
Today, I will show how to use the open-source SPMF data mining software to discover sequential patterns in web log data. Then, I will show to how visualize the frequent sequential patterns found using GraphViz.
Step 1 : getting the data.
The first step is to get some data. To discover sequential patterns, we will use the SPMF software. Therefore the data has to be in SPMF format. In this blog post, I will just use the web log data from the FIFA world cup from the datasets webpage of the SPMF website. It is already in SPMF format.
Step 2 : extracting sequential patterns.
Then using the SPMF.jar file downloaded from the SPMF website, I have applied the PrefixSpan algorithm to discover frequent sequences of webpages visited by the users. I have set the minsup parameter of PrefixSpan to 0.15, which means that a sequence of webpages is frequent if it is visited by at least 15% of the users.
The result is an output file containing 5123 sequential patterns in a text file. For example, here are three patterns from the output file:
155 -1 44 -1 21 -1 #SUP: 4528 147 -1 #SUP: 7787 147 -1 59 -1 #SUP: 6070 147 -1 57 -1 #SUP: 6101
The first one represents users vising the webpage 155, then visiting webpage 44 and then 21. The line indicates that this patterns has a support of 4528, which means that this patterns is shared by 4528 users.
The result may be hard to understand in a text file, so we will next visualize them using GraphViz.
Step 3: Transforming the output file into GraphViz DOT format.
I use a very simple piece of Java code to transform the sequential patterns found by SPMF to the GraphViz DOT format.
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
/**
* @author Philippe Fournier-Viger, 2014
*/
public class MainDatasetConvertSequentialPatternsToDotFormat {
public static void main(String [] arg) throws IOException, InterruptedException{
String input = "C:\\patterns\\test.txt";
String output = "C:\\patterns\\input.dot";
BufferedReader myInput = new BufferedReader(new InputStreamReader( new FileInputStream(new File(input))));
// map to remember arrow already seen
Map<String, String> mapEdges = new HashMap<String, String>();
// for each line (pattern) until the end of file
String thisLine;
while ((thisLine = myInput.readLine()) != null) {
if (thisLine.isEmpty() == true) {
continue;
}
// split the pattern according to the " " separator
String split[] = thisLine.split(" ");
boolean firstItemOfItemset = true;
boolean firstItemset = true;
String previousItemFromSameItemset = null;
// for each token
for(String token : split) {
if("-1".equals(token)) { // if end of an item
}else if("-2".equals(token) || '#' == token.charAt(0)){ // if end of sequence
previousItemFromSameItemset = null;
break;
}else { // if an item
if(previousItemFromSameItemset != null) {
mapEdges.put(previousItemFromSameItemset, token);
}
previousItemFromSameItemset = token;
}
}
}
BufferedWriter writer = new BufferedWriter(new FileWriter(output));
writer.write("digraph mygraph{");
// PRINT THE ARROWS
for(Entry<String, String> edge : mapEdges.entrySet()) {
writer.write(edge.getKey() + " -> " +edge.getValue() + " \n");
}
// Note: only sequential patterns of size >=2 are used to create the graph and
// patterns are assumed to have only one item per itemset.
writer.write("}");
myInput.close();
writer.close();
}
}
Step 4: Generating a graph using GraphViz
Then I installed GraphViz on my computer running Windows 7. GraphViz is a great software for the visualization of graphs and it is not very hard to use. The idea is that you feed GraphViz with a text file describing a graph and then he will automatically draw it. Of course there are many options that can be selected and here I just use the basic options.
I use the command: dot -Tpng patterns.dot > output.png"
This convert my DOT file to a graph in PNG format.
The result is the following (click on the picture to see it in full size).
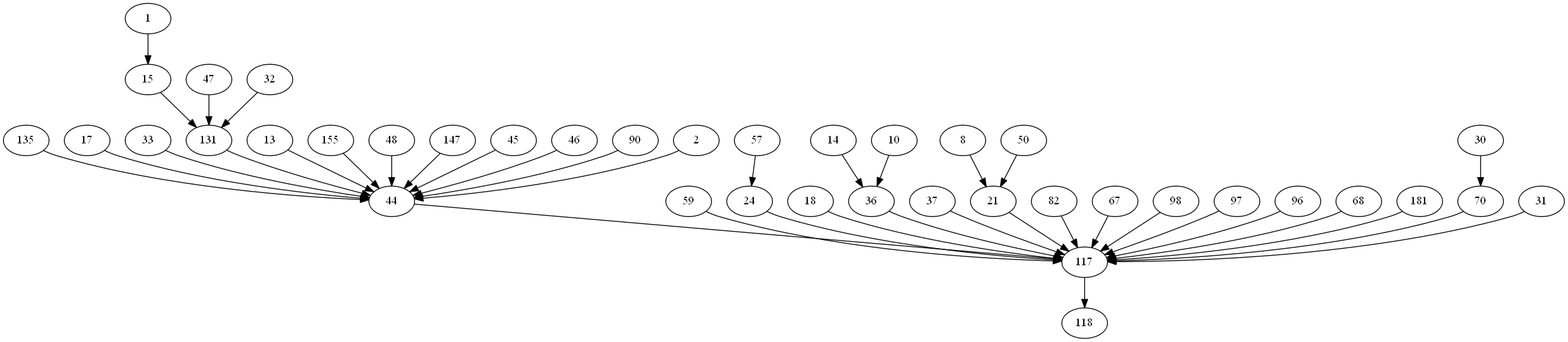 The result is pretty interesting. It summarizes the 5123 patterns into an easy to understand graph. By looking at the graph we can easily see that many sequential patterns passes by the nodes 44 and 117, which must be very important webpages on the website.
The result is pretty interesting. It summarizes the 5123 patterns into an easy to understand graph. By looking at the graph we can easily see that many sequential patterns passes by the nodes 44 and 117, which must be very important webpages on the website.
Note that using this technique, we loose a little bit information. For example, the support of edges is not indicated on this graph. It may be possible to improve upon this visualization for example by using various colors to indicate the support or the number of patterns that pass by a node.
Hope that you have enjoyed this post. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.
Philippe Fournier-Viger is an assistant professor in Computer Science and also the founder of the open-source data mining software SPMF, offering more than 52 data mining algorithms.




hello Dr.
thank you so much for this blog ,, you have no idea how you helped me
i was struggling to find a field for my PHD thesis and i found this blog through google . unfortunately when i took data mining course, i took it very with a really bad professor and i didn’t like it at all but after reading some of your posts I loved it and i went ahead and re-opened my introductory book about data mining to learn about it all over again and i made my mind that my PHD thesis will be about data mining in education “i still have no how I’m going to do this is, but I’m learning” so can you recommend any thing to read about this field ?
best regards
Hi,
Thanks for your message!
If you want some general books about data mining from a computer science perspective, I recommend the following books:
– Introduction to data mining by Tan & Kumar. You can get three free chapters here: http://www-users.cs.umn.edu/~kumar/dmbook/index.php The free chapters introduce three importants topics in data mining : classification, clustering and pattern mining. In the full book, there are also some advanced chapters on these topics, but the free chapters are a good introduction. This book is easy to read compared to some other data mining books.
– The book by Han & Kamber. This book is like an encyclopedia of data mining. The good point is that it describes a lot of things. But because of that, it contains less details or code about each approach that is described
– Lastly, here is a free PDF Draft of upcoming book by Mohamed Zaki about Data Mining. Zaki is a famous researcher in the field of data mining, especially in pattern mining (itemset, sequence and association mining). This book dot not describe the very recent approaches and is a little bit more formal than the previous books.
http://www2.dcc.ufmg.br/livros/miningalgorithms/DokuWiki/doku.php
This is just some starting points. Besides books, you could search specific topics.
thank you so much ,, ,, I bought the first book you recommended and I’m still waiting for it to be delivered and i will buy the second book but the last link of the third book isn’t working unfortunately,, any way thank you so much
You are right, there was an error with the last link. Here it is:
http://www.dcc.ufmg.br/miningalgorithms/files/pdf/dmafca.pdf
Dear sir,
I have tried with SPMF to generate the pattern as you have mentioned in your blog, i could not get any pattern for the web access log (http request log from the web server). I want to know whether we have to perform any data pre processing work on we b log.
Hi,
It is probably because of the input format. As I said in the blog post, the web log file that I have used was first preprocessed to be in the correct format (in SPMF format). If you take a weblog file from internet, you would need to convert it first to the appropriate format used by SPMF.
By the way, please don’t send the same message to all my e-mails.
Philippe
Thank you sir
Pingback: New version of SPMF Java open-source data mining library (0.95) - The Data Mining & Research Blog