Today, I will discuss some common mistakes that I have seen in research papers and that every author should avoid!

- Overlength papers. When a paper is submitted to a conference or journal, there is generally a page limit. If the page limit is not respected, several reviewers will not like it. The reason is that reviewers are generally very busy and they have to review many papers. Reviewers should not have to spend more time reading a paper because someone did not want to spend time to make it fit within the page limit.
- Proofreading and unreadable papers. A paper should be well-written and the author(s) proofread it before submitting it. I have seen on a few occasions some unreadable paper that look like they were automatically translated by Google. This is a guaranteed reject. Besides, if there are many typos because the author did not took the time to proofread their paper, it may bother the reviewers.
- Paper that contains plagiarized content. A paper that contains text copied from another paper more or less reduce your chance of being accepted, depending on the amount of text that is copied. All the text in your papers should be written by yourself only. It is easy for a reviewer to detect plagiarized content using the internet.
- Incremental extension of the author’s previous work. I have recently read a paper where the author extended his own work, published just a few months ago. The problem with that paper was that the author just made a few minor changes before submitting it as a new paper. A new paper should present on a same topic should present at least 30 to 40 % new content and there should be a significant difference with the previous work.
- Not citing recent work or works in top conferences, journals. Several reviewers check the dates of the references when evaluating a paper. For example,I have read a paper recently where all references where from before 2006. This is a bad sign, since it is unlikely that nothing has happened in a given field since 2006. When writing a paper, it is recommended to add a few newer references in your paper to show that you are aware of the newest research. It also looks better if you cite articles from top conferences and journals.
- Irrelevant information. Some papers contains irrelevant information or information that is not really important. For example, if your paper is a data mining paper submitted to a data mining or artificial intelligence conference, it is not necessary to explain what is data mining. It can be assumed that the reviewers who are specialist in their field know what is “data mining”. Another example is to mention irrelevant details such as to why a given software was used to make charts.
- Not comparing your proposal with the state-of-the-art solutions but instead with old solutions. For example, if you propose a new data mining algorithm, it is expected that you will compare the performance with the current best algorithm to demonstrate that your algorithm is better at least in some cases. A common error is to compare with some old algorithms that are not the best anymore.
- Not citing correctly the sources, making factual errors or missing some important references. Another mistake that I have seen many times is authors that claim incorrect facts about previous work or ignore important previous work in their paper. For example, I have read recently a paper that said that to do X, there is only two types of methods : A and B. However, from my knowledge into this field, I know that there is three main approaches: A, B and C. Another example, is a paper where the author propose to define a new problem and propose a new algorithm for that problem. However, the author fails to recognize that his problem can be solved using some existing methods published several years ago, and do not cite this work either.
- Not showing that the problem that the author want to solve is important and challenging. It is important in a research paper to show that the problem that you want to solve is important and is challenging. If the reviewer is not convinced in the introduction that your problem is important or challenging, it is a bad start. To convince the reviewer, explain in that the problem is important and explains the limitations of current solutions for the current problem and why the problem is difficult.
- Poor organization / Paragraphs should flow naturally. It is important that the various parts of the research papers are connected by a “flow”. What I mean is that when the reviewer is reading your paper, each section or paragraph should feel logically connected the previous and next paragraphs.
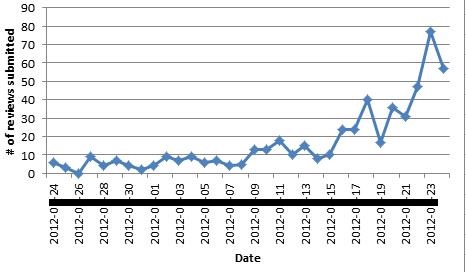
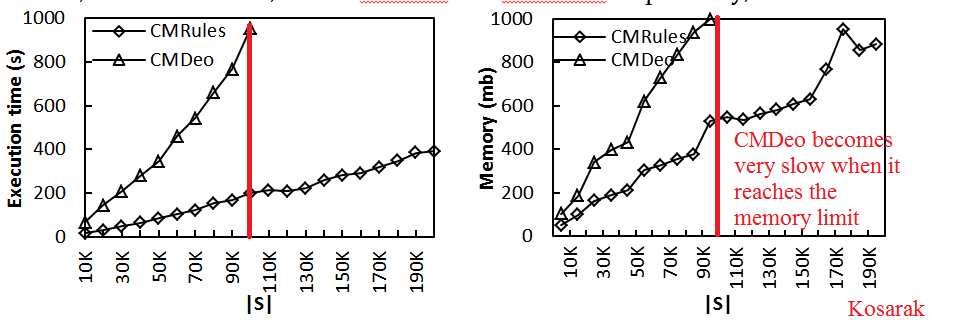
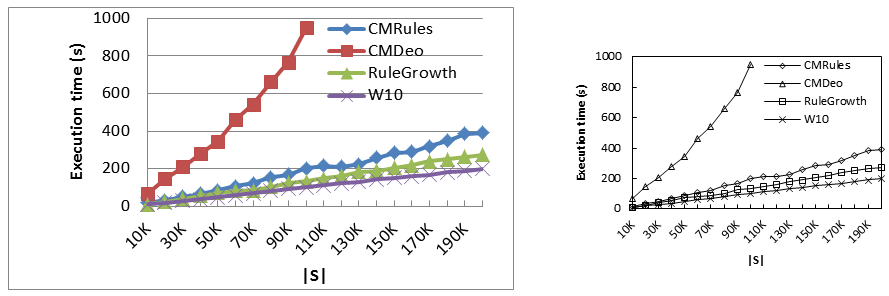
- Figures/charts that do not look good or are too small. About charts, it is important to make them look good. I have made a blog post about “How to make good looking charts for research papers?” Besides, a second mistake is to make the charts or figures so small that they become unreadable. If the reviewer prints your paper to read it, he should be able to read the text without using a magnifying glass. Moreover, it should not be expected that the reviewer will read the PDF version of your paper and can zoom in.
- Figures that are irrelevant. In some papers, authors put a lot of figures that are irrelevant. For example, if a figure can be summarized with one or two lines of text, it is better to remove it.
- Not justifying the design decisions for the proposed solution. If the solution proposed in a research paper looks like a naïve solution, it can be bad. When a reviewer reads your paper, the paper should convince him that the solution is a good solution. What I means is that it is not enough to explain your solution. You should also explain why it is a good solution. For example, for a data mining algorithms, you may introduce some optimizations. To show that the optimizations are good optimizations, a good way is to compare your algorithm with and without the optimizations to show that the optimizations improve the performance.
- Respecting the paper format. In general, it is important to respect the paper format, even if it is not the final version of the paper. In particular, I have seen several authors not respect the format for the references. But it is important if you want to give a good impression.
- Mention your contributions. Although it is not mandatory, I recommend to state the contributions that you will make in the paper in your introduction, and to mention them again in the conclusion. If you don’t mention them explicitly, then the reviewer will have to guess what they are.
Obviously, I could write more about this because there is many mistakes that one can make in a research paper. But here, I have just tried to show the most common mistakes.. Hope that you have enjoyed this post. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 52 data mining algorithms.