
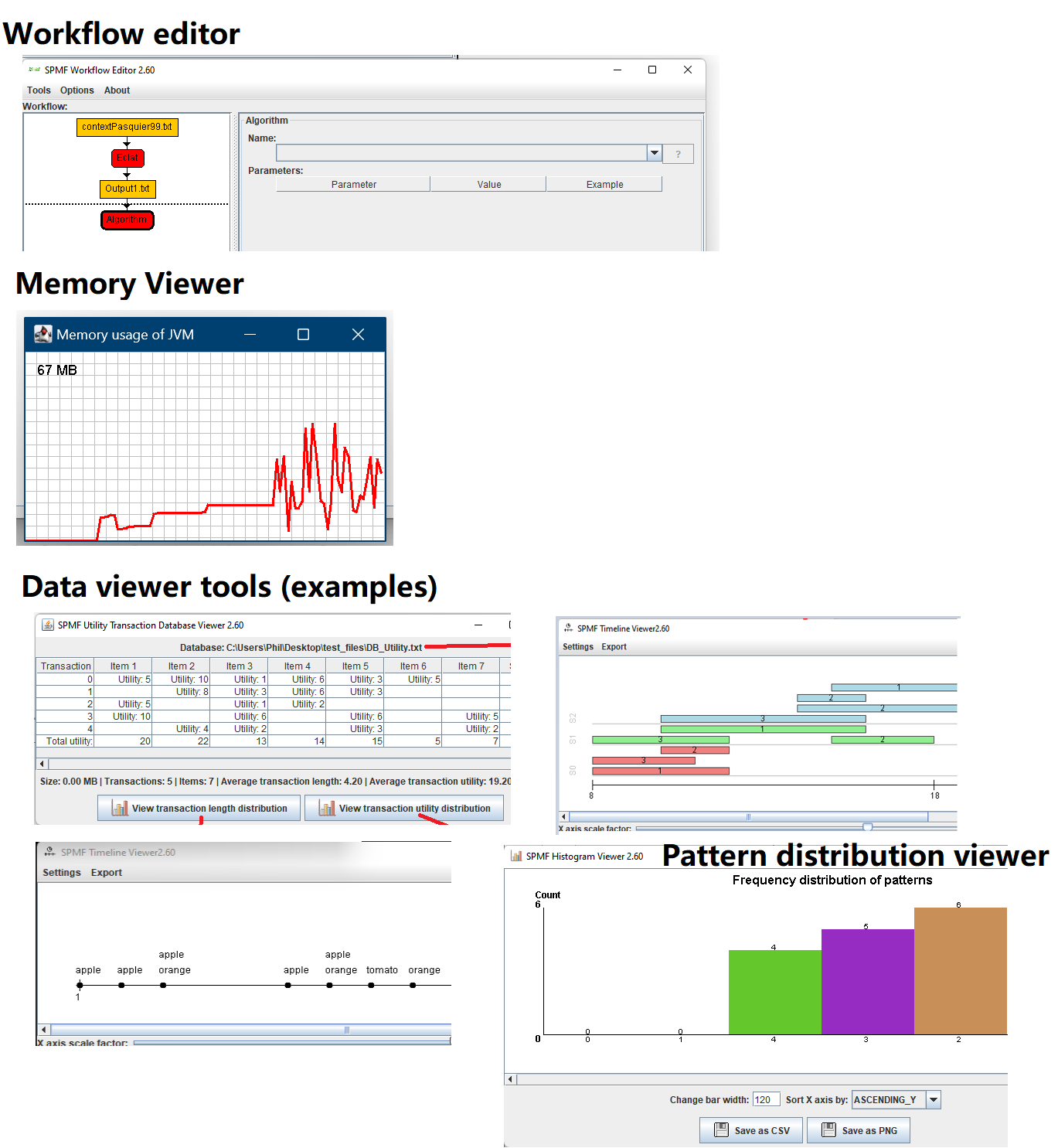
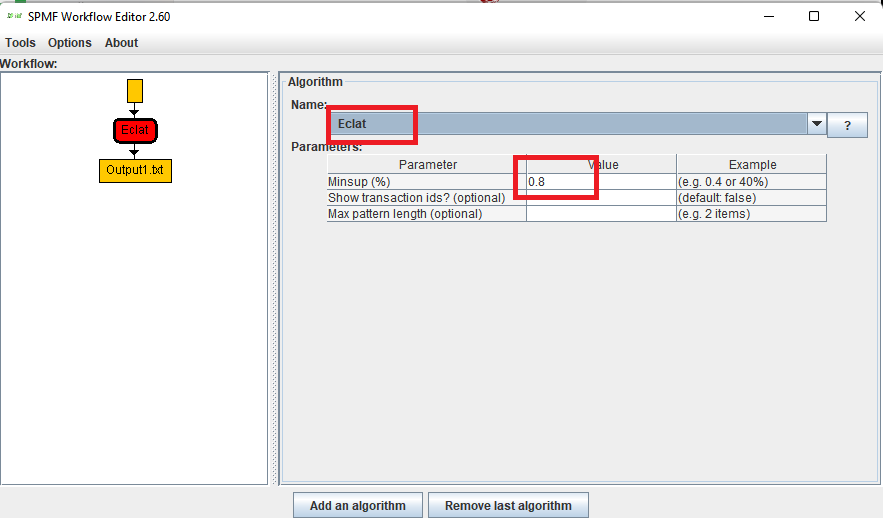
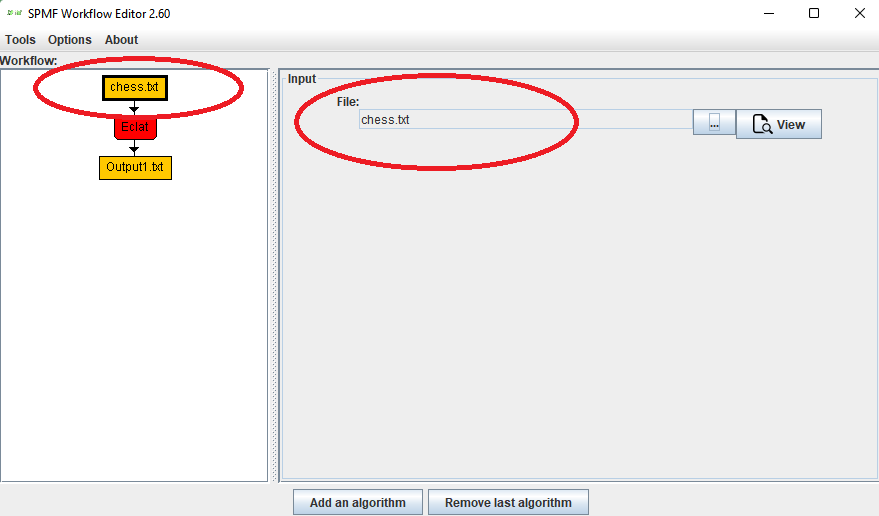
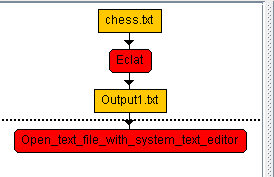
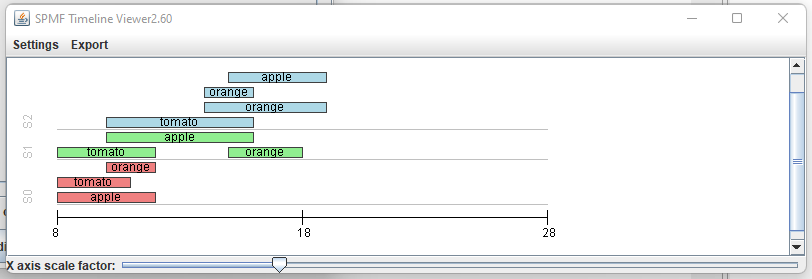
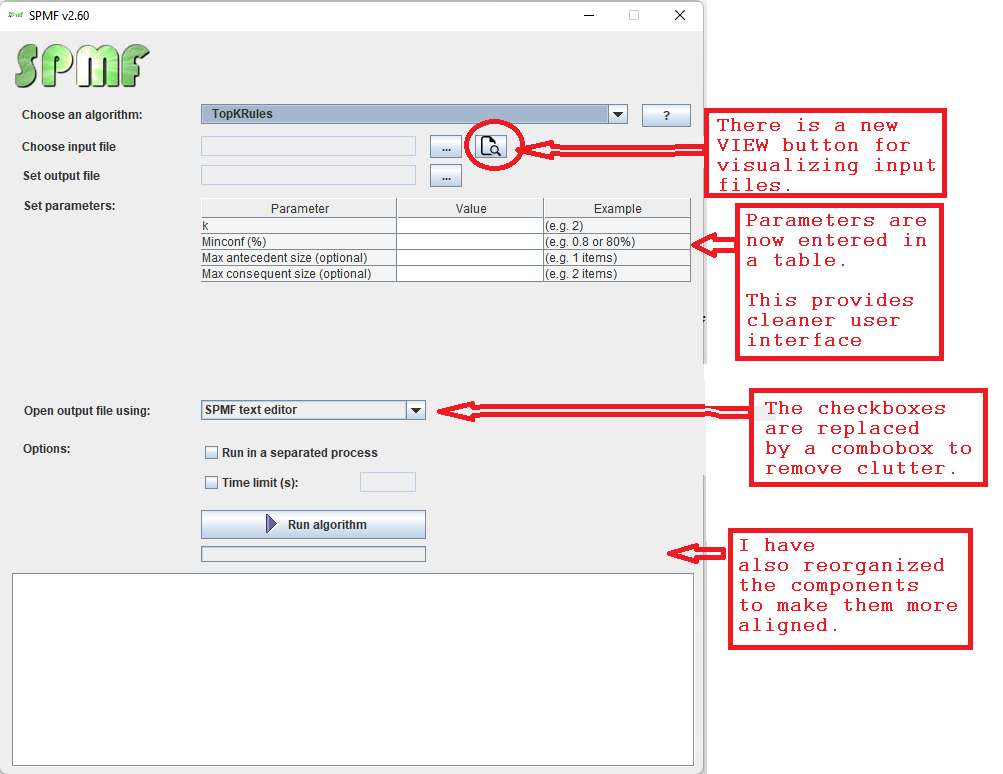
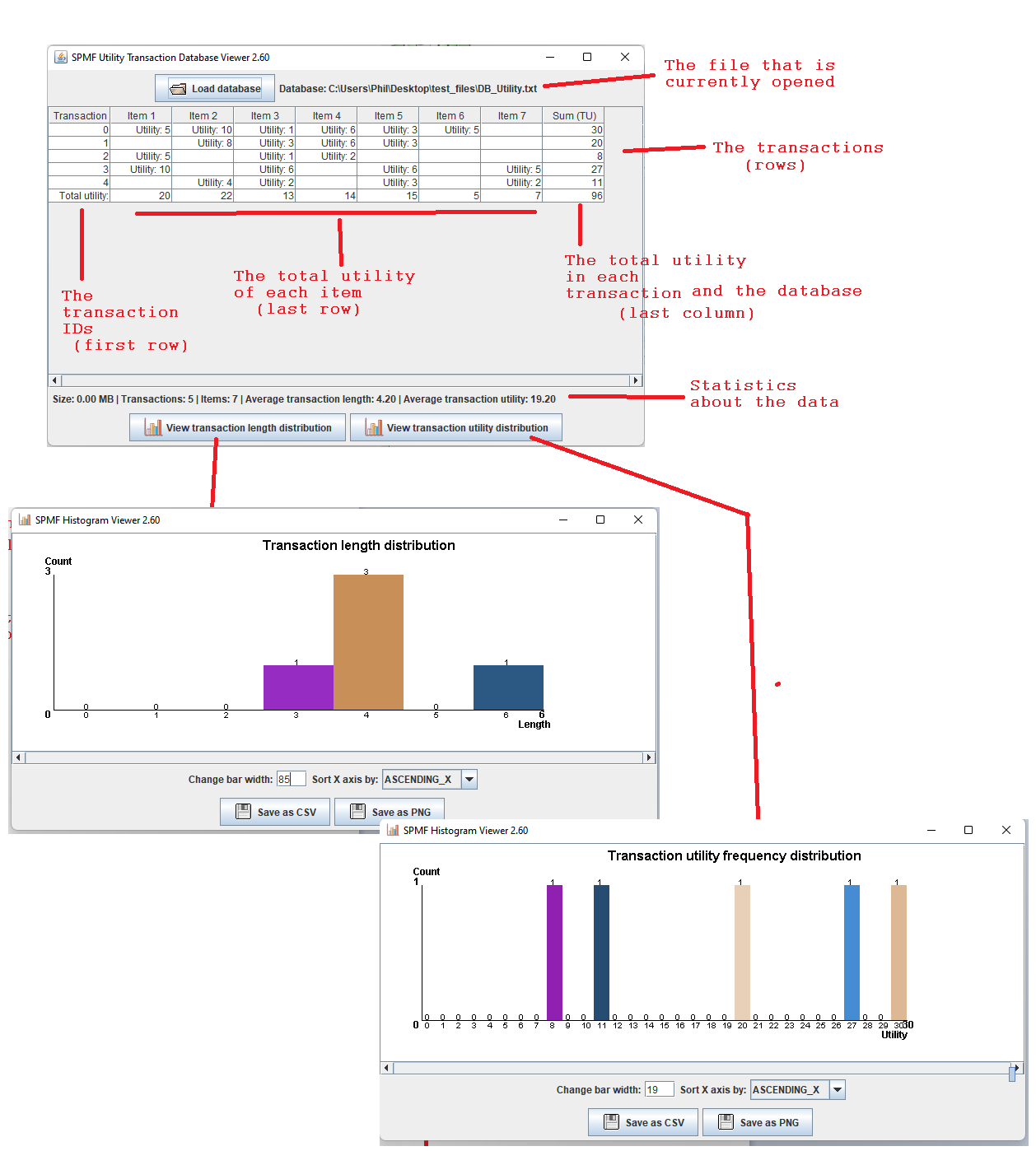
Hi all, this is just to let you know that I found that there was a problem with the user interface of SPMF on low resolution screens in the update 2.60. The table for setting the parameters of algorithms was not appearing properly. I fixed the bug and replace the files spmf.jar and spmf.zip on the website. If you had this issue, you may download the software again.
If you have any other issues with the new version of SPMF, please send me an e-mail to philfv AT qq DOT com.
In particular, if you try to compile the Java code, you may have to update your Java version to the latest version.



Archives
Categories
- Academia (82)
- artificial intelligence (34)
- Big data (80)
- Bioinformatics (3)
- cfp (10)
- Chinese posts (1)
- Conference (70)
- Data Mining (182)
- Data science (102)
- Database (1)
- General (42)
- Industry (2)
- Interview (1)
- Java (11)
- Latex (10)
- Machine Learning (20)
- Mathematics (2)
- open-source (37)
- Other (3)
- Pattern Mining (84)
- Plagiarism (1)
- Programming (17)
- Research (109)
- spmf (53)
- Time series (3)
- Uncategorized (22)
- Utility Mining (22)
- Video (19)
- Website (3)
-
Recent Posts
- SPMF: bug fix about screen resolution
- SPMF 2.60 is released!
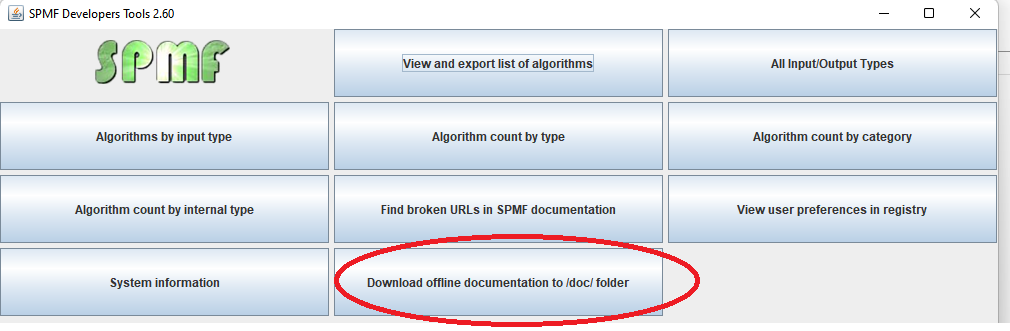
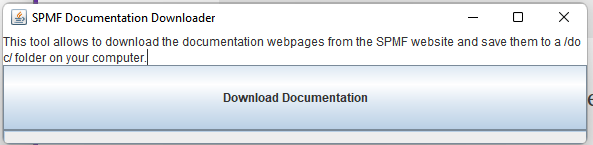
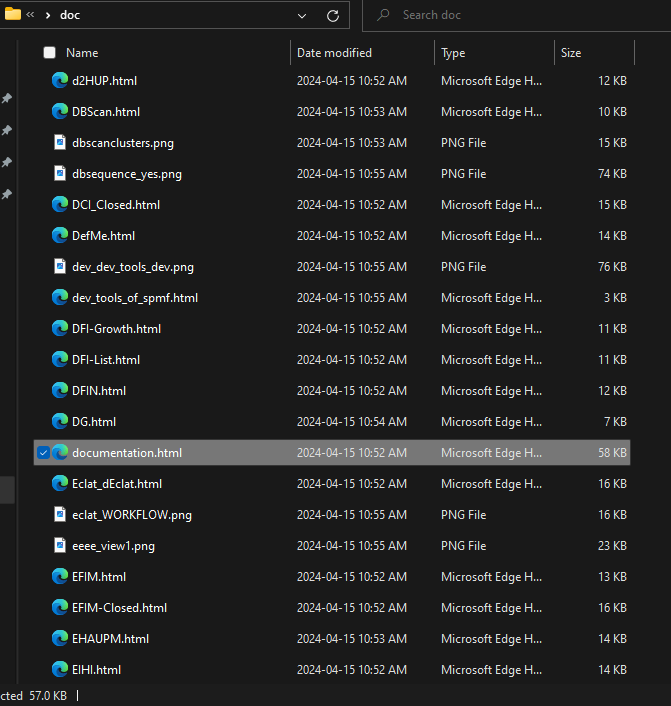
- How to download an offline copy of the SPMF documentation?
- Some interesting statistics about SPMF
- Sneak peak at the new user interface of SPMF (part 3)
- ChatGPT, LLMs and homework
- When ChatGPT is used to write papers…
- Sneak peak at the new user interface of SPMF (part 2)
- Sneak peak at the new user interface of SPMF (part 1)
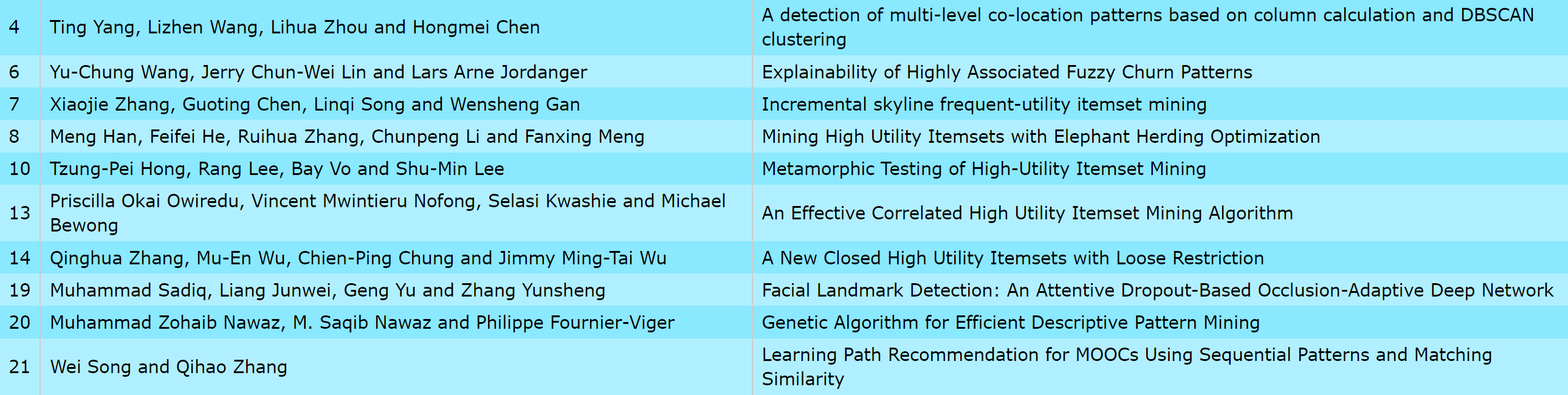
- UDML 2024 Accepted papers
Recent Comments
- K. P. Birla on About the author
- An Overview of Pattern Mining Techniques | The Data Blog on An Introduction to Data Mining
- Key Papers about Episode Mining | The Data Blog on An introduction to periodic pattern mining
- Dr J Gangadhar Naik on How to improve the quality of your research papers?
- Philippe Fournier-Viger on About the author




Tag cloud
- academia
- ai
- algorithm
- apriori
- article
- articles
- artificial intelligence
- association rule
- big data
- cfp
- china
- conference
- data
- data mining
- data science
- episode
- graph
- high utility itemset mining
- icdm
- itemset
- itemset mining
- java
- journal
- latex
- machine learning
- open-source
- open source
- pakdd
- paper
- papers
- pattern mining
- periodic pattern
- phd
- Research
- researcher
- reviewer
- sequence
- sequential pattern
- software
- spmf
- udml
- utility mining
- video
- workshop
- writing
Number of visitors:
2,281,042