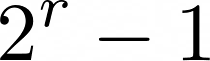Today, I post one more new video to explain concepts about pattern mining. In the new video, I talk about high utility itemset mining, and explain the HUI-Miner and FHM algorithms. Those are two popular high utility itemset mining algorithms that have been used in hundreds of research papers.
I have posted a new video about pattern mining, explaining the PrefixSpan algorithm. It assumes that you know already what is sequential pattern mining. If you are not familiar with sequential pattern mining, you can first watch my video Introduction to sequential pattern mining.
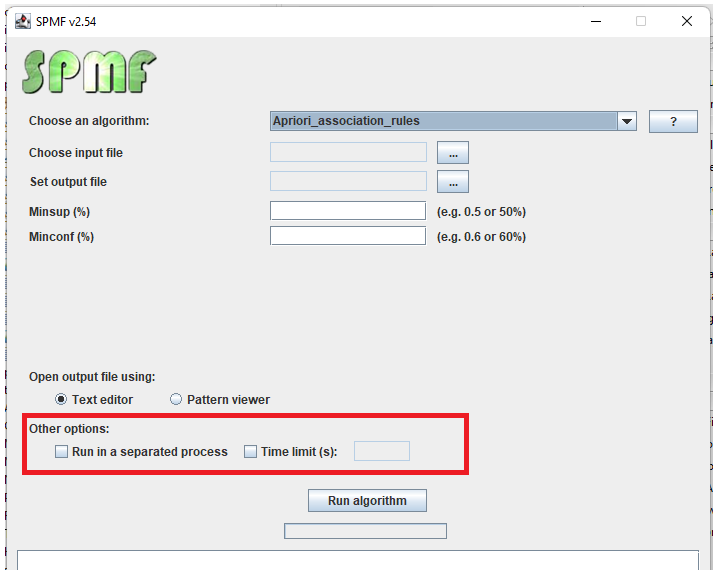
Today, I will reveal some upcoming features of SPMF, which I am currently testing and will be released in the next version (2.54), probably in about 1 week.
1) The first new feature is that it will be possible to launch an algorithm in a separated virtual machine instead of using a thread in the same virtual machine. This option is useful for running performance experiments as it ensures that a new virtual machine is used for each algorithm execution. This avoids the problem that the memory is not released by the Java Garbage collector.
2) The second new feature is a time limit. It will now be possible to set a maximum time limit and to kill an algorithm automatically after exceeding that time limit.
The features are already implemented and I have tested them on Windows. I will be testing them on Linux later to see if it also works before releasing them.
If you have any suggestions for other features, you may leave a comment in the comment section below. I am happy to receive any comments to improve the software 🙂
This is a short blog post where I will explain how to call SPMF as an external program from another Java program to execute an algorithm.
Before we start, it should be said that there are multiple ways to use SPMF. It can be used as a standalone program with a graphical user interface and from the command line. Moreover, the code of SPMF can be directly integrated in other Java programs, and SPMF can also be called using unofficial wrappers from other languages such as Python and R.
If you want to use SPMF from a Java program, it can be desirable in some cases to call SPMF using its command line interface rather than integrating the code of SPMF directly in your Java program. The adavantage is that SPMF is then executed as a separated process on your computer and it may be easier to maintain. How to do this?
First, you should download spmf.jar from the download page of the SPMF website and put it in the same folder as your Java program.
Second, you should lookup which algorithm you want to use in the documentation webpage of the SPMF website. For this example, lets say that we want to call the Apriori algorithm on a file called “contextPasquier99.txt” with the parameter minsup = 40% and save the result in a file “output.txt“.
According to the documentation of Apriori, we should write a command like this to execute it from the command line:
java -jar spmf.jar run Apriori contextPasquier99.txt output.txt 40%
From Java code, we can write do like this:
List commandWithParameters = new ArrayList();
commandWithParameters.add("java");
commandWithParameters.add("-jar");
commandWithParameters.add("spmf.jar");
commandWithParameters.add("run");
commandWithParameters.add("Apriori"); // Algorithm name
commandWithParameters.add("contextPasquier99.txt"); // input file
commandWithParameters.add("output.txt"); // output file
commandWithParameters.add("0.5%"); // parameter
ProcessBuilder pb = new ProcessBuilder(commandWithParameters);
pb.redirectOutput(Redirect.INHERIT); // This will redirect the output of SPMF to the console
Process process = pb.start(); // Run SPMF in a separated process
Running this code, will execute the Apriori algorithm and write some statistics in the console:
============= APRIORI - STATS =============
Candidates count : 11
The algorithm stopped at size 4
Frequent itemsets count : 9
Maximum memory usage : 7.322685241699219 mb
Total time ~ 0 ms
===================================================
If you want your Java program to wait for the completion of SPMF before continuing, you can add this line:
int exitValue = process.waitFor();
It is also possible to stop the process using this:
If you like these videos, you can also check the video page of the SPMF software website, where I have put more videos to explain algorithms. Also, you can check out my Youtube channel, which contains also various recorded talks that I have given.
I you would like that I make a video about a particular topic, you may leave a comment below, and I will consider it if I have time and I think the topic is good.
The TKU-CE algorithm for heuristically mining the top-k high-utility itemsets with cross-entropy (thanks to Wei Song, Lu Liu, Chuanlong Zheng et al., for the original code)
The TKU-CE+ algorithm for heuristically mining the top-k high-utility itemsets with cross-entropy with optimizations (thanks to Wei Song, Lu Liu, Chuanlong Zheng et al., for the original code)
The TKQ algorithm for mining the top-k quantitative high utility itemsets (thanks to Nouioua, M. et al., for the original code)
Besides, since December, four more algorithms have been released (in SPMF 2.50 and 2.51):
The SFU-CE algorithm for mining skyline frequent high utility itemsets using the cross-entropy method (thanks to Wei Song, Chuanlong Zheng et al., for the original code)
The POERMH algorithm for mining partially ordered episode rules in a sequence of events, using the head support (thanks to Yangming Chen et al. for the original code)
The SFUI_UF algorithm for mining skyline utility itemsets using utility filtering (thanks to Wei Song, Chuanlong Zheng et al., for the original code)
The HAUIM-GMU algorithm for mining high average utility itemsets (thanks to Wei Song, Lu Liu, et al. for the original code)
Need your contributions!
For the SPMF project, we are always looking for new contributors. If you are interested to participate (e.g. contributing code of new algorithms, bug fixes, etc.), you can contact with me at philfv AT qq.com.
Typhoons can be very destructive. Predicting their paths is important to be prepared when they arrive. In this blog post, I will talk briefly about an applied research topic which is to predict the paths of typhoons. This blog post is based on a recent research paper published in Neural Computing and Applications, where I have participated as co-author:
Xu, G., Xian, D., Fournier-Viger, P., Li, X., Ye, Y., Hu, X. (2022). AM-ConvGRU: A Spatio-Temporal Model for Typhoon Path Prediction. Neural Computing and Applications, Springer,
Over the years many models have been proposed for typhoon path prediction. But the accuracy of these models could be improved. In general, we want to have models that are as accurate as possible.
Predicting typhoon paths is a difficult problem because it involves spatial data and temporal data, that is described using numerous features. Moreover, some features are 2D features while others are 3D features and combining them is also a challenge.
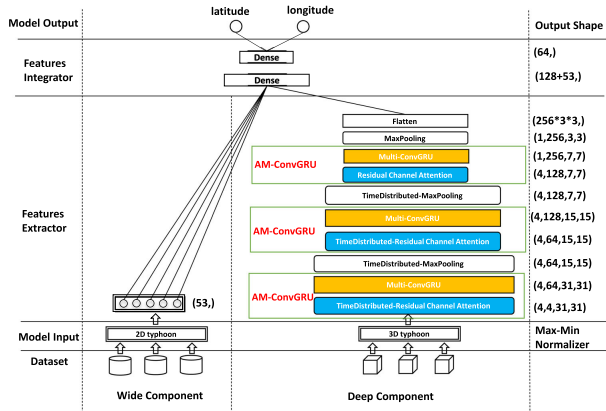
To address this issue, in the above paper, we presented a deep learning framework to perform accurate predictions of the paths of typhoons. The model is called Attention-based Multi ConvGRU (AM-ConvGRU).
For that research project, typhoons data was obtained from two sources: (1) the China Meteorological Administration (CMA) and (2) the European Centre for Medium-Range Weather Forecasts (ECMWF). The first provides data about 2D typhoons while the second provides 3D typhoon data. The data covers typhoons in the Western North Pacific (WNP) basin. Here is a visualization of typhoon paths from the paper:
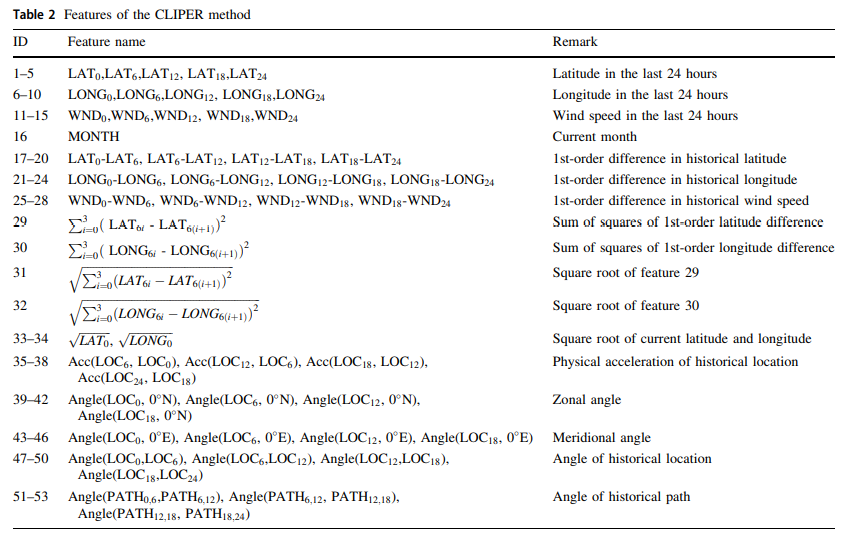
After obtaining the data, the data has to be preprocessed. In particular, the 2D typhoon data is transformed into 53 features, according to a method called CLIPPER. These features are depicted in the table below as example.
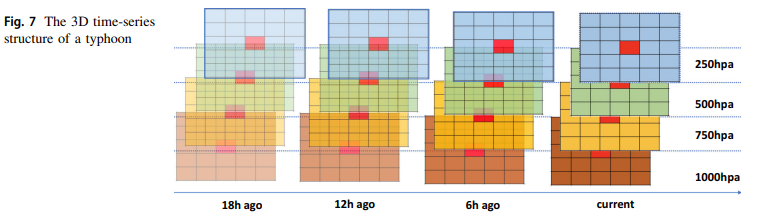
Similarly, the 3D typhoon data has to been prepared. This is done by dividing the earth into a grid of 1 degree by 1 degree, by geopotential, and then looking more closely at the zone around the typhoon center. I will skip the details. But the result is a 3D time series structure:
After that, the deep learning model is trained using the 3d and 2D typhoon data. This is an overview of the model’s architecture:
I will skip the details.
To evaluate the proposed model, it was compared with state-of-the-art models. It was shown that the proposed model can generally provide better predictions.
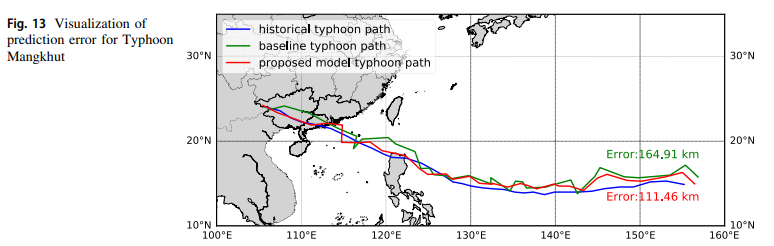
To show a little bit more clearly what is the output, here is an illustration of some prediction by the proposed model, a baseline model, and to the historical path for Typhoon Mangkhut:
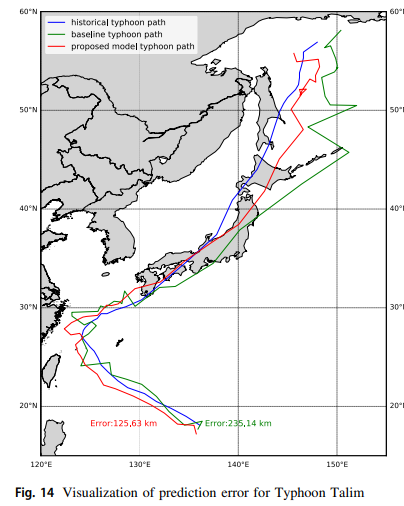
It can be seen that the proposed model is closer to the historical path than the baseline by over 50 km. Here is another example for Typhoon Talim:
The improvement of distance error for the proposed model over the baseline is over100 km.
Hope this has been interesting. This is just a very short overview of the topic of typhoon path prediction. If you are interested, please check the paper!
This week, I have attended the 16th International Conference on Advanced Data Mining and Applications(ADMA 2021) conference, which is held online due to the COVID pandemic.
What is ADMA ?
ADMA is a medium-scale conference that focus on data science and its applications (hence its name). The ADMA conference is generally held in China but was twice in Australia and once in Singapore. I participated to this conference several times. If you want to read my report about previous ADMA conferences, you can click here: ADMA 2019, ADMA 2018, ADMA 2013 and ADMA 2014.
This time, the conference was called ADMA 2021, although it is held from the 2nd to 4th February 2022. The reason why the conference is held in 2022 is that it was postponed due to the COVID-19 pandemic. ADMA 2021 was co-located with the australasian artificial intelligence conference (AJCAI 2021), which is a national conference about AI.
Proceedings
The proceedings are published by Springer in the Lecture Notes in Artificial Intelligence series as two volumes. The proceedings contain 61 papers, among which 26 were presented orally at the conference while the remaining were presented as posters.
The papers were selected from 116 paper submissions, which means an overall acceptance rate of 61 / 116 = 52 % and 22 % for the papers presented orally.
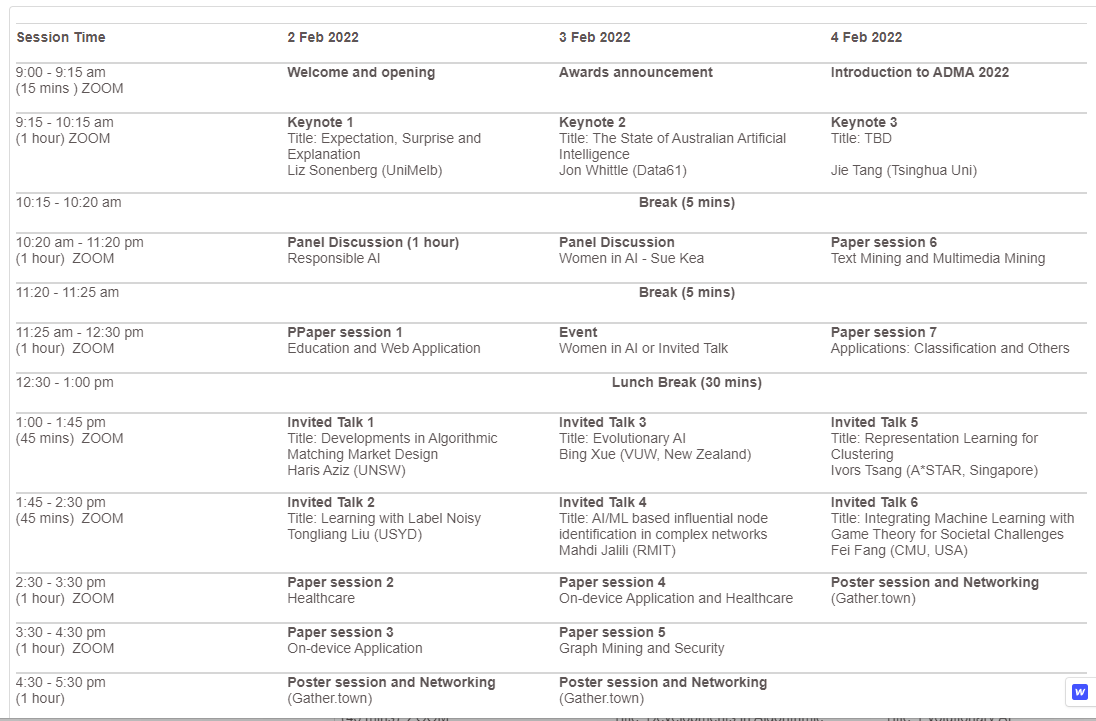
Schedule
The ADMA conference was held on three days. There was three keynote talks, two panels, six invited talks, two hours for poster sessions and some regular paper sessions. The schedule is below.
The conference was held according to the Australian time zone, which means that I had to wake up at 6 PM in China to see the first events.
A virtual conference
The ADMA conference was hosted on the Zoom platform for viewing the presentations and another platform called GatherTown for social interactions. The Gathertown platform is used by several conferences. Using this platform, each attendee can create an avatar and to explore a 2D world. Then, when you go closer to the avatar of another person, you can have a discussion via webcam and microphone with that person. This allows to recreate a little bit the atmosphere of a real conference. Here are a few screenshots of this virtual environment:
Several options to edit your avatarThe welcome room of ADMA 2021Another roomA chat room with a few chairs and a tableOne of the poster rooms
Day 1 – Panel on Responsable AI
On the first day, there was a panel on responsable AI with 4 invited panelists. The discussion was on topics such as how to improve the brand of Australia for AI, the need on more funding for Responsabble AI in Australia, AI regulations, AI ethics, deepfakes, etc.
Day 1 – Paper sessions
On the first day, there was also some paper sessions. There was several topics such as personalized question recommendation, cheating detection, a paper about a new dataset, and medical applications.
Day 1 – Poster sessions
The poster session was held in Gather Town. During the poster session, I have stayed mostly beside my poster in case some people would come to talk with me. It works as follows. If some persons approach your poster, then it starts a webcam discussion with them. There was over 60 persons online at that time. I have discussed with maybe 4 or 5. Here are a few screenshots from the poster session:
Waiting for people to come see my virtual posterAn example of view that we get when looking at a poster (my poster)
Globally, this idea of using GatherTown is interesting. It allows to make some social interactions, which otherwise would be lacking for a virtual conference. However, some thing that I think could be improved about poster sessions in GatherTown is that there is no index or search function to find a poster. Thus, to search for a poster we must go around the room to try to find it, which takes time. Also another area for improvement is that when showing a poster to another attendee, that person cannot see your mouse cursor. That is something that GatherTown developers could improve.
Pattern mining papers
As readers of this blog know, I am interested by pattern mining research. So here, I have made a list of the main pattern mining papers presented at the conference:
3- “OPECUR: An enhanced clustering-based model for discovering unexpected rules”
4- “Extracting High Profit Sequential Feature Groups of Products using High Utility Sequential Pattern Mining”
5- “Game Achievement Analysis: Process Mining Approach”
6- “Tourists Profiling by Interest Analysis”
It is interesting to see that three of this papers are related to high utility pattern mining, a popular research direction in pattern mining. The last paper is related to process mining, which is also a popular topic about the application of pattern mining and data mining to analyze business processes.
Award ceremony
I missed the award ceremony because it started very early (6:00 AM) in my time zone (China) so I will not report the details about awards but I got the news that I received this award afterward:
Next ADMA conference (ADMA 2022)
The next ADMA conference will be called ADMA 2022 and be in Brisbane, Australia, probably around December.
Conclusion
Overall, ADMA 2021 was a good conference. That is all for today!
Nouioua, M., Fournier-Viger, P., Gan, W., Wu, Y., Lin, J. C.-W., Nouioua, F. (2021).TKQ: Top-K Quantitative High Utility Itemset Mining. Proc. 16th Intern. Conference on Advanced Data Mining and Applications (ADMA 2021) Springer LNAI, 12 pages [ppt]
The source code and datasets will be made available in the next release of the SPMF data mining library.
This is a very short blog post about the calculation of the number of possible association rules in a dataset. I will assume that you know already what is association rule mining.
Let’s say that you have a dataset that contains r distinct items. With these items, it is possible to make many rules. Since the left side and right side of a rule cannot be empty, then the left side of a rule can contain between 1 to r-1 items (since the right side of a rule cannot be empty). Lets say that the number of items on the left size of a rule is called k and that the number of items on the right size is called j.
Then, the total number of association rules that can be made from these r items is:
For example, lets say that we have r = 6 distinct items. Then, the number of possible association rules is 602.
This may seems a quite complex expression but it is correct. I have first seen it in the book “Introduction to Data Mining” of Tan & Kumar. If you want to type this expression in Latex, here is the code: