The SPP-Growth algorithm and datasets for evaluating its performance are available in the SPMF software, which is open-source and programmed in Java.
Source code and datasets:
The source code of SPP-Growth and datasets are available in the SPMF software.
The research paper:
Fournier-Viger, P., Yang, P., Lin, J. C.-W., Kiran, U. (2019). Discovering Stable Periodic-Frequent Patterns in Transactional Data. Proc. 32nd Intern. Conf. on Industrial, Engineering and Other Applications of Applied Intelligent Systems (IEA AIE 2019), Springer LNAI, pp. 230-244
If you want to watch more videos about data mining algorithms that I have recorded, you can click on the “video” category of this blog.
In this blog post, I will talk about how about to record a research talk on a computer as a video. This is an important topic for researchers for at least two reasons. First, sharing videos talking about your research can help to promote your research. Second, a researcher may be invited to send a video of his talk to a conference if he cannot attend it because of issues such as not obtaining a travel visa. Third, recording a video of a talk is useful as a backup plan when giving a talk online.
The steps to record a presentation as video on a computer are as follows.
Step 1. What kind of presentation do you want to give?
The first step is to decide on the type of presentation that you want to record. The most common types are:
A) Slides with voice-over: A person will record some slides with a voice-over.
B)Videoof a talk: A person will record a video of himself talking without slides.
C)Complex presentation: A person will combine multiple elements such as a presentation with slides, a video of himself, and audio.
D)Virtual whiteboard presentation: A person will do a type of presentation where we will see him writing or drawing live on a virtual whiteboard.
Doing a presentation of type A) or B) is easier than of type C) and D). But a more complex presentation may sometimes appear more interesting.
Step 2.Make sure that you have the right equipment
Recording a presentation can be done using very basic equipment like a cellphone or the microphone and webcam of a laptop computer. However, the quality of built-in webcams and microphones if often poor. To record video presentations, I use:
A professional microphone. I have bought one that is not so expensive and can be plugged by USB, and comes with a tripod (the SAMSON C01UPRO – see below). Using such microphone makes a huge difference in sound quality compared to the built-in microphone of my laptop. Some people will also buy additional accessories for their microphone like a pop filter, and a microphone shock mount. Also, it is important to plug the microphone directly into a USB port of the computer rather than using a USB hub to avoid recording delays.
A good webcam. I have also bought a good webcam (Logitech c922 Pro Stream), which can record in high definition with good colors. A nice feature is that the webcam can also be mounted on a tripod and that it has a free background removal feature that I will talk more about later.
Light. A good lighting source is also important if you are going to record videos of yourself using a camera and want to look good. Some cheap LED lamps or LED panels can for example be purchased and installed on your desk.
The above is perhaps the most important piece of equipments to increase the quality of recorded talks. Other equipment could also be added like tripods, a green screen for shooting videos, good headphones, etc. Here is a picture of my relatively simple setup for recording videos. I use two LED lamps, and an external webcam and microphone.
Step 3. Prepare your presentation
Before recording a talk, it is recommended to prepare your talk well and rehearse it a few times. This is true for any talks so I will not talk about this here.
Step4.Record the video
Depending on the type of presentation that you will make, it will be more or less complicated to record the presentation. I will discuss a few cases below.
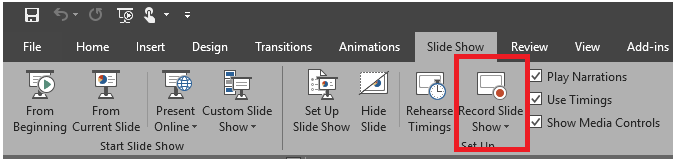
For a presentation of type A) (slides + voice-over), it is quite simple. One can prepare his slides with a software such as Microsoft Powerpoint and then use the “Record slide show” feature to add voice to the presentation. This is done by clicking on the button below:
The result is a Powerpoint presentation that can be played with audio on any computer equipped with Powerpoint. Then, for more convenience, there is some software to convert a Powerpoint presentation to a video.
For a presentation of type B) (video from a camera), one can use some basic software to record from a camera such as a wecam. Some basic software to record a video come packaged with most operating systems (e.g. the Camera app in Windows 10). However, there also exist many other software programs that let you record videos but also add special effects, transitions, texts and other elements to your videos. Some video editing software are quite powerful and easy to use (e.g. Wondershare Filmora, Movavi Video editor) while some are harder to learn but are more powerful (e.g. Adobe Premiere).
For a presentation of type C)(slide + video of the person), it is more complicated to record because it requires to not only record your slides but also a video of yourself at the same time and then put them together in a video. Here is a picture of the result that we may want to achieve:
To do such video recording, I use the Camtasia software, which allows to record my screen or a Powerpoint presentation with a Webcam at the same time, and then to edit the resulting video with effects, transitions, text, etc. This software is not free, but it is very easy to use and powerful. Other alternative software could certainly be used.
I first open my slides with Microsoft Powerpoint.
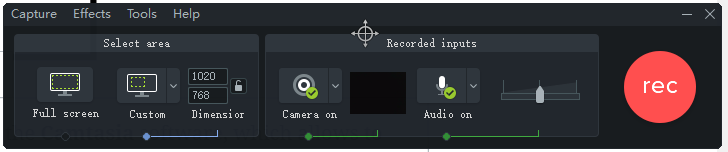
Then I open the “Camtasia Recorder“. You can see the interface, below:
There, I first select the part of the screen that I want to record by clicking the “Custom” button. Then, I choose to record using my webcam by clicking “Camera on” and using my microphone by clicking “Audio on“. Then, to start recording, I click the “rec” button.
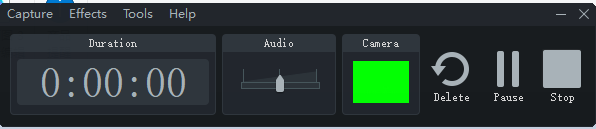
Then, after I finish recording my presentation, I click “Stop“.
After clicking “Stop” this opens the Camtasia editor and there I can edit the video that I have recorded. The interface of the Camtasia editor looks like this:
In the editor, it is possible to cut some part of the videos, add effects, and many other things. As you can see in the picture above, I have two different video tracks (at the bottom), one for the video recorded from the webcam (with a green background), and one for the presentation.
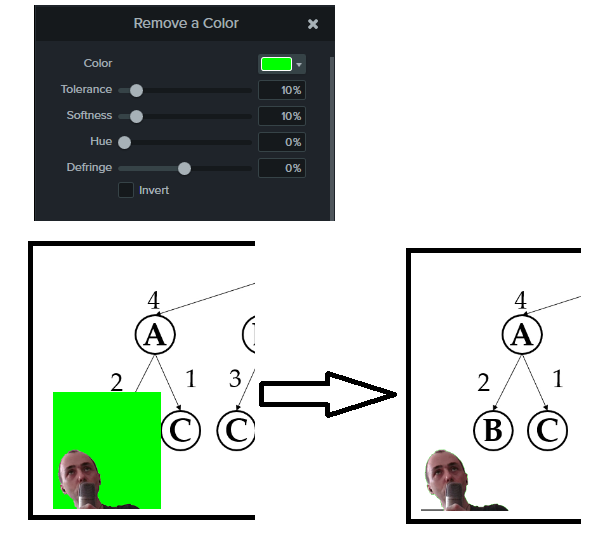
Then, since I have shot the video of myself with a green background, I can remove the background behind me. This is done by clicking on the video track of me and adding the “Remove a color” visual effect where I choose “green” as the color to be removed. (see a screenshot below):
This effect called “Chroma key” is a nice effect to have to do a nice presentation. It allows to have a transparent background so that I can overlay my video on top of my slides! If you also want to do this, you first need to shoot your video of yourself with a green background. There are two ways to do this. The traditional way is to shoot with a green screen behind you like this (source of the picture: Amazon).
However, buying a green screen is actually not necessary. A more simple solution is to use a virtual webcam software like ChromaCam that will use machine learning to automatically remove your background and put a green background behind you.
This is what I have done in the example above to avoid buying a real green screen. The latter would of course give a better effect but it would require additional space and money. The virtual webcam software Chromacam can be used for free but in that case, it will add a watermark to your videos. To remove the watermark, it is possible to buy a license. Or if you have a webcam like the C922 Pro Stream or Brio from Logitech, then ChromaCam will be free to use for the ChromaKey effect. So this is one of the reasons why I chose to buy the C922 Pro Stream for my setup. There are some other alternatives to ChromaCam like XSplit VCam but it is also not free and worse, it is based on a subscription model that requires to pay every month. There might be some other free alternatives to Chromacam but I did not find a good one that is easy to use and give good results. Here is a picture of the Chroma Key effect obtained using the Chroma Cam software:
As you can see above, it can remove the background quite well, although it may cut a bit of my hair and shoulder sometimes 😉
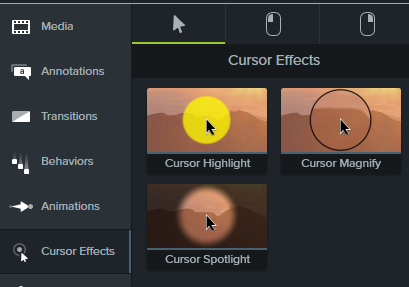
Another important thing that I do using the CamtasiaEditor is to add a “Cursor effect” so that my mouse pointer is highlighted in yellow in my videos. The result looks like this:
To do that, I click on the video track of my slides in Camtasia Editor and select a Cursor effect from the one offered:
Lastly, after recording the video, the last step is to encode it in an appropriate format. I usually choose MP4 because it is read by most browsers and devices. Then I publish the video. There exists various websites for publishing videos with different features. In my case, I already pay for a hosting company to host my website. Thus, I put my videos on that platform.
Lastly, for a presentation of type D) using a virtual whiteboard for writing and drawing on the screen, one can use a pen tablet or a computer that support pen input. For example, I bought a Wacom Intuos pen tablet (see below) that I connected to my laptop. Using this tablet, I can draw inside a software like Microsoft Paint, Powerpoint or One Note.
Then, I can record what I am writing using a screen recording software like Camtasia. This allows to create video presentations where I appear to be writing on a virtual whiteboard. For example, here is a little drawing that I made using the pen tablet, just as example:
Using this type of presentations is very useful to teach topics such as mathematics that are typically taught using a whiteboard.
Update from 2023: a green screen, and better recording method
I have recently upgraded my setup to record with a green screen, and the result is quite better. As you can see in the screenshot below:
This is my updated setup with a green screen:
Having a green screen gives better results but requires more space and also to adjust the lightning properly which is more complex than my previous solution with ChromaCam.
Besides, I also recently improved my recording method to get better video quality. A problem that I had observed is that Camtasia is quite CPU hungry and because of this the videos that I recorded of myself with my webcam tended to be a little choppy with a low frame rate. Moreover, I also observed that my new smartphone has better image quality than my webcam. Thus, I now use my cellphone to record the video of myself separately rather than using my webcam. This has the advantages that video quality is not affected by the CPU usage of Camtasia anymore and that better image quality is also obtained due to the smartphone’s better camera. Then, after I recorded the video with my smartphone, I import the video in Camtasia and synchronize the video with the sound and the recorded presentation. By doing this the end result has better image quality but is also more fluid. If I had a more expensive camera, I could also use this in place of my smartphone.
Conclusion
In this blog post, I have provided some tips about how to record a research talk on a computer. Hope this has been interesting and will be useful!
If you have some comments or other complementary advices, please leave a comment below.
Today, I presents the CPT and CPT+ sequence prediction models in a video. Sequence prediction is an important task in data mining which consists of predicting the next symbols of a sequence. It can be used for example to predict the next word that someone will type on a keyboard, or the next location where someone will go.
The official implementations of CPT and CPT+ models and datasets for evaluating their performance are available in the SPMF software, which is implemented in Java and open-source. There is also an unofficial implementation of CPT in Cython.
The CPT+ (Compact Prediction Tree+) model is described in this article:
So you have a paper accepted for presentation at an academicconference and you wonder how to prepare for attending the conference? In this blog post, I will discuss this topic.
Making a travel plan
For an international conference, the first thing to do before attending the conference is to check for thetravel requirements. Travelling to several countries or territories require to apply for a visa and obtaining a visa can sometimes take a long time, and require to have various documents ready such as an invitation letter. Thus, it is better to start the process of applying for a visa early if needed. One may also require to obtain the approval from his university or company to attend a conference. If one cannot attend the organizers, he should also let the organizers know about it or arrange someone else to replace him.
After ensuring that you can enter the country/territory where the conference is held, the second most important thing is to have a transportation plan. For international conferences or domestic conferences that are far away, one should reserve an airplane/bus/train ticket early, as prices may increase and less choices may be available over time. Generally, I would recommend to arrive at least one day before the conference at the city where it is held.
You may also want to pay for a travel insurance and check if some vaccines are required. Travel insurance can sometimes be purchased with your airplane ticket.
Then, one should also book an hotel room early. When a conference is held in a famous city, sometimes the most affordable hotels or those that are the closest to the conference may become fully booked quickly.
Preparing your talk,and giving a good talk
If you are planning to give talk (a presentation of your research work) at a conference, you should prepare your presentation BEFORE the trip. I have previously written a blog post about how to give a good oral presentation at an academicconference and another one here. You may read these blog posts which gives many advices rabout how to prepare and deliver a good talk. Then, after your presentation is ready, if you are using electronic slides such as PPT slides, you want to put them on your laptop, on a USB drive and perhaps also keep a copy in your e-mail to avoid any problem.
If one has to present a poster at an academicconference, he should also prepare the poster in advance and keep some time for printing it.
Preparing a networking plan
In my opinion, the most important reason for attending an academicconferenceis to meet other researchers because all the papers presented at a conference can be read online anyway. To take advantage of the networking opportunities offered by a conference, you may look at the list of attendees before attending the conference and make a list of people that you would like to meet and discuss with. Meeting other researchers is important for the career of a researcher as it allows to exchange ideas and also develop collaborations and look for opportunities such as finding a post-doctoral, researcher or faculty position.
At a conference, many people will ask you where you are from?what kind of research are you doing? It is also good to have a short 30 second or 1 minute answer ready for these questions, as it may help to start some discussion. It is also good to bring your business cards if you have some, and it is useful to invite the people that you meet to connect on your profesionnal social network website like LinkedIn so you may want to install it on your phone. By the way, if you don’t already have a website, or profile on LinkedIn or on academic social networks like ResearchGate, it is a good idea to have one for your career so that people can find you online.
When you participate to an academicconference, you should also look at the schedule and make a plan of the activities that you want to attend to use your time well. And especially, you should not miss the networking activites like coffee breaks, banquet, reception, and poster sessions to talk with other people. Also don’t be shy. If you don’t know anyone, then remember that most people attending the conference also probably don’t know anyone and will be happy to talk with you.
Taking the airplane
If you fly to a conference, it is important to prepare your luggage well and what you will carry in the airplane. I generally prepare a luggage and also a backpack or small bag that I bring with me in the airplane. In that latter bag, I carry:
My passport, a printed copy of airplane tickets (because you may have to show your return ticket when arriving in another country), visa or other required travel documents, and travel insurance.
Computer and accesories (usb, charger, laser pointer, mouse, adapter to connect computer to a projector, etc.), cellphone.
Earplugs (for the noise in the airplane), headphones and adapter for using it in an airplane (because headphones provided in airplanes are sometimes quite bad),
Pens (always useful for filling forms when arriving in another country)
International power plug adapter (you should check if needed before travelling) to be able to use your electronic equipments
Cash, debit cards, credit cards, and other valuables items (jewelry, etc.).
Medicines (if needed)
Book (if I want to read in the airplane)
I also bring a very thin sport jacket to put in the airplane in case it is too cold (but you can also ask the air attendant for a blanket ).
I then put all other things in my luggage. For a conference, it is important to bring some nice clothings but it also does not need to be highly formal either.
Before entering the airplane, you should also choose your seat when checking in. In an airplane there are some good seats and some bad seats. For a long flight, I prefer to have an aisle seat (a seat beside the walking alley) because if I need to go to the washroom or walk a bit, I don’t need to ask other people to let me pass (they may be sleeping), and there is no one besides me on one side. The second best seat is the window seat, because there is also no one besides you on one side and you can lean on the window to have a rest. The worst seat are the seats where you sit between two persons because you may be squeezed between two persons and you can’t enjoy the window view and still need to ask other people to pass if you need to go to washroom or walk outside.
Arriving at the conference
When you will arrive at the conference, the first thing to do is to register at the registration desk. Then, you can enjoy the various activities of the conference.
Conclusion
In this short blog post, I gave some advices about attending a conference that I hope will be useful, especially to those attending an academicconference for the first time. If you have some questions or if you think that I forgot to mention something important, then please leave a comment below!
== Philippe Fournier-Viger is a full professor and the founder of the open-source data mining software SPMF, offering more than 170 data mining algorithms. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.
Fist I would like to wish a happy new year to all readers of this blog. I wish you health, hapiness and also success in your research projects! I am also thankful to all those who have used and/or contributed to the SPMF data mining software , which I have founded already a decade ago! Time goes fast, but the project is still active, and I am preparing a new release with about 10 new algorithms that will be released in one or two weeks. The new algorithms have been contributed by various people. By the way, if you would like to contribute code to SPMF, it is also welcome.
Now, I want to talk a little bit about the new year. The new year is a good time to think about past achievements and update ourgoals or set new goals. Having clear goals and working hard towards these goals is key to be successful.
That is all I wanted to say for today!
== Philippe Fournier-Viger is a full professor and the founder of the open-source data mining software SPMF, offering more than 170 data mining algorithms. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.
In this short blog post, I will answer the question: what is the difference between Machine Learning and Data Mining? I will first explain what is artificial intelligence, machine learning and data mining. Then, I will answer the question.
What is artificial intelligence and machine learning?
Artificial intelligence is a field of research, which aims at developing software that can do some tasks that require intelligence. What is a task that requires intelligence is open to debate and can be for example to play chess, translate documents, write a novel, or choose the best route to drive from one location to another. This broad definition of artificial intelligence that I have given is defined based on the behavior of a software program (what a software program can do rather than how it works). Some people define artificial intelligence in a stricter way by requiring that an artificial intelligence should also simulate the mechanisms that intelligent beings such as humans use for producing intelligent behavior. In another word, an intelligent program should not only appear to behave intelligently but should also mimic how the brain works, for example.
There exist many types of artificial intelligence techniques. Some early research on artificial intelligence proposed the so called expert systems where a human expert would give knowledge to the system (for example, as a set of IF-THEN rules), which the system would then apply to behave intelligently. A problem with this approach is that writing knowledge by hand is time-consuming and prone to error for complex tasks, and that it is not always easy for a human expert to encode his knowledge. Such systems have also been called knowledge-based systems.
Another type of artificial intelligence systems does not require knowledge or data. This is the case for example of algorithms such as A* (a-star), which are used for example to play games. Consider a simple game like Tic Tac Toe. All the possible moves in this game can be viewed as leading to different states, including some states where one wins or loses. Because the number of possible states for such games is rather small, a simple algorithm to play such games can search through all the possible states or a subset of them to select the best move to perform.
Other artificial intelligence systems are not preprogrammed and are designed to learn by themselves from data. The field of research aiming at designing such systems is machine learning. Some popular types of machine learning systems are artificial neural networks, which are very loosely inspired by the brain. Such systems are generally trained to do some specialized task using some training data indicating what is the expected behavior in a given situation. The system then generalizes from this data to take decisions in new but similar situations. This process is called supervised learning. This is for example the case of a system for reading handwritten texts. Such system can be trained using handwritten letters where correct answers are provided by a human. After training the system with many examples of letters, the system can then recognize new letter drawings. There also exist some artificial intelligence systems that can learn from data without knowing the correct answers beforehand. This is called unsupervised learning. To summarize, machine learning is a subfield of artificial intelligence where a software program can learn from data.
What is data mining?
Data mining has a different focus. As the name implies, data is key to data mining. Without data, one cannot do data mining. The goal of data mining is to analyze data by discovering knowledge hidden in the data. For example, a classic data mining task is frequent pattern mining, which consists of finding the sets of values that frequently appear in data (e.g. discovering that many people buy bread with cheese and a chocolate bar at a supermarket). This task is unsupervised and has for only purpose of discovering something new in the data. Generally, such techniques can be used to understand the past or predict the future.
Some other data mining techniques are explicitly designed for extracting models from data that can then be used for making predictions. This is the case of techniques such as neural networks, decision trees, and regression models. Now, you probably remember that I already talked about neural networks as a machine learning technique. This is because data mining is overlapping with machine learning. In other words, some data mining techniques can also be called machine learning techniques.
What is the difference between machine learning and data mining?
Though, machine learning and data mining overlap, and both require data, data mining traditionally focuses more on providing knowledge or models that are explainable or interpretable by humans, while machine learning studies are often more focused on what a model does. As a result, several machine learning models are designed to provide a high accuracy for some tasks such as handwritten character recognition, but appear to work like a black-box to humans. There is thus currently an important need to build more interpretable or explainable machine learning models. The problem of black-box machine learning models is illustrated in this funny picture from XKCD (credit: https://xkcd.com/1838/ ):
Conclusion
That is all for this blog post. I just wanted to discuss differences and similarities between machine learning and data mining. If you would like to add something to this, you can post a message in the comment section, below.
— Philippe Fournier-Viger is a full professor working in China and founder of the SPMF open source data mining software.
This week, I have attended the 7thBig Data Analytics conference(BDA 2019), which was held in Ahmedabad, India from the 17th to 20th December 2019. This was a great event with good keynote speeches, invited talks, research papers, tutorials, a workshop on IT for agriculture, a panel and social activities. In this blog post, I will give a brief report about the conference.
The Big Data Analytics (BDA) conference
The BDA conference is an international conference about Big Data Analytics, Data Mining, Machine Learning and related topic. This year is the 7th edition of the conference. BDA is held every year in different cities of India but it attracts papers from several countries. This year, authors from 13 countries published papers, and the program committee, invited talks and keynote speeches comprised experts from numerous countries, as well as local experts. There was about 150 to 200 persons attending the conference.
The proceedings of the Big Data Analytics (BDA 2019) conference are published by Springer in the LNCS (Lecture Notes in Computer Science) series, which ensures a good visibility to the published papers. The papers are indexed by EI, DBLP and other major indexes for computer science. This is the proceedings book, which is available electronically to attendees:
It was a pleasure for me to work as Program Committee co-chair for the conference to help select papers and build the program. This year, there was about 53 submissions, from which 13 were selected for publication (an acceptance rate of about 25%), and five invited papers were also published, for a total of 18 papers. The idea of having invited papers from top researchers was a good one, as it brought some really good papers.
Location of the BDA 2019 conference
The conference was held at Ahmedabad University. It is a relatively new university (10 years old). The university is located in the city of Ahmedabad, in the state of Gujurat, India.
Ahmedabad is famous for being a place where Mahatma Gandhi had lived, among other things. It also has some historical buildings and structures in and around the city, that are quite interesting. People living in this city are mostly vegetarian, and in that state, all alcohol is prohibited (unlike in other parts of India). There is also some local language spoken by the population. It was interesting to visit the city.
Local organization
The local organization was very well done. Everything was well arranged. For example, an airport pickup service was offered to all international attendees, and e-mails were always answered very quickly by local organizers.
Day 1. Registration
On the first day, I registered and received a nice bag with a pen, notebook, schedule and other things inside.
The conference badges offered by the conference are of good quality. They are made of a wood-like material where names and affiliations appear to have been etched into the material.
Day 1. Tutorial and Workshop on IT in Agriculture
On the first day of the conference, there was tutorials. Moreover, there was a workshop on IT in agriculture. I listened to the keynote by Prof. P. Krishna Reddy, which was quite interesting. It talked about how he has developed computer systems to provide advices to farmers in India, in various projects for more than 10 years. This is interesting as it is not just theory but has real practical applications that can change life of many people.
Day 2, 3, 4 – Paper presentations
The paper presentations were quite interesting. I will not report about the details of each paper. But the paper covered a wide range of topics from pattern mining, information extraction, online review helpfulness prediction, urban tree type classification to data warehousing.
As I am a researcher working on pattern mining, I am particularly interested by this topic. There was three papers on pattern mining:
Duong, H., Truong, T., Le, B., Fournier-Viger, P. (2019). An Explicit Relationship between Sequential Patterns and their Concise Representations. Proc. of 7th Intern. Conf. on Big Data Analytics (BDA 2019), Springer, pp. 341-361. (this is a paper about a new way of finding frequent sequential patterns using generator and closed sequential patterns).
P. P. C. Reddy, R. Uday Kiran, Koji Zettsu, Masashi Toyoda, P. Krishna Reddy, Masaru Kitsuregawa: Discovering Spatial High Utility Frequent Itemsets in Spatiotemporal Databases. 287-306 (this is a paper about extending high utility itemset mining for spatial data)
Day 2 – Cultural performance and reception
On the evening of the second day, there was a music and dance show, performed by students of the Ahmedabad University. Although students may not be professional, the show was quite good. It presented some traditional dances and Indian songs. The show was followed by a dinner.
Day 3 – Panel: Big Data Analytics is not AI
On the third day, there was a panel titled “Big Data Analytics is not AI” that has sparked a lot of discussion, organized by Anirban Mondhal. I was one of the panel members, along with Goce Trajcevski, Shashi Shekhar, Ladjel Bellatreche, Sanjay Madrias and others. Here is a picture (some panel members not shown):
(credit: BDA 2019)
The topic was the relationship between machine learning and big data analytics. Four questions were asked to panel members, and then the audience asked additional questions.
Should CS students learn theory and skills related to both BDA and ML? My answer: Artificial intelligence and big data analytics are popular. It is thus good for students to at least become familiar with these topics. Moreover, if one wants to become user of these techniques, he should not only learn how to utilize the many libraries available that are easy to use but also understand the theory, and the assumptions behind these techniques. This is important because if one does not understand the assumptions or theory behind these techniques, one may apply them wrongly. Also, before learning big data analytics and machine learning, it is better to have a strong foundation about the core concepts behind those such as databases, linear algebra and statistics.
Should researchers work across both BDA and ML or specialize in any one of these areas? My answer: As researchers, we always tend to specialize in some area. This is reasonable because we are expected to publish state-of-the-art research, which requires to know well research in a given field. Having said that, I would like to talk about the relationship between big data analytics and machine learning. Generally, the goal of artificial intelligence is to build some software that can perform some task(s) that are said to require intelligence. On the other hand, the goal of big data analytics or data mining is to discover some useful information or build some useful models from data to understand the past or predict the future. Thus, artificial intelligence and big data analytics have different goals. The main one is that many techniques from artificial intelligence require data to train models. The artificial intelligence techniques that are not explicitly programmed but instead learn from data are called machine learning. The requirements for cleaning, preparing, transforming, storing and handling data may be the same as big data analytics. But there exists some artificial intelligence techniques that do not require training data. For example, this is the case of some traditional AI techniques such as theorem provers, path planners and logic reasoners. There are also some differences between machine learning and big data analytics. An important one is that machine learning tends to focus on building models that do something well or are accurate but are often black boxes (a model works, but the user don’t know why or how the model do predictions – this is the case of many deep learning models for example). On the contrary, many big data analytics techniques focus on discovering interpretable insights and on the visualization of results. For AI researchers, there is a lot to learn from data science/data mining about building explainable and interpretable models. But also, it is to be said that machine learning and big data analytics/data mining are also some fields that are overlapping. Some techniques such as neural networks can be said to belong to both machine learning and big data analytics.
In the future, will the industry have separate roles for BDA and ML specialists? My answer: In the industry, it depends on the size of the company. Bigger companies tend to have persons doing more specialized tasks, while smaller companies may have persons doing many tasks. Recently, it has been interesting to see on some website like LinkedIn that many specialized job titles have been proposed such as: •Data scientist •Data engineer •Data architect •Data developer •Data analysist •Data warehouse software engineer •Database engineer •Statistician •Business analysis •Machine learning engineer •Predictive modeler… I personally don’t know very clearly the differences between all these job titles, and I often see contradictory definitions about these job titles.
From a long-term perspective, do you see BDA and ML converging as a single research area or will they grow independently? My answer: No. As I said previously, big data analytics and machine learning have many things in common but also some different goals. Besides, in academia, there exists some communities that are clearly defined such as statisticians, data mining, machine learning, and researchers tend to stay in their field and publish in the journals and conferences of their community. It would take some time and major effort to redefine these communities.
Day 3 – Banquet
On the evening of the third day, there was a banquet outside. There were some tables serving Indian food and some chairs for those who wanted to sit. Others would eat standing and talk with others. As always, banquets are good for networking with other researchers. I had some good discussions with friends and met some other international and local researchers. Moreover, I was happy to talk with some local students who attended the conference and asked me some questions about how to learn about data science and machine learning. Besides, I was happy to meet some professors from some local universities who told me that they were using my SPMF data mining software for teaching data mining.
Group photo
Here is a group photo of BDA attendees:
(credit: BDA 2019)
Next year: BDA 2020
Next year, the BDA 2020 conference will be held in New Dehli, India. Then, BDA 2021 will be held in Allahabad, India.
Conclusion
In this blog post, I have given a brief report about the 7th Big Data Analytics conference (BDA 2019), from my perspective. On overall, it was a great conference, and I am very happy to have attended it. It was the first time that I went to India, and it has been a good experience. The quality of papers was quite high, and the invited speakers, tutorials and keynote speeches were very interesting. I will try to attend it again next year.
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 150 data mining algorithms.(Visited 336 times, 1 visits today)
This week, I am also attending the 14th International Conference on Advanced Data Mining and Applications (ADMA 2019) conference in Dalian, China, from the 21st to 23rd November at Dalian Neusoft University of Information.
About ADMA
The ADMA conference is focused on data mining and its applications, and is generally held in China. It was held evey year since 2005, except in 2015. I have attended ADMA 2011, ADMA 2012, ADMA 2013 and ADMA 2014, ADMA 2018, and now I am here for ADMA 2019. ADMA is a medium-size conference but I like to attend it as it generally still has some high quality papers and it is convenient for me to attend it as I am currently living in China.
Proceedings and acceptance rate
For the 14th edition of the conference, 170 submissions were received, and 39 were accepted as full paper (acceptance rate of 23%) and 26 more as short papers. This is a considerable increase in the number of submissions compared to last year, where 104 papers were submitted to ADMA 2018 .
The proceedings are published by Springer in the LNAI series, which ensures good visibility to the papers.
Registration
On the first day, I registered and received the conference bag containing the program, a pen, a note book and a guest conference badge. The proceeding book was available online. Although, I would have enjoyed having a physical copy of the proceedings, I have to admit that an online proceedings is more environment-friendly.
Day 1
The conference started with the opening ceremony, where the founder of the conference, Prof. Xue Li talked about the history of the conference.
Then, there was a keynote speech by Chengqi Zhang about “AI for Social Good“. He first discussed about the AI turing test and the use of AI for different goals: functional simulation, perception and action. Then, he discusses three corresponding ways of doing AI that are knowledge-based reasoning systems (symbolism) and data-driven neural networks (connectivism), and behavior-based action system (behaviorism). He also emphasized the importance of combining different aspects of AI such as perception, action, and image and language understanding. He then talked more about what is AI, and how AI can make us happier, healthier and wealthier. He discussed applications such as medicine and self-driving.
Then, there was a second keynote, by Guoren Wang about ” Big Data 2.0: Future Data Computing“. He first talked about the history of innovation for Big Data technology, from Relational Database Systems relying on SQL/ACID database systems, to distributed systems, to NOSQL databases, to real-time technologies. He also talked about the evolution of big data computing frameworks such as Hadoop from Hadoop 0.0 (2007) to Hadoop 3.0 (2016), and newer frameworks such as Apache Flink and Spark Streaming for stream processing, and framework such as Apache Beam that support both stream and batch processing. He also talked about trends such as geo-distributed data centers and edge computing
Then, in the afternoon, there was several paper presentations. I presented a paper about a faster algorithm for high utility episode mining, named HUE-SPAN. In this paper, we first show that there is a problem in how the utility of episodes is calculated in previous work on high utility episode mining, and propose a solution to that problem. Then we present novel strategies and a tight upper-bound for high utility episode mining that result in the more efficient HUE-SPAN algorithm. The PPT about HUE-SPAN is available here.
Also related to the topic of mining patterns in data, I enjoyed the paper presentation of Acquah Hackman et al. called “Mining Emerging High Utility Itemsets over Streaming Database “, which receive the best student paper award.
I also enjoyed the presentation about discovering sequential rules in time series data by Benoit Vuillemin “TSRuleGrowth: Mining Partially-Ordered Prediction Rules From a Time Series of Discrete Elements, Application to a Context of Ambient Intelligence“, which was inspired by some ideas of my TRuleGrowth algorithm but for time series.
Then, there was a buffet in the evening to close the day.
Day 2
On the second day, there was a keynote by Prof. Vincent S. Tseng about deep learning and broad learning for medical AI. Broad learning means the fusion of multiple heterogeneous data sources for learning a model. To do broad learning, we can collect data from multiple data sources, devise a model to fuse the information from these heterogeneous data sources, and then mine information from each data source to then build a global model. Prof. Tseng then discusses medical AI systems, and some specific applications such as health prediction, and disease risk prediction.
There was then a keynote on geo-social recommendation by Prof. Hongzhi Yin.
Then, there was more paper presentations, and finally the gala dinner, where the best paper award winners were announced.
I was very happy to see that the paper “Tourist’s Tour Prediction by Sequential Data Mining Approach” by Baccar, L. B., Djebali, S., Guérard, G. won some award as they have used my SPMF data mining software in their work.
Day 3and 4
On the third day, there was more paper presentations, and on the fourth days, there was a workshop related to health data.
ADMA 2020
Next year, the 15thADMA conference (ADMA 2020) will be held in the Foshan area of the city of Guangzhou in China.
Conclusion
I enjoyed the conference. It is not a very big conference but usually the paper quality is fine. I will probably submit a paper again next year.
In this blog post, I will report about the MIWAI 2019 conference (13th Multi-disciplinary International conference on Artificial Intelligence), which was held from the 17th to 19th November 2019 at the EDC hotel in Kuala Lampur Malaysia.
About the MIWAI conference
This is the 13th edition of the MIWAI conference. The conference is called MIWAI since originally, it started as a workshop called Mahasarakham International Workshop on Artificial Intelligence in 2017. Initially, MIWAI was held every year in Thailand, and since 2011, it has been held outside Thailand as a conference:
Ho Chi Minh City, Vietnam (2012)
Krabi, Thailand (2013)
Bangalore, India (2014)
Fuzhou, China (2015)
Chiang Mai, Thailand (2016)
Brunei Darussalam (2017)
Hanoi, Vietnam (2018)
Kuala Lampur, Malaysia (2019)
Registrationand proceedings
On the first day, I first registered and received the conference bag and proceedings.
The proceedings of MIWAI 2019 are published by Springer in the Lecture Notes in Artificial Intelligence (LNAI) series, which ensures good visibility to the papers. This year, there was 53 submissions from 23 countries, and 25 papers where accepted, for an acceptance rate of 45%.
Day 1 – Opening ceremony, keynote talkand paper presentations
On the first day, there was the opening ceremony.
Then, there was a keynote talk by me (Prof. Philippe Fournier-Viger) entitled “Algorithms to Find Interesting and Interpretable High Utility Patterns in Symbolic Data” about techniques for discovering useful patterns in data. In particular, I talked about high utility itemset mining, which has become a popular area of research, and introduced some of my recent contributions.
Then, there was several paper presentations. In particular, I enjoyed the talk about associative classification by “Generation of Efficient Rules for Associative Classification” by Chartwut Thanajiranthorn and Panida Songram. They proposed a novel associative classifier method that achieved high accuracy compared to other classifiers of that type.
Another interesting paper that caught my attention, applied sequential pattern mining for building an academic chatbot. This paper is “Identification of Conversational Intent Pattern Using Pattern-Growth Technique for Academic Chatbot” by Suraya Alias, Mohd Shamrie Sainin, Tan Soo Fun and Norhayati Daut.
Day 1 – reception
In the evening, there was a nice reception dinner at the hotel with a traditional malaysian dance performance, and the best paper award was announced.
Day 2 – keynote talk and other presentations
On the second day, there was a keynote by Prof. László T. Kóczy from Hungary about a novel Discrete Bacterial Memetic Evolutionary algorithm(DBMEA) for solving hard problems such as the travelling saleslman problem with a time window.
Then, it was followed by more paper presentations.
MIWAI 2020
New year, the MIWAI 2020 conference will be held in Seoul, Korea. See the information below.
And I heard that MIWAI 2021 would be held in Japan.
Conclusion
I am happy to have attended the MIWAI 2019conference. I met some researchers that I knew beforehand and met several interesting people that I did not know. The quality of the papers was good, and some papers were particularly interesting for my research interests. The conference was well-organized.
In this blog post, I will talk about competitiveness in academia. I will discuss questions such as: What are the different forms of competition in academia? Is there too much competition in academia? and How to cope with competition?
The different forms of competition in academia
Generally competition means that many people will compete to access a limited amount of resources and opportunities. In academia, competition happens at many levels:
Students competing against each other in courses. Students taking courses at an undergraduate or graduate level sometimes compete with each other to obtain the highest grades. This is especially true for courses where the teacher uses a normal curve for grading. For example, when I was a graduate student, some professors would give the highest grade (A+) to only the top 5% of students. Then, some students would work quite hard to be in that top 5%.
Being admited in graduate school. The best students may be admitted in better research teams and research institutions for their master degree or PhD.
Competing for scholarships. The best students are often selected to receive scholarships.
Publishing papers in conferences and journals. Publishing research papers is a competitive process. This is especially true for conferences that only accept a limited number of papers and have a good reputation. Some journals are also very competitive because they receive many papers and only publish the best.
Competing for a post-doctoral researcher or faculty position. The job market in academia is also very competitive. Some universities receive hundreds of CVs for some faculty positions. In fact, there are much more people that have Ph.Ds than there are faculty positions available, in several countries. Thus, not all PhD graduates can continue working in academia.
Competing for research project funding. Obtaining funding is also a competitive process, as many researchers wants to obtain funding.
Competing for research impact. There are millions of research papers that are published but many of them are never cited. Writing papers that can have a major impact is difficult and is often a matter of publishing results first and doing a better work than other researchers.
Competing for awards. Several awards are given to researchers based on the quality of their work such as “best paper awards” at conferences. Few researchers may receive it.
Is there too much competition in academia?
Hence, there is competition in academia. But is there too much? It is hard to say if it is too much, but there is certainly quite a lot of competition. For example, competing for publishing papers in top conferences or obtaining faculty positions in some countries can be very difficult. Some people certainly don’t like to have that much competition, while others are comfortable with it. A positive aspect of competition is that it can push researchers to work harder. But a negative aspect is that some people may be discouraged or fail to attain their goals due to the limited resources and opportunities.
Generally, I think that it is necessary to have at least some minimum level of competition. For example, it make sense that some papers are not accepted in top conferences and journals because these papers are weak and contain major problems.
How to cope with competition?
Given that there is a high level of competition in academia, what one should do to be sucessful? Some people believe that they should solely focus on their own success and not contribute to the success of others. This is the mindset that some people have in sports where helping other people would decrease your chances of winning. However, academia is not like that. The most successful researchers generally have many collaborations with other researchers. The reason is that collaboration can bring benefits to all researchers that are cooperating (it is not a zero-sum game). For example, doing research projects with other researchers allows to obtain ideas and comments from collaborators that can be very valuable. Collaborating can also result in producing more papers. Building strong connections with other researchers can also help obtaining opportunities such as being invited to join committes of conferences. To know more researchers, a good way is to attend academic conferences.
Inside a research team, there can be some competition sometimes. However, members of a research team should try to collaborate or at least support each other. This can benefit all members, and also the whole team.
Also, one should not feel discouraged by competition. If one really wants to achieve some goals, it is always possible. But it requires to makes these goals clear as early as possible and to work hard to attain these goals. I think that working hard and smart are some of the most important skills in academia.
Conclusion
In this blog post, I talked about competitiveness in academia, as I think that it is a very important topic for researchers. I have shared a few ideas related to that. If you want to share your comments or your experience about how you are living competition in academia or if you think that I forgot to talk about something important, please post a message in the comment section below! I will be happy to read you.