In this blog post, I will talk about attending the 12th International Conference on Swarm Intelligence (ICSI 2021). The ICSI conference is a relatively young conference about swarm intelligence, metaheuristics and related topics and applications. This year, ICSI 2021 is held in Qingdao, a coastal city in eastern China, from July 17–21, 2021. The conference is also held partially online for those that cannot attend due to travel restrictions.

The conference was held at the Blue Horizon Hotel:

The ICSI conference has been held in several cities and countries, over the years:
- ICSI 2020 – Serbia (virtual)
- ICSI 2019 – Chiang Mai, Vietnam
- ICSI 2018 – Shanghai, China
- ICSI 2017 – Fukuoka, Japan
- ICSI 2016 – Bali, Indonesia
- ICSI-CCI 2015 – Beijing, China
- ICSI 2014 – Hefei, China
- ICSI 2013 – Harbin, China
- ICSI 2012 – Shenzhen, China
- ICSI 2011 – Chongqing, China
- ICSI 2010 – Beijing, China
Proceedings
The proceedings of the ICSI conference are published in the Springer Lecture Notes in Computer Science (LNCS) series as two volumes (Part 1 and Part 2). This ensures that the proceedings are indexed by EI and other indexes like DBLP.

This year, the conference received 177 submissions, which were reviewed on average by 2.5 reviewers. From this 104 papers were accepted for publications, which means an acceptance rate of 58.76%. The paper were organized into 16 sessions.
Day 1 – Registration
On the first day, I registered. I received a paper bag with a badge and the conference program. The proceedings was available online as a download.


Day 1 – Reception
There was also a reception at the hotel in the evening that lasted about an hour. There was food, beer and other drinks. This was a social activity, which is a good opportunity to discuss with other researchers that attend the conference.
Day – 2 – Opening ceremony
On the second day there was the opening ceremony, where the general chair talked about the conference, and the program.

The program committee chair also talked about the paper selection process.
Day – 2 – Keynote talks and invited talks
On the second day, there was two keynote talks and two invited talks. Some good researchers had been invited, and some of the talks were quite interesting. Below is a very brief overview.
The first keynote talk was by Prof. Qirong Tang from Tongji University who talked about “Large-Scale Heterogeneous Robotic Swarms”. He developed a swarm robotic platform that is used for some applications such as searching for multiple light sources, searching for a target, drug delivery in the body, etc. The idea is that some robots can cooperate together to perform a task more quickly (e.g. cooperative search) and thus outperform a single high quality robot. The swarm can be heterogeneous, that is using different types of robots such as flying robots and ground robots. Many bio-inspired algorithms are used to control a robot swarm such as particle swarm optimization (PSO) and genetic algorithms but it was argued that PSO is particularly suited for this task.


The second keynote talk was online by Prof. Chaomin Luo from USA about swarm intelligence applications to robotics and autonomous systems. This includes for example, exploration robots, search and rescue robots.


There was an invited talk by Prof. Gai-Ge Wang from Ocean university. He talked about how to improve the performance of metaheuristics using information feedback. The idea is that during iterations, some feedback of previous iterations is used to guide the search process towards better solutions.


The second invited talk was by Prof. Wenjian Luo from Harbin Institute of Technology (Shenzhen) about many-objectives optimization when multiple parties are involved. For example, to buy a car, many objectives may have to be considered such as the price, size, and fuel consumption and multiple parties such as an husband and wife may put different weights on those objectives. The goal is to find a solution that is optimal for all the parties involved but it is not always possible.


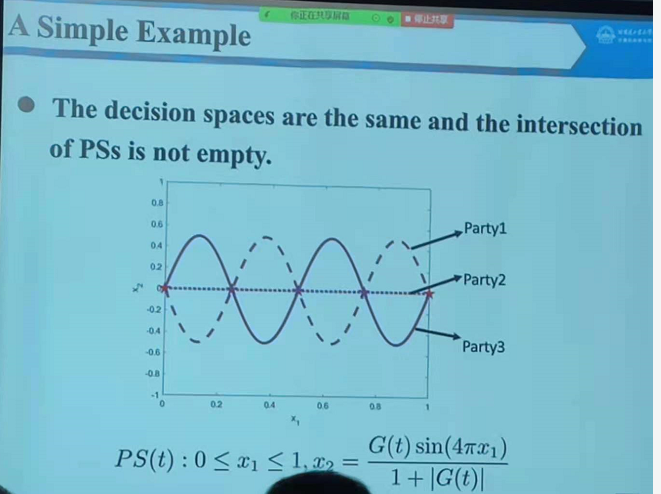
Day 2 – Paper presentations
On the afternoon, there was paper presentations and a poster session. There was some good papers about a variety of topics such as sheep optimization, classification of imbalanced data with PSO, citation analysis, swarm intelligence for UAVs, and multi-robot cooperation.
I have presented the below data mining paper about proof searching for proving theorems using simulated anneealing (which is mainly the work of my post-doc. M. S. Nawaz). In that paper, we use the simulated annealing metaheuristic to search for proofs to PVS theorems and compare with a genetic algorithm.
Nawaz, M. S., Sun, M., Fournier-Viger, P. (2021). Proof Searching in PVS theorem prover using Simulated Annealing. Proceedings of the 12th Intern. Conf. on Swarm Intelligence (ICSI 2021) Part II, pp. 253-262
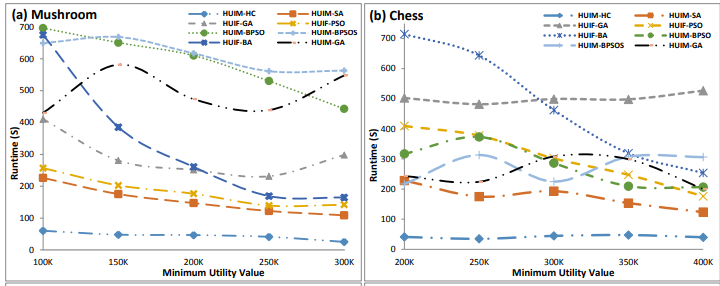
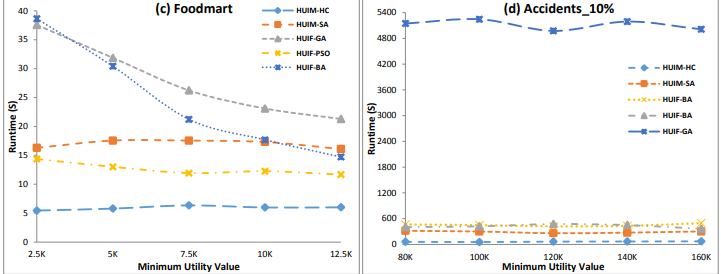
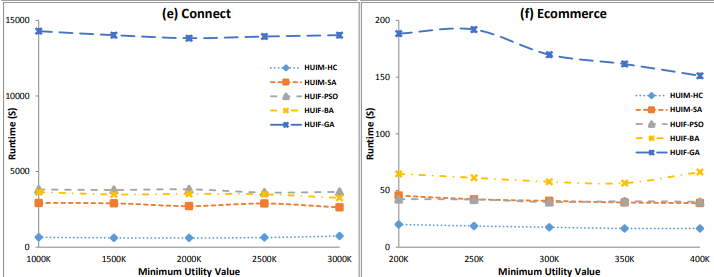
There was also a good paper by Prof. Wei Song et al. about using fish swarm optimization for high utility itemset mining:
Song, W. Li, J. Huang, C.: Artificial Fish Swarm Algorithm for Mining High Utility Itemsets. ICSI (2) 2021: 407-419

Day 2 – Banquet
In the evening, there was a banquet. The best paper awards were announced.


ICSI 2022
It was announced that next year the ICSI 2022 conference will be held in Xian, China from July 15 to 19 2022.

Conclusion
Swarm intelligence is not my main research area although I have participated to several papers on this topic. But the conference was interesting and well organized. The quality was generally good. I would attend it again if I have some papers on this topic.
Now, I will leave Qingdao, and next I will attend the CCF-AI 2021 conference, DSIT 2021 conference, and then the IEA AIE 2021 conference.
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.