This week, I am attending the DSIT 2021 conference (4th International Conference on Data Science and Information Technology) from July 23 to 25 in Shanghai, China.

The DSIT 2021 conference is co-located with the DMBD 2021 conference (the 4th International Conference on Data Mining and Big Data).
DSIT is a relatively young conference, which focuses on data science and data mining. But the quality was good and it was well organized. The proceedings of the conference are published by ACM. Thus, all papers are in the ACM Digital Library. This gives visibility to the papers.
A total of 150 submissions were received and 80 full papers were accepted for publication (acceptance rate = 53%). The papers were from several countries including China, Japan, Singapore, Vietnam, Philippines, Pakistan, Thailand, USA, Greece, France and Germany.
There was also several keynote speakers: Prof. Tok Wang Ling from National University of Singapore, Prof. Ma Maode from Nanyang Techn. University of Singapore, Prof. Shigeo Akashi from Tokyo University of Science, Japan and Prof. Philippe Fournier-Viger (myself) from Harbin Inst. of Technology (Shenzhen), China.
Due to the COVID pandemic and travel restrictions, the conference was held in Shanghai but some speakers were online through Zoom.
Day 1 – Registration
On the first day, I registered at the conference reception desk at hotel and receive a bag with the program, ID card, a small gift, and other things.

Day 2 – Keynote Talk
First, there was the opening ceremony.

Then, it was the keynote talks. I started first with my invited talk on algorithms for discovering patterns in data that are in interpretable (pattern mining).
Then, there was the talk by Prof. Jie Yang on adversarial attacks on deep neural networks. He has shown some recent work on generating adversarial pictures to fool neural networks. For instance a picture of a car may be slightly modified to fool a neural network into believing it is a house. What I find the most interesting about this talk is that it was shown that some modified pictures can fool not only one network but all the state of the art deep neural networks for image recognition. The reason why it is possible to fool multiple networks with a same modified picture is that an attack based on attention was used and that many deep neural networks will use attention in a similar way (focusing on the same image features). A dataset of adversarial images called DAmageNet was also presented, which can be helpful to test ways to protecting against such attacks. An interesting conclusion was that these attacks are possible because deep neural models tend to ignore some important features and incorporate unnecessary features.




Then, there was the other keynote talks.
Day 2 – Paper presentation
Then there was the regular paper presentations and a poster session.

There was two papers related to pattern mining. The first one was about high utility itemset mining and the other about frequent pattern mining.
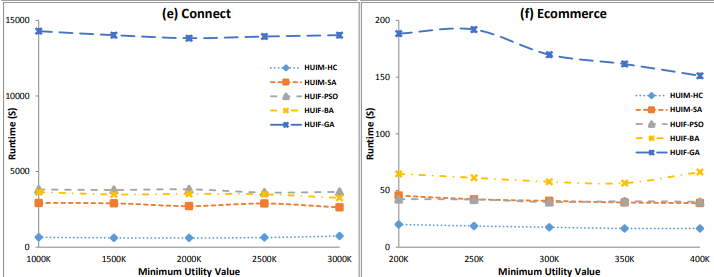
- High Utility pattern mining based on historical data table over data streams by Xinru Chen, Pengjun Zhai and Yu Fang
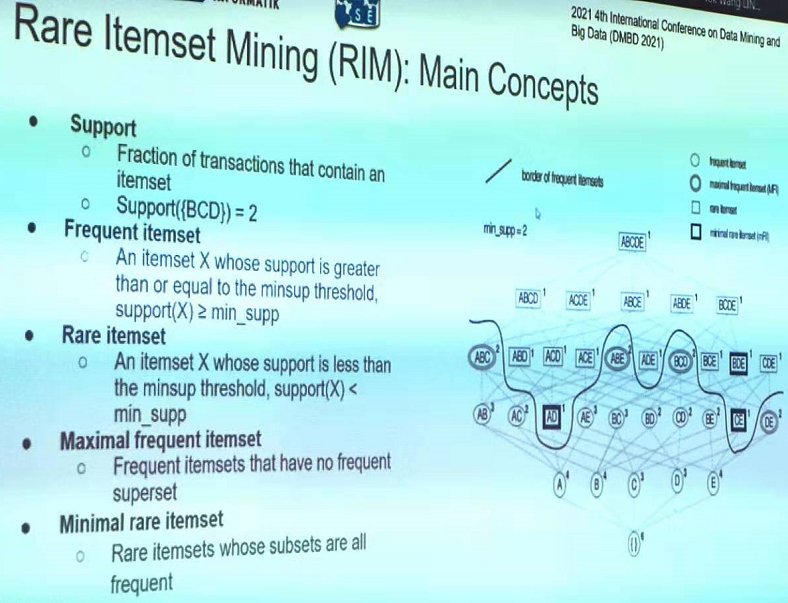
- MaxRI: A method for discovering maximal rare itemsets by Sadeq Darrab et al.
I took some pictures of a few slides from that paper about maximal rare itemsets, as I find this to be an interesting topic:






Conclusion
This is all I will write for this conference. Overall, that was an interesting conference. It is not a very big conference but I met some other interesting researchers and we had some good discussions. Some papers were also quite good.
In a few days, I will be attending the IEA AIE 2021 conference and will report also about it.
—
Philippe Fournier-Viger is a full professor working in China and founder of the SPMF open source data mining software.