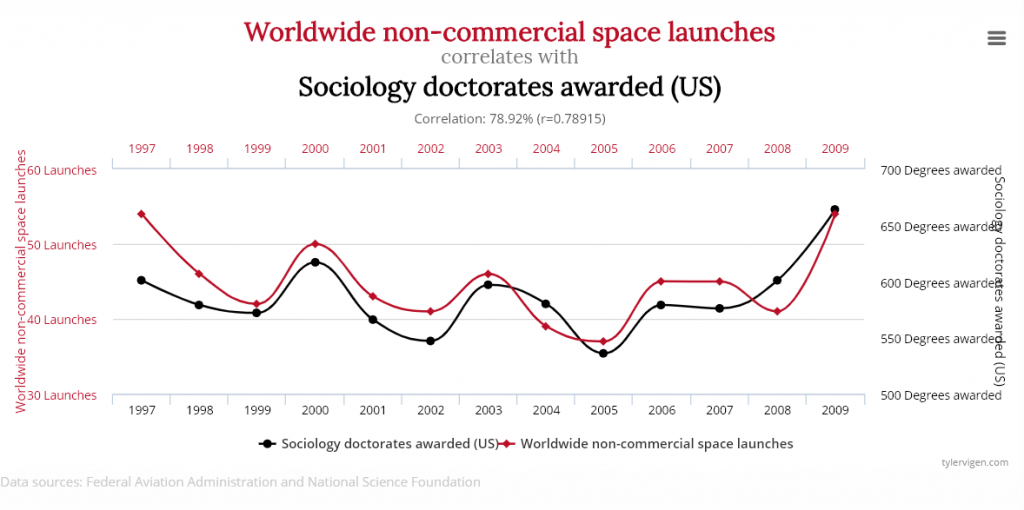
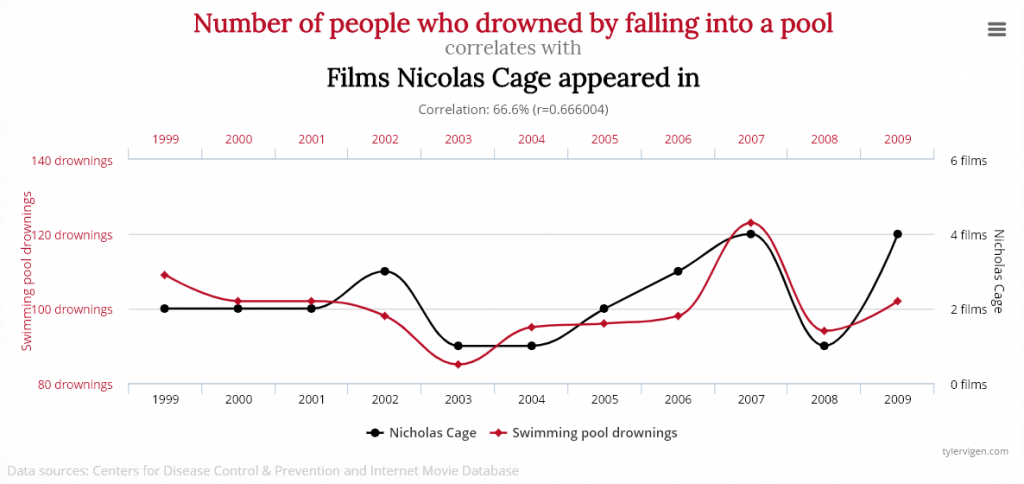
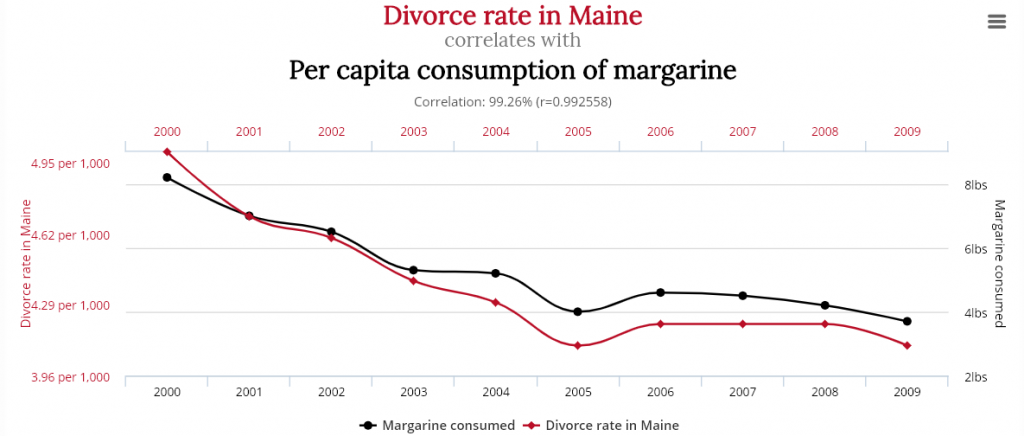
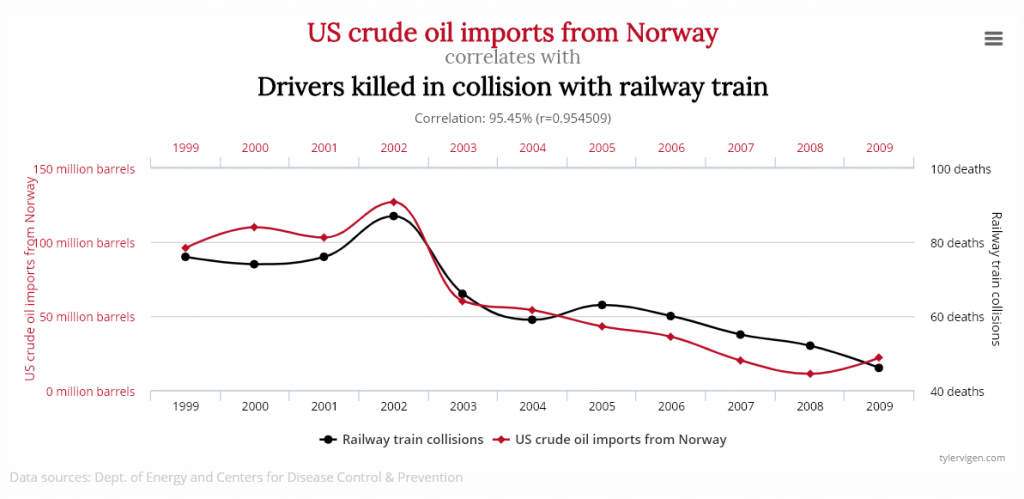
There is a well known principle in statistics that correlation does not imply causation. It means that even if we observe that two variables behave in the same way, we should not conclude that the behavior of one of those variables is the cause (or is related) to the other.
In statistics and data mining, we can calculate the correlation between two variables or time series to see if they are correlated. The range of values for the correlation is usually [-1,1] where -1 indicates a negative correlation (two variables that behave in opposite ways, 0 indicates no correlation, and 1 indicates a positive correlation. Two variables that have a high correlation may be related. But if two variables have a high correlation but are not related, they are called a spurious correlations.
To be convinced of the principle that correlation does not imply causation, I will share a few examples from a very good website on this topic ( http://tylervigen.com/ ), that lists thousands of spurious correlations.
Correlation of 0.78Correlation of 0.66Correlation of 0.99
Obviously, these correlations are totally spurious although the variables show very similar behavior. This shows the needs to always look further than just using a correlation measure.
Those are just a few example of spurious correlations. If you try the website, you can also browse various variables to find other spurious correlations.
Conclusion
In this short blog post, I shown a few examples of spurious correlations at I think it is quite interesting. If you have comments, please share them in the comments section below.
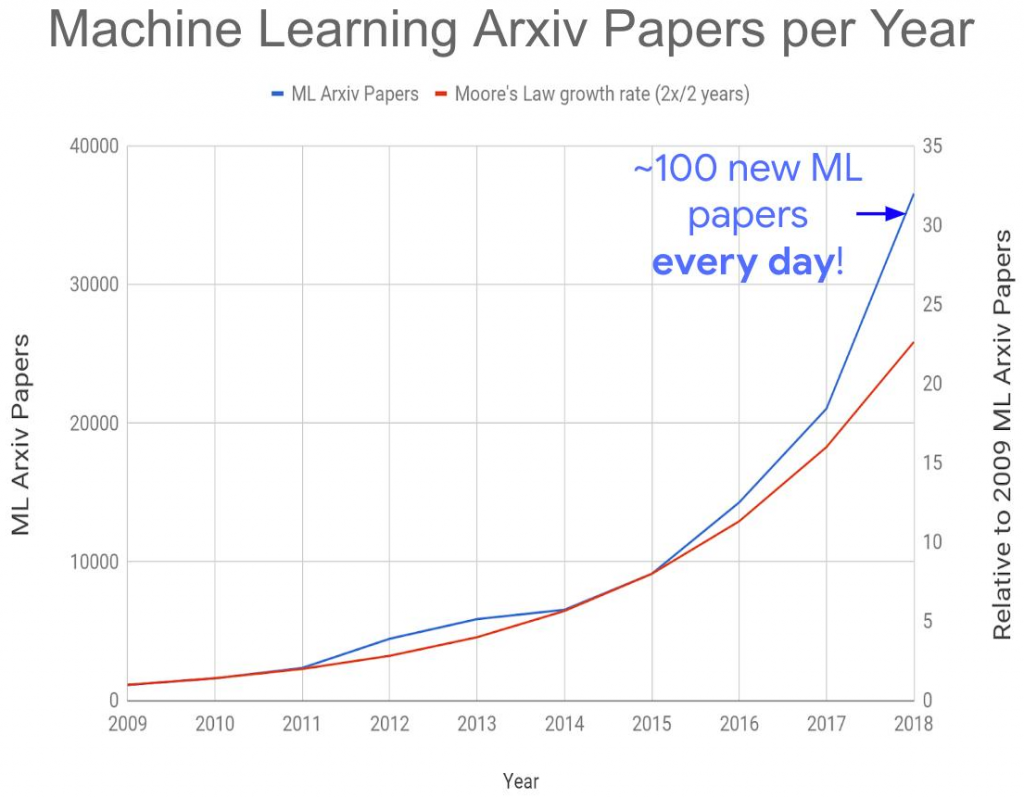
A few days ago, I have read a post on LinkedIn showing that the number of Machine Learning (ML) papers has been increasing very quickly over the last few years to about 100 ML papers per day (on Arxiv, a popular public repository of research papers).
Figure from: “A New Golden Age in Computer Architecture: Empowering the Machine-Learning Revolution” Jeff Dean, David Patterson, and Cliff Young
That is about 33,000 papers per year. This shows the excitement about the new advances in that field in particular with respect to deep learning that has lead to obtaining good results for various applications. Some people on LinkedIn wondered if there are too many ML papers and how they could keep up with advances in that field.
I will make a few comments about this.
First, in general in computer science, the papers that present a major innovation or breakthrough are few. There is always a lot of papers that make incremental advances by simply reusing ideas with some small modifications, or that just focus on applications rather than on fundamental problems. In fact, generally, few papers are highly cited while many paper receive few citations. Thus, although there may be a great increase in ML papers, one can ignore a huge amount of low quality papers. It is thus important to learn some strategies to detect low quality papers such as looking at the reputation of conferences and journals where papers are published and other criteria such as paper citation count.
Second, the large increase of ML papers result in a huge demand to review ML papers but a problem is that there is perhaps not enough experts to read those. I can share some story related to that. Recently, I have been invited to join the program committee of a good neural network conference. Honesty, I was surprised because I have never published there, and I have never made any significant contributions in that field. I have used neural networks as a tool with other techniques in an applied paper about 4 years ago but that is all, and it should not count. Thus, I tend to think that there is not enough expert reviewers and they may have invited many such as me because I work on data mining, which is related. I also noticed an increase in the number of invitation to review ML papers for journals in my mailbox. But honestly, I rarely accept these invitations because it is not much related to my research. If there is not enough reviewers though, this may just be a temporary problem.
Third, due to the increasing number of papers, some conferences on related or overlapping topics such as database or data mining start to receive many ML papers. There is generally no problem about that. But in some cases, these papers are inadequate for the topic of the conference. For example, this year, a conference that I will not name relates to databases, clearly mentioned to reviewers that if a paper is on ML and they do not understand the content or it doesn’t seem interesting to the target audience, then to not recommend these ML papers for acceptance. As always, it is important to choose a relevant conference when submitting a conference paper (for papers on any topics).
Fourth, ML has currently a lot of hype because of some excellent results obtained for applications such a computer vision and translation. Should there be so many researchers working in that area? I do not have the answer but it is a question that is worthy to be asked. For example, I know that in some university, more than 50% of graduate students are now working on deep learning. But it remains that deep learning cannot solve all the problems of computer science, and many other research areas still have complex challenges to address. Also there is always some trends in research that come and goes every few years. For example, a technique like SVM was quite popular 10 years ago but now is less than deep learning. Neural networks have also had cycles of popularity over the last forty years. As an individual, it can be good to somewhat follow the trends to take advantage of opportunities, or at least be aware of them.
Conclusion
In this short blog post, I have just shared a few comments and observations related to the ML trend. If you have other comments, please share them in the comments section below. I will be happy to read them.
In this blog post, I will discuss about the importance of an ethical review process in academia, and the problem ofunethical reviewers. I will share some stories about some unethical reviewers in journals and conferences.
Peer reviewin academia
The process of peer review in academia consists of several researchers that evaluate the work of other researchers to determine if it should be published, revised or rejected.
Peer review is important because it acts as a filter to ensure the quality of papers that are published. For conferences, the goal of peer review is also to rank the papers to select the best one to be published.
In the best case, the peer review process is fair and the best papers that are the most worthy of being published are published. But this is not always the case. One of the reason is that the opinion of reviewers is sometimes subjective. But sometimes, it is also due to some unethical behaviour. I will discuss this problem in more details.
Case 1. Reviewers who ask authors to cite their paper to increase their citation count
This is one of the problem that I see quite often in academia. It happened to me several times that after submitting a paper to a journal, a reviewer would ask me to cite 3 to 10 of his papers as a condition for accepting the paper. Of course the review is anonymous, but when the reviewer asks to cite several papers by a same author and these papers are not really related to the topic, it is quite obvious that this author is the reviewer. In an extreme case, I saw a reviewer asking to cite 10 papers, and I complained to the editor of that journal. But it did not appear to have much effect.
As a program committee member of a good conference, I once saw an anonymous reviewer who reviewed several papers, and in each of his review was systematically asking the author to cite his paper(s). This is unprofessional.
Case 2.Editor who ask authors to cite his papers or papers from his journal
Yes, sometimes, it is the editor that directly asks that an author cites his papers (!) This is surprising but it happened to me and my collaborators at least twice. In that case, the editor seemingly wants to increase his citation count. In some case, the editor also asks to cite papers from his own journal to increase its impact factor.
This type of behaviour is very serious and has lead some journals from famous publishers to be banned from journal indexes. For example, the IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS was banned from JCR (Journal Citation Report) in 2015 for “citation stacking”. A special committee was set up by the IEEE to oversee that journal and the IEEE TRANSACTIONS ON INDUSTRIAL ELECTRONICS for a similar reason ( more details here: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7812814 ).
As an author, if a reviewer is unethical, you can complain to the editor, but if the editor is unethical, then this is a difficult situation to handle. And this can happen even in journals published by some famous publishers.
Case 3. Reviewer reviewing his own papers or those of his friendsto accept them
This is another type of cheating in academia. As a program committee member of a conference, I have once found that a reviewer had created two accounts and was reviewing his own paper with a slightly different name. I then reported him to the conference organizers who banned him from the conference. This is relatively easy to detect. But it becomes more difficult to detect such problem when some person review the papers of his friends instead of his own papers. In some top conferences, I have heard rumors that some authors were doing this type of cheating.
Case 4. Reviewer rejecting papers because of a conflict of interest.
Another problem in academia is that a reviewer may reject a paper just because it is in conflict with his own research. For example, an unethical reviewer may reject a paper because he does not want someone else to publish on a topic before him. This is unethical, but it does happen, and as an author there is not much that one can do because usually reviewers are anonymous.
Case 5. Reviewer who disclose publicly an unpublished paper, or to his collaborators
A reviewer should always ensure that unpublished papers remain confidential and are not leaked to the public. But this is not always the case. I have found this the hard way around 2012, when I submitted my TRuleGrowth paper to the PKDD conference. My paper was rejected, but by searching on Google, I found that the paper that I had submitted was publicly available on the website of the reviewer. I then contacted the PKDD organizers to complain about that reviewer who leaked my unpublished paper. Then the reviewer said sorry and that he just put the paper on his webserver because he was travelling and did not expect it to appear in Google…
In some cases, an unethical reviewer will also send unpublished papers to his collaborators.
Conclusion
The peer-review process is very important in academia. Although some authors are unethical, it also happens that reviewers and editors may also be unethical. In this blog post, I have discussed several such scenarios that I have noticed or heard of. Of course, a researcher should always have an ethical behavior and avoid cheating. If you want to share your own experiences, please post them in the comment section below. I would like to hear your stories too.
The China International Big Data Industry Expo is a huge event, and the biggest related to big data in China. This year 448 companies are participating, including over 150 foreign companies such as SAS and Microsoft, and major Chinese companies like Tencent and Huawei. The exhibition space is more than 60,000 square meters and more than 1700 foreign visitors from 38 countries are attending. In previous years many leaders of the Chinese industry have also given talks at this expo such as Pony Ma and Jack Ma.
Why I attend?
It is an excellent event to connect with the industry and see the trends and recent innovations related to big data, and also to learn about new government policies. I have attended CIBD 2018 last year (report about CIBD 2018 here), and I think it was a great event. I attend as VIP guest.
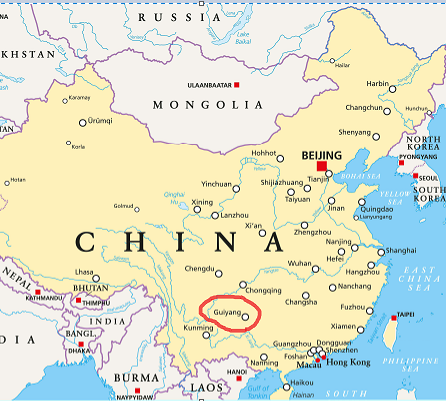
Why is it held in the city of Guiyang?
I will explain briefly. Guiyang is located in the province of Guizhou in China. Historically, Guizhou is not one of the richest provinces in part due to its location a bit far from the coast. However, a key feature of the region is its large water and electricity supply, cool weather, and it is located in a stable geological area. All these factors are highly desirable for setting up large data centers for storing big data. For this reason, it has been selected as a key city for the development of the big data industry in China. Huge government incentives are in place to transform Guiyang into the Chinese city of big data. Due to this, it has grown very fast in recent years. Numerous large international and Chinese companies have data centers in Guiyang such as Apple, Tencent, and Alibaba. It is said that more than 1600 big data companies are now operating in Guiyang, generating a yearly revenue of more than 15 billions USD. The GDP of the city is also growing very fast (increased by 10 percent last year!). It is thus a very interesting place for everything about big data. The Big Data Expo is held every year in Guiyang around the end of May.
Location of Guiyang in China
Theme: Data creates values
This year, the expo has a special theme on the applications of big data. Beside the exhibition, 49 forums, and several talks, conferences and other activities are held. Some of the topics that are going to be discussed are big data, AI, self driving cars, security, data science, 5G, intelligent manufacturing, blockchains, and smart cities.
Some announcements are also expected about new policies in Guiyang to attract talents, and the growth of the Shubo Avenue, a novel district in Guiyang for big data companies and projects that is receiving major investments.
2019 China International Big Data Fusion and AI Global Competition
On the 25th May afternoon, I attended this competition, which was held at the Empark hotel, and sponsored by Intel. The format of this competition is quite interesting with a set of 9 judges evaluating competitors, followed by an award ceremony. The judges included Prof. Jian Pei, King Wang (Tencent cloud), and others. Each competitor team had 8 minutes for presenting his project and answer questions from judges. The event was very well organized, offering simultaneous translation from Chinese to English, which makes it accessible to non Chinese speakers.
The first team was from Israel, a company called Keepod. They mentioned that 4 billion persons don’t have access to personal computing (excluding mobile devices) and the solution is not to buy a computer to each one. They instead propose to distribute an encrypted USB to each student that contains data and applications so that many people can share the same computers by just plugging their USB to a computer to work and then leave with their USB. The project is used in Cameroon and other countries.
The second team is a startup iSpace that relies on AI. They develop an advanced recovery control system and fault analysis for rockets. The system appeared interesting but the presenter spoke very fast and changed slides sometimes very quickly. In my opinion, they should have the presentation more succinct rather than try to show too much in a short time. But the technology looks great.
The third team is a company from Beijing working on AR (augmented reality). They mention that resolution of AR glasses is important. They developed prototypes of advanced AR glasses, that can have various applications such as for military. They are focused on the hardware solution and optics.
The next company is Braid (不来赛德) from Shenzhen, and relies on AI for industrial projects. They use knowledge and concept graphs, deep learning and other technologies. Some of their projects is related to analyzing transaction data from stock markets.
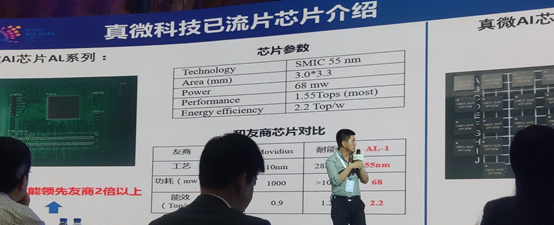
The next company is TrueMicro. They work on low power chips. One of their product is a computing stick called Movidius. One application is for traffic monitoring. They also develop chips based on RISC-V architecture for AI. They supply chips for some Huawei servers and 5G base stations. They also provide ASIC and FPGA.
The next team is Pzartech from Israel. Its goal is to provide solutions to reduce the downtime of complex mechanical systems such as engines of airplanes. In fact, if an airplane has a problem then it cannot fly until it is fixed and money is lost. The proposed solution uses image treatment, deep learning and semi synthetic data generation. A technician that repairs an engine takes a picture of a part with his cellphone to find information about the part such as its name, which greatly helps to fix a system more quickly. It is basically and object recognition problem supported by the cloud.
The next company works on IoT with 5G technology, and is named CranCloud. It works on base stations. They work on integrated solutions rather than only chips.
The next company is related to AI for smart security checks. Mostly, they have solutions for the analysis of pictures or videos based on AI, such as to analyze pictures from security checks at airports, or pictures of parcels send through mail. They use labelled data from train or subway security checks. They aim to detect forbidden objects such as lithium batteries.
The next company is about computer vision with AI. They mention that there are many applications of computer visions/ They discussed some applications such as intelligent security checks and intelligent kitchen. They propose an algorithm platform named Extreme Vision for vision recognition, which has more than 500 algortihms. Some applications are fire detection or detecting that construction workers don’t wear helmets. One of the judges mentioned that there are already many AI vision companies. The presenter explained that they provide a platform to facilitate the development of AI vision solutions.
The last company is a Shanghai based company, also working on deep learning technology for image processing and other related topics, which collaborates with Huawei, Xiaomi, Toyota and Apple. They have a transportation big data platform, and analyze data from vehicles to improve self driving cars, among other projects. They also have technology to analyze industrial parts. Their business model is to sell license for their software.
The judges then provided some general comments. One of the comment is that many teams were focusing on computer vision with AI, and solutions for this type of problems have become quite mature, and perhaps that it is important to focus on specific applications such as security checks for this type of project. Moreover, a judge was also happy to see the more fundamental research such as on chips. There was also several other comments.
The awards were then presented. Keepod, Braid, and Pzartech received some “access” awards. Three companies received a “innovation award” such as the Extreme vision platform company from Shenzhen. Finally, the top three winners were announced. The third prize was to TrueMicro, the first prize was to iSpace, and the second prize was to CranCloud. I perhaps missed a few details about the awards and may not be totally accurate.
Opening ceremony
The opening ceremony was held on the 26th May at the Guiyang International Eco Conference Center.
Several leaders from the Chinese government were present such as:
Wang Chen, Member of the Political Bureau of the CPC Central Committee, Vice Chairman of the Standing Committee of the National People’s Congress, Miaowei, Minister of Industry and Information Technology, Guo Zhenhua, Deputy Secretary-General of the Standing Committee of the National People’s Congress, Yang Xiaowei, Deputy Director of the National Internet Information Office, Rongfa, Vice-Director of the State Administration of Taxation, Xianzude State Statistics Bureau, Wang Mingyu, Vice-Governor of Liaoning Province
and representatives and CEOs from many companies.
A letter from the Chinese president Xi Jinping supporting the expo was read.
and a letter from the secretary general of United Nations:
It was mentioned during the ceremony that some goals are to support big data companies, and the recruitment of talents, how big data can support the industry, how to ensure security of the data, build core technology, how to design regulations about how data is handled.
Paul M. Romer winner of the 2018 Nobel prize of economics gave a talk. He talked about the concept of cyber sovereignty, that is that each country should be able to regulate the Internet. He mentioned that in some countries like USA, what is good for firms often take over was is good for society. The most common business model is targeted advertisement and the user often don’t know about the data they are giving. He talked about other things such as implementing big data for road networks to improve people s lives using big data.
There was then a talk by Whitfield Diffie, famous cryptography specialist and Turing award winner. He first mentioned that 5000 years ago, and now we are moving our culture in the cloud. He mentioned that computers were designed for big data, as the properties of big data such as variety have always been there. For big data, we need computers to store and process data. He defined artificial intelligence as using computers to do things that people used to do such a playing Chess, Go, translation and autonomous driving. For him the most important aspect of AI is to leverage huge amount of data to think about things that people cannot think about. He also talked about cyber-security. Information should.not.be corrupted (integrity) and we need to know the source (authenticity). Confidentiality of data is important and depends on authenticity (for example, phishing websites). Big data can be used to reduce security, But AI can give new techniques of controlling computers that may improve security. Big data security depends on the control of input data, the mining process, and the results. Big data will be everywhere in our society and its security is crucial.
He shown a quote from the Chinese president:
There was then a talk by Prof Gao Wen From Beijing University. He talked that a fourth industrial revolution may happen in 10 years, where artificial intelligence would play the key role. He talked about weak vs strong AI and that technology we have today is weak AI. He also mention that AI has evolved from coding in the 1970s to expert systems with rules in the 1980s to now deep neural nets trained using big data (in terms of trends). He mentioned that having data is key to doing big data research so working with companies is good for academia. He thinks that computer that we use today will not be able to achieve strong AI, for example the brain consumes much less energy than a computer, so we should reach that efficiency. An advantage of China is the large amount of data. Open source platforms are great for advancing technology. China would benefit from developing its own open source platforms, and having more AI specialists.
The Industry Expo
The Interactive Art Exhibition
There was also a very interactive art exhibition where people could interact with art using technology. Here are a few pictures.
The Big Data Concert
In the evening, I was invited to a great Big Data concert by the Symphony Orchestra of Guiyang.
The Belt and Road Forum
I attended the “Belt and Road” Big Data Innovation Entrepreneurship Forum. There was several guests.
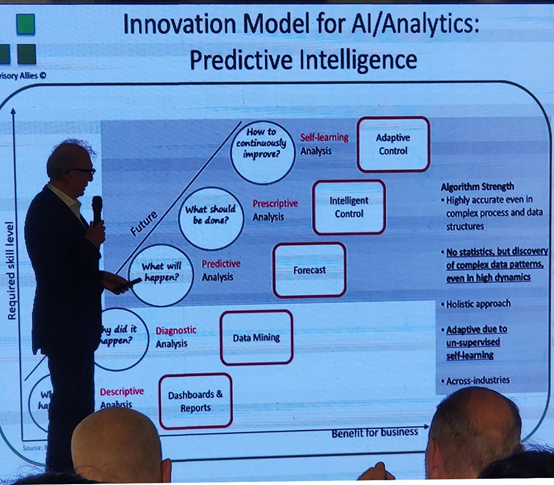
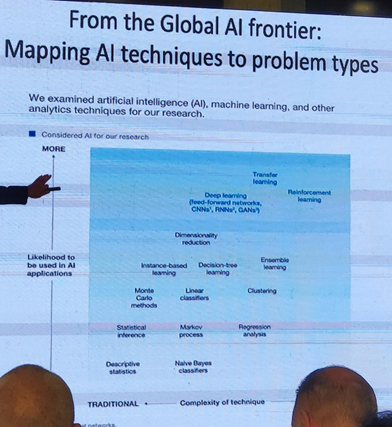
From the industry, Johannes Vizethum from Advisory Allies gave a talk about the applications of AI with big data, and about how AI can benefit to the industry. He discussed several use cases, including some augmented reality system to help repair cars. This system can recognize pieces of a car using image processing. Another system can evaluate the fatigue level or productivity of workers from video cameras. Another use case is intelligent tools for construction sites. Here are a few interesting slides related to AI:
The next speaker was Michael Eagleton and is presentation was called “Together we build prosperity”. He is now living in Shenzhen and involved in several business including his own Shenzhen Xinshunao Co. Ltd. He first talked about what is big data, and how internet is important in our daily lives. He has shown statistics indicating that 97.2% of organizations are investing in AI and big data, but it is not clear if these statistics are from China, USA or other places. He indicated that according to Wikibon the big data and analytics market is worth 49 billion $. Moreover, he shown statistics from Statista indicating that the big market is expected to grow by 20 %. He also cited Forbes/IBM, which says that data science and analytics jobs will reach 2.7 million by 2020 for the world, and that there is a gap between offer and demand, and more talents are needed on the job market. According to Domo, every person will generate 1.7 MB of data per second in 2020. He mentioned that automated analytics will be crucial in the future, and that all countries should collaborate to build the future.
The next speaker was Philip Beck and his talk was “Expand your business with Big Data”. He is an “angel investor”, who has worked a lot on marketing, and who has been living in China for more than a decade. He mentioned that for a business, some customers are more valuable (e.g. spend more money) than others, and that with big data, we can understand what characterize the most valuable customers. He mentioned how mobile payment systems like Alipay and Wechat Pay are widely used in China, and that the data collected from these systems can be used for marketing (e.g. sending targeted advertisements to some specific customers).
The next speaker was David Kovacs, director of CDSI Startup Campus Global. He first mentioned the strong relations between China and Europe. He also mention that the regulations and technology in China are suitable for innovation, and there are a lot of support from the government.
Then, there was a talk by Marian Danko founder and CEO of weHustle and TECOM Conf Startup Grind. This latter company provides a platform to connect entrepreneurs to share knowledge, experience and support each other. They also organize events for entrepreneurs to meet others.
The next speaker was Rasmus Rasmusson, Founder and CEO of VARM. They are working on a machine for people who can’t cook. It can steam, cook, fries, etc., and it is very precise and can cook many types of food. The goal is to Let the user buy a pack of food and press a single button to cook it. The machine would download a cooking program from the cloud to know how to cook the food perfectly. He mentioned that the machine can collect a lot of data about users such as what they eat and when.
The next speaker is Yoann Delwarde about turning buzzwords such as AI and big data.into business. He has a software company named Bassetti. He mentioned that 50 to 90 percent of startups fail within five years because the lack of market need or they run out of funding. He gave various advices for startups to succeed.
The last speaker was Adam Rush. He talked about opportunities from the Belt and road program, and has shown various statistics.
Banquet
In the evening there was a nice banquet at the 29th floor of the Novotel.
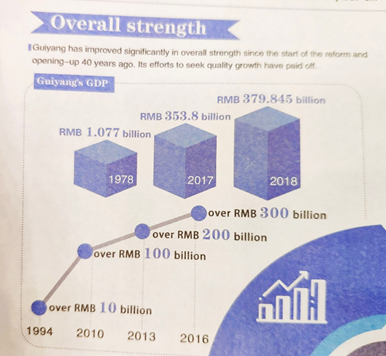
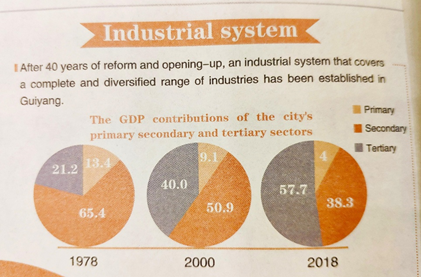
About the rapid growth of Guiyang
Here are some interesting facts about the growth of Guiyang (pictures from the Guiyang Todaynewspaper).
and it is interesting to see goals for the growth of the city for the next 15 years, announced during the Fifth plenary session of the tenth Guiyang Municipal Committee of the CPC:
Conclusion
In this blog post, I have talked about the CIBD2019 expo. It was a great event! Hope you have enjoyed reading about it! If you have comments, please share them in the comment section below. I will be happy to read them.
Today, I will talk about the review speed of academic journals. Review speed is an important criterion for selecting a journal to submit a paper when researchers face time constraints. For example, it is common that some students need to publish a paper quickly to graduate, or that a professor may want to get his research published quickly to meet requirements of a performance evaluation or just to be the first to publish some new ideas.
Before I talk about this topic in more details, it is important to know that that many aspects should be consideredto select a journal for submitting a paper such as:
the reputation of the journal in your field (a good journal will give more visibility to your work),
metrics (e.g. impact factor?, is the journal indexed by major publication databases such as EI and SCI? ranking),
is the topic of the journal appropriate for your paper and did that journal previously publish papers related to your topic?
the review speed,
the cost of publishing a paper in the journal (is it free? or is there a fee?),
is the requirements of this journal suitable for your paper (in terms of article format, maximum number of pages, etc.).
Now, let’s talk in more details about review speed. The time required to process a paper can very greatly from one journal to another, and also in different fields. For some journals, the turnaround time will be very quick, and an author may get a first decision in just a few weeks, while in some other journals, it may take several months or even a year.
Personally, I have published more than 70 journal papers, and in some cases I have waited up to two years:
This is quite long for a paper. But it can be worse. In an extreme case, some people had their paper published after 10 years:
What influences the review time?
There are several factors that can influence the review time such as:
does the editor quickly find reviewers to evaluate the paper?
does the reviewers disagree (in that case more reviews may be needed)?
does the reviewers are late or do not submit their reviews at all (in that case other reviewers may have to be found)?
how much time the journal gives to reviewers (some journal may give a few months)?
does multiple rounds of reviews are needed?
How to check the review time of a journal?
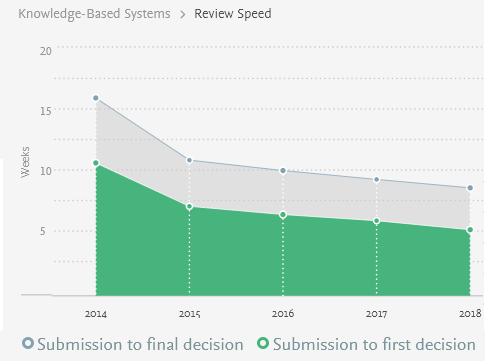
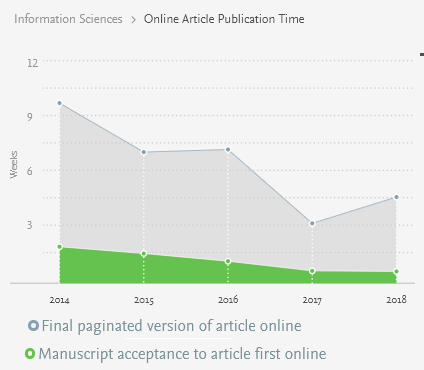
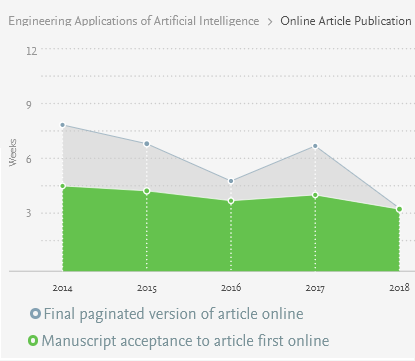
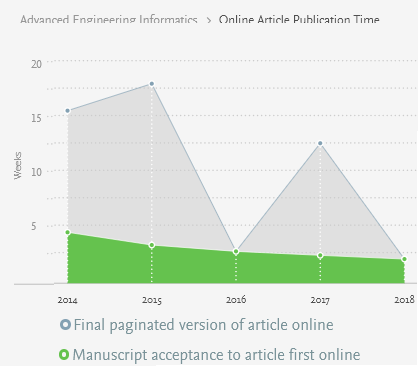
Given that review time is important, how can we know the average review time? There are several ways. First, one may contact with the editor to ask about it, or discuss with colleagues or other people who have previously published in that journal. Second, some journal will publish the average review times on their websites. This is a very useful information. For example, many Elsevier journals indicate the average review time. As example, I show below the processing times for four journals related to applied artificial intelligence, namely Knowledge-Based Systems, Information Science, Engineering Applications of Artificial Intelligence and Advanced Engineering Informatics.
As it can be seen above, the review time of journals can vary from one journal to another. Besides, it should be noted that those are average. It is quite possible to receive reviews more quickly if everything goes well, or more slowly, if there are some problems with the review process. In the above charts, it can be seen that Knowledge-Based Systems is slower than Advanced Engineering Informatics. But this is in my opinion understandable as KBS is perhaps a more famous journal, and may perhaps receive more papers. Generally, less famous journals may have faster processing times, but it is not always true.
Hope that this blog post has been interesting. If you have comments, questions, or would like to add something to this discussion, please post a message in the comment section below!
A few years ago, I decided to give a try at theMLDM 2016 conference, which I had never attended. It was not a bad conference, although quite small and the registration is quite expensive for a conference (about 650 euros). I submitted a paper to MLDM because at that time, it was still published by Springer (update: in 2019, it was not published by Springer anymore) and the timing was good.
The conference itself was not bad, but as several other attendees, I have been disappointed by the MLDM conference location, which was supposed to be New York, but was instead in Newark, New Jersey!
Why is this a problem? The problem is that Newark is about 45 minutes by train from New York. Moreover, the location of the MLDM conference was one of the worst among all conferences that I have attended. The Ramada Hotel was located in the middle of highways, and there was basically nowhere to walk around. To go to New York we had to take a shuttle back to the Newark airport to then take a 40 minute train to New York.
Because of the misleading information about the conference being held in New York on the MLDM website, some attendees even booked airplanes to the JFK airport or Laguardia airport, which are in New York, and had to travel about 1 hour by train to get out of New York to arrive in Newark for the MLDM conference. Some of those persons were quite frustrated by the location.
The real location of MLDM 2019 is in Newark
A few years later, one could expect that things have changed. I did not submit papers but I decided to check. On the 28th February, I had a look at the webpage of MLDM 2019.
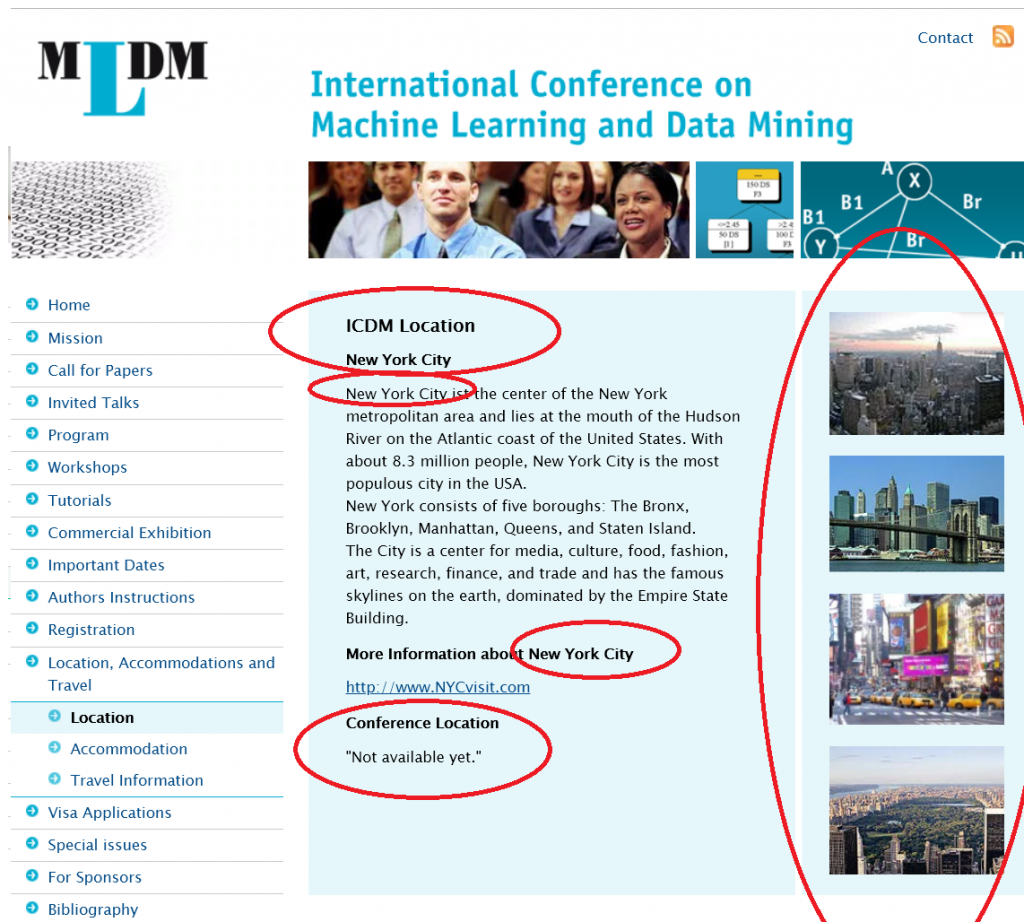
The deadline for submitting papers had passed. But the conference is again advertised as being in New York City. There are even some picture of New York on the website.
On March 14th 2019, I checked again. I clicked on the location section of the MLDM conference website, and it still advertised as being held in New York city (see below). And the exact conference location is *** not available ***.
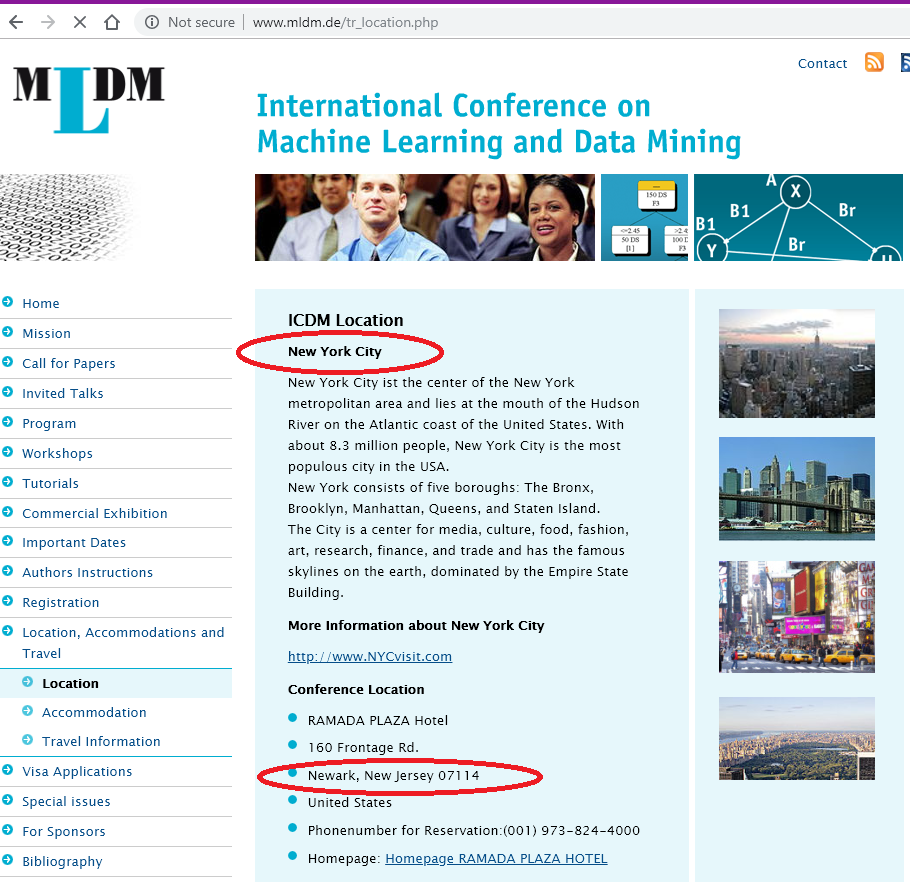
On April 19 2019, I checked again. The deadline for submitting papers has passed since a long time now. The website has been updated, and if we look carefully, it is said that the MLDM conference will be held in Newark, New Jersey rather than New York. Thus again, the conference will not be in New York! It will be held in the same Ramada Hotel as in 2016, in Newark.
It is important to note that it is written only at one place on the website that the MLDM conference will be in Newark, while “New York City” is written everywhere else on the website, and there are many pictures of New York. Thus if someone does not read carefully, it is very easy to be mislead and think that the conference is in New York. Besides, since it is announced to be inNewark after the deadline for submitting papers, authors are already somewhat committed to attending the conference, and they expect it to still be in New York.
It should be announced **before the deadline* that the conference is in Newark.
This pattern of announcing that the conference is in New York before moving it to Newark seems to be repeating itself every year since 2016. I could not find the website of MLDM 2017 and MLDM 2018 because it is offline, but the proceedings of MLDM 2017 and MLDM 2018 claim that it was in New York. However, it was probably also in Newark, just like MLDM 2016.
Conclusion
Although I do not submit papers to MLDM since 2016, I have written this blog post because I think that it should be clearly announced that the MLDM conference is in Newark rather than New York. This will avoid disappointment of attendees who have submitted a paper and expected the conference to be held in New York.
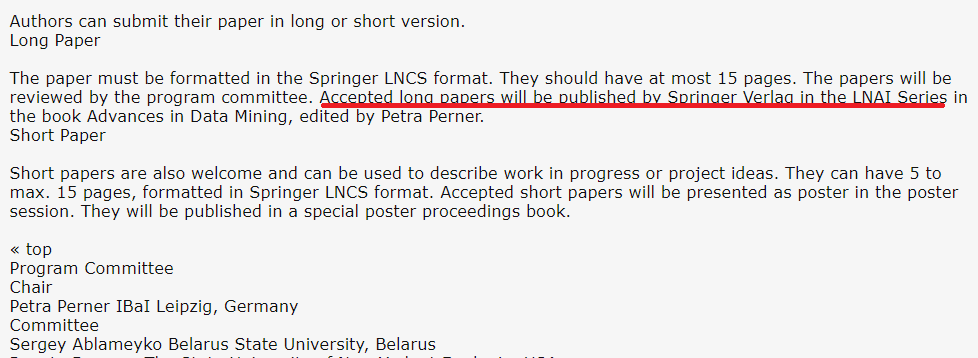
Update2020-1: Another misleading information about MLDM 2019 was that it was supposed to be published by Springer in the LNAI series (this is written for example on the CFP posed on WikiCFP). But at the conference, some authors found that the proceedings were **not** published by Springer but by a small publisher called Ibai (see some author commenting about this in the comment section below). In case that it gets removed, here is screenshot of the call for papers:
This is a video presentation of the Apriori algorithmfor discovering frequent itemsets in data. Frequent itemset mining is one of the most popular data mining task.
This year, I am attending the PAKDD 2019 conference (23rd Pacific Asia Conference on Knowledge Discovery and Data Mining), in Macau, China, from the 14th to the 17th April 2019. In this blog post, I will provide information about the conference.
About the PAKDD conference
PAKDD is one of the most important international conference on data mining, especially forAsia and the pacific area. I have attended this conference several times in recent years. I have written reports about the PAKDD 2014, PAKDD 2015, PAKDD 2017 and PAKDD 2018 conferences.
The proceedings of PAKDD are published in the Springer Lectures Notes on Artificial Intelligence (LNAI) series, which ensures good visibility for the paper. Until the end of May 2019, the proceedings of PAKDD 2019 can be downloaded for free.
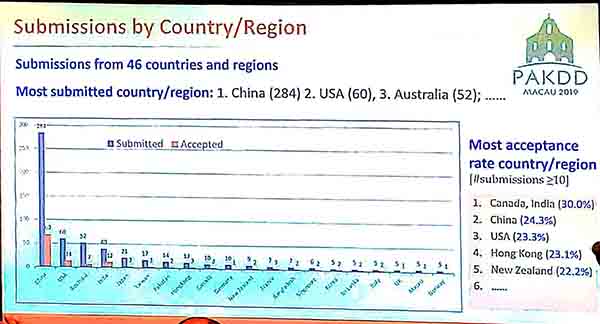
This year, PAKDD2019 received a record of 567 submissions from 46 countries. 25 papers were rejected because they did not follow the guidelines of the conference. Then, other papers were reviewed each by at least 3 reviewers. 137 papers have been accepted. Thus the acceptance rate is 24.1 %.
Location
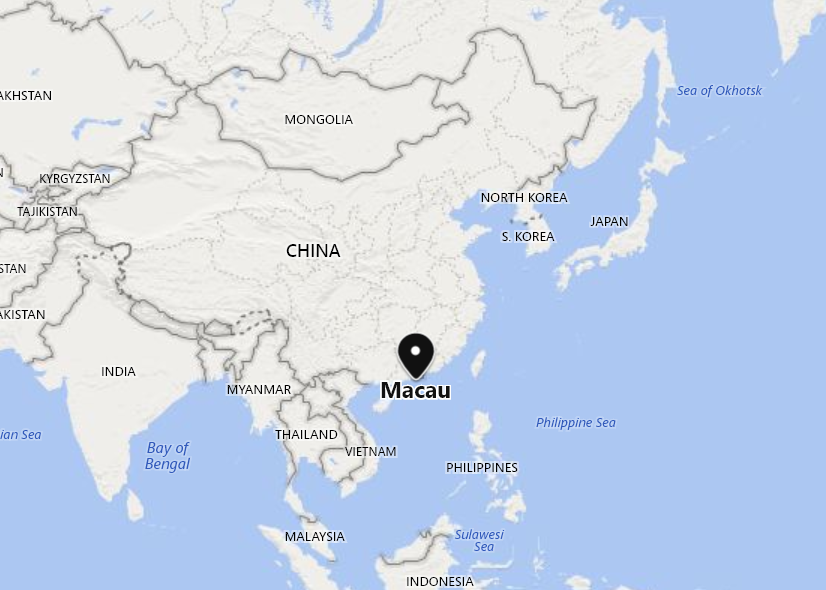
The PAKDDconference was held at The Parisian hotel, a 5 stars hotel in Macau, China. Macau is a very nice city, located in the south of China. It has nice weather and some of its major industries are casinos and tourism. Macau was once occupied by Portugal before being returned to China. As a result, there is a certain Portuguese influence in Macau.
The Parisian Hotel, Macau
Day 0: Registration
On the first day, I arrived at the hotel and registered. The staff was very friendly. Below are some pictures of the registration area, the conference bags and materials. The bag is good-looking and contains the proceedings on a USB, the program, as well as some delicious local food as a gift.
The PAKDD2019conference bagThe conference material and gift!The PAKDD2019 Registration Desk
Day 1 : Tutorial: IoT BigData Stream Mining
In the morning, I have attended the IoT Big Data Stream Mining tutorial by Joao Gama, Albert Bifet, and Latifur Khan.
IoT Big Data Stream tutorial
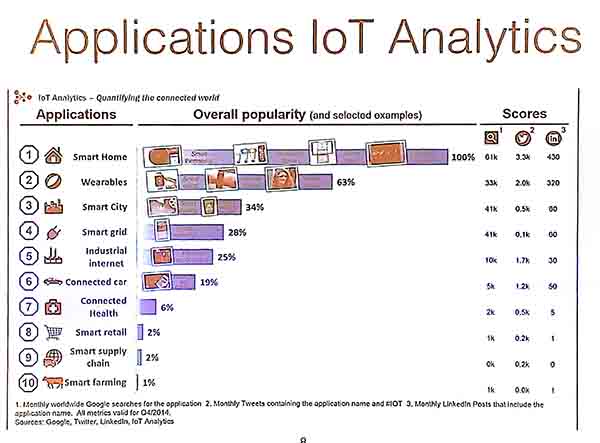
It was first discussed that IoT is a very important topic nowadays. According to Google Trends, IoT (Internet of Things) has became more popular than “Big Data”.
IoT Applications
In traditional data mining, we often assume that we have a dataset to train a model. A key difference between traditional data mining and analyzing the data of IoT is that the data may not be a static dataset but a stream of data, coming from multiple devices. A data stream is a “continous flow of data generated at high-speed from a dynamic time-changing environment”. When dealing with a stream, we need to build a model that is updated in real-time and can fit in a limited amount of memory, to be able to do anytime predictions. Various tasks can be done on data streams such as classification, clustering, regression and pattern mining. Some key idea in stream mining is to extract summaries of the stream because all the data of a stream cannot be stored in memory. Then, the goal is to provide approximate predictions based on these summaries and provide an estimation of the error. It is also possible to not look at all the data but to take some data samples, and to estimate the error based on the sample size.
If you are interested in this topics, slides of this tutorial can be found here.
Day 1: Welcome reception
After the workshops and tutorials, there was a welcome reception in the evening at the Galaxy Hotel. There were drinks and food. It was a good opportunity for discussing with other researchers. I met several researchers that I knew and met several people that I did not knew.
The PAKDD2019 Welcome Reception
Day 2: Conference Opening
The second day started with the conference opening, where a traditional lion dance was first performed.
Then, the organizers talked. It was announced that there was more than 300 participants to the conference this year.
The PC chair gave information about the conference. Here are some pictures of some slides:
Then, there was a keynote about relational AI by Dr. Jennifer L. Neville. It was about the analysis of graph or networks such as social networks.
In the evening, there were no activities were planned, so I went with other researcher to eat at a restaurant in the Taipa area.
Day 3: Keynote on Talent Analytics
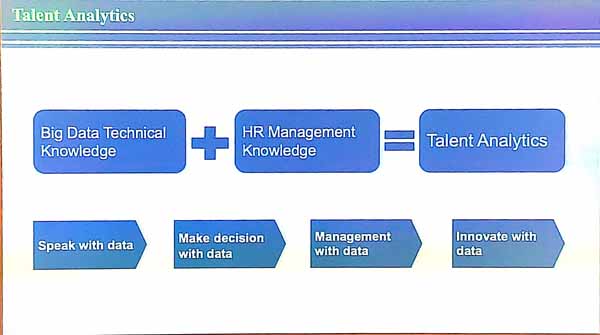
In the morning, there was a keynote by prof. Hui Xiong about “Talent Analytics: Prospects and Opportunities”. The talk is about how to identify and manage talents, which is very important for companies.
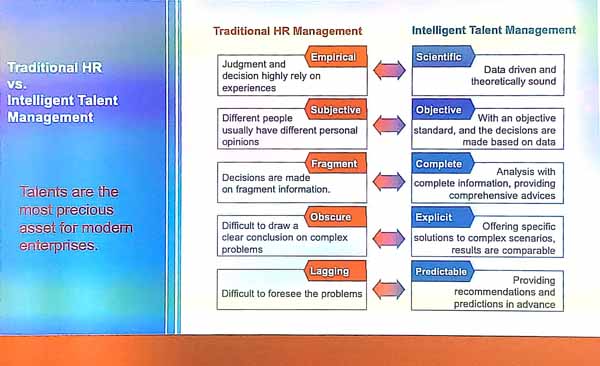
A talent is some “experienced professional with deep knowledge”. This is in contrast with personnel that do simple standardized work and have simple knowledge and may in the future be replaced by machines. Talents are team players and elite talents also have leadership. Leadership means to have vision about the current situation and what will happen in the next five years, be able to manage a team and manage risks. In terms of team management, it is important to find talents for the right positions and manage the team well.
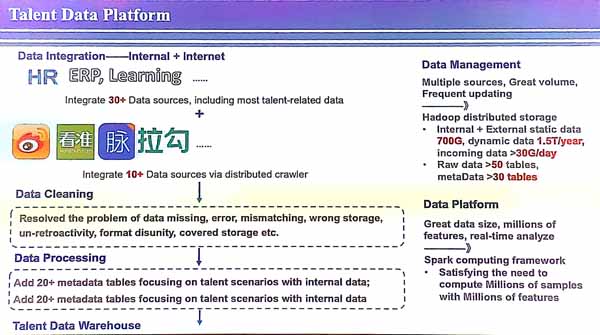
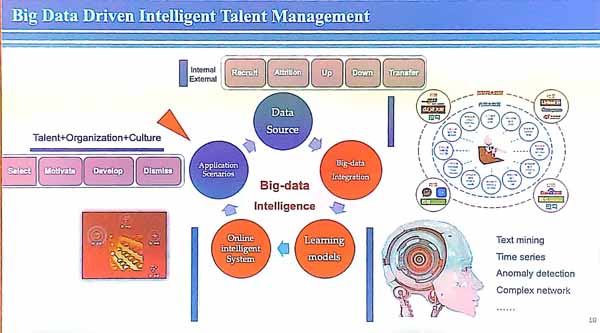
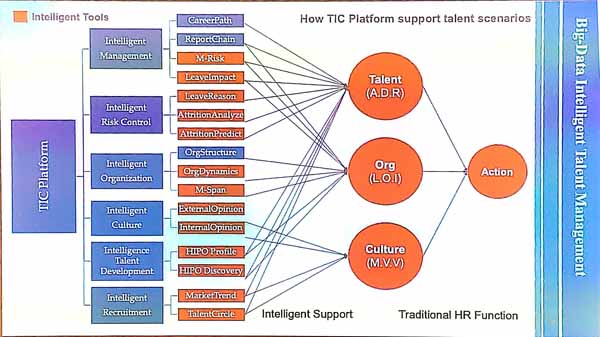
The presenter explained that intelligent talent management (ITM) means to use data with an objective, and to take decisions based on data, and to offer specific solution to complex scenarios and be able to do recommendations and predictions. Some examples of tasks are to predict when talents will leave, do intelligent recruitment, do intelligent talent development, management, organization, and risk control. Doing this well requires big data technical knowledge and human resource management knowledge.
Then, there was paper presentations.
Day 3: Excursion and banquet
In the afternoon, there was a 4 hour city tour of St. Paul Ruin, Senado Square, A Ma temple and the Lotus flower square. Here are a few pictures.
Finally, the conference banquet was held in the evening. Several awards were announced.
Ee-Peng Lim received the Distinguished Contributions AwardShengrui Wang et al. received the best application paper awardThe best Student paper award went to Heng-Yi Li et al.The Best Paper Award went to Yinghua Zhang
And there was some music and show during the banquet:
Day 4: Keynote Talk on Big Data Privacy
In the morning, there was a keynote talk by Josep Domingo-Ferrer about how to reconcile privacy with data analytics. He explained what is big data anonymization, limitation of the state of the art techniques, how to empower subjects, users and controllers, and opportunities for research.
It was first discussed that several novels have anticipated the problem of data privacy, and nowadays many countries have adopted laws to protect data. A few principles are proposed to handle data: (1) only collect data that is needed that and keep it only as long as possible, (2) let the user give specific and explicit consent, and (3) limit collected data to some purpose, (4) the process should be open and transparent, (5) the ability to erase or rectify data, (6) protect data from security threats, (7) accountability, and (8) privacy should be in the design of the system.
But it is sometimes complicated to comply with these principles. It seems to be in conflict with the use of big data.
A solution is data anonymization. After we anonymize data, it may be easier to use the data for secondary uses. Thus a challenge is to create these anonymized big data sets.
Statistical disclosure control is a set of techniques to anonymize data. It is used to reduce the risk that data is re-identified. A goal is often to anonymize the data to reduce the risks of disclosure while preserving the usefulness of the data (utility).
On the other hand, privacy-first models ensure that the anonymized data meet some minimum requirements. One of the most famous approach is called “k-anonymity“.
Other approaches are “differential privacy” techniques.
Some challenges related to privacy forbig data is to ensure privacy in dynamic data (data streams). For big data, there are methods that anonymize data locally (e.g. by adding noise or generalization) before sending them to controller.
Some limitations of state-of-the-art techniques are as follows:
There was then some discussion of some proposals for privacy preserving big data analytics. I will not report all the details. The conclusions of the talk:
Day 4 – afternoon
In the afternoon, there was a PAKDDmost influential paper award presentation on Extreme Support Vector Machine by Prof. Qing He, as well as the PAKDD2019 Challenge Award presentation.
Conclusion
Overall, this was an excellent conference. It was well-organized. I met many researchers, listened to several interesting talks. Looking to PAKDD 2020next year in Singapore.
Update: I have also written reports following this conference about PAKDD 2020 and PAKDD 2024.
This week, I have attended the 7th China International Technology Expo (CITE 2019), which was held at the Shenzhen Convention and Exhibition Center in the city of Shenzhen, China from the 9th to the 11th April 2019. In this blog post, I will give a brief overview of this fair, where various companies were showing their new products and services.
The event is organized as a fair, where companies have booths, separated by themes: (1) Smart Home, Smart City, Smart Terminal, (2) New Display, (3) Intelligent Manufacturing and 3D printing, (4) Robot and Intelligent Systems, (5) Artificial Intelligence and Intelligent Hardware, (6) IOT, Blockchain, Cyber security, (7) Automative electronics, battery, New energy, (8) Basic electronics, components, equipments and materials.
There was numerous Chinese companies as well as some international companies. And it was quite interesting to see the various products on display. The CITE 2019 fair is reasonably big but not as big as some other technology fairs in China such as the BIG DATA expo.
Below, I show some selected pictures from the CITE2019 fair:
Robot for cleaning windowsThere was many specialised machinesCurved displaysA robot fish was swimmingRobots for assembly linesAnother assembly line robotMore displays including on transparent glassesLED displaysMore machinesMultiplayer virtual reality games3D printers were also on displayThere was many types of robots for kids and homeRealistic looking robots that can move8K displaysFlexible displaysSome of the booths at CITE2019
Conclusion
This was just a short blog post to give a glimpse of this event. I think it is quite interesting to attend such event to see what is happening in the industry. Hope you have enjoyed reading this blog post about CITE2019. If you want to get notified about next blog posts, you can follow me on Twitter at@philfv.
Today, I will list a few useful mailing lists related to data mining and big data. Subscribing to these mailing list is useful for PhD students and researchers, as many jobs, conferences, special issues and other opportunities are advertised on these mailing lists. It is also good to post your own announcements for jobs, call for papers, etc.