Today, I attended the EITCE 2021 conference, which was held in Xiamen, China from the 22nd to 24th October 2021. The conference was held virtually and I participated as an invited keynote speaker. In this blog post, I will talk about the confernce.
About the conference
This is the 5th International Conference on Electronic Information Technology and Computer Engineering (EITCE 2021). It is a conference focused on computer science, that has been held in different cities in China such as Xiamen, Shanghai and Zhuhai.
The proceedings are published by ACM, and all papers are indexed by EI Compendex.
The conference was well organized, in part by a company called GSRA, and professors from Jimei University and Shanghai University of Engineering Science.
The website of the EITCE conference is : http://eitce.org/
Schedule of the first day
On the first day, there was five keynote speeches followed by paper presentations.
The first keynote was by Prof. Sun-Yuan Kung from Princeton University (USA) and was about deep learning, and in particular neural architecture search (NAS). He discussed techniques to search for a good neural network architecture using reinforcement learning or other techniques.
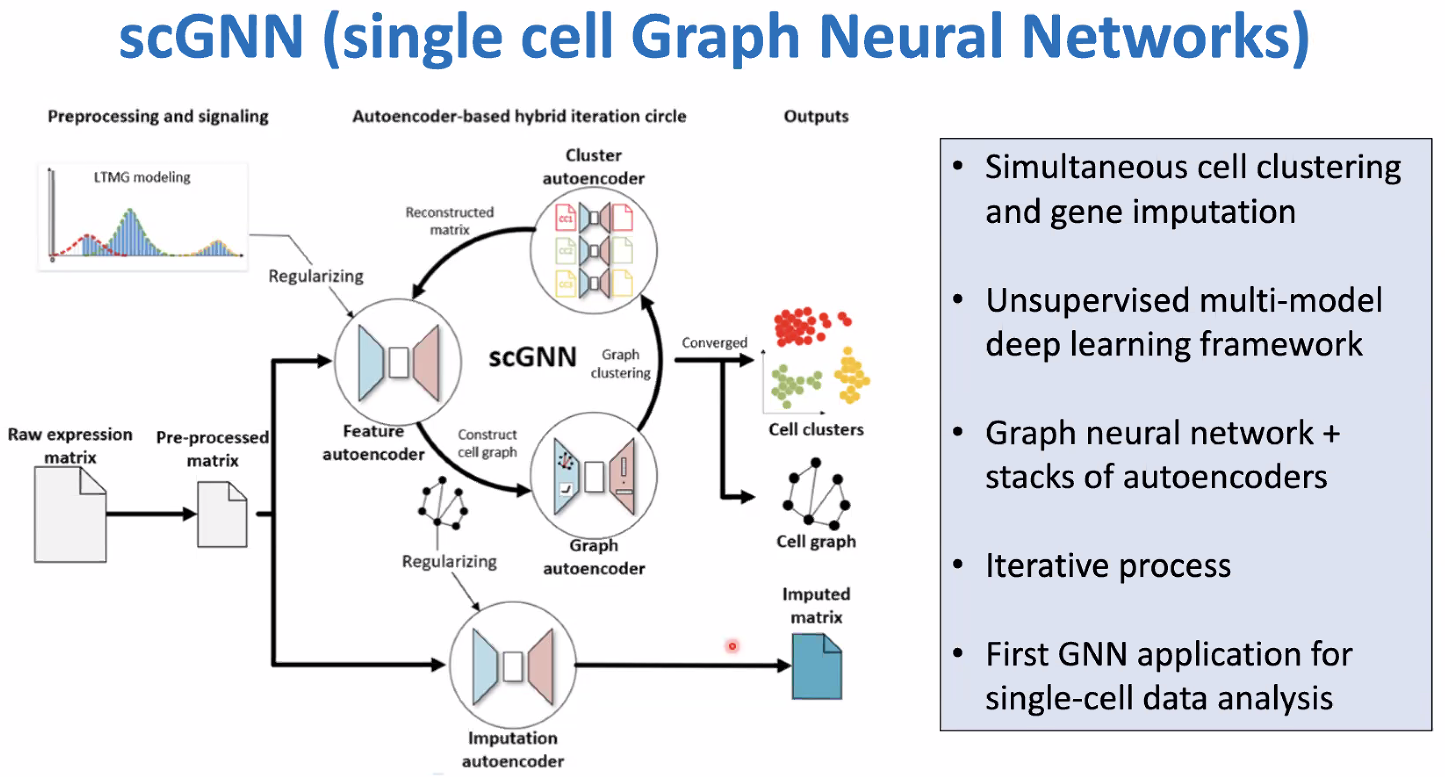
The second keynote speaker was Prof. Dong Xu, from University of Missouri. It was about using graph neural networks for single cell analysis. This talk was more about bioinformatics, which is a bit far from what I do, but was interesting as an application of machine learning.
The third keynote speaker was Prof. Yuping Wang fromTulane University, USA. The talk was about Interpretable multimodal deep learning for brain imaging and genomics data fusion. A highlight of this talk was to say that interpretability is a challenge but is also very important for research on neural networks applied to real applications.
Then, there was my keynote (Prof. Philippe Fournier-Viger) about discovering interesting patterns in data using pattern mining algorithms.
The fifth keynote was by Prof. Yulong Bai.
Conclusion
That was an interesting conference, and I was happy to participate to it.
— Philippe Fournier-Viger is a distinguished professor working in China and founder of the SPMFopen source data mining software.
PMDB 2022 aims at providing a place for researchers from the fields of machine learning, pattern mining and database to present and exchange ideas about how to adapt and develop techniques to process and analyze big complex data.
The scope of PMDB 2022 encompasses many topics that revolves around database technology, machine learning, data mining and pattern mining. These topics include but are not limited to:
Artificial intelligence, machine learning and pattern mining models for analyzing big complex data
Database engines for storing and querying big complex data
Distributed database systems
Data models and query languages
Distributed and parallel algorithms
Real-time processing of big data
Nature-inspired and metaheuristic algorithms
Multimedia data, spatial data, biomedical data, and text
Unstructured, semi-structured and heterogeneous data
Temporal data and streaming data
Graph data and multi-view data
Uncertain, fuzzy and approximate data
Visualization and evaluation of big complex data
Predictive models for big complex data
Privacy-preservation and security issues for big complex data
Explainable models for big complex data
Interactive data analysis
Open-source software and platforms
Applications in domains such as finance, healthcare, e-commerce, sport and social media
The deadline for submiting papers is the 30th November 2021.
All accepted papers of PMDB 2022 will be published in Springer LNCS together with other DASFAA workshops. This will ensure good indexing in DBLP etc.
Hope to see your papers!
— Philippe Fournier-Viger is a distinguished professor working in China and founder of the SPMFopen source data mining software.
Today, I will talk about something that I like very much, which is travelling. Being a researcher has allowed me to travel to numerous places around the world that I may not have discovered otherwise. In fact, I have attended many conferences around the world since I was a gradudate student and also visited many research labs, and gave invited talks in many locations. Besides, I have also travelled to many places as a tourist.
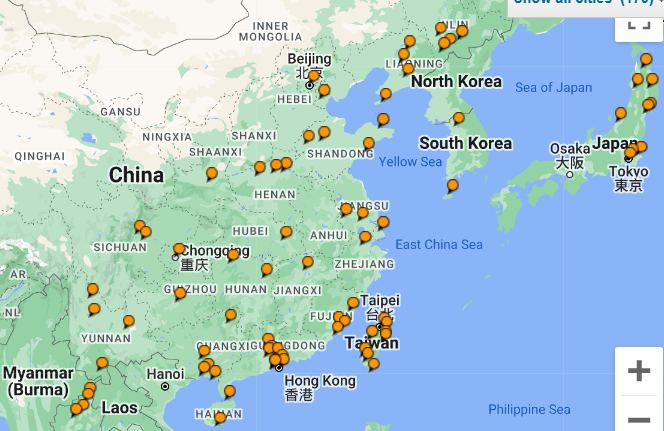
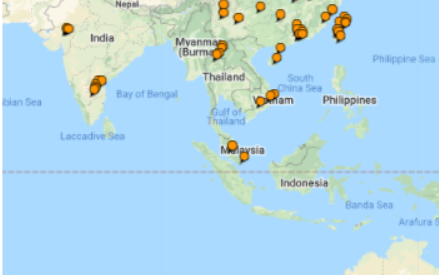
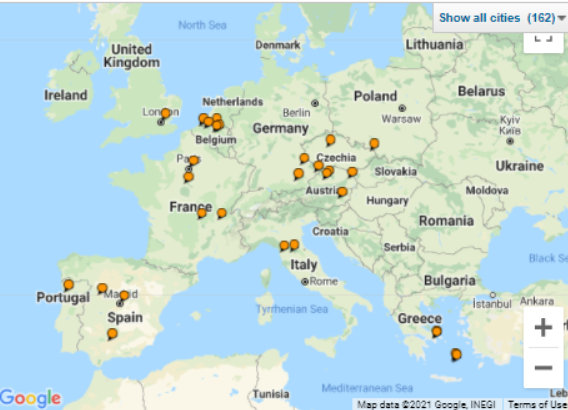
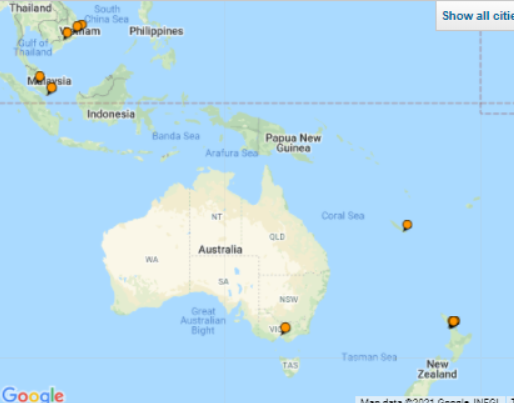
Totally, I have visited 25 countries. And in China, I have visited four territories that belong to China (mainland China, Taiwan, Hong Kong and Macau). Those 25 countries (including 4 territories of China) are pictured below:
And for more details, here are some of the cities that I have visited (the Map is generated by TripAdvisor, which allows users to create a map of visited cities).
As it can be seen, I particularly like Asia and Europe.
This is just a short blog post, to talk a little about something different. I miss very much travelling internationally due to the pandemic. But in the mean time, I have been travelling to several places around China, which is also very interesting for me, as it is a big country with many different things to see. I am looking forward to start travelling internationally again as there are still so many places to see around the world. Do you also like to travel? You may let me know in the comment section below
— Philippe Fournier-Viger is a distinguished professor working in China and founder of the SPMFopen source data mining software.
Today, I will talk a little bit about the recent improvements and future direction for the SPMFdata mining library.
How SPMF started?
SPMF is a software project that I started around 2008 when I was a Ph.D student in Montreal, Canada. The short story of that software is as follows. I was taking a Ph.D course on data mining at University of Quebec at Montreal. For that course, I had to implement a few data mining algorithms as homework. I implemented some simple algorithms in Java such as Apriori and some code for discovering association rules. Then, I decided to clean the code, and add more algorithms during my free time, including those made for my PhD research. My idea was to make something for the pattern community in Java. In fact, most of the code that I could see online was written in C++… I wanted to change this so as to use my favorite language, Java. Besides, I wanted to share pattern mining code so that other researchers could save time by not having to implement again the same code. This is why all the code is open-source. Thus, it is around that time, in early 2009 that I created the website for SPMF and put the first version online. That version was simple. The code was not so efficient. Then, over the years the code has been optimized and more algorithms have been added, and luckily many researchers have joined this effort by providing code for many other algorithms such that today there are over 200 algorithms, many not available in other software programs. Besides, many other researchers have reported bugs and provided feedback to improve the software, which has been very useful to make the software very stable and bug-free. It is thanks to all contributors and SPMFusers that the software is what it is today! Thanks!
What is the future?
The SPMF software is still very active. Just in the first eight months of 2021, about 20 algorithms have been added already. But there is many things to do to further improve the software:
I have been working on a plugin system that is not finished but will likely appear in a future version of SPMF when it is stable enough. This will allow to download plugins as jar files from online repositories and integrate them with SPMF. I have some version that is almost working but I want to make sure it is well-tested before it is released.
I also want to integrate some additional tools to automatically run experiments in SPMF to make it more convenient for researchers who want to compare algorithms.
I will eventually redesign the user interface to further improve it with more capabilities. The user interface has always been quite simple as the focus of the software is to provide an extensive library of algorithms. But it is perhaps time to add more functionalities to the user interface such to allow the user to combine several algorithms as a pipeline to process data, and to save that pipeline to a file.
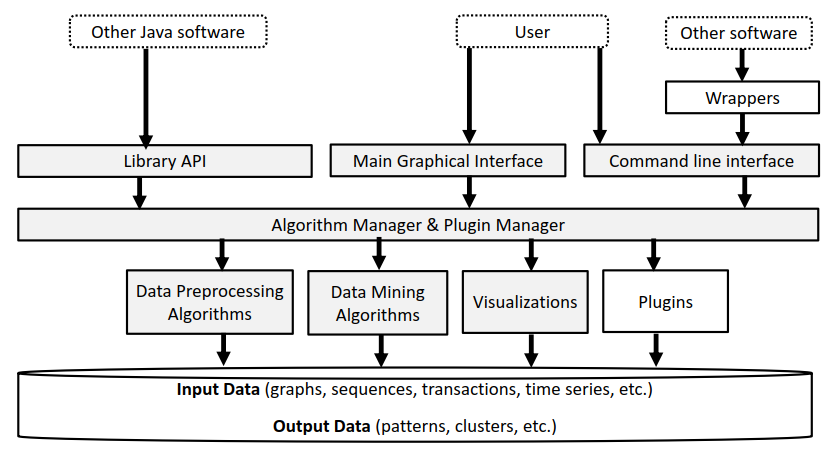
Here is a picture of the system architecture of SPMF, including the planned plugin system:
Next step: SPMF 3.0
It is already a few years that SPMF 2.0 was released. The next major version shall be SPMF 3.0 and hopefully it will be released early in 2022.
For SPMF 3.0, I will also publish a new research paper about SPMF. For the version 0.9, a paper on SPMF was published in the Journal of Machine Learning Research. For the version 2.0, I published a paper in PKDD 2016. For version 3.0, I will also make a paper for another top journal or conference. The people who have contributed the most to SPMF in recent years will be invited to co-author that paper (as much as possible due to limitations on the number of authors).
For those who have observed, the convention for numbering versions of SPMF have changed quite a lot over the years. At the beginning, I started at 0.49, and incremented the numbers by 0.01. But I did not want to reach version 1.0 too early, so I then started to add letters like 0.96b, 0.96c,… 0.96r and then even some numbers after that like 0.96r2, 0.96r3, 0.96r4 to stay away longer from 1.0. The last version before 1.0 was 0.99j. Then after that I jumped to version 2.0 for the PKDD paper, and now I continued as 2.01, 2.02… 2.50. The next jump will be to 3.0 in the next few months.
Conclusion
In this blog post, I have talked a little bit about the early development and future direction of SPMF. Hope it has been interesting!
Thanks again to all contributors and users of SPMF for supporting the software through all these years. I really appreciate your support.
— Philippe Fournier-Viger is a distinguished professor of computer science and founder of the SPMF open-source data mining library, which offers over 200 algorithms for pattern mining.
In this blog post, I will talk about the DEXA 2021 and DAWAK 2021 conferences that I have attended, September 27–30, 2021. Those two conferences are co-located and co-organized every year in different countries of Europe. This year, these conferences were held virtually due to the COVID pandemic.
What is DEXA and DAWAK?
DEXA 2021 is the 32nd International Conference on Database and Expert Systems Applications. It is a conference oriented towards database technology and expert systems, but that also accepts data mining papers.
DAWAK 2021 is the 23rd International Conference on Big Data Analytics and Knowledge Discovery. The focus is similar to DEXA but more oriented towards data mining and machine learning. Several years ago, the DAWAK conference was named “Data Warehousing and Knowledge Discovery, hence DAWAK). But the name has changed in recent years.
The proceedings of DEXA and DAWAK are both published by Springer in the LNAI series, which ensures good visibility and indexing in EI, DBLP and other popular publication databases. The DEXA conference is older and viewed as a better conference than DAWAK by some researchers (e.g. in China, DEXA is ranked higher than DAWAK by the Chinese Computer Federation).
Personally, I enjoy the DEXA and DAWAK conferences. There are not so big but the paper are overall of good quality. Also, there is often some special journal issues associated with these conferences. I have previously attended these conferences several times. My report about previous editions can be found here: DEXA and DAWAK 2016, DEXA and DAWAK 2018, and DEXA and DAWAK 2019.
Acceptance rate
This year, 71 papers were submitted to DaWaK 2021. 12 papers were accepted as full papers and 15 as short papers. Thus, 16% is the acceptance rate for the full papers and 35% for both full and short papers.
The best papers of DAWAK were invited to submit an extended version in a special issue of the Data & Knowledge Engineering (DKE) journal.
For DEXA, I did not see the information about the number of submission in the front matter of the Springer proceedings. Usually this information is provided for conferences published by Springer. But this time, it is just said that “the number of submissions was similar to those of the past few years” and that “the acceptance rate this year was 27%“. To estimate the number of submissions, I counted that there is about 67 papers in the proceedings. Thus, the number of submissions would be about 67 / 27 * 100 = 248 submissions. Thus, this would be a 25% increase from last year, since in 2020, there was 197 submissions, in 2019, there was 157 submissions, and in 2018, there was 160 submissions.
Opening
On the first day, there was the opening session.
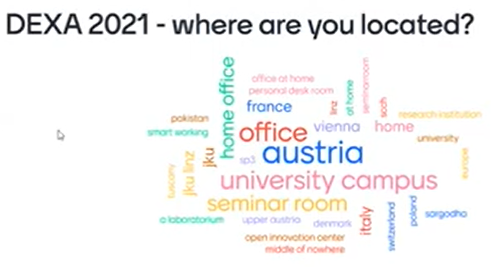
The program of the conference was presented, as well as the different organizers. It was said that this year there is a panel and five keynote speakers. Attendees were also asked to scan a QR during the opening to indicate their location, which generated the following word cloud:
Paper presentations
The paper presentations were done online using the Zoom software. There was a lot of interesting topics. Here is a screenshot of the first paper session on big data from DEXA 2021:
I presented the paper of my student about episode rules. During that session, there about a dozen people and there was some interesting questions. Due to the schedule and time different, I was not able to attend all the paper presentations that I wished to attend, but I saw some interesting work.
Papers about pattern mining
This year, again, there was several papers about pattern mining at DEXA and DAWAK. Since it is one of my research area, I will report about these papers:
P. Revanth Rathan, P. Krishna Reddy, Anirban Mondal: Improving Billboard Advertising Revenue Using Transactional Modeling and Pattern Mining. 112-118
Yinqiao Li, Lizhen Wang, Peizhong Yang, Junyi Li: EHUCM: An Efficient Algorithm for Mining High Utility Co-location Patterns from Spatial Datasets with Feature-specific Utilities. 185-191
Xin Wang, Liang Tang, Yong Liu, Huayi Zhan, Xuanzhe Feng: Diversified Pattern Mining on Large Graphs. 171-184
So Nakamura, R. Uday Kiran, Likhitha Palla, Penugonda Ravikumar, Yutaka Watanobe, Minh-Son Dao, Koji Zettsu, Masashi Toyoda: Efficient Discovery of Partial Periodic-Frequent Patterns in Temporal Databases. 221-227
Amel Hidouri, Saïd Jabbour, Badran Raddaoui, Mouna Chebbah, Boutheina Ben Yaghlane: A Declarative Framework for Mining Top-k High Utility Itemsets. 250-256
Conclusion
On overall, it was a good conference. It is not so big but well-organized and with some good papers. I will certainly continue to send papers to that conference in the following years, and hopefully I can attend that conference in person next time. That would be much more interesting than a virtual conference because one of the best part about academic conferences is to be able to meet people and talk face to face.
— Philippe Fournier-Viger is a distinguished professor of computer science and founder of the SPMF open-source data mining library, which offers over 200 algorithms for pattern mining.
Today, I will talk about pattern mining. I will explain a topic that is in my opinion very important but has been largely overlooked by the research community working on high utility itemset mining. It is to integrate length constraints in high utility itemset mining. The goal is to find patterns that have a maximum size, defined by the user (e.g. no more than two items).
Why do this? There are two very important reasons.
First, from a practical perspective, it is often unnecessary to find the very long patterns. For example, let’s say that we analyze shopping data and find that a high utility pattern is that people buy {mapleSyrup, pancake, orange, cheese, cereal} together and that this yield a high profit. This may sound like an interesting discovery, but from a business perspective, it is not useful as this pattern contain too many items. For example, it would not be easy for a business to do marketing to promote buying 5 items together. This has been confirmed in my discussion with a business in real-life. I was told by someone working for a company that they are not interested in patterns with more than 2 or 3 items.
Second, finding the very long patterns is inefficient due to the very large search space. They are generally too many possible combinations of items. If we add a constraint on the length of patterns to be found, then we could save a huge amount of time to focus on the small patterns that are often more interesting for the user.
Based on these motivations, some algorithms like FHM+ and MinFHM have focused on finding the small patterns that have a high utility using two different approaches. In this blog post, I will give a brief introduction to the ideas from those algorithms, which could be integrated in other pattern mining problems.
First, I will give a brief introduction about high utility itemset mining for those who are not so familiar with this topic and then I will explain the solutions to find short patterns that are proposed in those algorithms.
High utility itemset mining
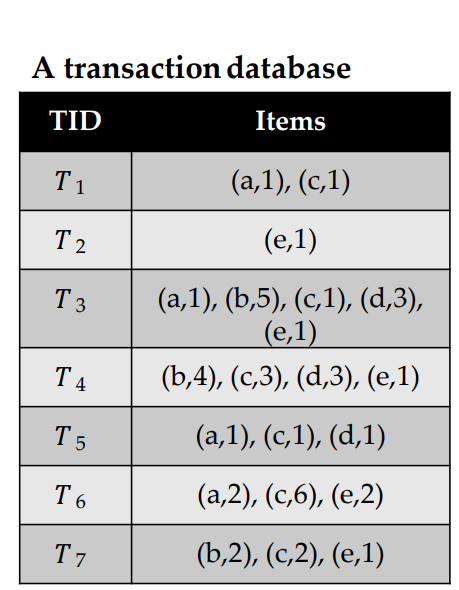
High utility itemset mining is a data mining task that aim at finding patterns in a database that have a high importance. The importance of a pattern is measured using a utility function. There can be many applications of high utility itemset mining, but the classical example is to find the sets of products purchased together by customers in a store that yield a high profit (utility). In that setting, the input is a transaction database, that is a set of records (transactions) indicating the items that some customers have bought at different times. For example, consider the following transaction database, which contains seven transactions called T1, T2, T3… T5:
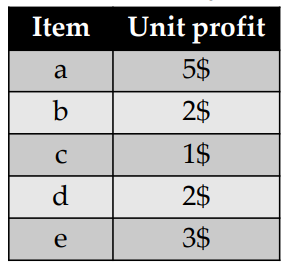
The second transaction T2 indicates that a customer has bought 4 units of an item “b” which stands for Bread and 3 units of an item “c”, which stands for Cake, 3 units of an item “d” which stands for Dates, and 1 unit of an item “e”, which stands for “Egg”. The second transaction contains 1 unit of an item “a”, denoting “Apple”, 1 cake and 1 unit of Dates. Besides, that table, another table is provided indicating the relative importance of each item. In this example, that table indicate the unit profit of each item (how much money is earned by the sale of 1 unit):
This table for example indicates that the sale of 1 Apple yields a 5$ profit, the sale of 1 bread yields 2$ profit, and so on.
To do the task of high utility itemset mining, the user must set a threshold called the minimum utility threshold (minutil). The goal is to find all the itemsets (sets of items) that have a utility (profit) that is no less than that threshold. For example, if the user set the threshold as minutil = 33$, there are four high utility itemsets:
The first itemset {b,d,e} means that customers buying Bread, Dates and Eggs together yield a total utility (profit) of 36$ in this database. It is a high utility itemset because 36$ is no less than minutil = 33$. But how do we calculate the utility of an itemset in a database? It is not very complicated. Let me show you. Let’s say that we take the itemset {b,d,e} as example. These items are purchased together in the transactions T1 and T2 of the database, which are highlighted below:
To calculate the utility of {b,d,e}, we need to multiply the quantities associated with b,d,e in T1 and T2 by their unit profit. This is done as follow:
In T1, we have: (5 x 2) + (3 x 2) + (1 x 3) = 19 $ because the customer bought 5 breads for 2$ each, 3 dates for 2 $ each and 1 egg for 1 $.
In T2, we have (4 x 2) + (3 x 2) + (1 x 3) = 17 $ because the customer bought 5 breads for 2$ each, 3 dates for 2 $ each and 1 egg for 1 $.
Thus, the total profit of {b,d,e} for T1 and T2 is 19$ + 17 $ = 36 $.
The problem of high utility itemset mining has been widely studied in the last two decades. Besides the example of shopping above, it can be applied to many other problems as the letters like a,b,c,d,e could represent for example webpages or words in a text. There has been many efficient algorithms that have been designed for high utility itemset mining such as IHUP, UP-Growth, HUI-Miner*, FHM, EFIM, ULB-Miner and REX to name a few. If you are interested by this topic, I wrote a good survey that introduce the problemin more details and it is easy to understand for beginners in this field.
Finding the Minimal High Utility Itemsets with MinFHM
As I said in the introduction, a problem with high utility itemset mining is that many high utility itemsets are very long and thus not useful in practice. This leads to finding too many patterns and to very long runtimes.
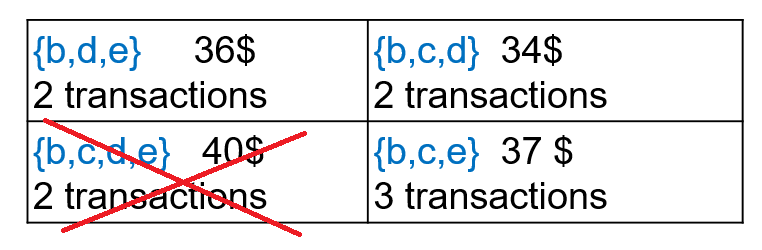
The first solution to this problem was proposed in the MinFHM algorithm. It is to find the minimal high utility itemsets. A minimal high utility itemset is simply a high utility itemset that is not a subset of a larger high utility itemset. This definition allows to focus on the smallest sets of items that yield a high utility (e.g. profit in this example). For example, if we take the same database and minutil = 33$, there are only threeminimal high utility itemsets:
The itemset {b,c,d,e} is not a minimal high utility itemsets because it has subsets such as {b,d,e} that are high utility itemsets.
To find the minimal high utility itemsets, MinFHM is a modified version of the FHM algorithm. It relies on search space reduction techniques that are specially designed to find the minimal high utility itemsets. This led to not only finding less patterns than FHM but also on having much faster runtimes. On some benchmark datasets, MinFHM was for example up to 800 times faster than FHM and could find up to 900,000 times less patterns.
For researchers, something interesting about the problem of minimal high utility itemsets is the following two properties, which are somewhat special for this problem:
I will not talk too much about the details of this as my goal is just to give some introduction. For more details about MinFHM, you can see the paper, powerpoint, video presentation and source code, below:
Fournier-Viger, P., Lin, C.W., Wu, C.-W., Tseng, V. S., Faghihi, U. (2016). Mining Minimal High-Utility Itemsets. Proc. 27th International Conference on Database and Expert Systems Applications (DEXA 2016). Springer, LNCS, pp. 88-101. [ppt][source code]
DOI: 10.1007/978-3-319-44403-1_6
Finding the High Utility Itemsets with a length constraint with FHM+
Now, let me talk about another solution to find the short high utility itemsets. This solution consists of simply adding a new parameter that sets a maximum length on the patterns to be found. For example, if take the same example and say that minutil = 33$ and the maximum length is 3, then the following three high utility itemsets are found:
In this example, the results is the same as the minimal high utility itemsets but it is not always the case.
To find the high utility itemsets with a length constraint, a naïve solution is to filter out the high utility itemsets that are too long as a post-processing step after applying a traditional high utility itemset mining algorithm such as FHM. However, that would not be efficient. For this reason, I have proposed the FHM+ algorithm in previous work. It is a modified version of FHM. The key idea is as follows. The FHM algorithm just like other high utility itemset mining algorithms uses upper bounds on the utility to reduce the search space such as the TWU and remaining utility (which I will not explain here). These upper bounds are defined by assuming that all items of a transaction could be used to create high utility itemsets. But if we have a length constraints and know that lets say we don’t want to find patterns with more than 3 items, then we can greatly reduce these upper bounds. This allows to reduce a much larger part of the search space and thus to have a much faster algorithm!
In the FHM+ paper, I have shown that using these ideas, the memory usage can be reduced by up to 50%, the speed can be increased by up to 4 times and up to 2700 times less patterns can be discovered, on benchmark datasets!
This is just a brief introduction, and these ideas could be used in other pattern mining problems. For more details, you may see the paper, powerpoint presentation and code below:
In this blog post, I have explained why it is unnecessary to find the very long patterns in high utility itemset mining for some applications such as analyzing customer behavior. I have also shown that if we focus on short patterns, we can greatly improve the runtimes and also reduce the number of patterns shown to the user. This can bring the algorithms for high utility itemset mining closer to what users really need in real-life. I have discussed two solutions to find short patterns, which are to find minimal high utility itemsets and using a length constraint.
That is all for today!
— Philippe Fournier-Viger is a distinguished professor of computer science and founder of the SPMF open-source data mining library, which offers over 200 algorithms for pattern mining.
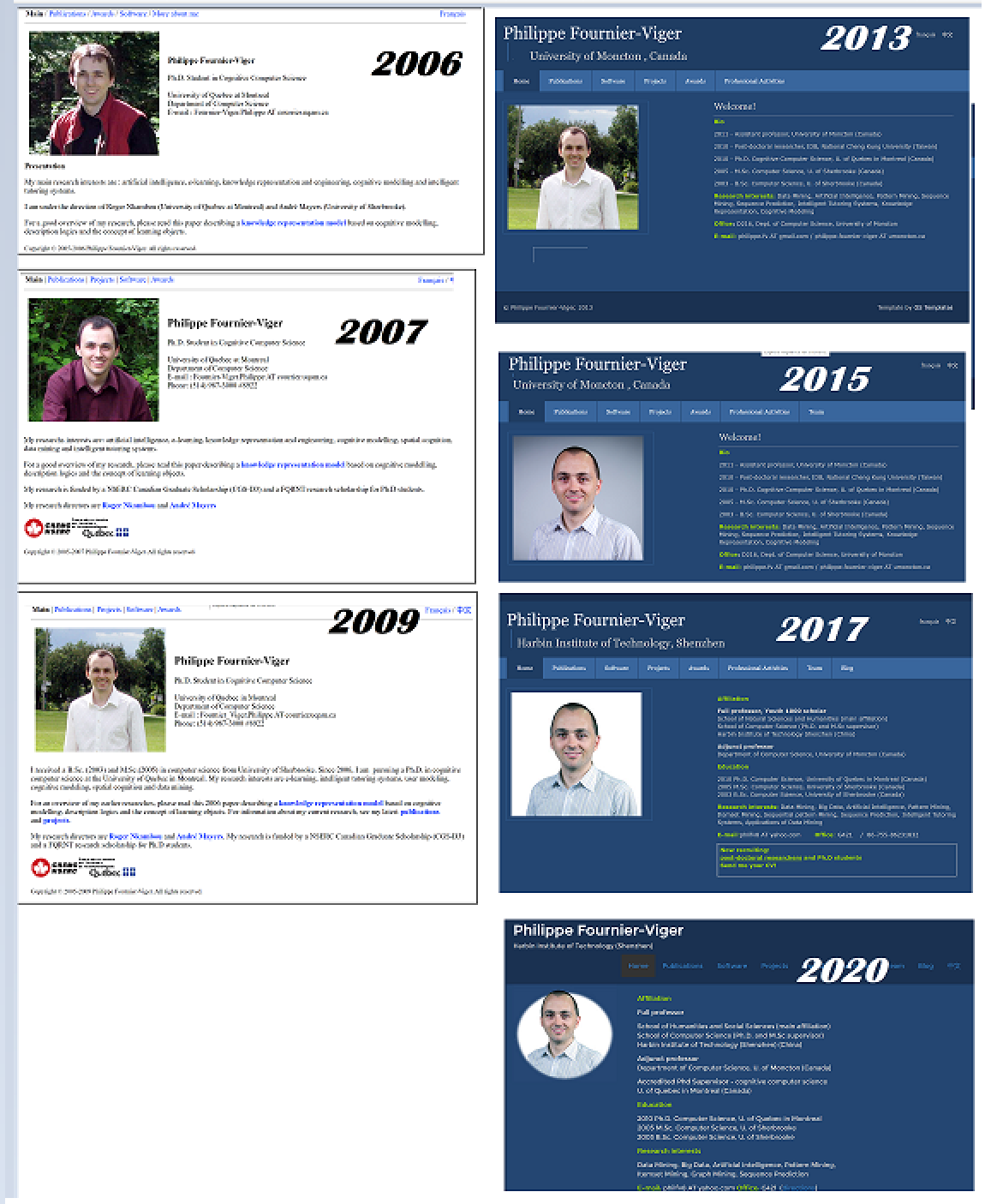
Today, I will talk about the design of my personal research webpage, which has evolved over the years from 2006 (the first year of my PhD) til today (2021). It is around 2006 that I decided to buy a .com domain name to make a webpage. My goal at that time was to have a Web presence so that people could easily find the PDFs of my research papers and also read about my research. The design of my webpage did not change so much over the years, as you can see below:
On the top left, it is the first version of my webpage, with a white background. That webpage was HTML 4 compliant and had a few subsections like “Main”, “Publications”, “Software” and “About me”. From 2006 to 2009, I made minor changes to the website, mainly to update my list of papers, change my picture (a few times) and add some other information. Then, around 2012, a student from Algeria, Hanane Amirat, gently offered to redesign my website, with a colored background as can be seen on the top right, which made it look better. At that time, I was also starting to work as professor and added more sections to my website, including a link to this blog. Then, around 2020, I redesigned the website again to make the site suitable for mobile devices, as search engines started to take this into account. This version can be seen at the bottom left. That version from 2020 looks almost the same as the 2017 version but under the hood, I have modified the website to use a responsive design template so that the menu can be dynamically resized on mobile devices.
Do you like the latest version of the website? If not, or if you have some suggestions to improve it, please leave a comment below 🙂 Maybe it is time to change the design again 🙂 In fact, I feel that the website colors are a little bit dark. Maybe it would be time to change to another design…
That is all I wanted to share today. If you are a researcher and do not have a website yet, I recommend to make one , or at least to have a page on websites such as ResearchGate and LinkedIn. This will bring more visibility to your research work!
— Philippe Fournier-Viger is a distinguished professor working in China and founder of the SPMFopen source data mining software.
There are two post-doc positions that are now OPEN in my research team in Shenzhen, China.
=== Topic ===
data mining or ML algorithms for processing graphs, sequences, streams or other complex data, pattern mining
=== Benefits =====
Very good salary
work in an excellent research team and top university
2 years contract
=== Requirements ===
have published papers in good journals or conferences during your Ph.D. as main author (papers in unknown journals from unknown or predatory publishers does not count)
be less than 35 years old (requirement of the university – I have no control over this)
be very motivated, and able to produce high quality papers
if you are not in China already, you must be in a country where a visa can be obtained for China === How to apply? ===
Send me an e-mail with your CV to philfv AT szu.edu.cn. Make sure that your CV includes your age and the list of your publications.
Tell me when you would be ready to start, and other relevant information
If you know someone who might be interested, please share! Thanks!
In this blog post, I will talk briefly about the ECML PKDD 2021 conference that I have attended virtually this week, from the 13th to the 17th of September 2021..
What is ECML PKDD?
ECML PKDD is an european conference about machine learning and data mining. This is year is the 24th edition of that conference. PKDD is viewed as a quite good conference in the field of data mining.
It is not the first time that I attend PKDD. I previously wrote some report about ECML PKDD2020 .
The PKDD 2021 program
Researchers could submit their research papers to two main tracks : the research track and the applied data science track. For these two tracks, 685 and 220 submissions were received, and 146 (21%) and 64 (29%) of the papers were accepted, respectively. Thus, it is slightly easier to get accepted in the applied data science track.
Besides these two tracks, 40 papers were accepted as part of a journal track. The journal track is something special that not all conferences have. How it works? Someone can submit a paper to either the Machine Learning journal or the Data Mining and Knowledge Discovery journal and be accepted at the same time for presenting the work at the PKDD conference.
The PKDD proceedings of regular papers is published by Springer in the LNCS series:
For the workshops, there was no official proceedings. Thus, several workshop organizers (including the MLiSE workshop that I co-organize), have teamed-up to organize a separate workshop proceedings that will appear after the conference, and will be published by Springer. Other workshops may have chosen to publish their proceedings in other ways.
An online conference
Due to the coronavirus pandemic, the conference was held online using a conference system called Whova. The website/app is quite convenient to use. It allows to see the schedule of the conference and recorded videos of the talk could be watched at a later moment. There is also some function to search for attendees based on location and similar interests, which is interesting. It allowed me to find some other researchers in my city.
Opening ceremony
The opening ceremony gave more details about the conference.
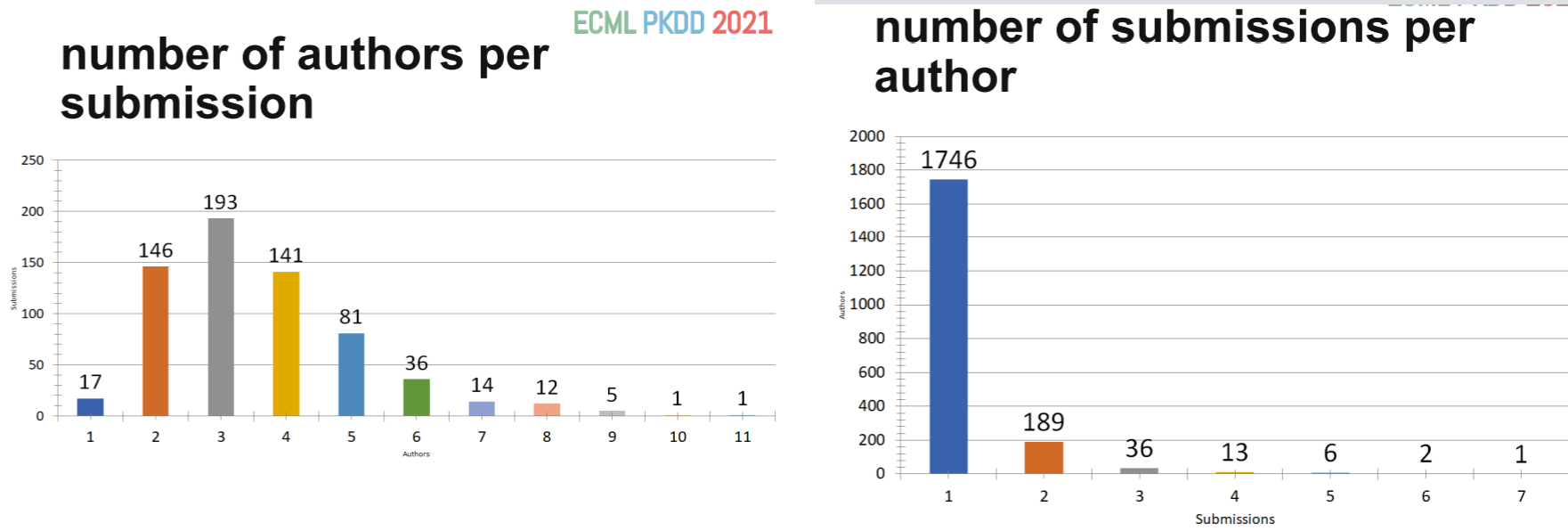
For the research track, it was said that this year, there was 384 program committee members to select papers, and 68 area chairs. On average, most papers had 3 reviews or more, with some having up to 5 reviews.
Some stats about the Research track:
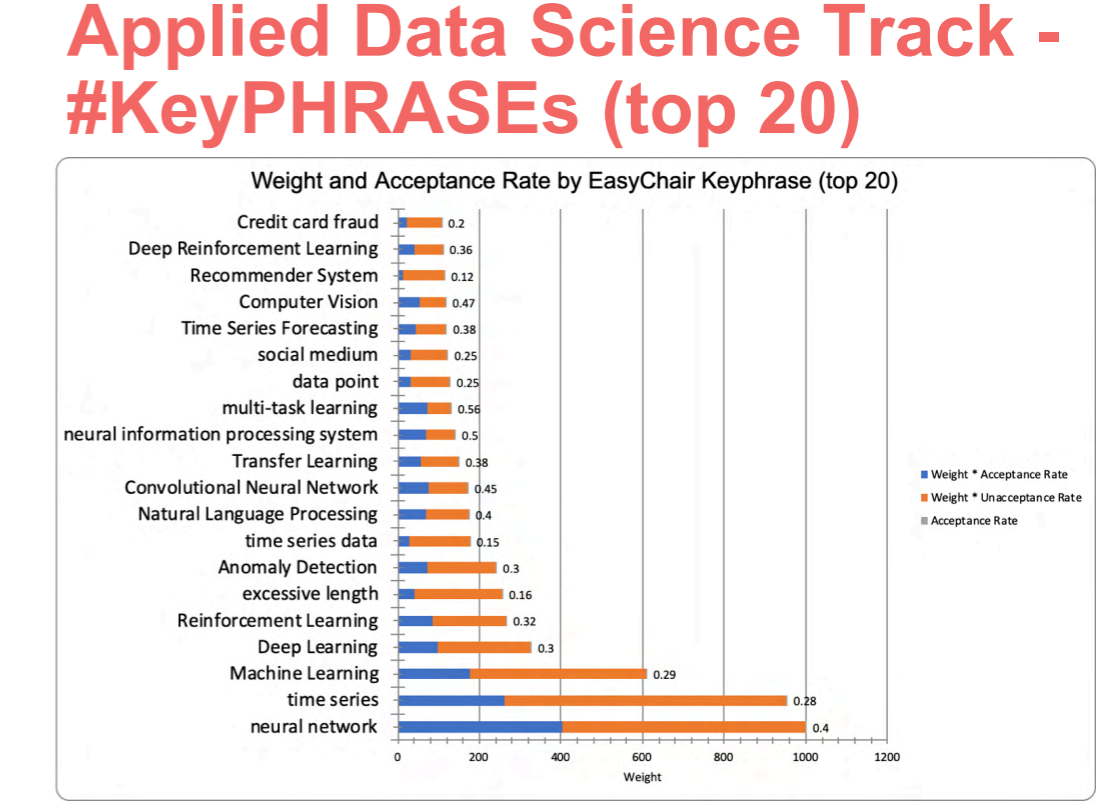
The most popular keywords of the research track:
For the Applied data science track, there was 233 program committee members and each paper was reviewed by 3 to 5 reviewers. The key phrases from the applied data science track are:
Some other stats from the applied data science track:
Some slides about the journal track, including the number of accepted papers and submitted papers:
Some slides about the workshop topics:
Best paper award
Several awards were announced. Mainly, the best paper award went to:
Reparameterized Sampling for Generative Adversarial Networks, by Yifei Wang, Yisen Wang, Jiansheng Yang and Zhouchen Lin
Workshop on Machine Learning on Software Engineering (MLiSE 2021)
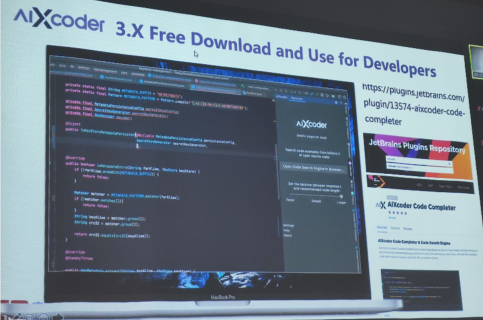
We had an excellent keynote talk by Prof. Zhi Jin from Peking University, who talked about using deep learning for software engineering. Some models were discussed for tasks such as code completion and code clone detection. A free tool called AIXCoder was also presented to support software developpers using AI.
There was also a second excellent keynote by Prof. Atif Mashkoor from Johannes Kepler University Austria
With two keynotes, seven papers, and many attendees, the MLiSE workshop was a success. We will thus try to organize it again at ECML PKDD next year!
Conclusion
That is all about the conference. I could have written more but this week was very busy. I could not attend all the events.
— Philippe Fournier-Viger is a full professor working in China and founder of the SPMFopen source data mining software.
Today, I will talk about pattern mining, a subfield of data science that aims at finding interesting patterns in data. More precisely, I will briefly describe a popular data mining task named high utility itemset mining. Then, I will describe a limitation of this task, which is the lack of information about quantities in the discovered patterns, and an extension that address this issue, called high utility quantitative itemset mining.
High Utility Itemset Mining
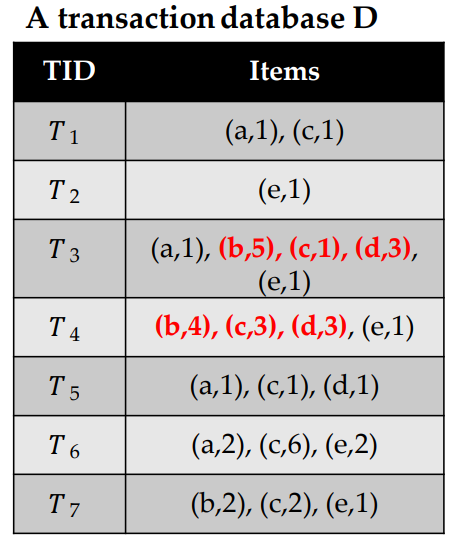
High utility itemset mining is a data mining task, which consists of finding patterns that have a high utility (importance) in a dataset, where the utility is measured using a function. There are various applications of this task, but the most representative one is to analyze customer transactions to find sets of products that people like to purchase together and yield a high profit. I will thus briefly explain what is high utility itemset mining for this application. In that context, the input is a transaction dataset, as illustrated in the table, below.
This dataset contains seven records called T1, T2, T3, T4, T5, T6, T7. Each record is a transaction, indicating what items (products) a customer has purchased in a store at a given time. In this example, the products are called “a”, “b”, “c”, “d” and “e”, which stands for apple, bread, cake, dattes and eggs. The first transaction (T1) indicates that a customer has purchased one unit of item “a” (one apple), with one unit of item “c” (one cake). The sixth transaction (T6) indicates that a customer has bought two units of “a” (two apples) with 6 units of “c” (six cakes) and 2 units of “e” (two eggs). Other transactions follow the same format.
Moreover, another table is taken as input, shown below, which indicates the amount of money that is obtained by the sale of each item (the unit profit).
For instance, in that table, it is indicated that selling an apple (item “a”) yields a 5$ profit, while each bread sold (item “b”) yields a 2$ profit.
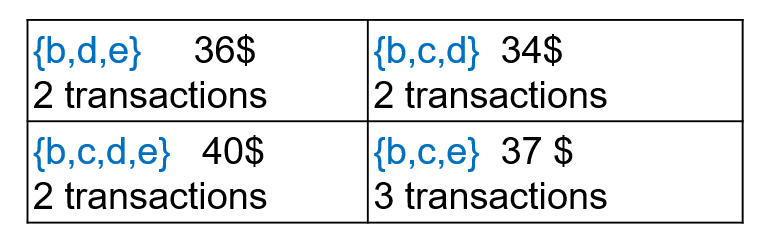
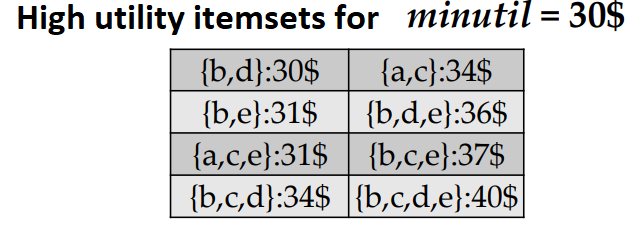
The goal of high utility itemset mining is to find the itemsets (sets of items) that yield a utility (profit) that is greater than or equal to a threshold called the minimum utility (minutil) threshold, set by the user. For instance, if the user sets minutil = 30$, the goal is to find all the sets of items (itemsets) that yield at least 30$ in the above database. Those itemsets are called the high utility itemsets. For this example, there are only 8 high utility itemsets, which are shown below with their utility (profit) in the database.
For instance, the itemset {b,c,d} has a utility of 34$, and it is a high utility itemset because 34$ > minutil = 30 $. But how do we calculate the utility (profit) of an itemset? Let me explain this more clearly.
Let’s take the itemset {b,c,d} as example. To calculate the utility (profit) of {b,c,d}, we first need to find all the transactions that contain {b,c,d} together. There are only two transactions (T3 and T4), highlighted below:
After we have found that, we need to calculate the utility of {b,c,d} in transaction T3 and in transaction T4 and do the sum.
Let’s first look at T3. Here, we have 5 units of “b” which have a unit profit of 2$ with 1 unit of item “c” that has a unit profit of 1$, and 3 units of “d” which has a unit profit of 2$. Thus, the utility of {b,c,d} in T3 is (5 x 2 ) + (1 x 1) + ( 3 x 2) = 17 $.
Now, lets look at T4. Here, we have 4 units of “b” which have a unit profit of 2$ with 3 unit of item “c” that has a unit profit of 1$, and 3 units of “d” which has a unit profit of 2$. Thus, the utility of {b,c,d} in T3 is (4 x 2 ) + (3 x 1) + ( 3 x 2) = 17 $.
Then, we do the sum of the utility of {b,c,d} in T3 and T4 to get its total utility (profit) in the whole database, which is 17$ + 17 $= 34 $.
To find the high utility itemsets in a database, many algorithms have been designed such as FHM, EFIM, HUI-Miner, ULB-Miner and UP-Growth. I have published a good survey on high utility itemset mining, which gives more details about it.
High Utility Quantitative Itemset Mining
The task of high utility itemset mining (HUIM) is useful but there is a major limitation, which is that the discovered high utility itemsets do not provide information about quantities. Thus, even though an itemset like {b,c,d} may be a high utility itemset, it does not indicate how many breads, how many cakes and how many dattes people like to buy together. But of course, buying 1 breads, 5 breads or 10 breads is not the same. Thus, it is important to have this information.
To address this limitation, the task of High Utility Quantitative Itemset Mining (HUQIM) was proposed. In this task, the discovered patterns provide information about quantities.
I will explain this with an example. Consider this database:
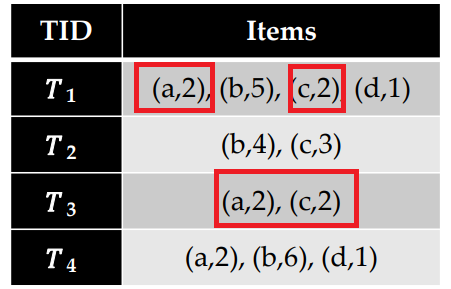
In HUQIM, we may find an itemset with quantities such as {(apple:2), (cake:2)} indicating that some people buy 2 apples with 2 cakes. But how to calculate the utility of this itemset? The utility is calculated as before but by only considering the transactions where a customer has bought 2 apples with 2cakes, that is T1 and T3:
The utility of {(apple:2), (cake:2)} in T1 is: (2 x 3) + (2 x 2), and the utility of that itemset in T3 is (2 x 3) + (2 x 2). Thus the utility of {(apple,2), (cake,2)} in the whole database is the sum of this: (2 x 3) + (2 x 2) + (2 x 3) + (2 x 2) = 20 $.
Such itemset where each item has an exact quantity is called an exact Q-itemset.
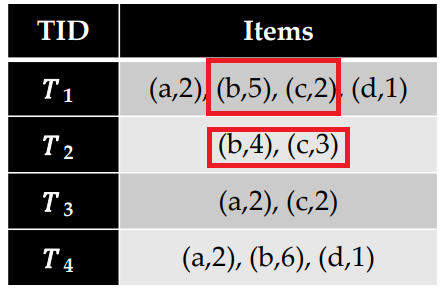
It is also possible to find another type of itemsets called the range Q-itemsets. Explained simply, a range Q-itemset is an itemset where quantities of items are expressed with some intervals. For example, the itemset {(bread,4,5),(cake,2,3)} means that some customer(s) buy 4 to 5 breads with 2 to 3 cakes. To compute the utility of this itemset is also simple. We first need to find all transactions where there are 4 to 5 breads with 2 to 3 cakes and calculate the utility (profit) and then do the sum. The two transactions meeting this criterion are T1 and T2:
Then, we multiply the quantity of bread and cake by their unit profits in these two transactions, which gives : (5 x 1) + (2 x 2) + (4 x 1) + (3 x 2) = 19 $
The problem of high utility quantitative itemset mining is interesting as it provides more information to the user than high utility itemset mining. However, the problem is also much more difficult because for each itemset like {b,c} multiple quantities may be assigned such as {(b,4),(c,3)}, {(b,5),(c,2)}, or even{(b,4,5),(c,3)}, etc. To avoid considering all possibilities, the algorithms for high utility quantitative itemset mining will use different combination methods to combine the quantities into ranges. There are a few combine methods like “combine_all”, “combine_min” and “Combine_max” that can be used. I will not explain them in this blog post to avoid going into too many details. Besides, there is also a parameter called “qrc” that is added to avoid making unecessary combinations.
In the end, the goal of high utility quantitative itemset is to find all the itemset with quantities that have a utility that is not less than the minutil threshold set by the user. I will just show a brief example of input and output:
To find high utility quantitative itemsets, the main algorithms are:
HUQA (2007), proposed in the paper “Mining high utility quantitative association rules”
VHUQI (2014), presented in the paper “Vertical mining of high utility quantitative itemsets”.
HUQI-Miner (2019), introduced in the paper “Efficient mining of high utility quantitative itemsets”
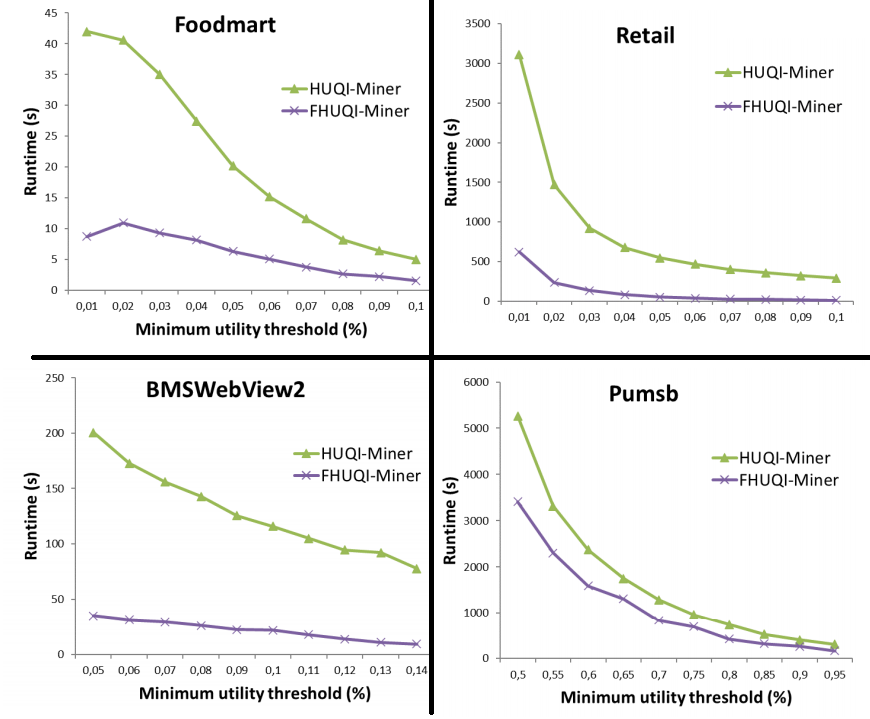
If you are new to this topic, reading the FHUQI-Miner paper is a good start as it is a journal paper that explains clearly all the important definitions with many examples. FHUQI-Miner was also shown to be much faster than the previous best algorithms in experiments, so it is good to start from this algorithm to develop extensions. Below is for example a performance comparison of FHUQI-Miner with the previous best algorithm called HUQI-Miner. It was found that FHUQI-Miner can be up to 20 times faster in some cases.
Also, you may find open-source implementations of several algorithms for HUQIM in the SPMF open-source data mining software, with datasets.
It is also possible to study extensions of the problem of finding high utility quantitative itemsets. For example, here are two recent papers by my team where we extend FHUQI-Miner for variations of the problem:
TKQ (2021) : Finding the top-k high utility quantitative itemsets : The idea is that rather than using the minutil parameter, the user can directly ask to find the k itemsets that yield the highest utility (e.g. the top 100 itemsets)
CHUQI-Miner (2021): This is a recent algorithm to find correlated high utility quantitative itemsets. The motivation is that many itemsets may have a high utility but still be weakly correlated. By using the bond correlation measure, more meaningful itemsets may be found.
Conclusion
In this blog post, I introduced the problem of high utility quantitative itemset mining. Hope it has been interesting. The content of this blog post is based on the articles that I did with Dr. Mourad Nouioua, post-doc in my team, on FHUQI-Miner and his very detailled powerpoint presentation about this algorithm. If you have any comments, please leave it in the comment section below!
— Philippe Fournier-Viger is a full professor working in China and founder of the SPMFopen source data mining software.