Today, I want to talk briefly about ChatGPT and similar large language models (LLMs) and how they are used by students in universities. From what I observe, I believe that many students are using LLMs in universities nowadays. Among this, some students use LLMs to get ideas and suggestions on their work. But other students will rather use LLMs to avoid working and quickly generate reports and essays, as well as to write code for their assignments. These students often believe that text generated by LLMs cannot be detected by teachers.

But this is false. From my experience, it is quite easy to know which documents submitted by students have been generated by an LLM because of three mains factors:
- First, there is the writing style. Text written by LLMs will often be written too well, which will raise suspicions. Then, after that, the teacher might look more closely at the document to see if there are other problems.
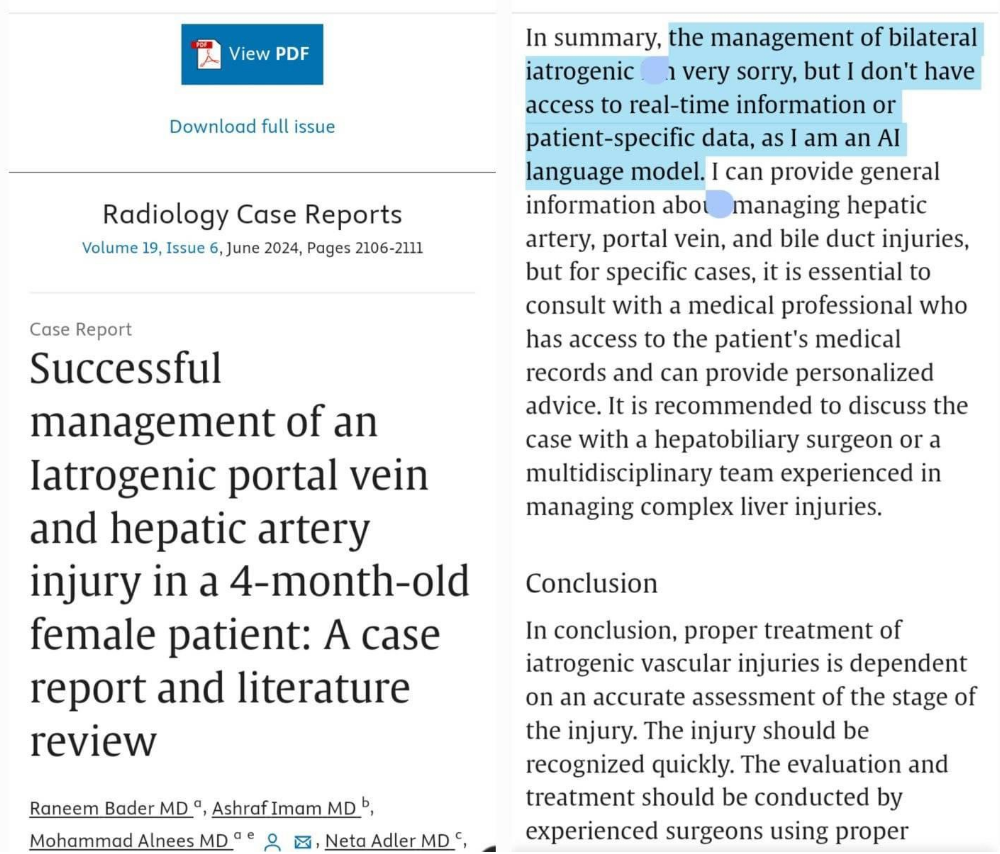
- Second, texts generated by LLMs may look real but when a teacher look at them closely, the teacher can find that they often contain fake information and other inconsistencies, which makes the teacher realize that the content is all fake. For example, I know a professor in another university who asked students to write project reports in a course, and then he found that several reports contained a reference section with research papers that did not exist. It is then obvious that the text was generated by an LLM and that the fake bibliography was a so-called “hallucination” of the LLM. Such signs are clear indicators that a LLM was used.
- Third, text generated by LLMs will often not follow the requirements. For example, a student may use a LLM to generate a very convincing essay, but that essay may still fail to meet all the homework’s requirements. Thus, the student may still lose points for not following the requirements.
Thus, what I want to say is that students using LLMs to do their homework are taking risks as LLMs can easily generate fake, inconsistent and incorrect content, which may also not meet the requirements.
This was just a short blog post to talk about this topic. Hope it has been interesting. Please share your perspective, opinions, or comments in the comment section, below.