some of the main problems studied by researchers in pattern mining and some variations.
To find patterns in your data, there are many data mining algorithms that can be used. To apply the algorithms described below, you may find fast, efficient and open-source implementations of pattern mining algorithms in the SPMF software/library (which I am the founder), which offers over 200 algorithms.
1.Finding Patterns in Binary Records
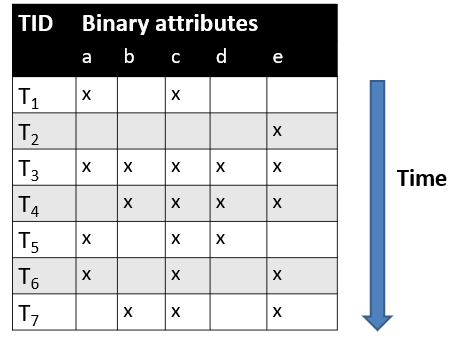
Data description: This first common type of data is a table containing a set of records described using a set of binary attributes. For example, a binary table is shown below. This table contains four records called T1, T2, T3 and T4, which are described using four five attributes (a,b,c,d,e)
A binary table (also called transaction database)
This type of data is very common in many fields. For example, it can be used to represent:
what some customers have purchased in a store (record = customer, attributes = purchased items)
the words appearing in text documents (record = text document, attributes = appearance of a word)
the characteristics of animals (record = animal, attributes = characteristics such as has fur?)
What kind of patterns can be found in this data?
The main type of patterns that can be discovered in a binary table are:
frequent itemsets: a frequent itemset is a set of values that appear in many records. For example, by using some algorithms such as FPGrowth, we can find that the itemset {a,b} appears three times in the above table, as well as other itemsets such as {d,e}, {e}, {a}, {d} and others. In a real application, someone could for example find that many people buy bread and milk together in a store.
association rules: an association rule indicate some strong relationship between some attributes. It is has the form of a rule X –> Y indicating that if some attribute values X are found in a record, they are likely associated with some other values Y. For example, in the above database, it can be found that {a,b}–> {e} is a strong association rules because (1) it is frequent (appears many times in the database), and also it has a high confidence (or conditional probability), that is everytime that {a,b} appears, {e} also appears.
rare itemsets: Those are sets of values that do not appear many times in the data but are still strongly correlated.
2. Finding Patterns in a Sequence of Binary Records
Data description: This is a sequence of records, where each record is described using binary attributes. Records are ordered by time or other factors. For example, a binary table where records are ordered is shown below. This table contains four records called T1, T2, T3 and T4, which are described using four five attributes (a,b,c,d,e)
A binary table with records ordered by time
This type of data is common in various fields. For example, it can be used for
representing what a customer has purchased in a store over time (record = each transaction made by a customer, attributes = purchased items, ordered by purchase time)
the words appearing sentences of a text document (record = word in a sentence, attributes = appearance of a word, ordered by sentences)
a sequence of locations visited by a person in a city (record = the position at a given time, attribute = the point of interest or location)
a DNA sequence (record = a nucletoride, attribute: the nucleotide type such as ACGT, ordered by appearance) such as COVID-19 sequences
The main type of patterns that can be discovered in a sequence of binary records are:
frequent episodes: an episode is of values that often appear close to each other. For example, an episode can be <{e}{c}> indicating that e is often followed by c, shortly after. To discover frequent episodes some algorithms are MINEPI, WINEPI, EMMA and TKE. (see a survey of episode mining for more details)
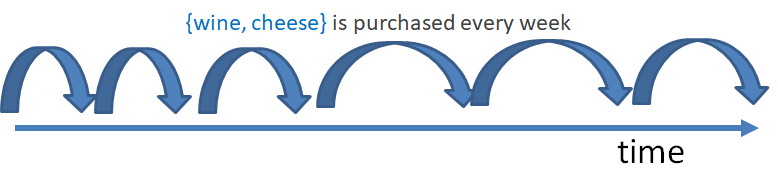
periodic itemsets: a periodic itemset is a set of values that is always re-appearing over time in a sequence of records. For example, in the above example, the itemset {a,c} always re-appear every one or two transactions, and hence can be called “periodic”. This type of patterns can be found by algorithm such as PFPM an others. An example application of finding periodic patterns is to study the behavior of customers in a store. It could be find that someone regularly purchase wine and cheese together.
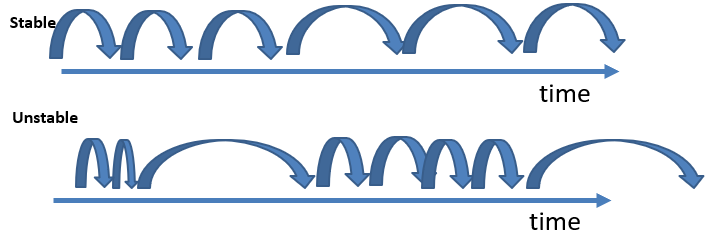
stable patterns: a stable patterns is a periodic patterns that has a stable periodic behavior over time. This means that the time between each occurrence of the pattern is more or less stable. The SPP-Growth algorithm can be used for this task. Here is an intuitive illustration of the concept of stability:
recently frequent patterns: The goal is to find patterns that have appeared many times recently rather than in the past. Algorithms such as EstDec can be used for this.
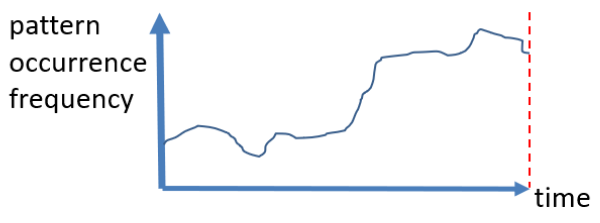
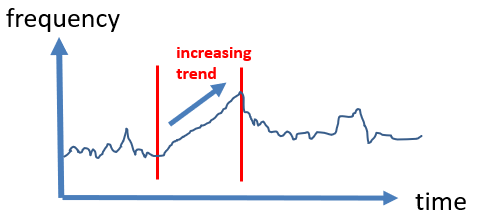
trends: Some algorithms are also designed to find increasing or decreasing trends. For example, some set of values may have may have an occurrence frequency that is slowly increasing during some time period. Such patterns can be found using some algorithms such as LTHUI-Miner.
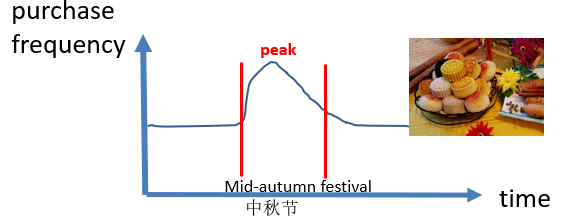
peaks: another interesting type of patterns that can be found in a sequence of records is peaks. A peak means that some set of values appears much more often than usual during some time interval. Some algorithm to find peak in a sequence of records is PHUI-Miner. For example, the picture below show that some type of food called “moon cakes” have a sale peak during some specific time period of the year in China, which is the mid-autumn festival.
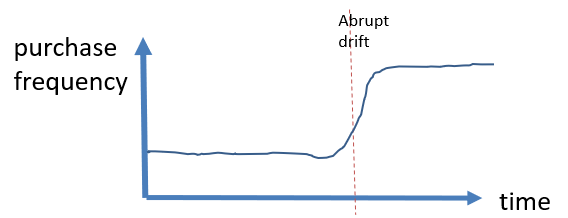
concept drifts: A concept drift is an abrupt of slow changes that happens over time. For example, it could be found in customer data, that the sales of some products as suddenly increased a lot due to the products being advertised on TV. This is illustrated with a picture:
3.Finding Patterns in a Sequence Database
Data description: Another type of data that is very common is a database of sequences of records. This is the same as the above data type except that instead of having a single sequences, we have a database containing multiple sequences. Below is an example, sequence database containing four sequences called s1, s2, s3 and s4. The first sequence indicates that some value a is followed by a value b, which is followed by c, and then by a, then b, then e, and finally f.
A sequence database
This type of data is common in various fields. For example, it can be used for
representing what a set of customers have each purchased in a store over time (sequence = the sequence of transaction made by a customer, values = purchased items)
the words appearing in sentences of a text document (sequence = a sentence where values represent words, each sentence is a sequence).
the sequence of locations visited by tourists in a city (sequence = the list of tourist spots visited by a tourist, each sequence represents a tourist)
and more..
The main type of patterns that can be discovered in a sequence of binary records are:
sequential patterns: a sequential pattern is a subsequence that appears in many sequences of the input database. In the above example, a sequential pattern is <{a},{b},{a}> because this patterns appear in the four sequences. Some algorithms for this tasks are GSP, CM-SPAM and CM-SPADE. It is also possible to add various constraints such as whether gaps are allowed or not between values in a sequential patterns. Some example of application is to find frequent sequence of locations visited by tourists and frequent sequence of purchases made by customers:
sequential rules: A sequential rule indicate some strong relationship between some values in several sequences. It is has the form of a rule X –> Y indicating that if some attribute values X appears, they are likely to be followed by some other values Y. For example, in the above database, it can be found that {a,b}–> {f} is a strong sequential rules because (1) it is frequent (appears many times in the database), and also it has a high confidence (or conditional probability), that is {a,b} is always followed by {f} . There are many algorithms for discovering sequential rules such as RuleGrowth, CMRules, and RuleGen. Some offer additional features or constraints such as to handle data with timestamps.
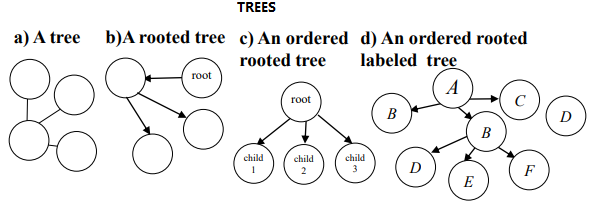
4.Finding Patterns in a Graph, Trees and Dynamic Graphs
Data description: Another type of data that is quite popular aregraphs. They can be used to represent various data types such as social networks and chemical molecules. There are various types of graphs and some algorithms to analyze them. Some main graph types are shown below (taken from this survey):
Some main type of patterns that can be discovered in one or more graphs are:
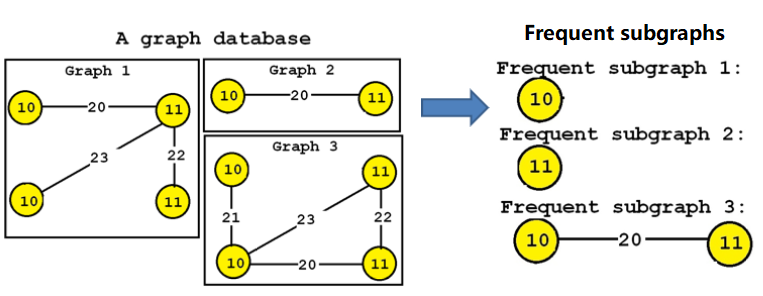
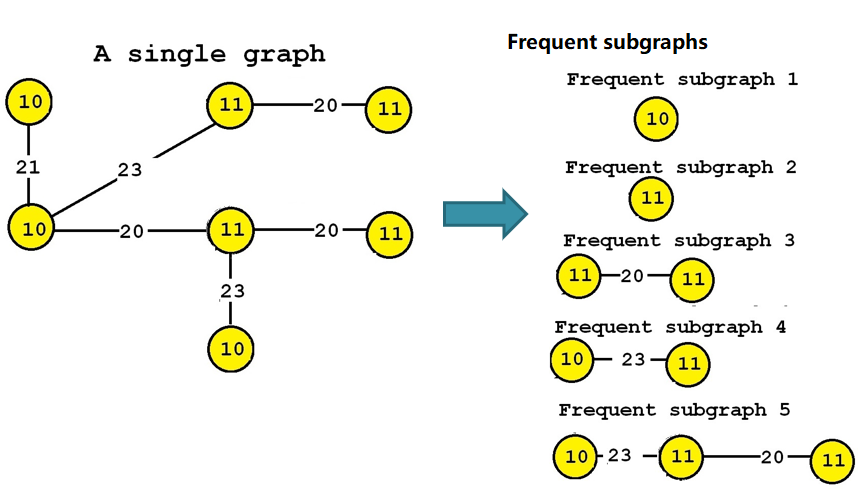
frequent subgraphs: those are subgraphs that appear many times in a large graph, or subgraphs that appear in many graphs. Some algorithms for this task are Gaston, GSPAN and TKG. Some illustrations are given below:
Illustration of finding frequent subgraphs in a graph database (all the subgraphs on the right appear in at least three graphs on the left)An illustration of finding frequent subgraphs in a single large graph (all the subgraphs on the right appears at least twice in the graph on the left)
frequent subtrees: the goal is to find trees that appear in many trees or many times in a large tree.
dynamic patterns: various types of patterns can be found in a graph that is evolving over time such as trend sequences, attribute evolution rules, etc. Those patterns can reveal how a graph is evolving. Some recent algorithms are AER-Miner and TSeqMiner.
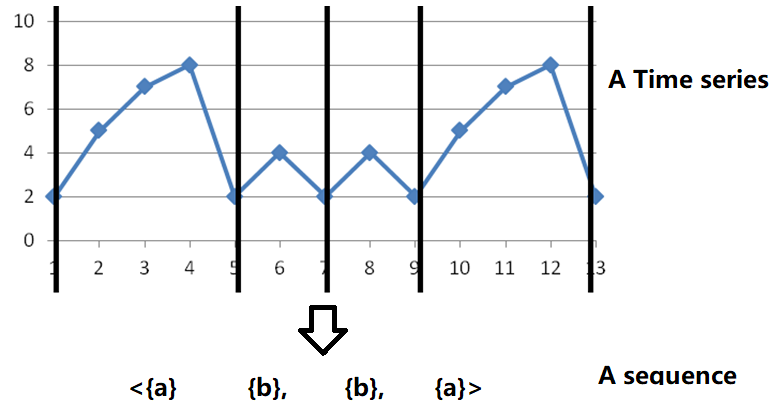
5.Finding Patterns in TimeSeries
Data description: Another type of data is time series. A time series is a sequence of numbers. It can be used to represent data such as daily weather observations about the temperature or wind speed, or the daily price of stocks. Here is some example of time series, where the X axis is time and the Y exist represents the temperature (celcius):
To analyse a time series, some methods like shapelet mining are specifically designed to analyze time series. They can find shapes that appear frequently in a time series. Another solution is simply to transform a time series into a sequenceof symbols using an algorithm such as SAX, and then to apply an algorithm to find patterns in a sequence of records as previously described.
6. Some other variations
There are also several other data types that are variations of the ones that I have described above. A popular type of data in recent year is a table of record where attributes can have numeric values. For example, the database below show a transaction database with quantities:
This database can for example indicate what a customer has made five transactions (T1 to T5) in a retail store. For instance, the first transaction may indicate that the customer has purchased 1 unit of item a (apple) with 5 units of item b (bread), 1 unit of item c (cake), 3 units of item d, 1 unit of item e, and 5 units of item f. It is also possible to have another table to indicate the profit yield by the sale of each item such as below:
This table indicates that item a yields a 5$ profit, item b yield a 2$ profit and so on. By analyzing such database, it is possible for example to find a type all the sets of items purchased together that yield a lot of money. This problem is called high utility itemset miningand is actually quite general. It can be applied to other types of data as well, and can be generalized to sequences. Many researchers have been working on this topic in recent years.
Conclusion
In this blog post, I have given some overview of some main pattern mining problems for analyzing mainly symbolic data such as database of records, sequences of records, graphs and sequence databases.
If you are interested by this, you can consider using the SPMF open-source library that I have founded, which offers implementations of over 200 pattern mining algorithms: SPMF software/library. On the website, you can also find datasets to play with those types of algorithms.
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.
Today, I will discuss how to write a good research grant proposal. This topic is important for researchers, who are at the beginning of their careers and want to obtain funding for their research projects. A good research proposal can be career-changing as it may allow to secure considerable funding that may for example, help to obtain a promotion. On the other hand, a poorly prepared research proposal is likely to fail. To avoid writing a very long post on this topic, I will focus on the key points for writing a good project proposal.
Preparation
Before writing a research grant proposal, the first step is preparation. Preparation should ideally start several weeks or months before the deadline. The reason is that writing a proposal takes time and that unexpected events may occur, which may delay the progress. Moreover, starting earlier allows to ask feedback from peers and to think more about the content and how to improve the proposal.
Another important aspect of preparation is to choose an appropriate funding program for the proposed research project.
The research question
A key aspect of preparing a research grant proposal is to choose a research question that will be addressed by the research project.
The key points to pay attention related to the research question are that: (1) the research question is new and relevant, (2) the research project is feasible within the time frame, using the proposed methodology and given the researcher(s)’s background and skills, and (3) the research project is expected to have an important impact (be useful). In the project proposal, the above elements (1), (2), and (3) need to be clearly explained to convince the reviewers that this project deserved to be funded.
Choosing a good research question takes time, but it is very important.
Literature review
Another important part of a project proposal is the literature review, which should provide an overview of relevant and recent studies on the same topic. It is important that the literature review is critical (highlight the limitations of previous studies) with respect to the research question. Moreover, the literature review can be used to highlight the importance of the research question, and its potential impact and applications.
References should be up-to-date (preferably from the last five years). But older references can be included, especially if they are the most relevant.
Methodology
A good proposal should also clearly explain the methodology that will be used, and the theoretical basis for using that methodology.
About carrying out experiments, one should explain how participants will be recruited and/or data will be obtained, how big the sample size will be(to ensure that results are significant), how results will be interpreted, and how do deal with issues related to ethics.
If a methodology is well-explained and detailed, it indicates that the researcher has a clear plan about how he will conduct the research. This is important to show that the project is feasible.
Timeline of the project
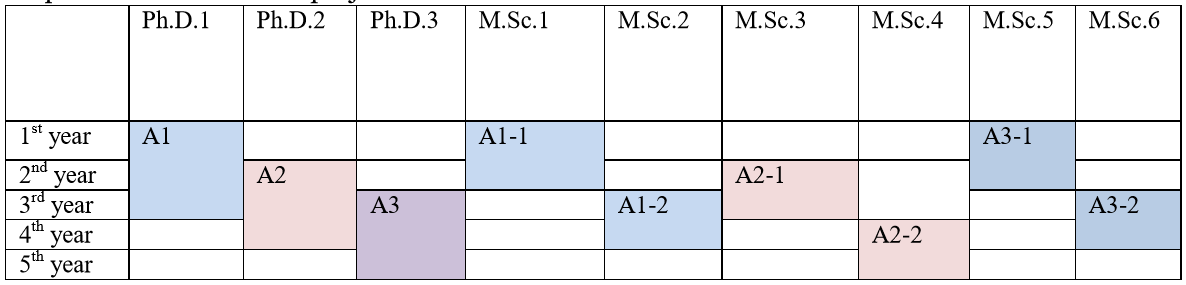
To further convince reviewers that the project will succeed, it is important to also provide a clear timeline for the project. That timeline should indicate when each main task will be done, by who, and what will be the result or deliverables for each task. For example, one could say that during the first 6 months, a PhD student will do a literature review and write a journal paper, while another student will collect data, and so on.
The timeline can be represented visually. For example, I show below a timeline that I have used to apply for some national research funding. That project was a five year projects with three main tasks. I have divided the task clearly among several students.
Note that it is good to mention the names of the students or staff involved in the project, if the names are known. It can also be good to explain how the students will be recruited.
Equipment
It is also useful to mention the equipment or facilities that are available at the institution where the researcher works, and that will help to carry the project.
Impact
Another very important aspect is to write clearly what will be the expected impact of the research project. The impact can be described in terms of advances in terms of knowledge, but also in terms of benefits to the society or economy. In other words, the proposal should explain why the project will be useful.
Budget
A project proposal needs to also include a budget that must follow the guidelines of the targeted funding source. It is important that the amounts of money are reasonable and justifications are provided to explain why the money is required.
Team, institution, and Individual
A proposal should also explain that the applicant and its team have the suitable background and skills required for successfully conducting the project. This is done by describing the background and skills of researchers, and how they fit the project.
Conclusion
In this blog post, I have discussed the key points that a good research proposal should include. I could say more about this topic, but I wanted to not make it too long for a blog post.
This is a website that let you automatically generate reviews to reject papers. The reviewer need to check some boxes about what is the content of the paper, and then a review is generated. Note that it is not meant to be used by reviewers in real-life. It was created as an April fool’s joke. But it is interesting to try and see what kind of review is generated. For example, I generated a review:
Dear Author,
Thank you very much for your submission. We have enclosed detailed reviews of your paper below.
Reviewer 2
Generally speaking, this is interesting work which may well find some readers in the community. However, in its present form, the paper suffers from a number of issues, which are outlined below.
Area
Computer Science is not new. The past decade has seen a flurry of papers in the area, which would indicate progress and interest. However, the impact outside of Computer Science has been very limited, as is easily reflected in the ever-decreasing number of citations. Unfortunately, Computer Science finds itself in a sandwich position between a more theoretical community and a more practical community, which can both claim a bigger intellectual challenge and a greater relevance in practical settings. This is especially true for the field of Data mining, where the last big progress is now decades ago. As refreshing it feels to finally again see progress claimed in the field, the present paper must be read and evaluated in this context.
Approach
The paper suffers from an excess of formalism. Several important definitions are introduced formally only, without a chance to clearly understand their motivation or usage. The authors should be encouraged to make more use of informal definitions, building on the well-established formal definitions in the community.
For readers, it is helpful to see the approach being demonstrated in a limited setting that facilitates control and comprehension. However, real-world settings are much more detailed, and much more challenging. If the approach is ever to succeed in practice, having a demonstrator that copes with real-world conditions is a must; the authors would be encouraged to work with industry to get access to appropriate settings and data sets.
Evaluation
This reviewer read until Page 2, and the evaluation seems to be okay.
The fact that your evaluation involves students is also a cause for concerns - not only for ethical reasons, but also for the sake of generality. Generally speaking, results achieved with students cannot generalize to results achieved with the general public - especially not in Computer Science. You have to run your evaluation and experiments involving a wider range of subjects.
Limitations
The section on 'future work' fits into this very picture: There clearly is still a lot of additional work to do until this approach can begin to sho (...)
The code of that website is open-source but the approach is really simple if you look under the hood. A review is generated using some simple IF conditions.
If you have submitted several papers to journals and conferences, you will know that sometimes, we are not lucky and some reviewers can give some very bad comments rather than adopting a constructive approach. This website lists several bad comments given by reviewers. Here are a few examples:
“Indeed, by the end of the paper, the reader is left with a feeling of ‘so what now?’”
” The fact that the question of this paper has never been asked should, on balance, count against the paper.”
“Is this really a discovery or just the confirmation of math?”
“I don’t see how your approach has potential to shed light on a question that anyone might have.”
“The paper could be considered for acceptance given a rewrite of the paper and change in the title and abstract. “
” This discussion might be better directed to a different audience, perhaps an undergraduate class “
“I am personally offended that the authors believed that this study had a reasonable chance of being accepted to a serious scientific journal.”
If you don’t know this website already, it offers some good cartoons about graduate student life. There are hundreds of comic strips, and some are really funny and to the point. When, I was a graduate student, I keep reading this every week. Although the author seems to have stopped uploading new comic strips, there is a big archive of old comics. There are also two movies that were made based on these comics called the PHD Movie 1 and PHD Movie 2. The 200 most popular comic strips from this website: http://phdcomics.com/comics/most_popular.php
An example of comic from PhDComics – Copyright (c) Jorge Cham
This website offers a tool to randomly generate computer science research papers. This was designed as a joke. But it is funny to try it and see what is generated. It can even generate some graphs and charts. To use the tool, all you need to do is fill the author names and click “Generate“:
The User interface of SCIGEN
Although papers generated by this tool generally do not make sense when you look at the details, some people have submitted generated papers to some predatory conferences to show that there is no review process and that the goal is just to get some money. You can see more details about that story on the website of SCIGEN.
Conclusion
That is all for today. I just wanted to share a few interesting websites that are not useful for your research but I think are funny or interesting.
If you have some other good websites, you may post them in the comment section below.
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.