To all readers of this blog, I would like to wish you a happy new year 2023!
Recently, I have been very busy due to the end of semester and also having COVID. But now, I am fully recovered.
Two things that I would like to talk about.
Recently, I have learnt the sad news that a researcher from the field of data mining has passed away, who was still very young (around 50 years old). He was a good researcher and also a very friendly person that I have met several times at conferences. This reminds me that life can be short and it is important to enjoy it and also take care of your health. As researchers, we often work very hard. But, we should also think about having more balance between work and other aspects of life so as to be more healthy, and also to do sport, eat well and sleep well. I talk more about success and health for researchers in this blog post.
On a different topic, I have recently released a new version of the SPMF data mining software (SPMF version 2.59, which you can download here). It offers two new tools: a graph viewer and an algorithm explorer (which I previously described on this blog), and also three new algorithms for periodic pattern mining, contributed by Prof. Vincent Nofong. I recommend to check out these new algorithms (PPFP, NPFPM and SRPFPM). They offer several possibilities for further research and applications.
This was just a short blog post to wish you a happy new year, talk to you about life, and tell you about the new version of SPMF.
== Philippe Fournier-Viger is a full professor and the founder of the open-source data mining software SPMF, offering more than 110 data mining algorithms. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.
This week, I wasattending the BDA 2022 conference, which is the 10th International Conference on Big Data Analytics. The BDA 2022 conference washeld in Hyderabad, India from the 20th to 22nd December 2022.
The BDA conference is an international conference organized in India, which is quite good and is published by Springer in the Lecture Notes in Computer Sciences series. I have previously attended in 2019 (see my report of BDA 2019). This year, I am attending it again as co-author of a paper and also as a keynote speaker and moderator for a panel.
My report for this conference is a little short because I have been a bit sick during the conference and could not attend all the presentations due to this.
Proceedings
All papers in BDA are published in Springer LNCS which gives good visibility and indexing.
Opening session
I have first attended the opening session. Below are some slides from the opening session that provide some interesting information.
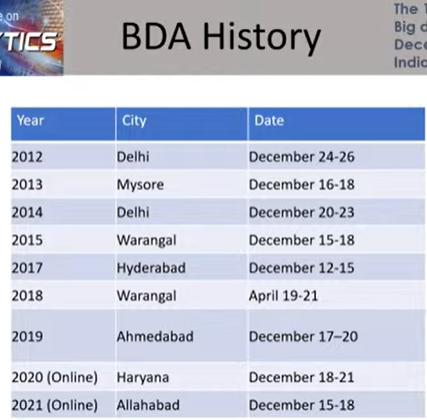
The BDA conference is held every year in different cities in India:
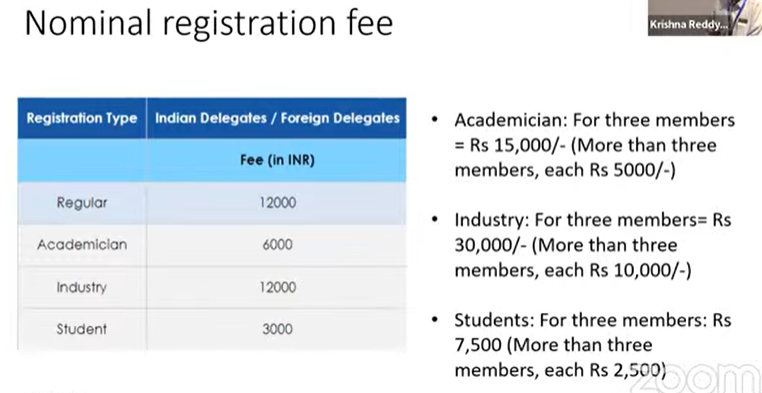
The registration fee is quite reasonable:
About the program of BDA 2022, there was 41 valid submissions, from which 14 were accepted, that is 7 short papers and 7 full papers.
There was several keynotes at the BDA conference. This year, I am one of the keynote speakers. I gave a talk about pattern mining.
There was also several invited talks, some from IBM and the Bank of America, which is quite interesting.
There was also a panel on big data analysis for attaining sustainability. I am one of the two moderators for this panel.
A lot of people are working behind the scene for this conference:
Paper presentations
There was many paper presentations.
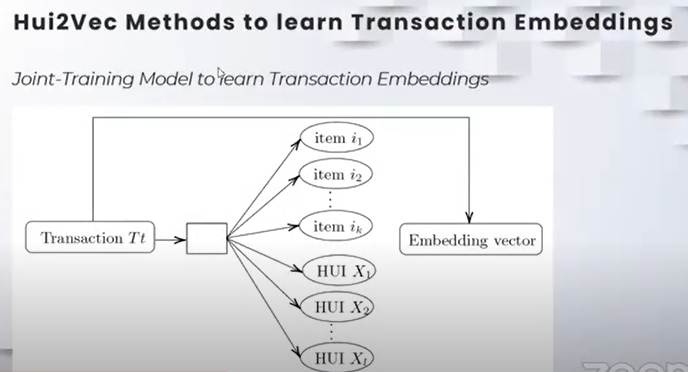
My collaborator from Tunisia, Prof. Khaled Belghith presented a paper on using high utility itemsets for transaction embeddings, which may be interesting for those working on pattern mining as it is a kind of bridge between machine learning and pattern mining:
Belghith, K., Fournier-Viger, P., Jawadi, J. (2022). Hui2Vec: Learning Transaction Embedding Through High Utility Itemsets. Proc. of 10th Intern. Conf. on Big Data Analytics (BDA 2022), Springer, to appear.
Panel on data science for sustainable development goals
There was a very interesting panel on data science for sustainable development goals with Prof. Masaru Kitsuregawa (The University of Tokyo), Prof. Longbing Cao (University of Technology of Sydney), Prof. Yun Sing Koh (University of Auckland), and Jaideep Srivastava (University of Minosota).
The panelists brought several interesting perspectives. In particular some cases study was discussed about algae bloom detection and about environmental monitoring. Besides, some other topics were discussed such as the importance of large data centers, health monitoring devices, data collection, and data sovereignty to name a few. The four invited experts also talked about the challenges of interdisciplinary work.
Conclusion
This is a short report about BDA 2022 because I have been sick during the event and I did not attend many activities due to this. But the BDA conference in general is a well-organized conference. The program is good with many excellent guests and speakers, and I also I know several researchers involved in this conference. Thus, I will be looking forward to attending it again.
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.
Previously, I wrote two blog posts about unethical reviewers in academia (part 1 and part 2). It is not that I like this topic, but today, I will talk again about that. Why? Because, I keep encountering them, unfortunately. It is something very common.
What is an unethical reviewer? As I explained in previous blog posts, there are various types of unethical behaviors that a reviewer may have such as (1) reviewing his own papers, (2) reviewing papers while having some other conflict of interests, or just (3) asking authors to cite his papers to boost his citation count.
Recently, the last case happened again. A collaborator had a paper rejected by two reviewers. And the two reviewers asked to cite between 3 to 5 irrelevant papers. One of the reviewer even put some comments that were unrelated to the paper, which shows that he did not even took the time to do his work seriously, in a hurry to boost his citations. This is some unprofessional behavior and result in wasting time and reduce the quality of the peer-review process.
Personally, every time that this happens, I am a bit angry and because of this phenomenon I think that there are several people in academia that do not care about research and honesty. It is for example, easy to find the profiles of some researchers on Google Scholar who suddenly have thousands of citations but that come from random journals, so it is obvious that they cheat rather than obtaining citations due to the quality of their research work.
So what to do in this situation?
Unfortunately, the balance of power is unequal between authors and reviewers. For the authors who submit a paper to a journal, if the paper is rejected due to unethical reviews, what can he do? He can write an e-mail to the associate-editor or editor-in-chief to complain but from my experience, decisions are almost never reversed in a journal. In fact, I have never seen the option of reversing a decision to even be available in paper management systems from journals. In the best case, maybe the editor could ask to submit the paper again but usually editors are very busy (some journals receive thousands of papers per year!) and I think many editors do not want to take care of authors who argue about the decisions of papers no matter what is the reason.
So what else could be done?
In my opinion, even if has few chances of working, the best is perhaps to send an e-mail to the associate editor and/or editor-in-chief to report the unethical behavior. Maybe that the reviewer could then be blacklisted or that a note could be put in its user profile of the management system as a result. But I would still not bet on this…
In my opinion, if we want something to change about this, the main persons who have power over a journal are the publishers, the societies that are responsible of these journals (e.g. ACM and IEEE), and the companies that take care of impact factors and other academic metrics and rankings of journals.
For example, in a famous case several years ago, an IEEE journal (the IEEE Transactions on Industrial Informatics) lost its impact factor due to citation stacking (artificially increasing the number of self-citations). Losing the impact factor is a serious consequence for the journal that can make things change. So a possibility to make things change is to also complain to the publisher or affiliated societies. This can have some impact although I did not see this happen often.
Another possibility would be to create an online public website where every researcher could upload the potentially unethical reviews that they have received. These reviews could be categorized by journals, and perhaps by authors of papers that reviewers ask to cite. This could show some interesting trends and could perhaps make some things to change. But it would also require to have some moderator to verify such website, and who would take care of this? It would certainly not be a perfect solution and perhaps that people would still find a way to game that system…
Another possibility is to have some external persons that occasionally check what is happening inside the different journals to evaluate them. I think that this is something that does exist. But I do not think that it is for all journals and obviously in some journals nothing is changing over the years.
That is all for today. I just wanted to post my thoughts about this topic once again but this time by discussing also some other solutions.
I co-organize a special issue in the DSE (Data Science and Engineering) journal, published by Springer, about how data science can be used to transform how we work and live.
Guest Editors:
Yee Ling Boo, RMIT University, Melbourne, Australia
Manik Gupta, BirIa Institute of Technology and Science, Pilani (BITS Pilani), Hyderabad, India
Weijia Zhang, Southeast University, Nanjing, China
Philippe Fournier-Viger, Shenzhen University, Shenzhen, China
The planned schedule is as follows:
Submission Deadline: 30 April 2023 Expected publication: December 2023
This week, I have attended the BIBM 2022 (IEEE International Conference on Bioinformatics and Biomedicine) conference online. I will give a brief report about this conference, although I did not have time to attend many sessions.
BIBM 2022 was held from the 6th to 8th December 2022 in Las Vegas, USA and from Changsha, China. However, due to the COVID situation, attendance in Changsha has been changed to online attendance.
BIBM is an international conference for bioinformatics. Interestingly, it has been held for over 15 years while being most of the times organized either in USA or China.
A bilingual conference
BIBM is actually held partly in English and partly in Chinese. Some sessions from USA were completely in English while some session from China are completely in Chinese. But authors from USA and China could in theory watch the talks from the other location. Talks from USA could be watched using Zoom, while talks from Changsha could be watched using Tencent Meetings.
Proceedings of BIBM
The proceedings of the BIBM conference are published by IEEE. These proceedings contain regular papers, workshop papers as well as poster papers. It will be interesting for some authors that all these papers are published in the same proceedings.
The proceedings were quite large with numerous papers. It was a PDF file of over 1 GB and over 3900 pages! Luckily, the Edge browser of Windows on my computer can open such large file without problem. B
This year, there was also a good range of workshops to choose from, with over 25 workshops hosted at BIBM. So even if a paper was not accepted as regular paper, there was a good choice of workshop to choose from for publishing a paper.
Day 1 –Opening ceremonyand first keynote in Las Vegas
On the first day, I stayed up late (until 1:30AM) to watch the conference opening in the USA, which was in the US. Unfortunately, there was some technical problem at the conference site in Las Vegas and we could not hear anything during the first maybe 45 minutes. The sound came back during the first keynote, which was about bioinformatics. Due to the technical problem I did not get much information from the opening. I will try to get the slides from the opening and update this post later with the information.
Day 1 – Opening ceremonyand first keynote in Changsha
Then, after waking up, I attended the second opening ceremony for people attending from Changsha China that gave also some general information about the conference. The opening and the following keynote talks from that session were given in Chinese.
The opening was explained that some part of the registration fee will be refunded to attendees as the conference is online, which is good news. The details will be explained after the conference.
And also, from what I understood, a best paper award was announced.
Below, I show some pictures from the opening in Changsha. There was a lot of attendees (over 250 at some point!).
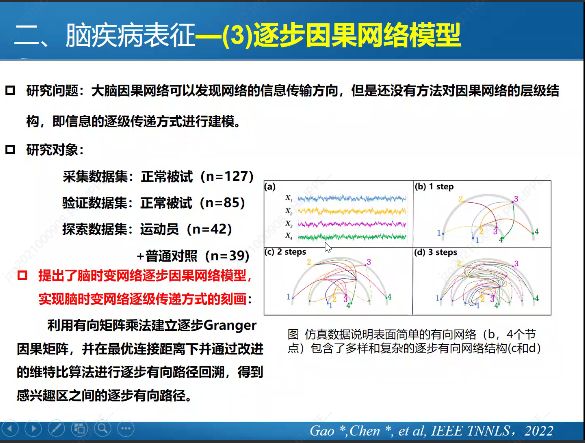
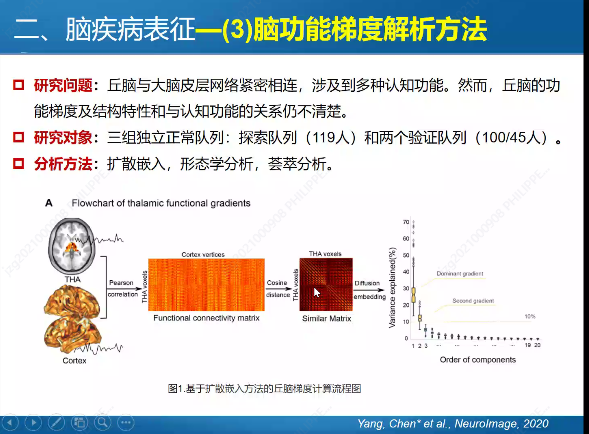
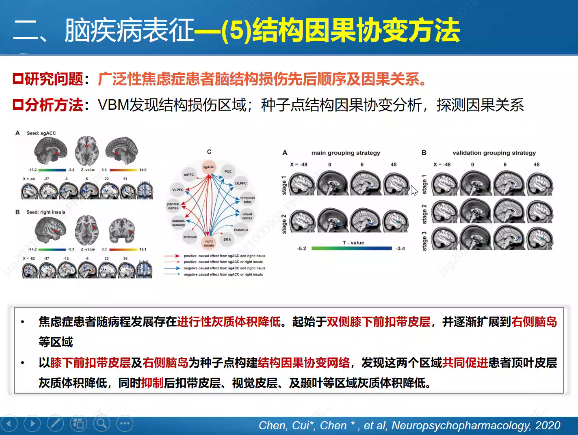
And here are a few slides from the first keynote on “Brain imaging pattern recognition methods and imaging representation of mental disorders” by Huafu Chen, which had some interesting content.
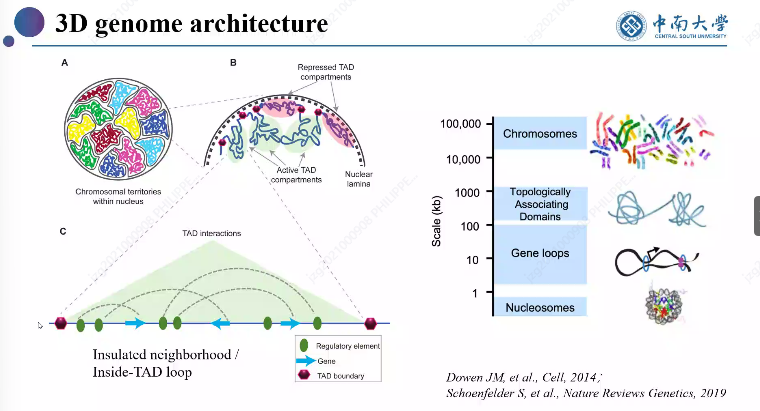
A second keynote was by Min Li about “Computational solutions to explore genomic 3D organization. Here are a few slides:
An interesting paper on sequential patterns for insurance claims
I also noticed a very interesting paper on utilizing sequential patterns with the CM-SPAM algorithm and periodic patterns with the LPP-Growth algorithm to analyze courses of medical treatment to obtain insights about anomalous insurance claims.
Kemp, J., Barker, C., Good, N., Bain, M. (2022) Sequential pattern detection for identifying courses of treatment and anomalous claim behaviour in medical insurance. Proc. of BIBM 2022.
That is a cool topic and a real application. Using the periodic patterns and sequential patterns, previously unknown anomalous claim patterns were found, which confirmed previously suspected anomalous claim pattern. Authors said that up to $486,617.60 in potentially recoverable costs were identified and a benefit of using a pattern mining approach is interpretability.
Analyzing COVID protein structures
My research team also published a paper about the analysis and classification of protein structures from COVID-19. You may read the paper below:
Although the program of the BIBM conference is good, the registration fee of BIBM is I would say very expensive at 985 USD to publish a single paper. I think this is the main drawback that I see from this conference, which would make me think twice about publishing there again (since some conferences are much cheaper). But with the refund due to the conference being online (which is expected to be around 300 USD), the price is now more reasonable.
Next year: BIBM 2023
It was announced that BIBM 2023 will be held in Istanbul, Turkey. That is a nice location.
Conclusion
This was a short blog post to talk about the BIBM 2022 conference, which I have attended. Hope it is interesting.
Today, I will give you a preview of another upcoming feature of SPMF, which will be released in the next version of SPMF (2.59). It is the Graph Viewer tool.
The Graph Viewer is a simple tool for visualizing graphs. The Graph Viewer is designed to display graphs that can be directed or undirected, and have labels. The Graph Viewer can also automatically choose an appropriate layout for visualizing a graph.
Why a Graph Viewer in SPMF? It will be used to allow users to visualize input files containing graphs and output files containing frequent subgraphs. This is useful to visualize the inpu files of frequent subgraph mining algorithms such as gSpan, cgSpan and TKG, as well as the patterns that are discovered by these algorithms (frequent subgraphs).
I have completely implemented the Graph Viewer in Java, without using external libraries so as to avoid dependencies and to make it as lightweight and fast as possible, a long-time design goal of SPMF. In fact, unlike many other data mining libraries and open-source projects, SPMF do not have any external dependencies and the code is well optimized. This ensure the stability of the project and avoid problems that could arise from relying on external libraries.
Let me now show you the current features of the Graph Viewer, which may still be updated or improved in the final release.
Opening a graph file
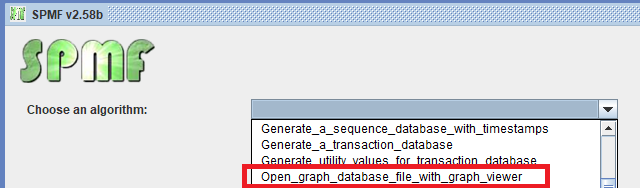
The first feature is to open an input file containing one or more graphs. This is done by selecting the Graph Viewer tool:
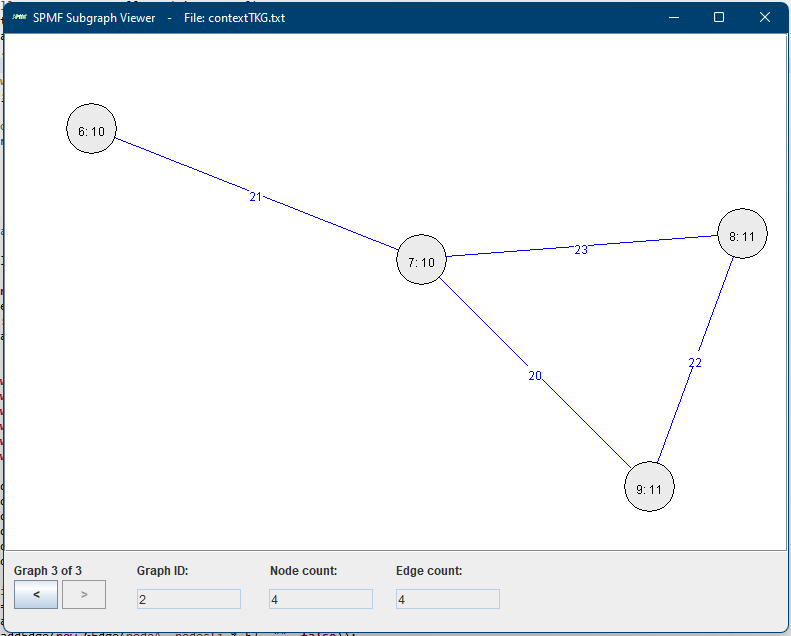
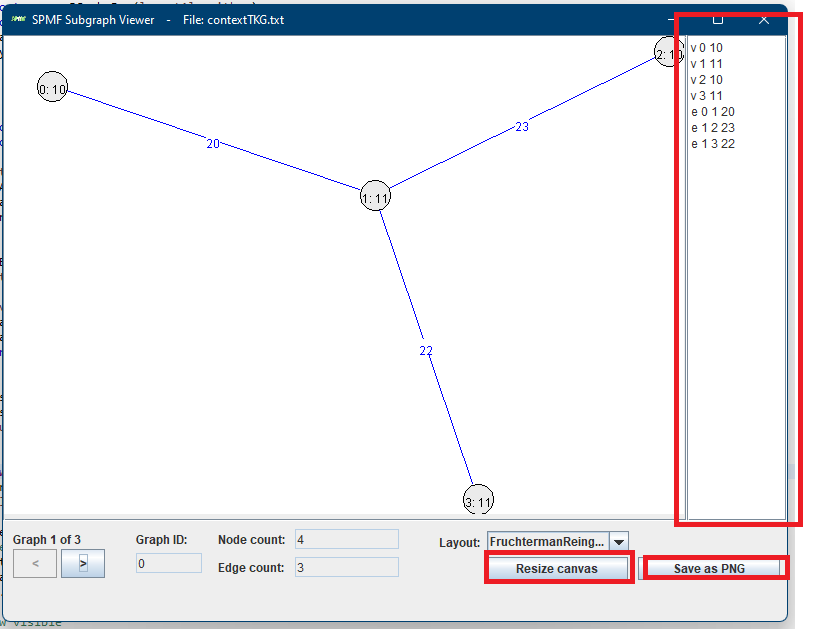
Then, let’s say that we open the example file contextTKG.txt offered in SPMF, which contains three graphs. The Graph viewer will display graphs in a window like this:
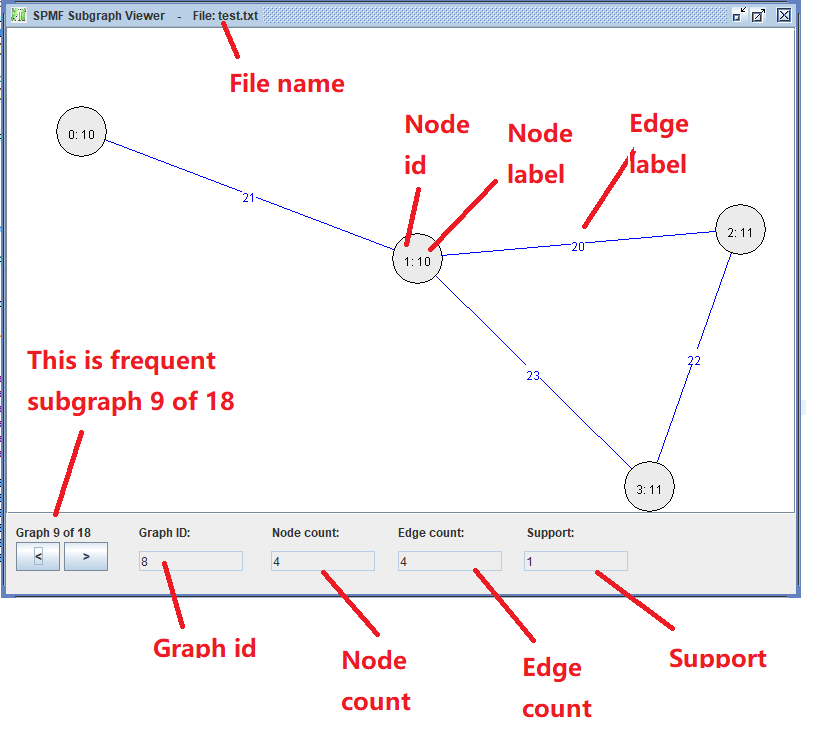
Here we see the third graph from the file. At the bottom, there are two buttons < > for navigating to the previous or the next graph. In the above picture, the third graph is shown (Graph 3 of 3). This graph has ID 3, and contains 4 nodes and 4 edges, as indicated in the bottom part of the Window. The nodes are displayed with a text of the form x:y where x is the node ID and y is the node label. Edges are displayed in blue color with their labels.
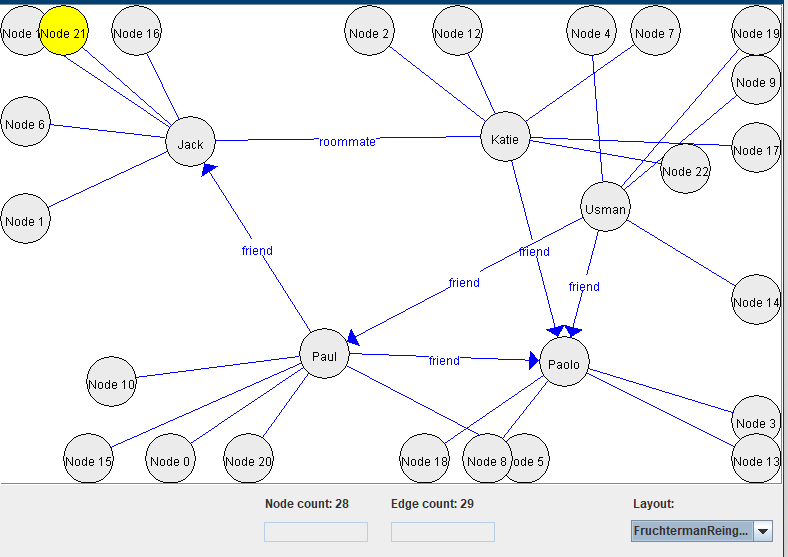
To display the graph in a pleasant way, I have implemented a forced directed graph layout algorithm, which is the Fruchterman/Reingold (1991) algorithm. It automatically places the nodes in an appropriate location so that the graph can be displayed in a beautiful way.
Opening a pattern file
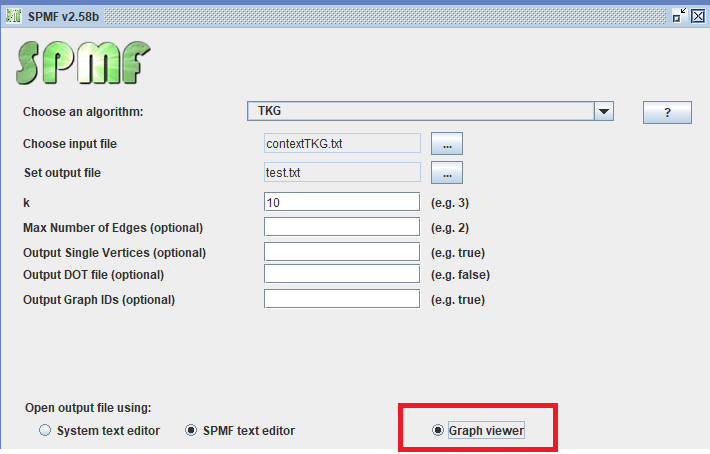
We can also use the graph viewer tool to display the frequent subgraphs found by an algorithm such as TKG. For example, here I apply the TKG algorithm and select the “Graph Viewer” tool to open the result file.
The result is 16 frequent subgraphs, which are displayed by the Graph Viewer as follows:
In the above picture, we see the frequent subgraph 9. We can use the buttons <> to move to the previous or next frequent subgraph, and thus view all of the 18 subgraphs that have been found. The support of each subgraph is displayed.
Moving the graph nodeswith the mouse
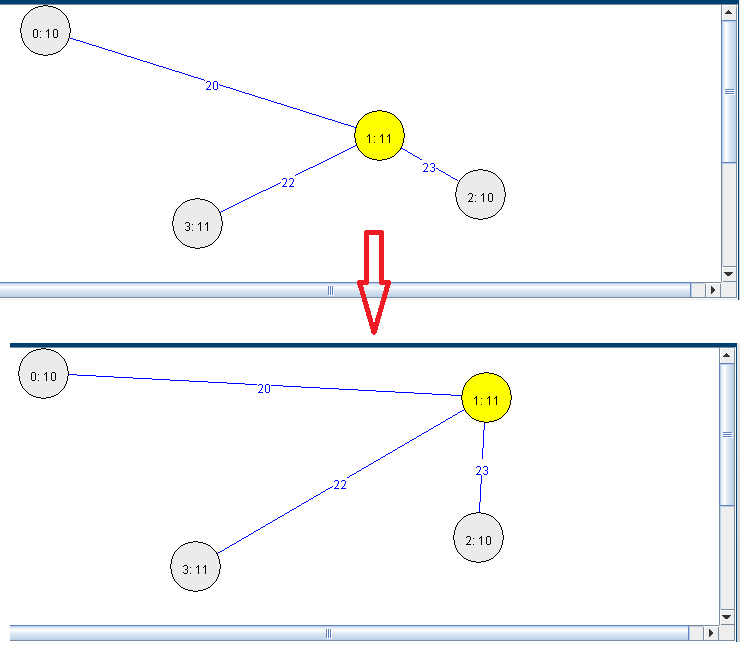
Another feature of the Graph Viewer is that we can move the nodes with the mouse by dragging them over the panel:
Running the graph viewer from the command line
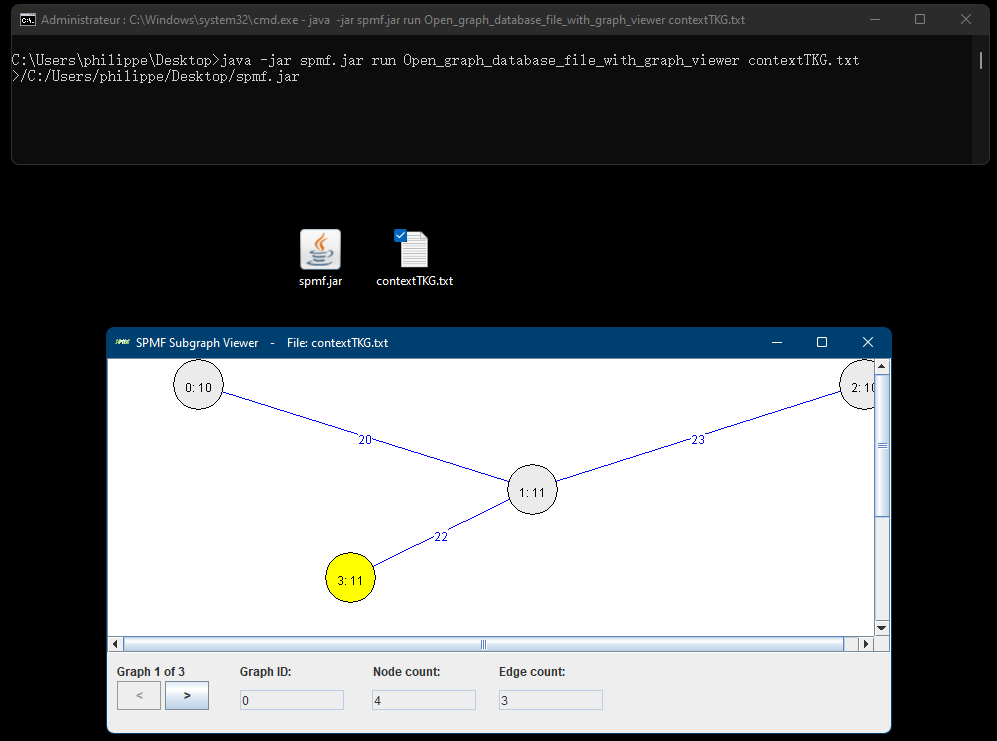
It will be also be possible to call the Graph Viewer from the command line, just like almost all algorithms and tools from SPMF. For example, if we put the spmf.jar file in the same folder as the file contextTKG.txt, we can apply this command:
java -jar spmf.jar run Open_graph_database_file_with_graph_viewer contextTKG.txt
Then, this will start the Graph Viewer to display the file:
Displaying other types of graphs
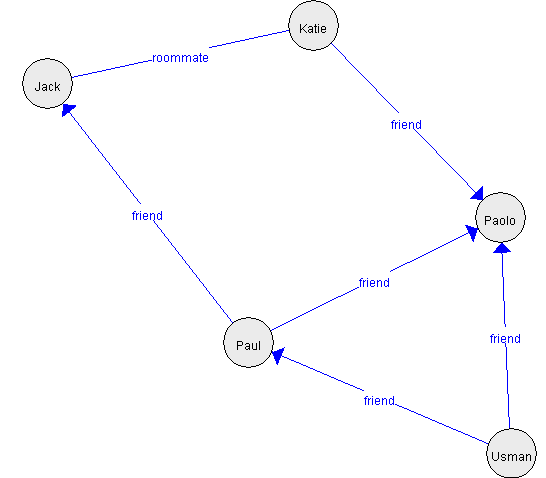
The Graph Viewer is designed in a quite general way so that it could also display other types of graphs and be used for other functions in SPMF in the future. For example, below, I show an example graph that is created programmatically rather than by reading a file.
I use this example to show the display of directed and undirected edges. Also, we can also see that the automatic layout algorithm works quite well and display the graph in a proper way. Here is another example:
In the Java code, we can also change how the nodes are displayed. I did not offer this option in the user interface as I think it is less important though. What do you think?
Update: Choosing different types of graph layout
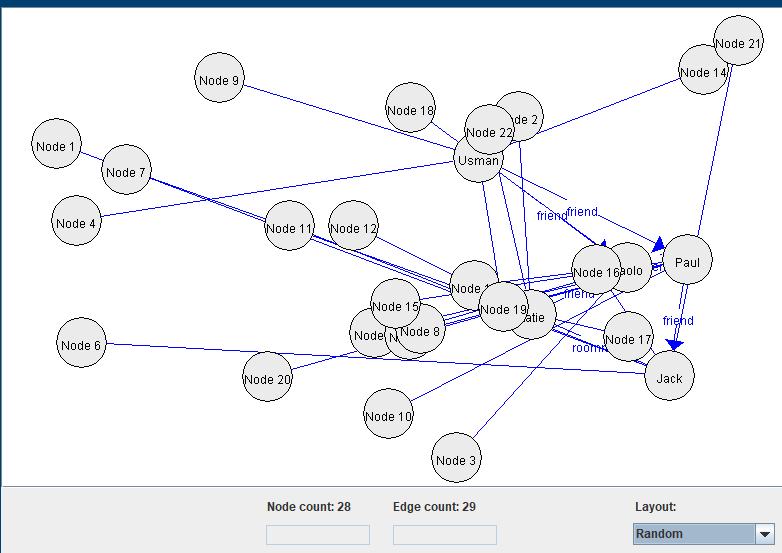
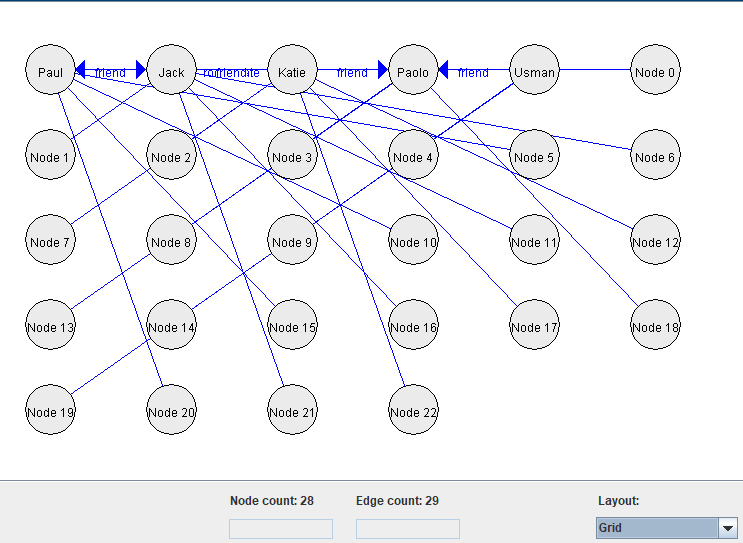
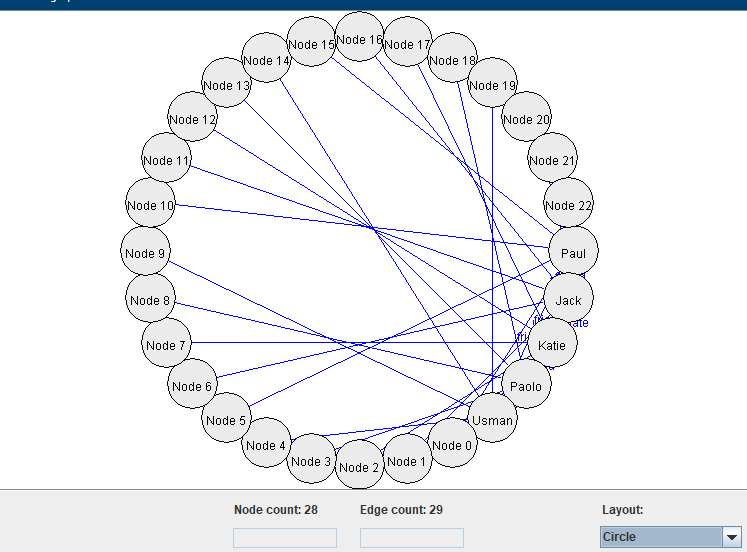
I had one hour of free time this morning, so I decided to add an option to choose different types of graph layout algorithm. For example, here we see three types of layout:
1) Using the Fruchterman/Reingold (1991) algorithm:
2) Using a random layout:
3) Using a grid layout:
4) Using a circle layout:
I might add more graph layout algorithms later. I think that these algorithms are quite interesting.
Update 2: a few more features
I have fixed some bugs and added a few more improvements. There is now a panel which can show the textual representations of graphs that are displayed (right side on picture below)). There is also a new button to save a graph visualization to PNG. Moreover, there is a button to resize the canvas so as to be able to show larger graphs.
Conclusion
Hope that this blog post has been interesting. My goal was to show you some upcoming feature, which I think will be useful for those working on frequent subgraph mining. If you have some suggestions to improve this tool, you may let me know in the comments below. I will consider them. Also, I might still improve this tool before it is released.
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.
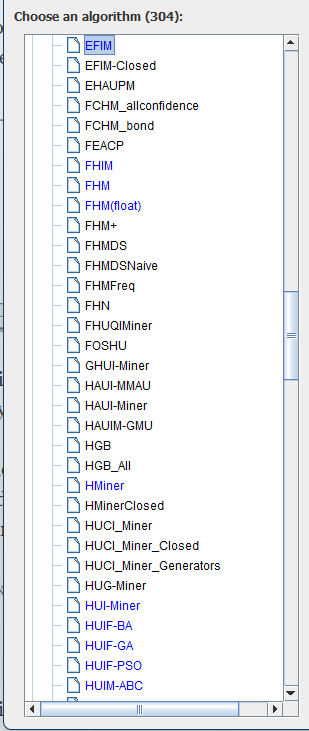
Today, I want to show you an upcoming feature of SPMF, which is a new tool called the Algorithm Explorer to explore the list of algorithms and tools offered in SPMF. It is actually a simple tool, but I think it can be useful, as there are many algorithms.
Note that this is a previewof the tool, as it will released in the next version of SPMF(2.59).
To open the new Algorithm Explorer, in the GUI of SPMF, we have to choose:
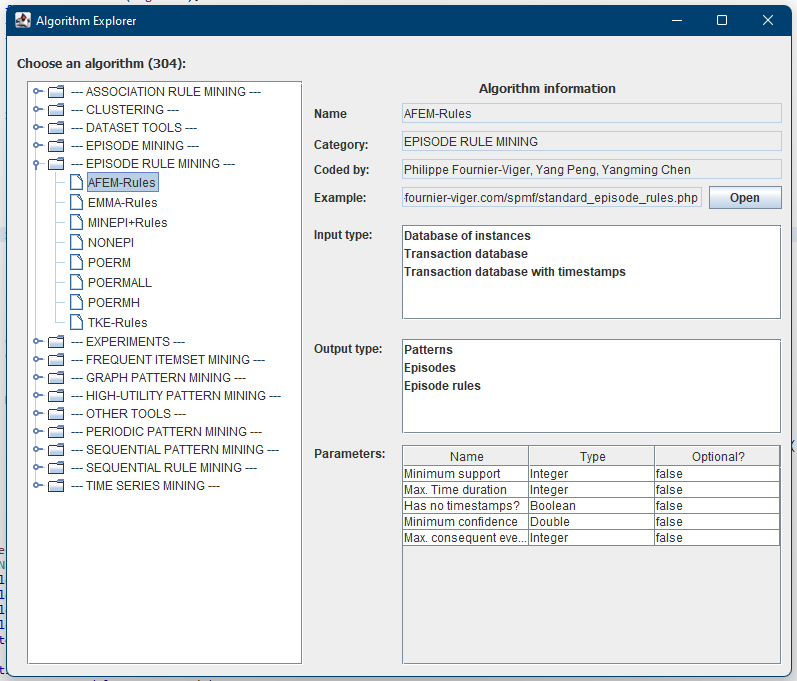
Then, this will open the new tool called Algorithm Explorer, where algorithms are shown as a tree on the left, classified by categories, and we can see information about the selected algorithm on the right:
In the above picture, we selected the AFEM-Rules algorithm. Thus, we can see the name of the algorithm, the category, the authors of the implementation, the link to the example page, the input and output types as well as the parameters.
Searching for similar algorithms
Update: I also added two buttons that allows to search for algorithms that are similar to a selected algorithm. More precisely, we can search for (1) algorithms with the same input, output and mandatory parameters, and (2) algorithms with the same input and output but that may not have the same parameters.
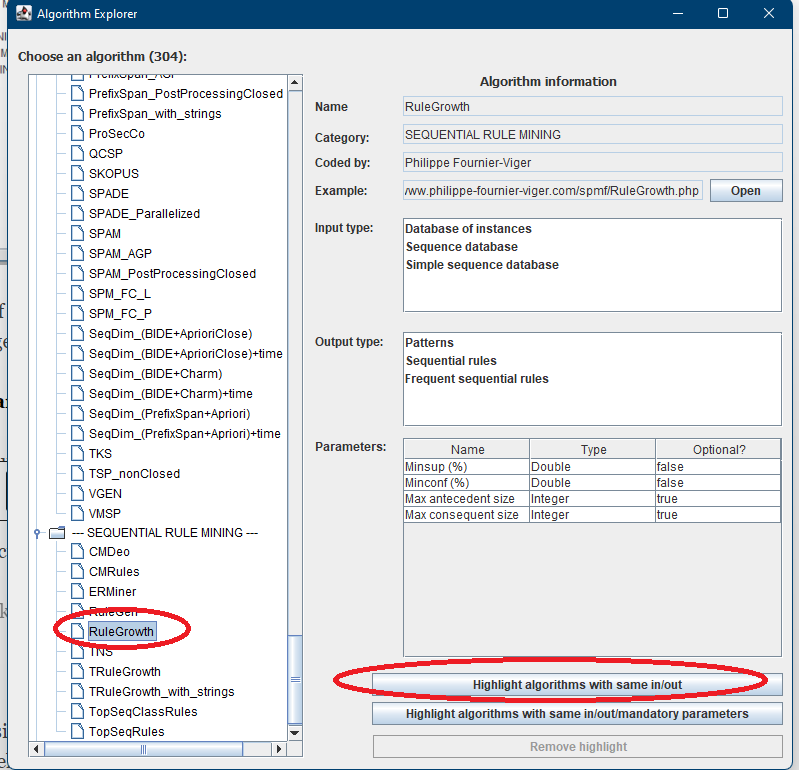
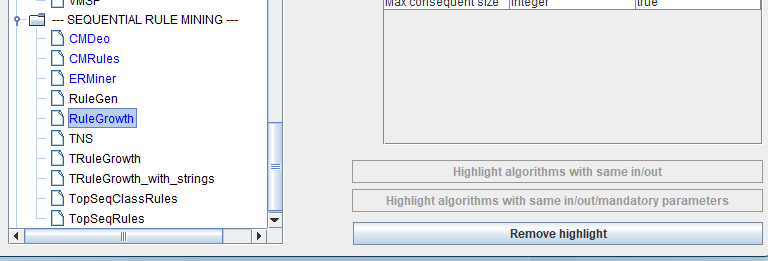
For example, if we select the RuleGrowth algorithm for sequential rule mining on the left and click on this button:
It will highlight all algorithms that have the same input and output types as RuleGrowth:
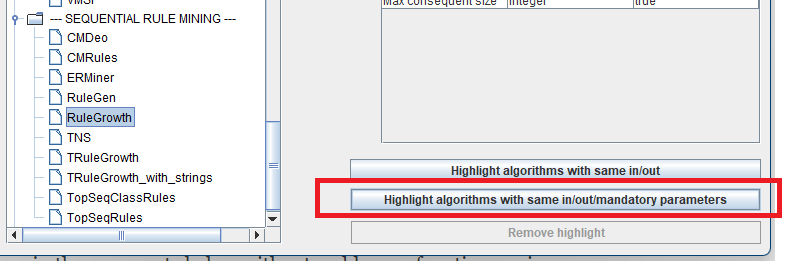
And if we instead click on this button:
It will highlight the algorithms that not only have the same input and output types as RuleGrowth but also the same mandatory parameters:
In this case, we can notice that TRuleGrowth is not included anymore because although it has the same input type and output type as RuleGrowth, it has an extra parameter that is the window length.
Let me show you one more example. Let’s say that I choose a high utility itemset mining algorithm like EFIM. Then, I can quickly find that many algorithms have the same input and output types and also the same mandatory parameters:
Conclusion
That is the current version of this tool. I will think about other potential improvements. If you have any suggestions, you may tell me in the comments below, either to add more functions or improve the user interface. I will try to take them into account, when I have time.
In this blog post, I will give a brief report about the IEEE ICDM 2022 (International Conference on Data mining), which I have attended. It started on November 28th 2022. I have attended ICDM as a workshop organizer this year and as a co-author.
What is ICDM?
ICDM is a good conference for data mining andmachine learning research. I have attended it for several years. You can see for example my reports about ICDM 2021 and ICDM 2020 on this blog. The proceedings are published by IEEE, and the conference was held offline with some online participants (for those who could not attend in person due to the pandemic).
Proceedings and acceptance rate
The proceedings were made available online to authors on the first day of the conference.
For the main proceedings, at ICDM 2022, 885 submissions were received from 54 countries. All papers were reviewed using a triple-blind process. From this, 85 regular papers and 89 short papers were accepted. Thus, the full paper acceptance rate is 9.77% and the overall acceptance rate is 20%.
For the workshop proceedings at ICDM 2022, there were 326 submissions in 15 workshops. And 135 papers (41%) were accepted.
Day 1: Workshops, but some problems
The first day was dedicated to workshops. There were many workshops on a variety of emerging topics. In particular, I co-organized the UDML workshop on utility-driven mining and learning, which is the 5th edition this year, and has been quite successful this year with about 20 submissions, 7 accepted papers, and over 20 participants.
However, on Day 1, I faced problems with the online platform that was adopted for the conference. It is Zoom Events, which can be viewed as a special version of Zoom designed to host events such as conferences with more functionalities than the basic Zoom platform. Zoom events provide a message board and a schedule of all events as well as the possibility to chat with other participants. The problems that I and other participants encountered are as follow.
First, our workshop was supposed to start at 10:00 AM but there was no “start” button to allow us to start our workshop. Thus, hours before, I sent several messages to the organizers on the platform and by e-mail, but we got no answer before the start time of our workshop. There were also a few other workshop organizers that had the same problem and were talking about how to solve the problem in the chat. As we did not receive any answer, for our workshop we decided to create a public Zoom link and send it to authors by e-mail to start the workshop on time. Then, at around 10:40, I received an e-mail telling me that I could start our workshop but we had started it already using our Zoom link, 40 minutes earlier…
Second, multiple authors from our workshop did not receive instructions about how to login to the conference before our workshop started. From 7 papers in our workshop, this affected 5 papers. So before the workshop, I receive multiple messages from authors about how to login. In one case, there was also an author who could not login because he used a different e-mail for his zoom account than for registering to the conference. And all these problems were not solved before our workshop start time. So this is another reason why we had to use a public Zoom link for our workshop.
From these problems, I think there are two lessons to learn: (1) It is better to do a rehearsal in advance with workshop organizers if a new system is used (like it was done for ICDM in Singapore in ICDM 2020, for example) to avoid issues, and (2) it would have been much simpler to just use Zoom public links instead of using Zoom events, because this latter creates problems for logging due to the restriction on e-mails who can log in.
Day 2 – Opening ceremonyand …
On the second day, I wanted to attend the opening ceremony and check the keynote talks as this is usually very interesting. However, I did not receive any Zoom Events link for accessing the second day of the conference in my e-mail. So it seems that only the first day of the conference is online. That is unfortunate but I can understand as it is supposed to be an in person conference. So that will be the end of this post about ICDM 2022.
Conclusion
This was a blog post about the ICDM 2022 conference. Hope it has been interesting. Will be looking forward to next year’s ICDM 2023 conference.
In this blog post, I will explain how to use the jpackage tool that is provided with Java to (1) package the JAR file of SPMF into an EXE file for Windows, and (2) to create an installer for SPMF.
Requirements
It is necessary to have:
A computer with Windows (as I will give instructions for this platform, but you may do something similar on other operating system)
A recent version of the Java JDK (at least version 14) so that you have the jpackage command available.
The JAR file of SPMF. You can download it here: spmf.jar or from the website of SPMF.
The ICO file of SPMF (if you want to make an application that has an icon): SPMF.ico
How tocreate an EXE application of SPMF for Windows
Step 1. On a windows computer, create two folders /input/ and /output/ on the desktop.
Step 2. Put the files spmf.jar and SPMF.ico in the folder /input/ that you have just created.
Step 3. Open the command line of Windows and execute this command:
Then, this will create an installer, which looks like this:
This is the installation process on Windows 11:
And those are the files after installation:
Customization and generating installers for other platforms
There are also many other options offered by jpackage, including generating packages for other platforms. For more information see the documentation of the jpackage command.
Conclusion
This was just a short blog post to show how to package SPMF.jar into a native application. I think the process of using jpackage is quite simple. In the past, I had used some other commercial tools to create EXE files for Java programs but the process was more complicated. I am thus happy to have found jpackage.
This is to announce that a new version of SPMF has been released on the 27th November 2022. This version has 7 new pattern mining algorithms:
the HUCI-Miner algorithm to mine closed high utility itemsets and generators at the same time (thanks to Jayakrushna Sahoo et al. for the original code )
the FHIM algorithm to mine all high utility itemsets (thanks to Jayakrushna Sahoo et al. for the original code)
the HGB algorithm to mine non redundant high utility association rules (thanks to Jayakrushna Sahoo et al. for the original code)
the HGB-all algorithm to derive all high utility association rules from the non redundant high utility association rules (thanks to Jayakrushna Sahoo et al. for the original code)
algorithms for mining sequential patterns with flexible constraints in a time-extended sequence database (eg. MOOC data)
the SPM-FC-L algorithm fi (Thanks to Wei Song et al. for the original code)
the SPM-FC-P algorithm (Thanks to Wei Song et al. for the original code)
Besides, it has several new features such as:
(1) An integrated text editor to open output file (to give an alternative to the system’s default text editor)
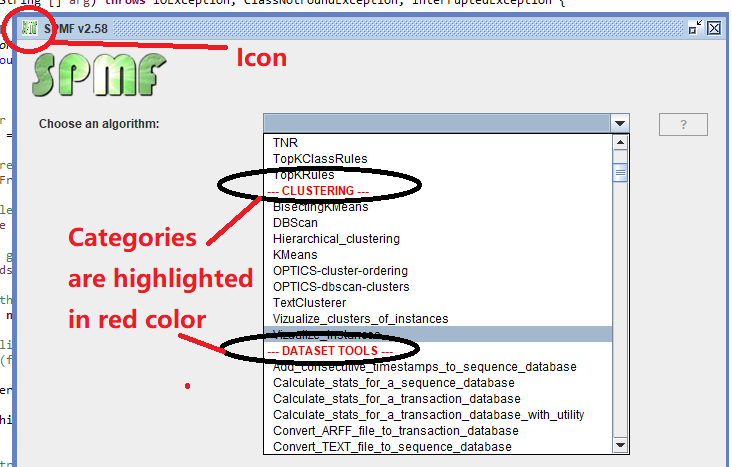
(2) Some improvements to the graphical user interface, such as shown below, such as colors to highlight algorithm categories and a window icon:
And some bugs have been fixed.
Besides a new MOOC.txt dataset of sequences of courses with timestamps has been added to the dataset page of SPMF.
Thanks again to all users and contributors to SPMF!