the HUIM-ABC algorithm for approximate high utility itemset mining using Artificial Bee Colony Optimization (thanks to Wei Song and Chaoming Huang for contributing the code)
the TKG algorithmfor mining the top-k frequent subgraphs in a graph database (thanks to Fournier-Viger, P. and Chao Cheng)
the gSpan algorithm for mining the frequent subgraphs in a graph database (thanks to Chao Cheng)
the SPP-Growth algorithm for mining stable periodic itemsets in a transaction database (by Peng Yang)
the MPFPS-BFS algorithm for miningperiodic patterns common to multiple sequences (by Zhitian Li).
the MPFPS-DFS algorithm for miningperiodic patterns common to multiple sequences (by Zhitian Li).
the NAFCP algorithm for mining frequent closed itemsets (thanks to Nader Aryabarzan et al.)
the OPUS-Miner algorithm for mining self-sufficient itemsets (thanks to Xiang Li for converting the original C++ code to Java)
It also includes some bug fixes and other minor improvements.
I did not release a new version of SPMF since a few months because I was quite busy recently. But the SPMF project is still very active. I am currently working on preparing a few more algorithms for release. I will try to make the next release in November.
Also I would like to say thanks again to all the persons who have contributed, used, cited, and supported the software! This is really helpful! Moreover, all contributions are always welcome.
This week-end, I am attending the 2019 World Conference on VR Industry (WCVRI 2019) as an invited guest and panel member (on Monday). In this blog post, I will talk about this event, held in Nanchang, China from the 19th to 21st October at the Primus Hotel.
WCVRI is an international event focused on the industry that has both an exhibition part with booths from large companies, and also various forums, speeches, and talks. This event is held for the second year, and it is every year in the city of Nanchang, as it is a hub for virtual reality technology in China.
This year, the main theme is “VR+5G for a new era of perception“. Some key topics of the conference program are Cloud, Industrial Ecology, AI, XR technology, Film and television, Manufacturing, Education and Training, 5G, Deep learning and mixed reality, Anime, Investment, Talent development, Virtual Simulation, and Security and production.
Nanchang is the capital of the Jiangxi province. There are about 6 million people living there. The Gan river flows through the city.
Nanchang, Jiangxi province, China
This is a major event in the city. The event is announced everywhere, which shows the strong support of the government for this event. Here is a sign in front of the Tengwang pavilion, a popular tourist spot.
Opening ceremony
The opening ceremony was held on the morning of the 19th October. The governor of the Jiangxi province was the first to talk during the opening ceremony. There was then other government representatives who talked, including the secretary of the party of the Jiangxi Province Liu Qi, the secretary of the leading party members’ group of industry and information technology Miao Wei, and the Vice Premier of China, Liu He.
It was said that he electronic industry grows by 30% every year in Nanchang, and VR is an important part of that. VR is a key project of the city that may contribute to many other industries such as manufacturing. The city is trying to attract world-famous talents and entrepreneurs in Nanchang, as well as projects and funds.
The organizers of the conference read a congratulatory letter that they received from the President of China, Xi Jinping, which highlights the support of the national government for the VR industry and this event.
The Vice Premier Liu He mentioned that he is very pleased to attend the event and would like to take the opportunity to exchange with people from the industry. He mentioned the importance of VR in the gaming and movie industry and that it can be used other areas such as manufacturing, medical services, and tourism. He also mentioned the importance of fundamental research to develop ground-breaking technologies, and enhancing education to produce a greater number of talents. He mentioned that the Chinese economy is moving in recent years from a phase of rapid development to a phase of quality development. Finally, he wished the industry and this event a great success.
Vice Premier Liu He
There was also an official signing ceremony between the leaders of Huawei, Inspur Group and the government of Jiangxi Province.
Keynote speech by Guo Ping, rotating chairman of Huawei
There was a keynote talk by the rotating chairman of Huawei Guo Ping. He said that VR provides a better experience than watching videos on mobile devices, and is more immersive than TV. Thus, VR may be the future of entertainment at home. He said that new generations of networks such as based on 5G are important to support a good VR experience. Latency must be low, data must not be lost, etc. Moreover, content delivery is important for VR, and thus having a fast and reliable cloud environment is important to deliver this content. Huawei has developed equipment and cloud computing technologies to support these requirements.
Talk by Guo Ping
Keynote speech by Martin Hellman, Turing Award Winner
Martin Hellman, a Turing award winner also gave a talk. He first reminded us of the importance of public key cryptography to protect financial transactions, and that this technology it key to e-commerce, and the blockchain. He then explained the principles of public key cryptography. I will not explain this here but it was quite interesting to listen to the presentation. Below is a picture where he explains that he wants to send a message to his collaborator but that his wife Dorothée may read the message if it is not encrypted (interesting example)!
Talk by Martin Hellman
During the first day, there was also several other keynote speeches, including by the CEO of HTC, the Vice president of SAP China, and the Chief Scientist of Inspur. I will not report the details of these talks here.
Industry Exhibition
In parallel to the sessions, forums and talk, there was an exhibition by the VR industry with booths from hundreds of VR related companies. It was possible to try various VR-related products and also to see related applications and technologies such as 360 degrees cameras, motion capture equipment, augmented reality software and devices, 5G equipments, and drones. There was a lot of applications of VR related to gaming. A few pictures of the industry expo are below:
Talent development forum
On Monday, I participated as a speaker at a round table of the talent development forum, organized in the WCVRI 2019 conference. This forum was well-organized, and invited several experts for presentations, discussion, and there was also some official signing ceremony. I talked for a few minutes about the importance of international collaboration and talent development for the virtual reality industry, and programs related to talent development.
Conclusion
I am now back in Shenzhen, China. The event has now ended and it was a great event that I would recommend for anyone interested in virtual reality and related technologies. I have greatly appreciated the work of organizers and volunteers that have been very helpful. I am looking forward to attend this event again in the future.
This year, we are in 2019, and it is already 25 years since Agrawal wrote his seminal papers on frequent itemset mining and association rule mining in 1994. Since then, there has been thousands of papers published on this topic, some about algorithm design, new pattern mining problems, and others about applications in a multitude of fields. And there is still many research issues to work on!
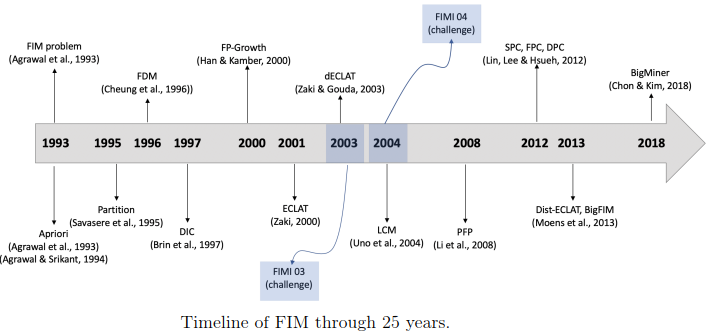
After all these years, it is a good time to look back at what has been achieved to get a new perspective. This is what I did recently with colleagues in a survey paper called “Frequent Itemset Mining: a 25 Years Review“. If you are interested by frequent pattern mining, I encourage you to read the paper, as it makes some interesting observations. For example, it is found that some ideas used in recent algorithms for mining patterns in big data can be traced back to some of the early algorithms. Here is a picture from the paper showing a timeline of key algorithms and events in frequent pattern mining:
This week, I am attending the DAWAK 2019 and DEXA 2019 conferences in Linz, Austria from the 26th to the 29th August 2019. In this blog post, I will provide a report about these conferences.
About the DAWAK and DEXAconferences
DAWAK ( Intern. Conf. on Data Warehousing and Knowledge Discovery ) and DEXA ( International Conference on Database and Expert Systems Applications ) are well-established conferences related to data mining and database systems. This year, it is the 30th edition of DEXA, and the 21st edition of DAWAK. These conferences are co-located and held in Europe.
The proceedings of DEXA and DAWAK are published by Springer in the LNCS (Lecture Notes in Computer Science) series, which ensures that it is indexed in all major databases (EI).
DEXA 2019 received 157 submissions, and 32 were accepted as full papers (acceptance rate of 20%) and 34 as special research papers.
DAWAK 2019 received 61 submissions, and 22 were accepted as full papers (acceptance rate of 36%).
Location
The conferences were held at the Johannes Kepler University of Linz, Austria. The city of Linz has some old buildings and streets, some hill, and the Danube river passes through the city. Holding the conferences in a university is fine. However, the drawback is that the campus of the university is located about 5 km from the city center.
Registration
On the first day, I registered for the conference, and everything went smoothly. The registration started at 12:00 AM, which gave plenty of time for arriving at the conference. Some drinks were served but there was no lunch. The conference bag contains the program, proceedings on USB as well as a few papers and tickets for lunch and other activities.
Keynote by Vldimir Marik “AI in manufacturing”
The first keynote was by Prof V. Marik from Czech Technical University. He talked about how AI can be used in manufacturing. He mentioned that there is a lot of expectations about AI in recent years, and AI has the potential to improve production efficiency and develop new business models. He talked about Industry 4.0, and concepts such as augmented reality, internet of things and services, multi-agent systems, and using robots in production facilities.
Welcome reception
On the first day, there was a welcome reception at the university where the conference was held.
Keynote by Axel Polleres about the semantic web and linked data
There was a keynote by A. Polleres about the Semantic Web. It first talked about how the concept of Semantic web has evolved from the idea of Tim Berners Lee in early 2000. Initially, the main idea was to use description logics to annotate Web content with ontologies to perform reasoning about the Web content. Some of the key results from 2000-2009 was that researchers have found which logics are decidable and scalable. A question was also how much reasoning do we really need for the web? and how can one publish knowledge on the Web? To publish data on the Web, it was proposed to use technologies such as URI and RDF to create what is called (open) linked data.
The speaker also mentionned that some lessons learned is that the OWL standard is perhaps too complicated for users (which I agree), and RDFS is among the most used standard. Also in practice, ontologies may contain inconsistencies. The speaker then talked about a prototype semantic web search engine that was created, and how there is more and more open data published by organizations such as governments, and also now there is open data portals to find open data.
The speaker talked about the Knowledge Graph of Google and how we don’t know exactly how it works but it may be related to work on Semantic Web and linked data, and it is used for question answering and showing related data to queries. Then, there was more discussion, but I will not report everything about the talk.
Keynote talk by Dirk Draheim “Future Perspectives of Association Rule Mining Based on Partial Conditionalization“
There was a keynote talk about association rule mining by Prof. Dirk Draheim from Estonia. He first indicated that data can be often misleading, and we may draw wrong conclusions if we don’t have enough data or don’t look at all the data. He mentionned the Simpson Paradox and that if we have more data or more information about the context, we can better understand the data. For example, although the average salary in Seattle may be higher than the average salary in Boston, it does not mean that people in Seattle really earn more than those in Boston, because in Seattle more people may be working in the IT industry and have high salary, which increases the average, but at the same time people in other industries in Seattle may be earning less than in Boston.
Prof. Draheim then suggested that we need to use other interesting measures and also consider probability theory. We can reformulate the problem of association rule mining using that theory and see a transaction database as a probability space. He then explained his idea, which I will not report all the details here. I think it is an interesting idea to use more statistics in pattern mining, and it is not the first work that goes in such direction (e.g. work on self-sufficient itemsets by Webb et al. uses statistical testing in pattern mining).
Banquet
On the evening of the third day, the conference banquet was held on a boat on the Danube River.
This year, several papers about pattern mining
I was pleased to see that there was many papers on pattern mining (e.g. itemsets, sequential patterns, association rules) this year such as:
Philippe Fournier-Viger, Jiaxuan Li, Jerry Chun-Wei Lin, Tin Truong-Chi: Discovering and Visualizing Efficient Patterns in Cost/Utility Sequences. 73-88
Philippe Fournier-Viger, Chao Cheng, Zhi Cheng, Jerry Chun-Wei Lin, Nazha Selmaoui-Folcher: Finding Strongly Correlated Trends in Dynamic Attributed Graphs. 250-265
T. Yashwanth Reddy, R. Uday Kiran, Masashi Toyoda, P. Krishna Reddy, Masaru Kitsuregawa: Discovering Partial Periodic High Utility Itemsets in Temporal Databases. 351-361
Hieu Hanh Le, Tatsuhiro Yamada, Yuichi Honda, Masaaki Kayahara, Muneo Kushima, Kenji Araki, Haruo Yokota: Analyzing Sequence Pattern Variants in Sequential Pattern Mining and Its Application to Electronic Medical Record Systems. 393-408
Joe Wing-Ho Lin, Raymond Chi-Wing Wong: Frequent Item Mining When Obtaining Support Is Costly. 37-56
Parul Chaudhary, Anirban Mondal, Polepalli Krishna Reddy: An Efficient Premiumness and Utility-Based Itemset Placement Scheme for Retail Stores. DEXA (1) 2019: 287-303
P. Revanth Rathan, P. Krishna Reddy, Anirban Mondal: Discovering Diverse Popular Paths Using Transactional Modeling and Pattern Mining. DEXA (1) 2019: 327-337
Raj Bhatta, Christie Ezeife, Mahreen Nasir Butt Mining Sequential Pattern of Historical Purchases for E-Commerce Recommendation
Next year
The DAWAK 2020 and DEXA 2020 conferences will be held in Bratislava, Slovakia on September 14th to 17th 2020.
Conclusion
That is all for this blog post! Globally, it was an interesting conference. It is not so big, nor too small, but it is an established conference, and some excellent researchers are attending it. The quality of papers was good. I have attended DEXA and DAWAK a few times, and will be looking forward to the next one.
Update: You may also be interested to read my newer posts about DEXA and DAWAK 2021.
In this blog post, I will write a short report about the HPCC 2019 conference (21st IEEE Conferences on High Performance Computing and Communications).The HPCC 2019 conference was held in Zhangjiajie, China from the 10th to 12nd August. It is colocated with DSS 2019 and SmartCity 2019, and organized by Hunan University.
Registration
I did the on-site registration and I received the conference bag, which contained the conference program, a notebook, a pen, and other information. However, I found that the conference bag did not contained the conference proceedings (neither printed or on a USB drive). So, I checked the website of HPCC which clearly say that: “each registrant will receive a copy of the conference proceedings.“
Then, I asked the registration desk why I did not receive a copy of the proceedings since it is written on the website. But they did not wanted to give me one. I am not sure what is the reason for that and they did not explain but just said that there is no proceedings. My guess is that it is because I paid the regular registration free (about 550$) rather than the author registration fee. But still, the website said that ALL registrants would receive the proceedings. After talking with the registration desk, they only offered to copy it to my computer from their USB drive… which is not convenient, and it should not be that way. It should be provided in the bag, or in the worst case, it should be downloadable from the website.
One hour later, after talking with other participants, I found that some of them had received the proceedings on a USB… Thus, while attending the keynotes I sent an e-mail to organizers to ask why I did not receive the proceedings. After about one hour, they apologized and asked me to go back to the registration desk (for the third time) to give me a proceedings on USB. They did not give me a clear explanation but by listening to them talking in Chinese, it seems that they did not have enough proceedings so some people did not receive it. But there might also have been some misunderstanding.
Keynote by Bart Selman on the future of AI
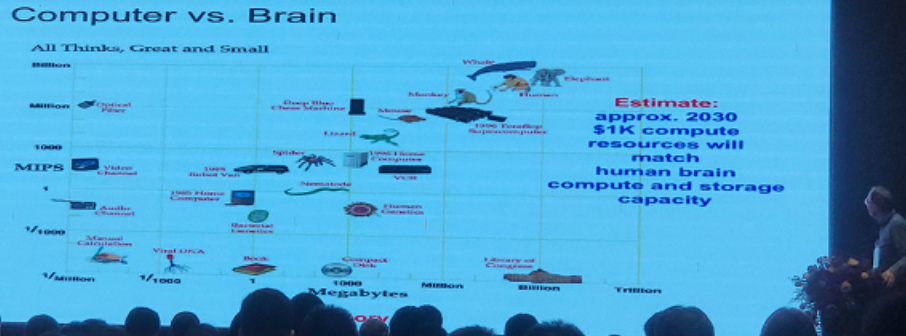
This speaker said that he is excited about recent developments in AI research, and its increasing applications into the real-world. He mentioned that finally machines are starting to “hear” and “see” after about 50+ year of research on AI. Some recent changes is that big set of labelled data are now used to make AI understand our conceptualization of the world, and that there is a strong commercial interest in AI. The speaker said that by 2030, a 1000$ computer will be as powerful as the human brain in terms of computing power and storage (see picture below). I think that this is a bold claim given that the brain has a very different architecture from a computer. I would be curious about how they come with these numbers that the brain has billions megabytes capacity and billions MIPS.
About the future of AI, he mentionned that the next phase is further integration of perception, planning, inference, and learning. Moreover, we also need depper semantics of natural language such as common sense knowledge and reasoning. Common sense is also needed to handle extreme or unforeseen case (for example, to ensure the safety of self-driving cars). Moreover, the speaker mentioned that non human intelligence may be developped. Overall the talk was interesting.
Other keynotes
There was also several other keynotes by some good speakers, including Prof. Witold Pedrycz, editor of Information Science and other journals. And there was a keynote by Yunhao Liu about the internet of things, and a talk by Xindong Wu among others. I will not describe all of the keynotes since some of them are not so much related to my research (e.g. keynote on sensor networks).
One keynote speaker had several videos but could not play them due to some technical problem. The talk was still very interesting, but it is a reminder that one should always do a test on the equipment before giving a talk especially when using videos.
Paper presentation
I came to the conference because I am co-author of the following paper (which was presented by the first author):
Win, K. N., Chen, J., Xiao, G., Chen, Y., Fournier-Viger (2019) A Parallel Crime Activity Clustering Algorithm based on Apache Spark Cloud Computing Platform. Proc. of 21st IEEE Conferences on High Performance Computing and Communications (HPCC-2019). to appear.
This paper is about analyzing criminal activity data to discover interesting patterns (fuzzy clusters). The proposed algorithm is implemented on Apache Spark.
Conclusion
This was a brief report about the HPCC 2019 conference. It is a medium-sized conference (I would guess about 400 persons including the two colocated conferences), with many parallel sessions. The highlight of the conference was for me the keynotes, which were given by some good researchers. The conference proceedings is published by IEEE and included in the EI index, which is interesting. The location of the conference in Zhangjiajie, China was also great. There is a nice national park.
Today, I will talk about the different milestones that a researcher may meet during his career. I will start from the first stage, which is graduate studies until reaching the stage of being a permanent researcher working at a research institution or being a well-known researcher. I will give some advices about what is important at each stage of the career of a researcher.
Stage 1: Graduate student
The first stage is graduate studies. The goal of the master degree is to learn how to do research, by joining a research team. At that stage, one should learn how to read research papers about state of the art research, develop ideas to solve some research problems, develop a solution, carry experiments, and write papers.
During the master degree, the supervisor usually guide the student and help him with some of the tasks (e.g. writing a paper). This is different from doing a PhD, where a student should do more tasks by himself. After completing PhD, one should be an autonomous researcher. It means that someone who has completed a PhD should be able to find interesting research problems by himself (without help from others) and to perform all other steps of a research project by himself.
Normally a graduate student will initially need much help to do research. But after completing a few projects and writing papers, one will become more and more efficient and autonomous. It is important to have that as a goal.
What one should focus on during graduate school?
learn to write well research papers (writing is a key skill for a researcher),
publish several papers, and at least some in good conferences and journals (to convince other people of your research ability and then land a researcher job),
learn to find research problems and develop original research solutions,
improve your presentation skills (not only to present papers at conferences but because researchers who will work as lecturers or professors will be expected to teach well),
try to obtain grants and prizes during studies,
try to build a network of contacts in academia and have collaborations with other students or researchers,
try to publish some papers that may obtain citations (because citation count is sometimes considered as a performance indicator),
try to have some teaching experience such as teaching an undergraduate course, or being a teaching assistant,
try to have good grades (although this is less important than having good research output),
learn other useful research related skills such as finding papers online, using LaTeX for writing papers (especially for science papers), managing time well,
learn to identify limitations and weaknesses in the research of others when reading a paper or attending a presentation,
try to always ask at least one question when attending a presentation,
try to be involved in reviewing papers and other important academic activities.
Stage 2: Postoctoral researcher
Many persons become a postdoctoral researcher after doing the PhD. Such position may be for one or two years and sometimes more, with usually the goal of then obtaining a position of professor or lecturer, or working in the industry.
Why doing a postdoc? It gives the opportunity of exploring new research topics, that are often different from the PhD, and to write more papers further improve research skills, and gives some extra time to find a job. A postdoc will also generally be done with a research team that is not the same as that of the PhD, and sometimes even in another country. This allows to learn other ways of doing research and to build contact with other researchers.
What one should focus on during a postdoc?
Find a good team,
Write quality papers,
Be almost autonomous in finding research problems and doing research,
Try to participate in the research of other team members or researchers and perhaps even unofficially cosupervise students,
Try participating in funding applications,
Work on projects that will lead to papers in a relatively short time and have relatively low chance of failure as a postdoc is often short and may need to show results to then apply for other jobs,
Don’t be a postdoc for too many years (ideally no more than two years) as more than that may be considered negative in some fields.
Step 3: Faculty member / researcher
The next stage for an academic researcher is usually to become a faculty member or professional researcher, that is to work for a university or research center and perform research and perhaps also teach.
There are different ranks for faculty members in universities, which depends on the countries. In north america and China some typical ranks in a university are lecturer, assistant professor, associate professor and professor (also called full professor). Sometimes there are also some honorific ranks such as distinguished professor. Typically, the rank of lecturer consists of only teaching (no research), while the lowest rank that consists of doing research and teaching is assistant professor.
The goal of a new faculty member should be to climb ranks by:
Creating a research program that spans over several years with a long-term vision (different from a graduate student that typically do not think more far than a paper at a time).
Writing research proposals that obtain significant research funding,
Writing high quality papers that have a significant impact,
Being an excellent teacher,
Obtaining awards, getting involved in international committees,
Supervising graduate students successfully, and learning to manage a team,
Having international collaborations and industry collaborations,
Being involved in university affairs,
Having other activities such as publishing books, organizing workshops, conferences, and being a journal editor.
Several young faculty members have problems developing a long term research plan, and/or are still having difficulty finding good research problems. This lead to the inability of obtaining research funding and publishing good papers, and is often caused by not learning to become autonomous during the PhD. It is thus important to develop these skills as early as possible during one’s career. If one is unable to have a research plan or obtain funding, he may not be promoted and may even not have his contract renewed. I have seen this several times.
Besides climbing the ranks, one may aim at becoming influential and well-known in his field. This requires the same goals but to put extra effort and to work strategically to obtain this goal.
For young faculty members, the most critical period is the first three to five years, where one needs to prove himself to become permanent or be promoted. This requires a huge amount of work because one not only need to prepare new courses as a new faculty member, but also to teach and do well in terms of research.
Conclusion
This post has given an overview of the main steps in the career of an academic researcher. Hope it was interesting. If you have comments and think that I have missed something important, please post a comment below. I will be happy to read it.
Today, I will share a few funny pictures related to data miningand machine learning that I have found online. These pictures comes from various sources (I don’t remember who created them). I will also perhaps add more later on that page
Associations between customer purchases?
Everybody is doing AI
Toy datasets vs real-life
Math?
Training a model
Overfitting (1)
Statistics
Citations
Overfitting (2)
Buzzwords
What people think I do?
Conclusion
If you also have some interesting pictures, you may share it in the comment below and I may add them to this page.
People will work several years to obtain a PhD, sometimes with the goal of becoming a researcher in academia or the industry, or a lecturer. Some think that getting a PhD is enough to become a successful researcher. But obtaining a PhD is not enough to ensure that.
For example, when I was doing my PhD in Canada, I noticed that there was a huge difference between the best and the worst students who completed their PhD studies. Some students would finish a PhD without publishing a paper (only a thesis), while other had scholarships and dozen of papers and awards, and had multiple collaborations with international researchers. All these students received the same Ph.D. diploma. But their CV were not equal and it made a big difference when it was time to apply for a job, and how successfully they would establish a research career.
I also noticed that some students would finish their PhD in the minimum amount of time, while in some case a student finished in ten years due to a lack of motivation, a part-time job, not producing meaningful research, and perhaps a lack of support from his advisor. This latter student was then unable to pursue a research career despite having finally obtained his PhD. In fact, he should have perhaps chosen another career path earlier.
Another problem that some PhD students face is that they would wait perhaps just a month before graduating to look for a job. But finding a good research position after the PhD is not always easy and require preparation.
So how to ensure a successful career after the PhD?
I will give some advices:
Try to find a mentor which has research experience to give you advices about how to succeed in your field, and overcome the challenges that you are facing to establish your career. This can greatly help as you will avoid making some errors that other people have made.
Set a clear goal for your career as early as possible, then think about the milestones or subgoals that you need to attain to succeed.
Make a realistic plan of how to attain your goals as early as possible.
Build a network of contacts and collaborators in your field. This can help you to find opportunities and bring other benefits. Attend conferences, talk with other researchers online, in your university, etc.
Create a website, and online profile on research oriented social networks like ResearchGate, and a Linkedin profile. This can help to promote your research and keep contact with other researchers. Share your papers online.
Publish your data, or softwareprograms that you developed as open source. People who will use them will cite you.
Find an important research problem to work on and develop something innovative. Choose a project that is realistic (will not likely lead to failure), not too long (will not likely delay your PhD), and can lead to good publications.
Improve your writing skills. This is a key aspect for researchers in academia as writing papers and grant proposals is something researchers always do. A well-written paper or grant proposal that is convincing has always more chance to be accepted/funded.
Aim at publishing in good journals and conferences. Getting your papers accepted there will show that your research is recognized by your peers. Publishing in unknown conferences and journals, or not having publiciations will not convince anyone of your research abilities when it is time to look for a job or apply for funding. Often, publishing good papers is more important than publishing many papers.
Improve your presentation skills. As a researcher, you will often need to present your research and deliver talks. A good presentation can make an enormous difference. Besides, when it is time to apply for a job in academia, the hiring committee will likely ask you to present your work and give a teaching demo to evaluate your teaching skills. A poor presenter may not be hired even if he is a good researcher. And an average researcher with poor presentation skills will likely not be hired. Here are some tips for improving your presentation skills.
Choose a good PhD supervisor, with a strong team. A good team will give you a good environment for your research and bring opportunities. Working with a famous researcher in your field may bring various benefits, including learning from successful researchers.
Don’t be afraid to go abroad or in other cities to find better opportunities. For researchers, having experience abroad generally looks good on a CV, and is even a criterion for hiring in some universities. If no suitable jobs are available in your countries, looking abroad may help find one. I for example did my PhD in Canada, my postdoc in Taiwan, moved to another province in Canada, before going to back to China. And this strategy of going abroad has paid off well as it opened new opportunies that I would not have if I always stayed in the same city.
Conclusion
That is all for today, as I am writing this on the airplane and it will soon land. If you have comments, please share them in the comment section below. I will be happy to read them.
In this blog post, I will talk about the first programming language that I have learn, which is HyperTalk. Younger readers may have never heard about it, as it was mostly popular in the 1980s and 1990s. Though, it is not a complex language, it was ahead of its time with many ideas, and has influenced many other important technologies such as the Web that we used today. I will briefly introduce the main idea around HyperTalk and its authoring system named HyperCard, and also talk a bit about my experience.
HyperCard is a visual authoring tool for writing software that was developped for Apple computers. It was designed to be used by novice as the user interface of a software could be built visually by drawing, and dragging and dropping buttons and fields. But one could also use the Hypertalk programming language to add more complex functions to the software. It become popular the end of the 1980s mainly due to it ease of use compared to other programming languages, and because at some point it was distributed for free will all Apple computers. The last release was in 1998.
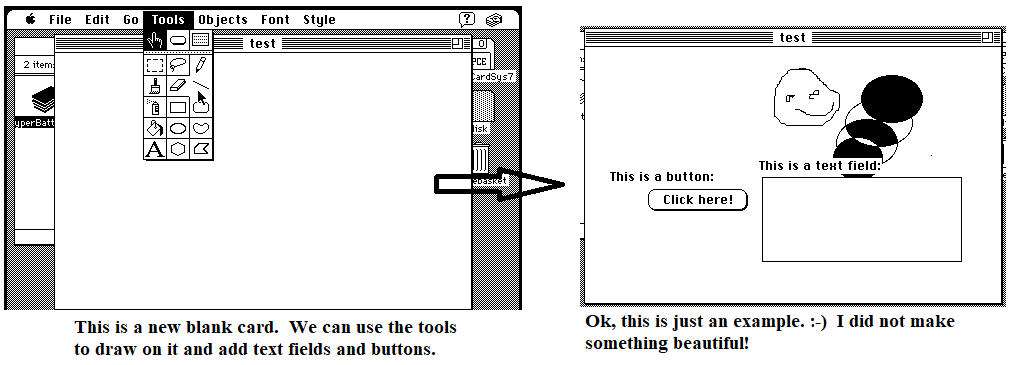
A program written using HyperCard was called a Stack, and contained several cards. You can consider a card as a page, where you could draw using painting tools and add some elements such as buttons and text fields for entering data and interacting with the software. Then it was possible to program buttons to do action such as going to another card, displaying messages, processing the data that the user entered in the text fields, and playing sounds.
The concept of a stack of cards with links between them was very innovative and can be seen asa precursor of the Word Wide Web. Indeed, the authors of the Mosaic Web browser in the 1990s have indicated that it has inspired them. But the difference with the Web is that Web pages are on different computers, rather than being inside a program. It can also be seen as something similar to Powerpoint as cards could be viewed as slides, but Hypercard would allow more complex programming and was not designed for presentation.
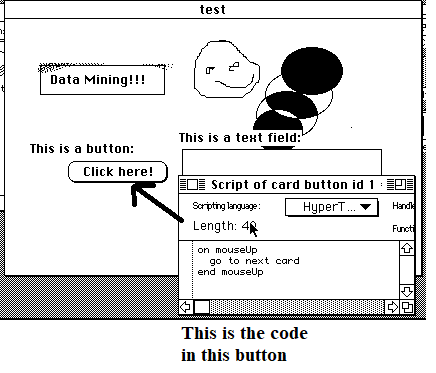
Another innovative aspect of HyperCard was its programming language that was designed to be close to the English language to make it very to read and learn. For example, some code in a button would look like this:
On Mouseup ask “What is your name” put answ into field “output” Go to next card End Mouseup
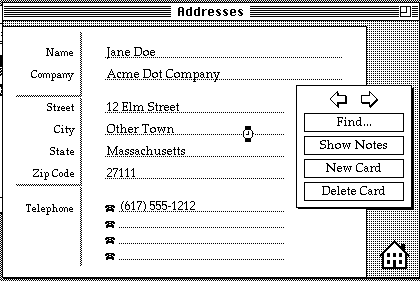
This code is very simple and easy to understand even by someone who did not learn the Hypertalk language. When the user click the button, it displays a dialog asking to enter a name, and then the name is put in a text field called “output”. Then the next card is displayed. Clicking on a button could also create new cards. For example, one could write a software to manage contacts, where each card was storing contact information.
An address book Hypercard stackA battleship game stack
But one of the best thing aboutf Hypercard is that it was promoting open-source software. In fact, HyperTalk is an interpreted programming language, and the HyperCard software initially acted as both an authoring tool for developing software and a player for running the software. As a user, this concept was extremely interesting, as one could obtain a stack (a program) made by someone else, run the stack, and at anytime look at the code inside the buttons, fields and other objects to learn how it work and modify it. There was of course some ways to hide the code such as calling some binary code external to the stack (eg. XCMDs) of setting up a password, but by default, the code of a stack was open to anyone.
Because Hypercard was an interpreted language, it was not designed to run very fast but it allowed to easily built some software with graphical user interface, and that in the 1980s. Building a user interface with other programming languages was far from easy for novices. When I was 12 years old, I learn programming using HyperCard on a black and white Mac Computer with a 80 Mb Hard Drive and 2 Mb of RAM. During that year, I was in high school and took a week long summer camp to learn HyperTalk at a college during the summer and then bought a book to learn more. I then programmed a few interesting software programs:
House of horror 1 and 2. This was a video game where you had to enter an haunted house and click on the right doors to find the exit. Choosing the wrong door would show a monster and the player would loose. Creating this type of visual game with HyperCard was not that hard as one could draw on the cards. In the second version of the game, I made it more complicated by implementing a life bar such that one would not die right away after an attack by a monster. That software was then installed on some computer in a local school for kids to play.
A fighting game. I also programmed a simple fighting game using the keyboard. There was a few keys to punch, kick or block, with a life bar for the player and the opponent, which was controled by the computer. Both opponents could not move forward or backward but just kick, punch, block. There was three fighters, and it was inspired by the Street Fighters II game, popular in 1992.
Encryption software. I also developed a simple software for encrypting/decrypting messages using a password.
A software for playing mazes. The software would allow to load or save a maze. Then the maze was drawn on the screen. The user would have to drag the mouse inside the maze to reach the exit, while avoiding touching the walls.
Unfortunately, I don’t have a copy of these software programs anymore. They were on a 3.5 inch floppy disk, and such disk were not reliable. But anyway, it was just a fun experience and it does not really matter.
For those who wanted to play with Hypercard, it is still possible to use it inside an emular of a Macintosh computer with the System 7 operating system: https://archive.org/details/AppleMacintoshSystem753
Another interesting thing about HyperCard is that it was basically designed by a single man: Bill Atkinson. This man is a legendary software developer. On the first Apple computer, I would open the MacPaint drawing software and see his name as the lead developer, and then open HyperCard and also see his name as the lead developer. He wrote a large part of these software by himself. Moreover, he designed core parts of the operating system of Apple computers such as the QuickDraw for drawing graphics on screen, the event manager and menu system. Bill Atkinson was a very smart man. He was actually almost completing PhD in neuroscience before being called by Steve Jobs to join Apple and write these software programs. For those interested, there are some videos of interviews with him available online.
After learning Hypertalk, I learned many other programming languages, including Cobol, C, C++, Java, Assembly language for SPARC processors, and Lisp among others.
That is all for today. I wanted to share something a bit different on this blog this time. What is your first programming language? Or have you used Hypercard? If you want to share your experience, please post in the comment section below!
I have just arrived Austria to attend the IEA AIE 2019 conference ( 32nd Intern. Conf. on Industrial, Engineering and Other Applications of Applied Intelligent Systems), which is held in Graz from the 9th to 11th July. In this blog post, I will give a report about the conference.
About the IEA AIEconference
It is a conference on artificial intelligence and applications that has been held for more than 30 years. I have attended this conference several times. You can read my reports about IEA AIE 2018 (Canada) and IEA AIE 2016 (Japan). And I also had papers at IEA AIE 2009, IEA AIE 2010, IEA AIE 2011 and IEA AIE 2014.
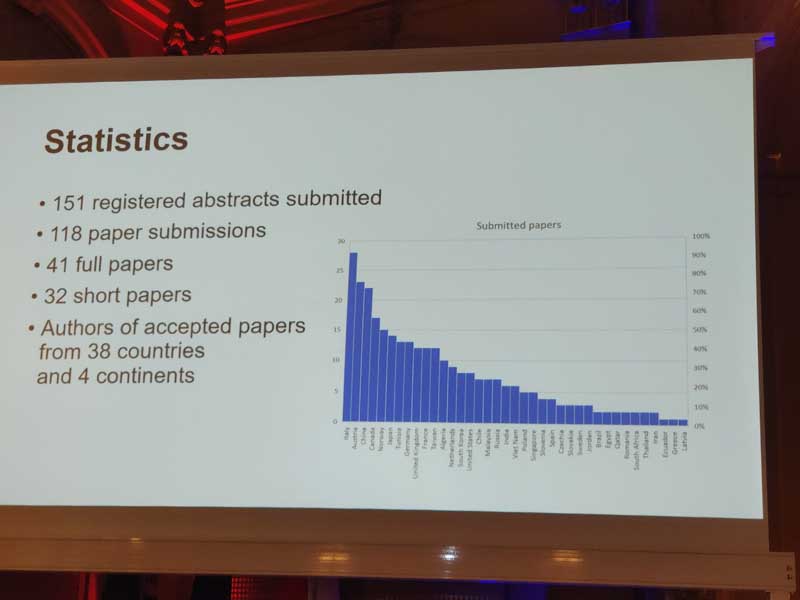
This year, 151 papers were submitted. From that 41 were selected as full papers, and 32 as short papers.
Location
The IEA AIE 2019 conference was held in the city of Graz in Austria, and more precisely at the Graz University of Technology.
The Graz University of Technology:
Opening cemenony
The organizers first introduced the program of this year’s conference. Below is a picture of the general chair Prof. M. Ali. giving a few words, and then below a slide about statistics.
Keynote by Reiner John, titled “The 2nd wave of AI – Thesis for success of AI in thrustworthy, safety critical mobility systems”
The talk was about highly automated driving. It talked about challenges for highly automated riving (HAD), an architecture for HAD, the opportunities for AI in components and subsystems and how AI can participate in the system at an application level.
Some of the challenges are how to drive in extreme weather conditions. Humans often rely on experience, precaution, adaptation, training and foreseen scenarios, to handle difficult situations.
A car is a very complex system and AI can be used to control that complexity. Also safety is very important, as well as predictive maintenance. AI can be used to enhance safety, efficiency and functionality. Here is a pictures of some requirements for automated cars:
Another important aspects is connectivity between cars to collaboratively manage traffic. There was then, a lot more details but here I just report some main ideas.
Welcome reception
On the first evening, there was a nice welcome reception on the top of a building that belongs to the university. A dinner was served. Here are a few pictures:
Paper presentation
I am also excited to present a paper at this conference proposing a new model to discover stable periodic patterns in a sequence of transactions (transaction database). This paper, which was written by my student, received a best paper award. The solution based on the cummulative sum is quite innovative and could be extended other pattern mining problems. I will also release the source code soon in my SPMF software. You can read the paper here:
Fournier-Viger, P., Yang, P., Lin, J. C.-W., Kiran, U. (2019). Discovering Stable Periodic-Frequent Patterns in Transactional Data. Proc. 32nd Intern. Conf. on Industrial, Engineering and Other Applications of Applied Intelligent Systems (IEA AIE 2019), Springer LNAI, 14 pages (to appear)
Banquet
On the evening of the second day, there was a banquet on the top of a hill with a good view of the city. The awards were announced.
Keynote byDietmar Jannach
Prof. Jannach gave a talk about recommender systems. Recommender systems have numerous applications in our daily lives. They help to filter information and find relevant information. Research in tha field started as far as the 1970s with “Selective Dissemination of Information” and then “Collaborative filtering” and “content-based” approaches in the 1990s.
A common abstraction of the recommendation problem is to see it as a matrix completion task, where the goal is to learn a function to recommend that can be assessed using measures such as accuracy.
The above problem has been well-studied The topic of this talk is session-based recommendation where instead of a rating matrix, we have a sequentially ordered log of user interactions (item views, purchases, etc.). And in many cases, we don’t have a user id or long term preference information, etc. We also don’t know the user intent but want to predict the next user action(s) given his last actions (in the current session) and other types of information (community behavior etc.
How to solve these problems? Some method are to use association rules, markov chains, sequential rules, sequential patterns, neural networks, session-based nearest neighbors, etc.
A problem to evaluate session-based recommender system is that there is no standard benchmark protocols and datasets.
The speaker also mentioned that neural networks often do not perform much better than simple approaches.
There was then more details, but I will not report all in this blog post.
Next year: IEA AIE 2020
It was announced that IEA AIE 2020will be held in Kitakyushu, Japan from 21st to 24th July. I am one of the Program Chair of IEA AIE 2020, and I am looking forward to it. Then, IEA AIE 2021 will be in Malaysia, and then IEA AIE 2022 in Japan.
Conclusion
The IEA AIE 2019 conference was good on overall. The organization was well done, and the location was interesting. I had a chance to meet several researchers that I knew beforehand and also meet some interesting researchers. Looking forward to next year!