Today, I saw something quite incredible in the Elsevier journal “International Journal of Hydrogen Energy“, which you can see in the screen shot below:

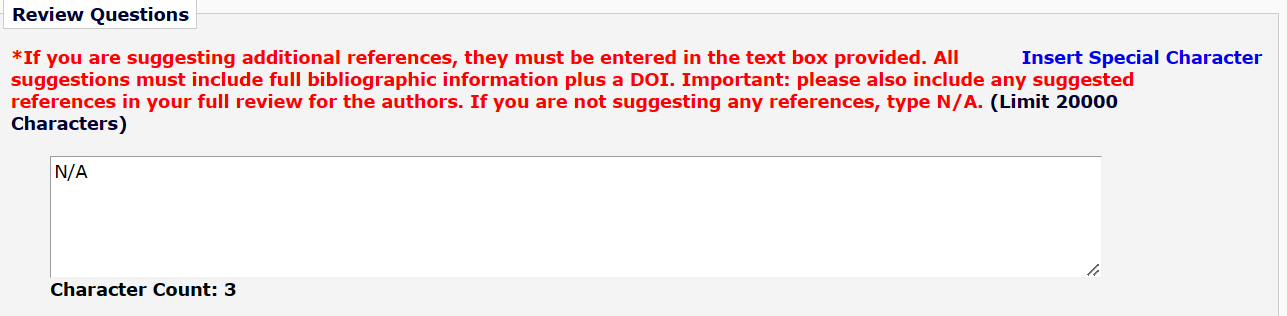
The authors wrote:
As strongly requested by the reviewers, here we cite some references [[35], [36], [37], [38], [39], [40], [41], [42], [43], [44], [45], [46], [47]] although they are completely irrelevant to the present work.
which apparently means that the reviewers forced the authors to cite a dozen unrelated papers, presumably for boosting their citations counts. ]
If we look more closely at these citations, it is not surprising that most of these papers appear to all have a few researchers in common:
- M. El-Ghobashy, H. Hashim, M. Darwish, ... SV. Trukhanov * Eco-friendly NiO/polydopamine nanocomposite for efficient removal of dyes from wastewater Nanomaterials, 12 (7) (2022), 10.3390/nano12071103
- Ahmed Maher Henaish a b , Moustafa A. Darwish a , Osama M. Hemeda a , Ilya A. Weinstein b , Tarek S. Soliman d e , Alex V. Trukhanov f g , Sergei V. Trukhanov f g , Di Zhou h , Ali M. Dorgham Structure and optoelectronic properties of ferroelectric PVA-PZT nanocomposites Opt Mater, 138 (2023), 10.1016/j.optmat.2022.113402
- Marwa M. Hussein,*a Samia A. Saafan,a H. F. Abosheiasha,b Amira A. Kamal, … Sergei V. Trukhanov, Tatiana I. Zubar,f Alex V. Trukhanov ef and Moustafa A. Darwish*a Structural and dielectric characterization of synthesized nano-BSTO/PVDF composites for smart sensor applications Mater Adv, 4 (22) (2023), pp. 5605-5617, 10.1039/D3MA00437F
- Marwa M. Hussein a , Samia A. Saafan a , Hatem F. Abosheiasha b , Di Zhou c , Daria I. Tishkevich d e , Nikita V. Abmiotka e , Ekaterina L. Trukhanova d e , Alex V. Trukhanov d e , Sergei V. Trukhanov d e , M. Khalid Hossain f , Moustafa A. Darwish a Preparation, structural, magnetic, and AC electrical properties of synthesized CoFe2O4 nanoparticles and its PVDF composites Mater Chem Phys, 317 (2024), 10.1016/j.matchemphys.2024.129041
- Dmitry B. Migas, Vitaliy A. Turchenko,c A. V. Rutkauskas,c Sergey V. Trukhanov,de Tatiana I. Zubar,Daria I. Tishkevich,Alex V. Trukhanov and Natalia V. Skorodumovagh Temperature induced structural and polarization features in BaFe12O19 J Mater Chem C, 11 (36) (2023), pp. 12406-12414, 10.1039/D3TC01533E
- D.I. Tishkevich, S.S. Grabchikov, S.B. Lastovskii, S.V. Trukhanov, D.S. Vasin, T.I. Zubar, A.L. Kozlovskiy, M.V. Zdorovets, V.A. Sivakov, T.R. Muradyan, A.V. Trukhanov, Function composites materials for shielding applications: correlation between phase separation and attenuation properties J Alloys Compd, 771 (2019), pp. 238-245, 10.1016/j.jallcom.2018.08.209
- S.V. Trukhanov, V.V. Fedotova, A.V. Trukhanov, et al. Cation ordering and magnetic properties of neodymium-barium manganites Tech Phys, 53 (1) (2008), pp. 49-54, 10.1134/S106378420801009X
- A.V. Trukhanov, D.I. Tishkevich, A.V. Timofeev, et al. Structural and electrodynamic characteristics of the spinel-based composite system Ceram Int, 50 (12) (2024), pp. 21311-21317, 10.1016/j.ceramint.2024.03.241
- A.V. Trukhanov, V.O. Turchenko, I.A. Bobrikov, et al. Crystal structure and magnetic properties of the BaFe12-xAlxO19 (x=0.1–1.2) solid solutions J Magn Magn Mater, 393 (2015), pp. 253-259, 10.1016/j.jmmm.2015.05.076
- S.V. Trukhanov, A.V. Trukhanov, A.N. Vasiliev, et al. Frustrated exchange interactions formation at low temperatures and high hydrostatic pressures in La0.70Sr0.30MnO2.85 J Exp Theor Phys, 111 (2) (2010), pp. 209-214, 10.1134/S106377611008008X
- S.V. Trukhanov, T.I. Zubar, V.A. Turchenko, An.V. Trukhanov, T. Kmječ, J. Kohout, L. Matzui, O. Yakovenko, D.A. Vinnik, A.Yu. Starikov, V.E. Zhivulin, A.S.B. Sombra, D. Zhou, R.B. Jotania, C. Singh, A.V. Trukhanov, Exploration of crystal structure, magnetic and dielectric properties of titanium-barium hexaferrites Mater Sci Eng, B, 272 (2021), 10.1016/j.mseb.2021.115345
- Vinnik D.A., Starikov A.Y., Zhivulin V.E., Astapovich K.A., Turchenko V.A., Zubar T.I., Trukhanov S.V., Kohout J., Kmječ T., Yakovenko O., Matzui L., Sombra A.S.B., Zhou D., Jotania R.B., Singh C., Yang Y., Trukhanov A.V. Changes in the structure, magnetization, and resistivity of BaFe12–xTixO19 ACS Appl Electron Mater, 3 (4) (2021), pp. 1583-1593, 10.1021/acsaelm.0c01081
- Vladimir E. Zhivulin 1 , Evgeniy A. Trofimov 1 , Olga V. Zaitseva 1 , Daria P. Sherstyuk 1 , Natalya A. Cherkasova 1 , Sergey V. Taskaev 2, Denis A. Vinnik 1 11 , Yulia A. Alekhina 3 4 , Nikolay S. Perov 3 4 , Kadiyala C.B. Naidu 5 , Halima I. Elsaeedy 6 , Mayeen U. Khandaker 7 8 , Daria I. Tishkevich 9 , Tatiana I. Zubar 9 , Alex V. Trukhanov 9 10 , Sergei V. Trukhanov Preparation, phase stability, and magnetization behavior of high entropy hexaferrites iScience, 26 (7) (2023), 10.1016/j.isci.2023.107077
I am not working in that field, so I cannot really judge whether these papers are unrelated to the current paper, and we cannot know for sure the identities of the reviewers. Thus, this would require further investigation from the journal to determine what happened in the review process of that paper, and if really the reviewers are the one who asked to cite these papers or not. Thus, we should not jump to conclusions too quickly about this.
Having said that, this whole situation raises questions about the editorial process of the International Journal of Hydrogen Energy, and in particular: (1) why the handling editor did not notice that apparently some reviewers had unethical requests and (2) why the editor and reviewers did not notice the sentence that the author added to their manuscript to complain about the review process before it was published?
I can understand that some problems are unnoticed by the editorial process because there are probably many papers to handle. But now that the problem has been discovered, I guess that the journal should do some investigation around this issue, if it has not been done yet, or if an investigation is not in process.
Update: The paper has been retracted and Elsevier has published the following statement at https://www.sciencedirect.com/science/article/pii/S0360319924043957#:~:text=In%20the%20present%20work%2C%20the%20origin%20of%20the,but%20the%20tetrahedral%20interstice%20in%20Zr%20and%20Hf.:

This blog post was just to share what I found about this story on social media. I am not involved in this paper, nor in this field, in this journal. But I know that there are many unethical reviewers in academia that ask to cite their papers or papers from their friends. And it is still quite surprising to see that this is mentioned directly in a paper like this. Thus, I decided to share the story on this blog.