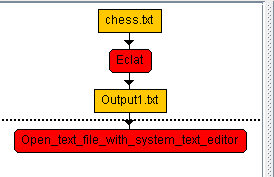
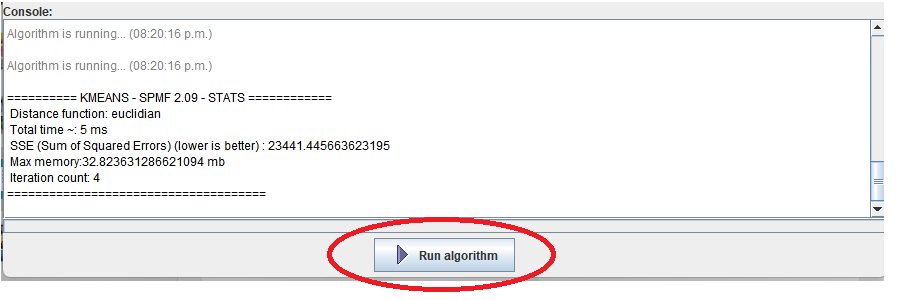
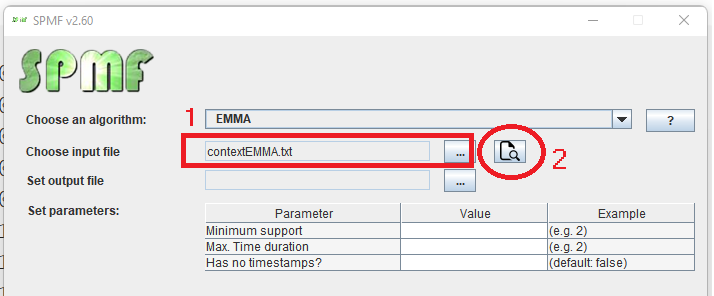
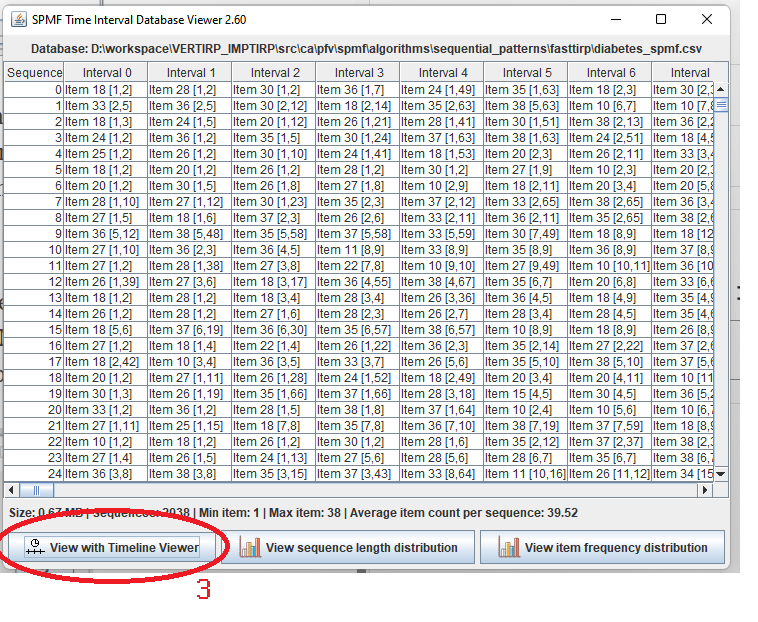
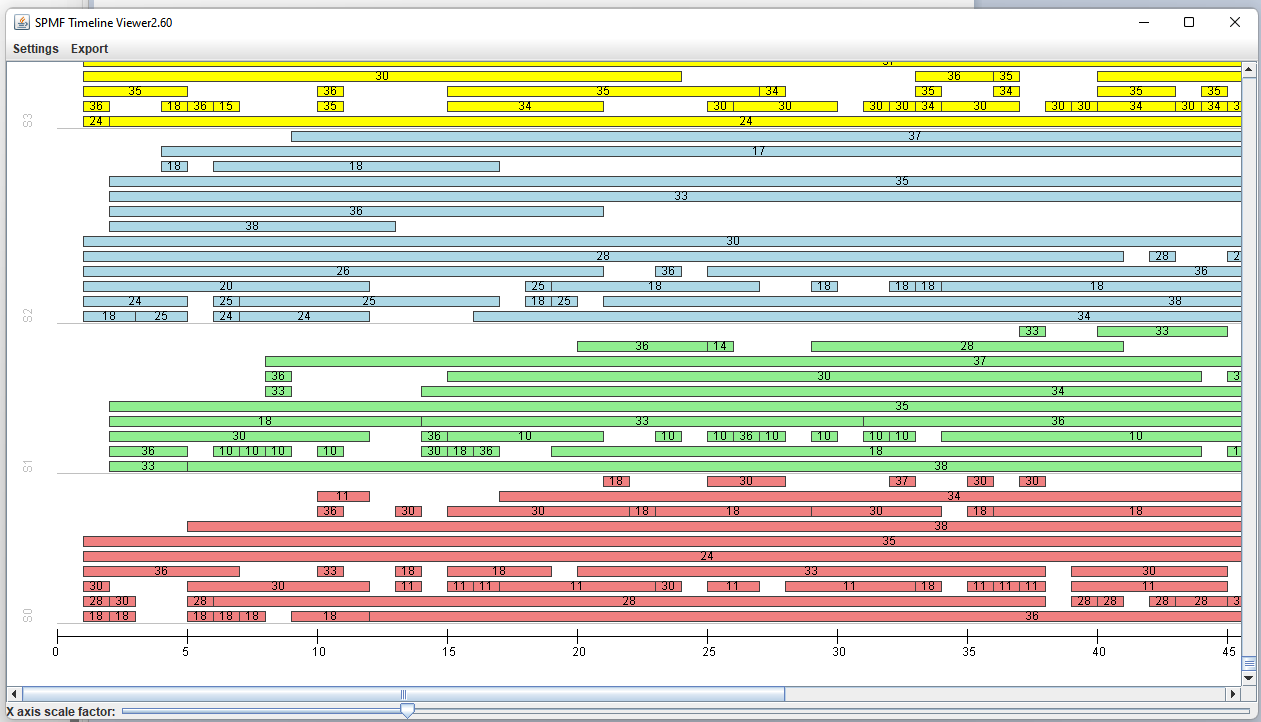
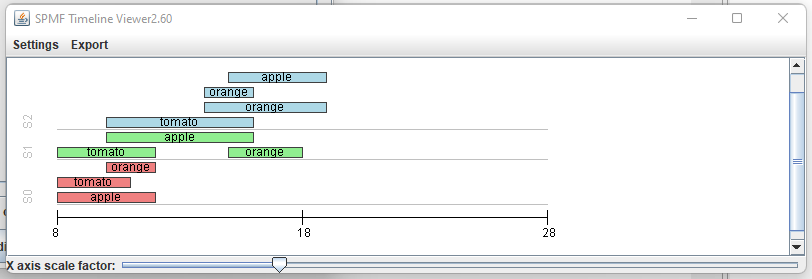
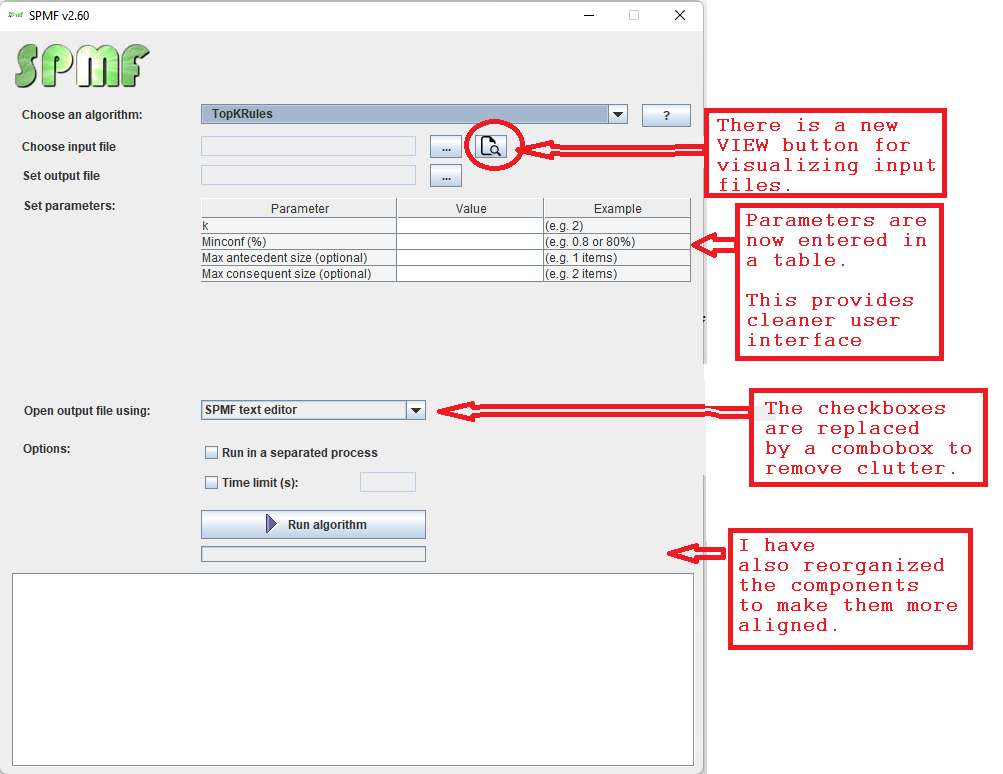
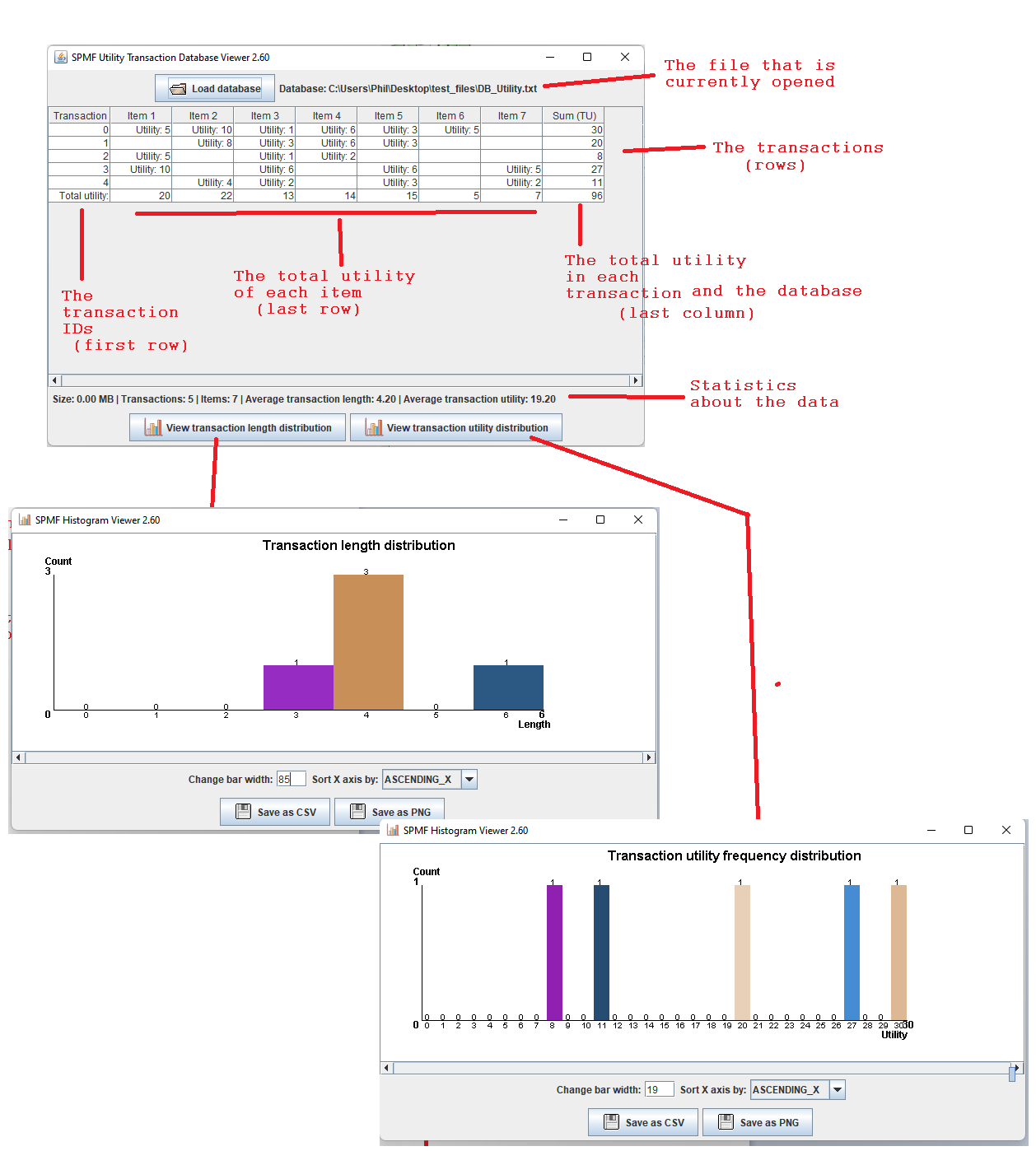
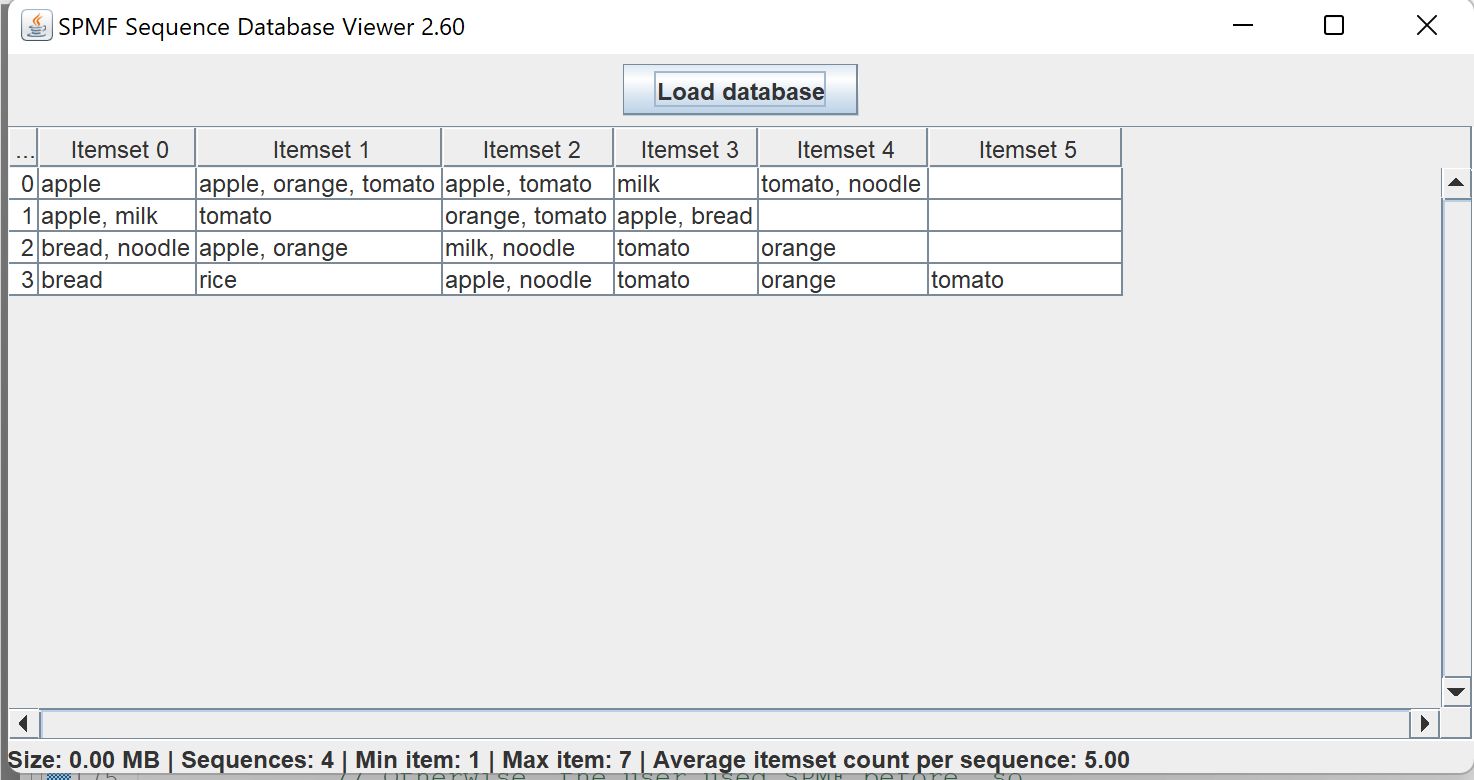
While I am preparing the next version of Java SPMF data mining software (2.60), here are some interesting statistics about the project, that I have generated directly from the metadata provided by SPMF. Here it is:
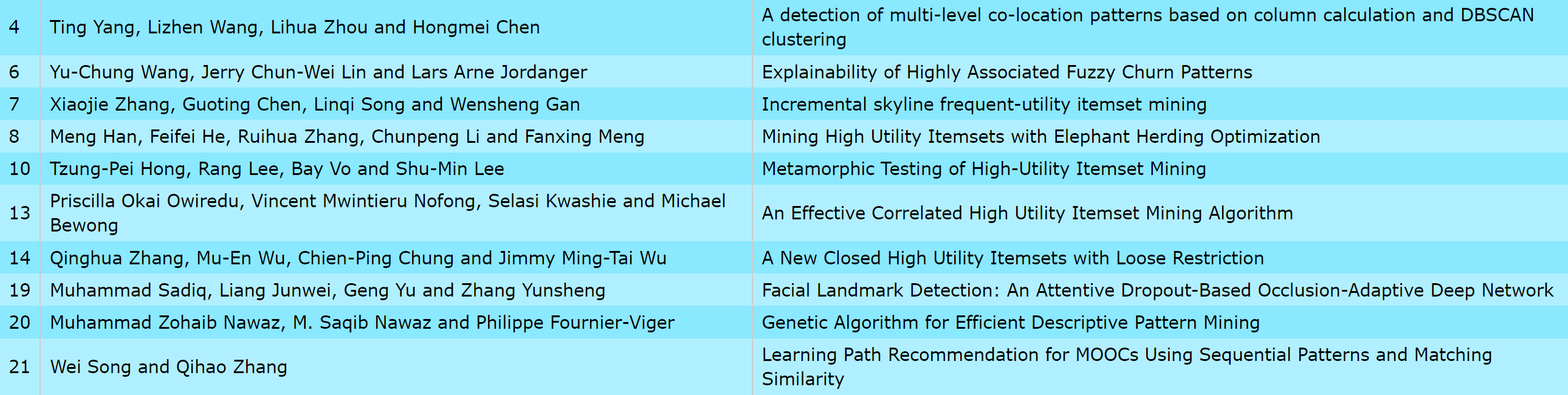
The number of algorithms implemented per person (based on metadata)
Note: this is generated automatically according to the metadata of each algorithm in SPMF using the class DescriptionOfAlgorithm, and some author names are spelled in multiple ways, and may contain some errors. The full list of contributors of SPMF is displayed on the SPMF website.
| Philippe Fournier-Viger | 206 |
| Yang Peng | 12 |
| Antonio Gomariz Penalver | 9 |
| Jayakrushna Sahoo | 6 |
| Jerry Chun-Wei Lin | 5 |
| Lu Yang | 5 |
| Chen YangMing | 5 |
| Wei Song et al. | 5 |
| Yangming Chen | 5 |
| Wei Song | 4 |
| Ting Li | 4 |
| Azadeh Soltani | 4 |
| Peng Yang and Philippe Fournier-Viger | 4 |
| Nader Aryabarzan | 4 |
| Vincent M. Nofong modified from Philippe Fournier-Viger | 3 |
| Cheng-Wei Wu et al. | 3 |
| Zhihong Deng | 3 |
| Prashant Barhate | 3 |
| Chaomin Huang et al. | 3 |
| Jiaxuan Li | 3 |
| Zhitian Li | 3 |
| Antonio Gomariz Penalver & Philippe Fournier-Viger | 3 |
| Yimin Zhang | 2 |
| Chaomin Huang | 2 |
| Nouioua et al. | 2 |
| Ting Li et al. | 2 |
| Philippe Fournier-Viger and Yuechun Li | 2 |
| Song et al. | 2 |
| Fournier-Viger et al. | 2 |
| Saqib Nawaz et al. | 2 |
| Chao Cheng and Philippe Fournier-Viger | 2 |
| Zevin Shaul et al. | 2 |
| Alan Souza | 2 |
| Rathore et al. | 2 |
| Bay Vo et al. | 2 |
| Junya Li | 2 |
| Ryan Benton and Blake Johns | 2 |
| Siddharth Dawar et al. | 2 |
| Yanjun Yang | 2 |
| Siddhart Dawar et al. | 2 |
| Huang et al. | 1 |
| M. | 1 |
| C.W. Wu et al. | 1 |
| Philippe Fournier-Viger and Cheng-Wei Wu | 1 |
| Sacha Servan-Schreiber | 1 |
| Dhaval Patel | 1 |
| jnfrancis | 1 |
| Cheng-Wei. et al. | 1 |
| Ganghuan He and Philippe Fournier-Viger | 1 |
| Siddharth Dawar | 1 |
| Improvements by Nouioua et al. | 1 |
| Philippe Fournier-Viger and Chao Cheng | 1 |
| Yang Peng et al. | 1 |
| Salvemini E | 1 |
| Java conversion by Xiang Li and Philippe Fournier-Viger | 1 |
| Alex Peng et al. | 1 |
| Hoang Thanh Lam | 1 |
| Souleymane Zida | 1 |
| F. | 1 |
| Shifeng Ren | 1 |
| Lanotte | 1 |
| github: limuhangk | 1 |
| Youxi Wu et al. | 1 |
| Hazem El-Raffiee | 1 |
| Jiakai Nan | 1 |
| Ahmed El-Serafy | 1 |
| Souleymane Zida and Philippe Fournier-Viger | 1 |
| Feremans et al. | 1 |
| Han J. | 1 |
| Shi-Feng Ren | 1 |
| Fumarola F | 1 |
| Vikram Goyal | 1 |
| P. F. | 1 |
| Petijean et al. | 1 |
| Srinivas Paturu | 1 |
| Malerba D | 1 |
| & Malerba | 1 |
| Ashish Sureka | 1 |
| Fumarola | 1 |
| Ying Wang and Peng Yang and Philippe Fournier-Viger | 1 |
| Sabarish Raghu | 1 |
| Wu et al. | 1 |
| D. | 1 |
| Srikumar Krishnamoorty | 1 |
| Siddharth Dawar et al | 1 |
| Ceci | 1 |
| Wu | 1 |
The number of algorithms per category
| HIGH-UTILITY PATTERN MINING | 83 |
| FREQUENT ITEMSET MINING | 54 |
| SEQUENTIAL PATTERN MINING | 48 |
| TOOLS – DATA VIEWERS | 22 |
| TIME SERIES MINING | 16 |
| ASSOCIATION RULE MINING | 16 |
| TOOLS – DATA TRANSFORMATION | 15 |
| PERIODIC PATTERN MINING | 13 |
| EPISODE MINING | 10 |
| EPISODE RULE MINING | 10 |
| CLUSTERING | 10 |
| SEQUENTIAL RULE MINING | 10 |
| GRAPH PATTERN MINING | 6 |
| TOOLS – DATA GENERATORS | 5 |
| TOOLS – STATS CALCULATORS | 4 |
| TOOLS – SPMF GUI | 4 |
| TOOLS – RUN EXPERIMENTS | 1 |
| PRIVACY-PRESERVING DATA MINING | 1 |
The number of algorithms per type
| DATA_MINING | 259 |
| DATA_PROCESSOR | 30 |
| DATA_VIEWER | 25 |
| DATA_GENERATOR | 5 |
| OTHER_GUI_TOOL | 4 |
| DATA_STATS_CALCULATOR | 4 |
| EXPERIMENT_TOOL | 1 |
The number of algorithms for each input data type
- Transaction database (194)
- Simple transaction database (80)
- Transaction database with utility values (77)
- Sequence database (73)
- Simple sequence database (48)
- Transaction database with timestamps (17)
- Time series database (16)
- Sequence database with timestamps (9)
- Database of double vectors (8)
- Labeled graph database (6)
- Graph database (6)
- Transaction database with utility values and time (5)
- Multi-dimensional sequence database with timestamps (4)
- Text file (4)
- Multi-dimensional sequence database (4)
- Time interval sequence database (3)
- Sequence database with utility values (3)
- Transaction database with utility values and taxonomy (3)
- Transaction database with shelf-time periods and utility values (3)
- Transaction database with utility values (HUQI) (3)
- Sequence database with cost and binary utility (3)
- Simple time interval sequence database (3)
- Frequent closed itemsets (3)
- Sequence database with cost and numeric utility (2)
- Transaction database with utility values skymine format (2)
- Transaction database with profit information (2)
- Uncertain transaction database (2)
- ARFF file (2)
- Transaction database with utility and cost values (2)
- Sequence database with strings (2)
- Dynamic Attributed Graph (2)
- Simple sequence database with strings (2)
- Sequence database with utility and probability values (2)
- Cost sequence database (2)
- Sequential patterns (1)
- Set of text documents (1)
- Sequence database in non SPMF format (1)
- Clusters (1)
- Sequence (1)
- Single sequence (1)
- Transaction database with utility values (MEMU) (1)
- Transaction database in non SPMF format (1)
The number of algorithms for each output data type
- High-utility patterns (91)
- High-utility itemsets (60)
- Frequent patterns (56)
- Sequential patterns (51)
- Frequent itemsets (37)
- Frequent sequential patterns (30)
- Database of instances (22)
- Association rules (16)
- Episodes (15)
- Time series database (14)
- Periodic patterns (13)
- Transaction database (12)
- Periodic frequent patterns (12)
- Sequential rules (11)
- Episode rules (10)
- Frequent closed itemsets (9)
- Frequent closed sequential patterns (8)
- Simple transaction database (8)
- Sequence database (8)
- Closed itemsets (8)
- Top-k High-utility itemsets (7)
- Closed high-utility itemsets (7)
- Simple sequence database (6)
- Frequent Sequential patterns (6)
- Clusters (6)
- Closed patterns (6)
- Frequent episodes (6)
- Frequent sequential rules (5)
- Rare itemsets (5)
- Rare patterns (5)
- High average-utility itemsets (5)
- Frequent episode rules (5)
- Skyline patterns (4)
- Subgraphs (4)
- Generator patterns (4)
- High-Utility episodes (4)
- Generator itemsets (4)
- Cost-efficient Sequential patterns (3)
- Skyline High-utility itemsets (3)
- Frequent sequential generators (3)
- Frequent subgraphs (3)
- Frequent itemsets with multiple thresholds (3)
- Local Periodic frequent itemsets (3)
- Correlated patterns (3)
- Quantitative high utility itemsets (3)
- Maximal patterns (2)
- Cross-Level High-utility itemsets (2)
- Multi-dimensional frequent closed sequential patterns (2)
- Maximal itemsets (2)
- High-utility probability sequential patterns (2)
- Frequent maximal sequential patterns (2)
- Density-based clusters (2)
- Periodic frequent itemsets common to multiple sequences (2)
- On-shelf high-utility itemsets (2)
- Multi-dimensional frequent closed sequential patterns with timestamps (2)
- Top-k frequent sequential rules (2)
- Frequent maximal itemsets (2)
- Frequent closed and generator itemsets (2)
- Closed association rules (2)
- Frequent time interval sequential patterns (2)
- Perfectly rare itemsets (2)
- Sequence Database with timestamps (2)
- Top-k frequent sequential patterns (2)
- Top-k High-Utility episodes (2)
- Transaction database with utility values (2)
- Closed and generator patterns (2)
- Periodic high-utility itemsets (2)
- Minimal rare itemsets (2)
- Trend patterns (2)
- Correlated High-utility itemsets (2)
- Generator high-utility itemsets (2)
- Association rules with lift and multiple support thresholds (2)
- Rare correlated itemsets common to multiple sequences (1)
- Productive Periodic frequent itemsets (1)
- Peak high-utility itemsets (1)
- Indirect association rules (1)
- Top-k non-redundant association rules (1)
- Top-k class association rules (1)
- Database of double vectors (1)
- Uncertain frequent itemsets (1)
- Non-redundant Periodic frequent itemsets (1)
- Transaction database with utility values and time (1)
- Top-k Stable Periodic frequent itemsets (1)
- Rare correlated itemsets (1)
- Frequent sequential rules with strings (1)
- Top-k frequent episodes (1)
- Minimal itemsets (1)
- High-utility association rules (1)
- Uncertain patterns (1)
- Ordered frequent sequential rules (1)
- Top-k association rules (1)
- High-utility itemsets with length constraints (1)
- High-utility generator itemsets (1)
- Multi-dimensional frequent sequential patterns with timestamps (1)
- Local high-utility itemsets (1)
- High-utility sequential rules (1)
- Periodic frequent itemsets (1)
- Density-based cluster ordering of points (1)
- Frequent sequential patterns with occurrences (1)
- Frequent sequential patterns with timestamps (1)
- Frequent closed sequential patterns with timestamps (1)
- Minimal high-utility itemsets (1)
- Significant Trend Sequences (1)
- Frequent fuzzy itemsets (1)
- Periodic rare patterns (1)
- Top-k Frequent subgraphs (1)
- Minimal patterns (1)
- Stable Periodic frequent itemsets (1)
- Maximal high-utility itemsets (1)
- Self-Sufficient Itemsets (1)
- Text clusters (1)
- Multi-dimensional frequent sequential patterns (1)
- Top-k frequent non-redundant sequential rules (1)
- Cost transaction database (1)
- Hierarchical clusters (1)
- Top-k frequent sequential patterns with leverage (1)
- Compressing sequential patterns (1)
- Minimal non-redundant association rules (1)
- Sporadic association rules (1)
- High-utility rules (1)
- Locally trending high-utility itemsets (1)
- Skyline Frequent High-utility itemsets (1)
- High-utility sequential patterns (1)
- Progressive Frequent Sequential patterns (1)
- Erasable itemsets (1)
- Attribute Evolution Rules (1)
- Generators of high-utility itemsets (1)
- Multiple Frequent fuzzy itemsets (1)
- Correlated itemsets (1)
- Multi-Level High-utility itemsets (1)
- Association rules with lift (1)
- Top-k sequential patterns with quantile-based cohesion (1)
- Erasable patterns (1)
- Frequent generator itemsets (1)
- Frequent high-utility itemsets (1)
Conclusion
Hope that this is interesting 🙂 If you have any comments, please leave them below.