Today, I will show how to fix the Latex reviewresponse.cls class to allow multi-page comments.
If you have ever written a detailed response to reviewers in LaTeX, you may have noticed that long reviewer comments sometimes get cut off instead of continuing on the next page. This happens because the comments are enclosed in non-breakable tcolorbox environments.
The Problem
In the original version of reviewresponse.cls, the environments for reviewer comments look something like this:
\newenvironment{generalcomment}{%
\begin{tcolorbox}[attach title to upper,
title={General Comments},
after title={.\enskip},
fonttitle={\bfseries},
coltitle={colorcommentfg},
colback={colorcommentbg},
colframe={colorcommentframe},
]
}{\end{tcolorbox}}
\newenvironment{revcomment}[1][]{\refstepcounter{revcomment}
\begin{tcolorbox}[adjusted title={Comment \arabic{revcomment}},
fonttitle={\bfseries},
colback={colorcommentbg},
colframe={colorcommentframe},
coltitle={colorcommentbg},
#1
]
}{\end{tcolorbox}}
\newenvironment{changes}{\begin{tcolorbox}[colback={colorchangebg},
colframe={colorchangeframe},enhanced jigsaw,]
}{\end{tcolorbox}}
These definitions produce nice colored boxes, but the problem is that tcolorbox by default does not break across pages. When your reviewer writes a long paragraph, LaTeX tries to keep the entire box on one page, which can result in missing text or strange layout issues.
The Solution
The fix is simple: you need to make the boxes breakable and enhanced. The tcolorbox package provides two key options for this:
breakable — allows the content to flow onto the next page.enhanced jigsaw — ensures compatibility with decorations, titles, and other layout features when breaking boxes.
Here is the fixed version of the environments:
\newenvironment{generalcomment}{%
\begin{tcolorbox}[
enhanced jigsaw,
breakable,
attach title to upper,
title={General Comments},
after title={.\enskip},
fonttitle={\bfseries},
coltitle={colorcommentfg},
colback={colorcommentbg},
colframe={colorcommentframe},
]
}{\end{tcolorbox}}
\newenvironment{revcomment}[1][]{%
\refstepcounter{revcomment}
\begin{tcolorbox}[
enhanced jigsaw,
breakable,
adjusted title={Comment \arabic{revcomment}},
fonttitle={\bfseries},
colback={colorcommentbg},
colframe={colorcommentframe},
coltitle={colorcommentbg},
#1
]
}{\end{tcolorbox}}
\newenvironment{revresponse}[1][{}]{%
\textbf{Response:} #1\par
}{\vspace{4em plus 0.2em minus 1.5em}}
\newenvironment{changes}{%
\begin{tcolorbox}[
enhanced jigsaw,
breakable,
colback={colorchangebg},
colframe={colorchangeframe},
]
}{\end{tcolorbox}}
Result
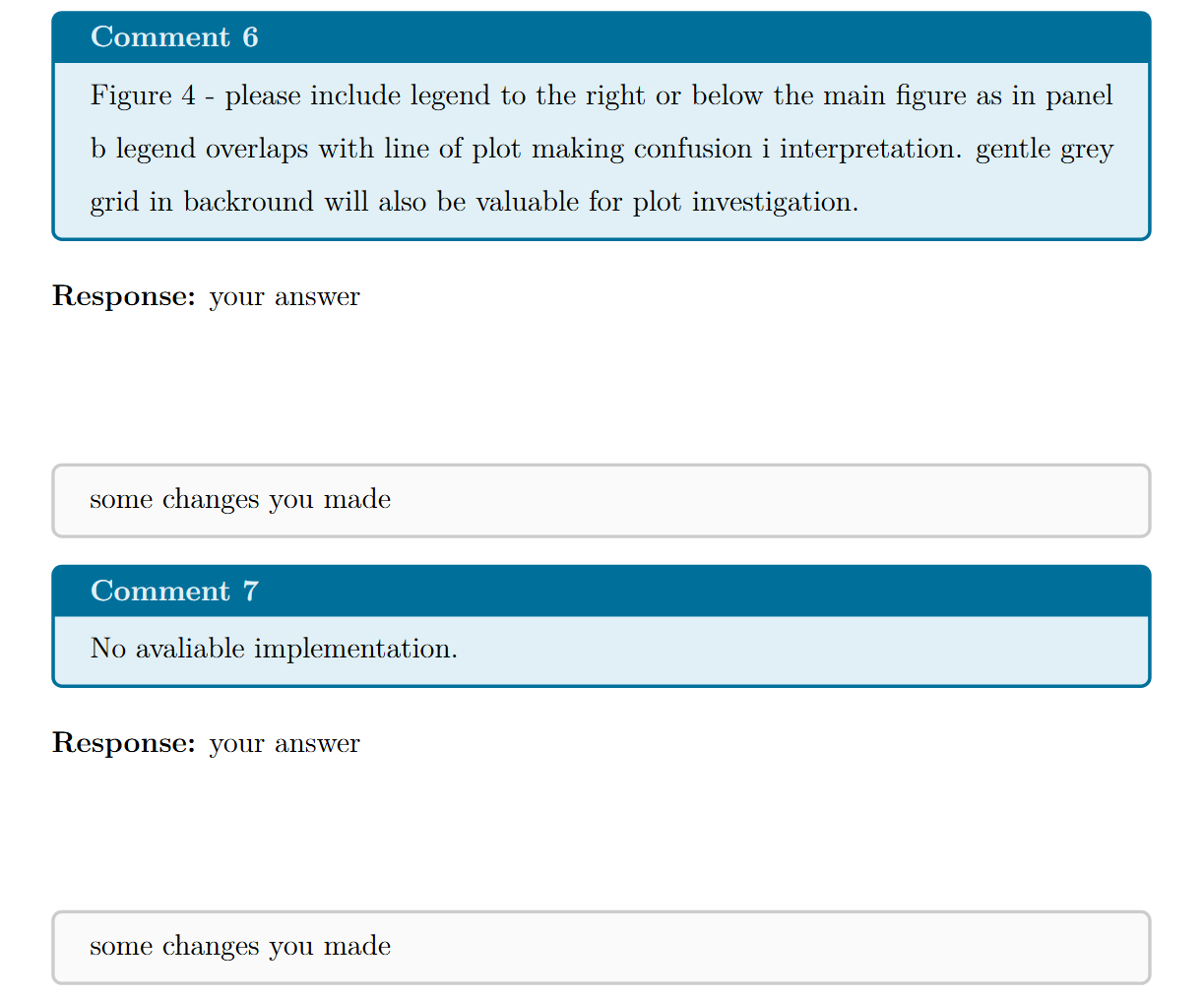
After this modification, your reviewer comments and “changes” boxes will automatically continue onto the next page, no matter how long they are. You can now safely include large comments or detailed explanations without worrying about text being cut off.
Conclusion
By simply adding enhanced jigsaw and breakable to the tcolorbox environments, you make your LaTeX review responses much more robust. This small fix prevents truncated comments and keeps your document professional and reviewer-friendly.