This is the fifth blog post about writing research papers. Today, I will discuss how to select references and write the bibliography of a research paper. I will also explain some common errors and give additional tips.
Why the bibliography is important?
Every researchpaper must have a bibliography. The purpose of the bibliography is to let the reader know about the sources of information (e.g. research papers, books, webpages) that have been used to write the paper. More specifically, the bibliography is used to give credit to some ideas that are reused or adapted in the current paper and to cite relevant related papers.
A good bibliography will give a good overview of related work and will give credit to other papers when credit is due. A bad bibliography may contain errors and may omit some important references. Moreover, the references may be cited in an inappropriate way. It is important to prepare well the bibliography of a researchpaper to increases its chances of getting accepted.
Some common problems
Here are a few common problems found in bibliographies:
References contain incorrect information. For example, a paper may be cited with the wrong page numbers, or incorrect information about the publisher. To avoid this problem, it is important to double-check all the information to ensure that it is correct. Many researchers will use some website such as Google Scholar to generate bibliographical entries in the appropriate format. Although this can save some time, the generated references often contain errors either in terms of information or format because they are machine-generated.
References are not formatted properly. Generally, a publisher will require that references are formatted in a specific format, or sorted in a specific order (e.g. alphabetical order). It is important to get familiar with and follow these rules. I have seen some journals that have rejected papers just because the references were not in the correct format, and asked to submit them again. Besides, the format must be consistent for all bibliographical entries.
References are too old. A bibliography should be up-to-date. If a paper does not cite any papers from the last few years, it generally means that authors are unaware of recent papers. I often see this problem when some authors publish papers a few years after writing their Ph.D. thesis. Often, they will not update the bibliography. Some reviewers think that an out-of-date bibliography is a good enough reason to reject a paper.
References are not cited in the text. All references from a bibliography must be cited in the text.
References to Wikipedia or similar websites. One should avoid citing Wikipedia in a scientific paper.
Low quality references. When possible, it is recommended to not cite papers having a weak research content, or published in journals that do not have a good reputation such as predatory journals (unless there is a good reason to do so). One should prefer citing papers that have good research content or are published in good journals and conferences.
Not citing papers in a correct way in the text. There are some researchers that will cite a paper and then copy and paste some text from that paper. If it is not explicitly mentioned that the text is copied from the original paper using quotation marks and with a citation, then this is plagiarism. This is a very serious issue. There also exists other types of plagiarism such as copying an idea but rewriting it differently without citing the paper. One should avoid doing this.
Too many self-citations. It is OK for one to cite his own papers. However, there should not be too many of those self-citations, except when there is a good reason. For example, I have reviewed some papers containing about 30 references but where more than 15 were by the authors. This is way too many self-citations. It can lead to directly rejecting the paper. A rule of thumb is that not more than about 10 % of the references should be self-citations.
Irrelevant references. This is another problem often related to the previous one. In some cases, an author will cite many of his own papers to increase his citation count, although these papers are not relevant to the current paper. In general, one should only cite relevant papers.
Tips for preparing a bibliography
Some tips:
There exists many websites and software that can help to prepare a bibliography. However, one should be careful when using tools that automatically generate a bibliography, as it may produce errors.
When starting a new research project, it is a good habit to keep track of all the papers that one reads and take notes about them. This will facilitate writing about related work and preparing the bibliography.
Before submitting a paper, always double-check the requirements of the publisher in terms of format and make sure that the paper is following them.
Conclusion
I have discussed how to write the bibliography of a researchpaper, common problems and given a few tips. Hope this will be useful. If you think I have missed something, please share it in the comment section.
—- Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.
This is the fourth blog post on how to write research papers. Today, I will discuss how to write the introduction of a scientific research paper, some common errors, and give some tips.
Why the introduction is important?
The introduction plays a very important role in a paper. If the introduction is not well-written and convincing, the reader may decide to stop reading the paper. The role of the introduction is to explain the context of the paper, describes the problem that will be addressed in the paper, briefly mention why previous studies have limitations with respect to that problem, and then briefly explain what will be the contribution of the paper.
A good introduction will have a clear logical structure, and will convince the reader that the problem addressed in the paper is worthy of being investigated (it is a novel problem that cannot be solved using existing approaches, it is not easy to solve, and solving this problem is useful). Moreover, the introduction will give an overview of the paper.
On the other hand, a bad introduction will be poorly organized and will not convince the reader that the problem addressed in the paper is useful, important or challenging. Thus, after reading the introduction, the reader may lose his interest in the paper. Writing a good introduction is thus very important.
What is the typical structure of an introduction?
Generally, the introduction of research papers always have more or less the same structure:
PART 1 (context): The first paragraph introduces the broad context of the paper, and then progressively goes from that broad context to a more specific context
PART 2 (problem): Then, a problem is mentioned and why it must be solved.
PART 3 (limitations): Then, the introduction briefly mentions that previous studies failed to solve that problem or have limitations. Hence, a new solution is needed (which will be described in the paper).
PART 4 (contributions): The following paragraph briefly mention the main contributions of the paper and the key features of the proposed solutions. This may include one or two sentences about the results and conclusion drawn from these results.
PART 5 (plan of the paper): Then, often there will be a short paragraph explaining how the rest of the paper is organized. For example: “The rest of this paper is organized as follows… Section 2 discussed related work. Section 3 …. Finally, a conclusion is drawn in Section 5.“
Some common errors
Here is a few common errors found in introductions:
English errors: An introduction should be well-written and devoid of English errors.
Poor structure: Some introductions do not follow the typical structure of an introduction, and are not organized in a logical way. In this case, the reader may feel lost, may become uninterested or may not be convinced that the research presented in the paper is worthy of being investigated. As a result, the reader may stop reading.
A very long introduction, with unnecessary details: Another common mistake is to write a very long introduction that contains too many details. But an introduction should generally be no longer than a page. Often, an introduction will contain too many details about related work that are not relevant for the purpose of the introduction. The introduction should only briefly discuss related work to explain the motivation of the paper. More details about related work can be given in other parts of the paper such as a dedicated “related work” section.
An introduction that is not convincing. The introduction needs to convince the reader that the research problem studied in the paper is important, useful and not trivial to solve. In many papers, a mistake is to not explain why the studied problem is useful. For example, in data mining research, I have read many papers that proposed some new algorithms, evaluated the algorithms with synthetic data, but did not explain clearly or show what are the real applications of the proposed algorithms.
An introduction that omit some relevant related work. Sometimes, the introduction of a paper will not cite some relevant studies. This happens when the author is not very familiar with his field of research, and sometimes authors will purposely not cite some relevant papers for various reasons. This can cause a paper to be rejected by reviewers.
A few tips
To write a good introduction:
Make a plan of the main ideas that you want to talk and the structure of your introduction before writing it. This will help to organize your ideas, and will help to create an introduction that is logically organized.
When planning or writing your introduction, think about your target audience. Choose words and expressions that are appropriate for that audience. In the first paragraph, you can also explain the context of your work in a more general way to try to reach a broader audience.
Reading the introductions of other papers, and studying their structure, can help to write better introductions.
If necessary, ask a native English speaker to proofread your text.
After writing the introduction, read it again, and spend some time to think about how you can improve it. Generally, taking time to read your text again will help to improve your writing skills.
Conclusion
That is all for this topic! In this blog post, I provided some key ideas about how to write introductions of research papers. If you have any additional comments, please leave them in the comment section below. Hope you have enjoyed this post.
—- Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.
In this blog post, I will continue the discussion of how to write research papers. I will discuss the importance of writing a good abstract for research papers, common errors, and give some tips.
Why the abstract is important?
The abstract is often overlooked but it is one of the most important part of a paper. The purpose of the abstract is to provide a short summary of a paper. A potential reader will often only look at the abstract and title to decide to read a paper or not. A good abstract will increase the probability that a paper is read or cited, while a bad abstract will have the opposite effect.
The abstract is also very important because many papers are behind a paywall (a publisher will only provide the abstract and ask readers to pay to read the full paper).
What is the typical structure of an abstract?
The structure of an abstract is always more or less the same. Typically, it is a single paragraph, containing five parts:
PART 1 (context): The first sentences talk about the context (background) of the paper from a very general perspective.
PART 2 (problem): Then, a problem is mentioned and why it must be solved.
PART 3 (limitations): Then, the abstract briefly mentions that solutions proposed in previous studies are insufficient to solve the problem due to some limitations. Thus, we need a new solution.
PART 4 (contributions): Then, the abstract mentions the contributions of the paper, which is to propose a new solution, and what are the key features of that solution.
PART 5 (results and conclusion): Then, one or two sentences are used to briefly mention the experiment results, and conclusion or implications that can be drawn from these results.
This type of structure gives a concise overview of the content of the paper. The next paragraph gives an example of an abstract, which adopts this structure, from the paper describing the EFIM algorithm:
PART 1: In recent years, high-utility itemset mining has emerged as an important data mining task. PART 2 and 3: However, it remains computationally expensive both in terms of runtime, and memory consumption. It is thus an important challenge to design more efficient algorithms for this task. PART 4: In this paper, we address this issue by proposing a novel algorithm named EFIM (EFficient high-utility Itemset Mining), which introduces several new ideas to more efficiently discover high-utility itemsets. EFIM relies on two new upper-bounds named revised sub-tree utility and local utility to more effectively prune the search space. It also introduces a novel array-based utility counting technique named Fast Utility Counting to calculate these upper-bounds in linear time and space. (… ) PART 5: An extensive experimental study on various datasets has shown that EFIM is in general two to three orders of magnitude faster than the state-of-art algorithms d2HUP, HUI-Miner, HUP-Miner, FHM and UP-Growth+ on dense datasets and performs quite well on sparse datasets. Moreover, a key advantage of EFIM is its low memory consumption.
There is typically a maximum length restriction for an abstract. For example, some journals may require no more than 200 words. For a very short abstract, the PARTS 1,2,3 can be made very short or ommitted to focus on PART 4 and 5. For example:
PART 1,2,3: High utility itemset mining has many applications but performance remains an important issue. PART 4: To address this problem, a novel algorithm named EFIM (EFficient high-utility Itemset Mining) is presented, which relies on two new upper-bounds to prune the search space, and a novel array-based utility counting technique. PART 5: Experiments have shown that EFIM has low memory consumption and is up to 50 times faster than state-of-art algorithms on dense datasets and performs quite well on sparse datasets.
For some other types of paper such as survey papers the structure is similar but some parts are omitted. Here is an example from a survey paper about frequent itemset mining:
PART 1: Itemset mining is an important subfield of data mining, which consists of discovering interesting and useful patterns in transaction databases. The traditional task of frequent itemset mining is to discover groups of items (itemsets) that appear frequently together in transactions made by customers. Although itemset mining was designed for market basket analysis, it can be viewed more generally as the task of discovering groups of attribute values frequently co-occurring in databases. Due to its numerous applications in domains such as bioinformatics, text mining, product recommendation, e-learning, and web click stream analysis, itemset mining has become a popular research area. PART 4: This paper provides an up-to-date survey that can serve both as an introduction and as a guide to recent advances and opportunities in the field. The problem of frequent itemset mining and its applications are described. Moreover, main approaches and strategies to solve itemset mining problems are presented, as well as their characteristics. Limitations of traditional frequent itemset mining approaches are also highlighted, and extensions of the task of itemset mining are presented such as high-utility itemset mining, rare itemset mining, fuzzy itemset mining and uncertain itemset mining. The paper also discusses research opportunities and the relationship to other popular pattern mining problems such as sequential pattern mining, episode mining, subgraph mining and association rule mining. Main open-source libraries of itemset mining implementations are also briefly presented.
Which verb tense should be used?
A good question is: Which verb tenses should be used in an abstract? Some general suggestions are:
To describe previous studies, the past tense is used,
To present general facts, the present tense is used
To discuss the contributions of the paper or what the paper will present, the present tense is recommended (e.g. “This paper proposes an algorithm named …”) .
If the abstract discusses some experimental results, the past tense is recommended (e.g. “Experiments have shown that…”)
Some common errors
I will now discuss six common errors found in abstracts:
An abstract containing English errors. The title is the first thing that someone reads, and then it is the abstract before reading the whole paper. If a title or an abstract contains English errors, it may give a bad impression to readers.
An abstract that does not accurately describe the content of the paper. Sometimes, only the abstract is available to the reader. If the abstract does not give a good overview of the paper, one may not try to access the full paper.
An abstract that does not follow the typical structure and is not logically organized. A good abstract will follow the standard structure described in this post, to ensure that ideas are presented in a logical way.
An abstract that contains abbreviations and acronyms. Generally, it is recommended to avoid using acronyms and abbreviations in an abstract since the reader may not be familiar with them. Moreover since abstracts are short, it is typically unnecessary to define abbreviations in an abstract.
An abstract that contains citations, or refer to tables and figures. An abstract should not contain citations, except in some exceptional cases. Moreover, an abstract should never refer to figures or tables.
An abstract that contains irrelevant details. Given that an abstract is often restricted to a maximum length, it is important to avoid wasting this space by discussing details that are not important. Thus, the abstract should be concisely written and focus on the key points of the paper.
A few tips
Here are a few additional tips about writing an abstract:
Before writing, check if there is a maximum length constraint for the abstract, specified by the publisher.
Think about your target audience and use appropriate keywords and expressions in your abstract to ensure that other people in your field can find your paper.
A good way to learn how to write abstracts is to look at the abstracts of other papers in your field.
Take your time to write an abstract. If necessary, show it to a peer and ask his opinion.
If necessary, ask someone to proofread your abstract to remove all English errors.
Write sentences that are not too long, and are concise.
Several researchers prefer to write an abstract after all the other parts of the paper have been written. This make sense since the abstract is a summary of the content of a paper. However, do not only copy and paste sentences from the paper to write the abstract. You may reuse some parts of sentences from the paper but you should adapt them.
Conclusion
That is all for this topic. I hope that you have enjoyed this blog post. I will continue discussing writingresearch papers in the next blog post. Looking forward to read your opinion and comments in the comment section below!
—- Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.
This week, I am attending the IEA AIE 2018 conference( 31st International Conference on Industrial, Engineering & Other Applications of Applied Intelligent Systems) in Montreal, Canada.
About the conference
The IEA AIE conference is an international conference on artificial intelligence and related topics.
Conference opening
On Tuesday morning, it was the conference opening.
This year, 146 papers have been submitted from 44 countries. From those 35 papers had been accepted as long papers, and 29 as short paper, and 22 papers in some special tracks. Thus, the acceptance rate for long paper is about 23%, while the global acceptance rate is around 59 %. More details about the review process:
Here is a breakdown of topics of papers submitted to the conference (from the conference opening):
It was also announced that next year, IEA AIE 2019 will be held in Graz, Austria ( http://ieaaie2019.ist.tugraz.at/ ). Then, IEA AIE 2020 will be held in Japan.
I estimate that there was about 80 persons attending the conference.
Conference location
The conference was held at the Concordia University in Montreal, Canada. The university is in the nice downtown area of Montreal. The talks where held in some meeting rooms or classrooms of the university.
Conference materials
After registering, I received a conference bag with a few papers, a pen, a notepad and the proceedings on a USB stick.
At the end of the conference, free copies of the proceedings were offered on a first come first serve basis.
Keynote talk by Guy Lapalme on Question Answering Systems
The first keynote talk was given by Guy Lapalme from the University of Montreal, and was titled “Question-Answering Systems: challenges and perspectives“. It gave an overview of research on Query-Answering Systems. I will give a brief description of this talk, below.
The speaker explained what is query answering by comparing it with information retrieval. Information retrieval is about finding documents. On the other hand, question-answering is not about finding documents but about finding answers to questions. A question-answering system according to Maybury (2004) is an interactive system, which can understands the user needs given in natural language, search for relevant data, knowledge and document, extract and prioritize answers, and shows and explain answers to the user.
Building a question-answering system requires to consider several aspects related to natural language processing (question/document analysis, information extraction, natural language generation and discourse analysis), information retrieval (query building, document parsing and providing relevant feedback) and computer-human interaction (user preferences and interaction).
Several question answering systems will be build based on some assumptions. Some of these assumptions are that the user prefers an answer rather than a document, it is not necessary to look at the context, we are dealing with closed questions (not questions such as: what is the purpose of life?), answers are given as nominal phrases or numbers instead of a procedure.
Question-answering was studied since the 1970. Researchers found that obtaining the general understanding of a question and its answers is a very difficult problem. Thus, in the nineties, research was more focused on answering simple questions about facts such as “Where is the Taj Mahal?” or “Name a film which actor A acted”. Nowadays these questions are easily answered by some Web search engines. Then, how to answer more complex questions have been studied by researchers.
There are different types of question answering system. The most simple ones try to directly find verbatim answers in documents by keyword matching, and do simple reasoning. More advanced system can do analogical, spatial and temporal reasoning to answer more complicated questions such as “Is Canada still in recession?”. Some systems are also interactive (the system can remember previous questions and answers).
A simple question answering system has three main components respectively (1) to analyse questions to find the type of expected answers (who, what where, how? ) , (2) to analyze documents and find interesting sentences, and (3) to extract answer, evaluate the answers (correct vs incorrect vs correct but without backing from a document).
Commercial systems like Alexa, Google Assistant and Cortana can usually answer simple questions that are task oriented, and can sometimes maintain a conversation context.
There was then more explanations. The conclusion of the talk was that question answering is hard and is far from being a solved problem. Moreover, even if many question answering systems are restricted to specific tasks, they can already answer interesting services.
Conference reception
One of the highlight of this conference was that the conference reception was held at Musée Grévin, a wax museum. This was quite special and was also a good opportunity to discuss with other researchers.
Keynote talk by Far H. Behrouz on Autonomous and Connected Vehicles
The second keynote talk was by Far H. Behrouz from the University of Calgary. It gave an overview of technologies for autonomous and connected vehicles and prospects in that field.
The main motivations for autonomous vehicle development is to reduce pollution and improve safety, and increase transportation efficiency. The introduction of connected and autonomous vehicles can bring benefits but can also have impacts such as disruption and loss of jobs (e.g. truck drivers) and resources.
Some terms used to describes autonomous vehicles are “Autonomous Ground Vehicles (AGVs), “Unmaned Ground Vehicles (UGVs)” (autonomous, self-driving, driverless vehicles), and Intelligent Transportation Systems (ITSs). Some studies have suggested that autonomous vehicles could reduce road fatalities by 1,600 a year in Canada, and bring billions of dollars in economic benefits. Manufacturers have said that UGVs would be available in 2020-2025.
Developing autonomous vehicles requires many advanced technologies, including sensor technology, navigation technology, communication technology, algorithms (control, guidance), data technology, software technology (artificial intelligence, machine learning, personalized guidance), and computing infrastructure (e. cloud). Below, more details will be provided about each of them.
1) Sensor technology: many types of sensors are available from GPS, camera, odometer, laser scanner, LiDAR and Radar. A modern automobile may have 1500+ sensors.
2) Navigation technology: There are both visual and non visual navigation systems. Visual systems use technologies such as pattern recognition, and feature tracking and matching.
3) Communication technology: Initially, a major problem was the range of communication. Nowadays several standards have been proposed for long range communication, including cellular technology.
4) Algorithms: This includes algorithms for localization, guidance and control, cooperative multi-sensor localization, advanced driver assistance systems, etc.
5) Data technology: Large amount of structured and unstructured data must be handled. Performance, availability, data security, resiliency, management and monitoring are important.
6) Software technology: This includes artificial intelligence and machine learning techniques, multi-agent systems, personalized intelligent transportation solutions (monitoring and warning systems). It is also desirable to combine sensory information with real time data, navigation technology and artificial intelligence.
Personalized Intelligent Transportation System solutions
7) Computing infrastructure
The speaker then explained that cheap Unmanned Ground Vehicles can be designed with technology that is available today. He has shown some simple examples.
The speaker then discussed about more technical details and more complex prototypes that were built in his lab.
Conference banquet
The conference banquet was at an archaeology museum called “Musée Pointe à Callières”. The dinner was fine.
Conclusion
That is all I wanted to write about the conference. It was not the first time that I have attended the IEAAIEconference. I have also attended it in 2009 and 2016. If you are curious, here is my report about IEAAIE 2016 in Japan.
—- Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.
Today, I will continue my series of blog posts about how to write research papers. I will discuss the importance of choosing a good title for research papers, some common errors, and give some tips.
Why the title is important?
The title and abstract are some of the most important parts of a paper because this is what one will typically first look at when searching for papers. A good title will make it easy to find the paper, and increases its visibility. What is a good title? I will discuss this in details in this post. But generally speaking, it should describe the content of the paper well and make it easy for the target audience to find the paper. Moreover, a good title should not be misleading or contain errors, as it may give a bad impression to potential readers.
Some common errors
Let’s first discuss some common errors in titles of research papers:
A title containing English errors. I often see titles containing English errors. This is a very serious problem because not only it gives a bad impression to potential readers but also it gives a bad impression when applying for jobs, as the title will appear in the CVs of authors, and cannot be changed after it is published. Thus, ensuring that there is no English errors is crucial. An example is the title of a paper in the GESTS International Transactions on Computer Science and Engineering journal: “Association rules mining: A recent overview“. Here “rules” should be written as “rule”.
A title that is too short or too broad. A title should give a good overview of the content of a paper. For example, a title such as “Methods to analyze data” would be too broad, as it does not tell what kind of methods is used or what kind of data is analyzed. A better title could be “Clustering algorithms to analyze e-learning data”. This is already much better.
A title that is too long. A common mistake for young researchers is to write titles that are very long to try to make the title very specific. Just like titles that are too broad, a title that is too specific is bad. A good rule of thumb is to try to write titles containing no more than 10 words. An example of title that is too long is: “Management and analytic of biomedical big data with cloud-based in-memory database and dynamic querying: a hands-on experience with real-world data” published in the proceedings of the KDD 2014 confeence. This title contains about 24 words and in my opinion contains a lot of unnecessary information. For example, “a hands-on experience with real-world data” could be removed to make the title shorter. I would rewrite the title as: “Biomedical data analytics with distributed in-memory databases”. This is only 7 words instead of 24 and it keeps the main information.
A title that contains unnecessary information. A good title should not contain unnecessary information. An example is the word “new” in this title “New algorithms for parking demand management and a city-scale deployment.” from a KDD 2014 paper. The word “new” should be removed since the algorithms are always new in a researchpaper. Another example is this title “Applying data mining techniques to address critical process optimization needs in advanced manufacturing.” from KDD 2014. In that title, the words “applying”, “needs” and “advanced” are unnecessary. The title could be rewritten as : “Data mining techniques for critical process optimization in manufacturing”.
A few more tips
Here are a few additional tips about writing a title:
As shown in the above example, a title can often be made shorter. Thus, after writing a title, one should spend some time to think about how to make it shorter.
A good idea is to write several potential titles and then choose the best one. One may also ask a colleague to help select the best title.
When choosing the title, one should think about the target audience of the paper. In particular, one should think about which keywords may be used to search for the paper, to ensure that other researchers will find it. Sometimes a paper may have more than one target audience. Thus, one may have to take a decision.
Avoid using abbreviations in titles as the reader may not be familiar with them. If the abbreviations are well-known such as H2O, it is no problem. But if the abbreviations are not well-known for the target audience, it will reduce the visibility of the paper.
A title does not need to be a complete sentence. A good title is short and descriptive.
A good way to learn how to write titles is to look at the titles of other papers in the same field.
Conclusion
I hope that you have enjoyed this blog post. If you have other suggestions or questions, please share them in the comment section below. If there is interest, I will continue writing more blog posts on paperwriting in the future.
—- Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.
Today, I will give some advice about how to write research papers. This will be the first post of a series of posts on this topic. In this post, I will focus on one aspect, which is to use simple structures and expressions to present the content of a paper. This is a very simple idea. But it very important.
Generally, the goal of writing a paper is to communicate some idea (the research contributions) to the reader. To do that, it is important to write in a clear way by using simple structures. Otherwise, the reader may not understand well your paper. This is different from other types of texts such as poetry or novels, where writing using complex structures, rare words and expressions can be considered better.
Let me give you some examples. Below is a table with some unnecessarily complex structures (left) which can be replaced by more simple structures (right) to express the same idea:
Complex structure
Simple structure
the great majority
most
an example of this is the fact that
for example
based on the fact that
because
for the purpose of
for
in a number of cases
sometimes
in order to
to
with the exception of
except
As shown above, it is often possible to replace four or five words by fewer words to express the same idea.
Why is it important to do that?
It saves space.
Readers better understand the content of the paper. In particular, the paper is easier to read for non native English speakers.
If you want to know more about this, there is a good list of complex structures that can be replaced by more simple structures in the book “How to write an publish a Scientific paper” by R. A. Day et al.) . You can click here for the list (PDF). I have used this list to prepare the above examples.
Besides, what I discussed today, I also recommend to avoid writing very long sentences. A sentence should not contain more than a single idea. Also, the structure of a paper is very important. I will discuss this in another blog post.
—- Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.
In this blog post, I will talk about the importance of attendingacademicconferences for researchers. I will answer two important questions: Why it is important to attend conference? and What one should do at an academic conference to get the most benefits?
Academic conferences
Academicconferences are meetings attended by researchers mostly from academia,. Typically attendees are professors, students, researchers, and researchers from the government or industry. Academicconferences are different in various fields. But generally, a person who wishes to attend a conference will submit a paper or an abstract to the conference. Then, the paper or abstract is evaluated by some researchers, and if the paper is accepted, the person can attend the conference and present his research work at the conference. Generally, one presents his work as a short talk (10 to 30 min) or as a poster during a poster session.
Why is it important to attend a conference?
First, it is important to understand that different people will attend a conference and their goals are not the same. For the student, attending a conference has several benefits:
Getting feedback on hisresearch project,
Discussing ideas with other researchers,
Learning about other projects in his field,
Practicing giving a talk in front of an audience (this is not an easy task… it requires to explain your work in a simple way in a fixed amount of time) and answering questions about your work sometimes in a foreign language.
Connecting with other people in your field that you may work with in the future.
Travelling (this is not the main goal of attending a conference but it is always nice to see other places),
For the professors, the benefits are similar. But after a few years of working in the same research community, the focus starts to change from attending paper presentations to connecting with people. Actually, a researcher should not work alone if he wants to be successful. Thus, to create opportunities, it is important to connect with other researchers. In my case, the best part of the conference is thus to meet and talk with other researchers, rather than attending the paper sessions. This year, for example, I have attended the PAKDD 2018 conference and it has been great. I have attended some good talks. But most importantly I had discussions with many researchers, including some that I often see on some papers but had never met. This can create some new opportunities.
For researchers from the industry or government,academicconferences are useful to get familiar with the new methods developed in academia, and sometimes to try to recruit people from academia, and also meet researchers.
What one should do at an academic conference?
Now, I will give some advices about what one should do when attending a conference. The first thing is to prepare your presentation before attending the conference (if you have to give a talk). By doing this, you will not be worried about giving a talk and can then focus on listening to other talks and meeting people.
The second advice is to carefully look at the program (schedule) of the conference to select the events and talks that are the most interesting for you to attend.
The third advice is to check the list of people who will attend the conference to see which people from your field will attend the conference. This can give you some idea about who you may want to try to talk with.
The fourth advice is to try to attend all the social activities and try to talk with as many people as possible. If you have name cards, bring some with you, and exchange it with other people, or ask for their name cards.
The fifth advice is to focus on attendingconferences that are good and relevant to your field. If one attends conference that are irrelevant, of low quality or cover a too broad field of research, then he is unlikely to meet people that will be interesting for his research work, and he may not get interesting feedback on his work. Thus, it is always important to send papers to relevant conferences and journals.
Conclusion
In this blog post, I discussed the importance of attendingacademicconferences and what one should do at academicconferences to get the most benefits out of it. Academicconferences are a very important activity to be a successful researcher, as sooner or later in the career of a researcher, it is necessary to collaborate with others on projects, apply for grants, organize events, and other things.
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.
In this blog post, I will discuss the PAKDD 2018 conference (Pacific Asia Conference on Knowledge Discovery and Data Mining), in Melbourne Australia, from the 3rd June to the 6th June 2018.
About the PAKDD conference
PAKDDis an important conference in the data science / data mining research community, mainly attended by researchers from academia. This year was the 22nd edition of the conference, which is always organized in the pacific asia region. In the last few years, I have attended this conference almost every year, and I always enjoy this conference as the quality of research papers is good. If you are curious about previous conferences, I have previously written reports about the PAKDD 2014 and PAKDD 2017 conferences.
The conference was held in the Grand Hyatt Hotel, in Melbourne, Australia, a modern city.
During the opening ceremony, several statistics were presented about the conference. I will share some pictures of some slides below that give an overview of the conference.
A picture of the opening ceremony
This year, more than 600 papers were submitted, which is higher than last year, and the acceptance rate was around 27%.
The papers were published in three books published by Springer in the LNAI (Lecture Notes in Artificial Intelligence) series.
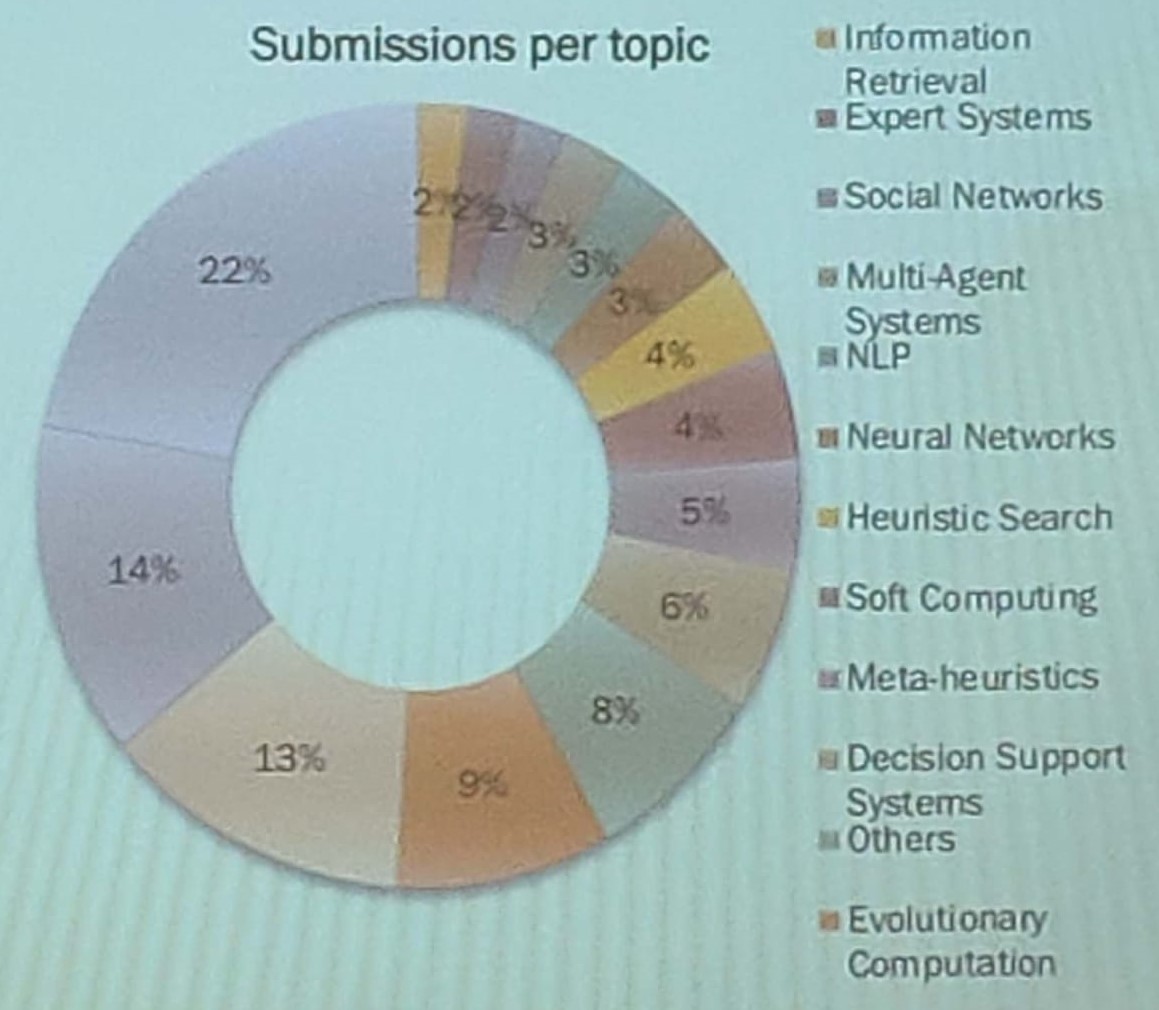
Below is some information about the top 10 topics of the papers that were submittedBelow is some information about the top 10 accepted areas, where more papers have been accepted. For each topic, two values are indicated. The first one indicates the percentage of papers on this topic, while the second one indicates the acceptance rate of the topic.
Below, there is a chart showing the acceptance rates and attendance by countries. The top two countries are the United States and China. Five workshops have been organized at PAKDD2018, as well as a data competition., and three keynote speakers gave talks.
And here is the list of previous PAKDDconference locations:
It was also announced that PAKDD 2019 will be held in Macau (http://pakdd2019.medmeeting.org/Content/91968 ), China. Moreover, I also learnt that PAKDD 2020 should be in Qingdao, China, and PAKDD 2021 should be in New Dehli, India.
Keynote speech by Kate Smith Miles
A very interesting Keynote speech was given by Kate Smith-Miles with the title “Instance Spaces for Objective Assesment of Algorithms and Benchmark Test Suites“. I think that this presentation was very interesting and can be useful to many, so I will give a brief summary of the key points and provides a few pictures of the slides with comments. What is the topic of this talk? It is about the evaluation of data mining algorithms to determine which algorithm is the best and in which situation(s).
In data mining, usually, when a new algorithm is proposed, it is compared with some state-of-the-art algorithms or baseline algorithm to show that the new algorithm is better. According to the No Free Lunch Theorem, it is quite difficult to design an algorithm that is always better than all other algorithms. Thus, an algorithm is typically better than other algorithms only in some specific situations. For example, an algorithm may perform better on datasets (instances) that have some specific properties such as being dense or sparse. Thus, the choice of datasets used to evaluate an algorithm is important as results will then provides insights on the behavior of the algorithm on datasets having similar features. Thus, to properly evaluate an algorithm, it is important to choose a set of databases (instances) that are diverse, challenging and real-world like.
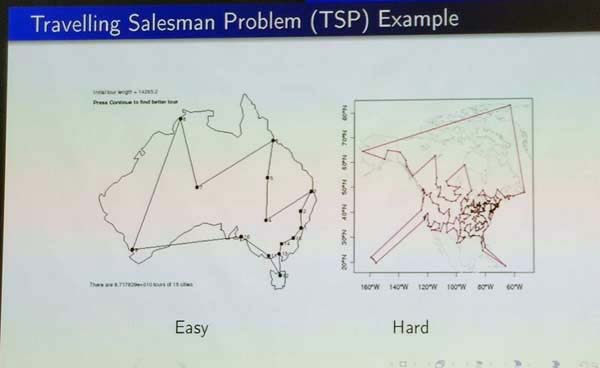
For example, consider the Travelling Salesman Problem (TSP), a classic optimization problem. On the slide below, two instances are illustrated, corresponding to Australia and United States. The database instance on the left is clearly much easier to solve for the TSP problem than the one on the right.
Thus, an important question is how the features of database instances help to understand the behavior of algorithms in terms of weaknesses and instances. Some other relevant questions are how easy or hard are some classic benchmark instances? how diverse are they (do they really allow to evaluate how an algorithm behave in most cases, or does these instances do not cover some important types of databases)? do the benchmark instances are representative of real-world data?
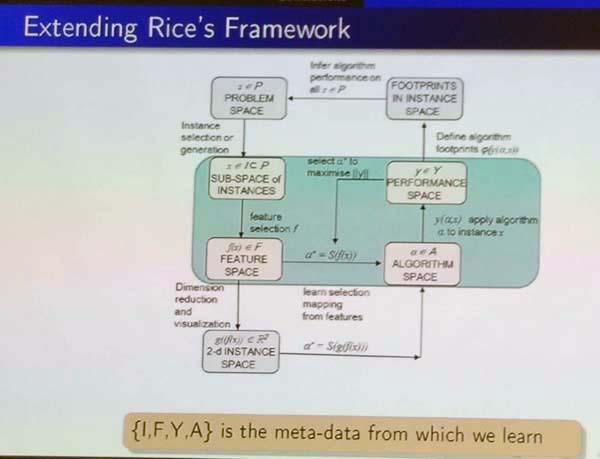
To address this problem, the speaker has developed a new methodology. The main idea is that database instances are described in terms of features. Then, a set of instances can be visualized to see how well they cover the space of all database instances. Moreover, by visualizing the space of instances, it is easier to understand when an algorithm works well and when it doesn’t. Besides, in the proposed methodology, it is suggested to generate synthetic instances using for example a genetic algorithm to have instances with specific features. By doing that, we can ensure to have a set of instances that provide a better coverage of the instance space (that is more diverse) for evaluating algorithms, and thus provide a more objective assessment of the strengths and weaknesses of algorithms.
Below, I show a few more slides that provides more details about the proposed methodology. This is the overall view. The first step is to think about why a problem is hard and what are the important features that makes an instance (database) a difficult one. Moreover, what are the metrics that should be used to evaluate algorithms (e.g. accuracy, error rate).
The second step is about creating the instance spaces based on the selected features from the previous step, and determine which ones are more useful to understand algorithm performance. The term step is to collect data about algorithm performance and analyze in which parts of the space and algorithm performs well or poorly. This is interesting because some algorithm may perform very well in some cases but not in others. For example, if an algorithm is the best even in just some specific cases, it may be worthy research.In step 4, new instances are generate to test other cases that have not been tested by the current set of instances. Then, the step 1 can be repeated again based on results to gain more information about the behavior of algorithms.
So this is my brief summary of they key ideas in that presentation. Now, I will give you my opinion. This presentation highlights an important problem in data mining, which is that authors of new algorithms often choose just a few datasets where their algorithm perform well to write a paper but ignore other datasets where their datasets do not perform well. Thus, it sometimes become hard for readers to see the weaknesses of algorithms, although there is always some. This is also related to the problem where authors often do not compare their algorithm with the state-of-the-art algorithms and do not use appropriate measure to compare with other algorithms. For example, in my field of pattern mining, many papers do not report the memory consumption or compare new algorithms with outdated algorithms.
Organization of the conference
The conference is quite well-organized. The location at the Grand Hyatt Hotel is fine, and the city of Melbourne is also a great city with many stores and restaurants, which is interesting and convenient. By registering to the conference, one has access to the workshops, paper presentations, banquet and a welcome reception. Here is a picture of the registration desk, and conference badge:
Keynote by Rajeev Rastogi (director of machine learning at Amazon)
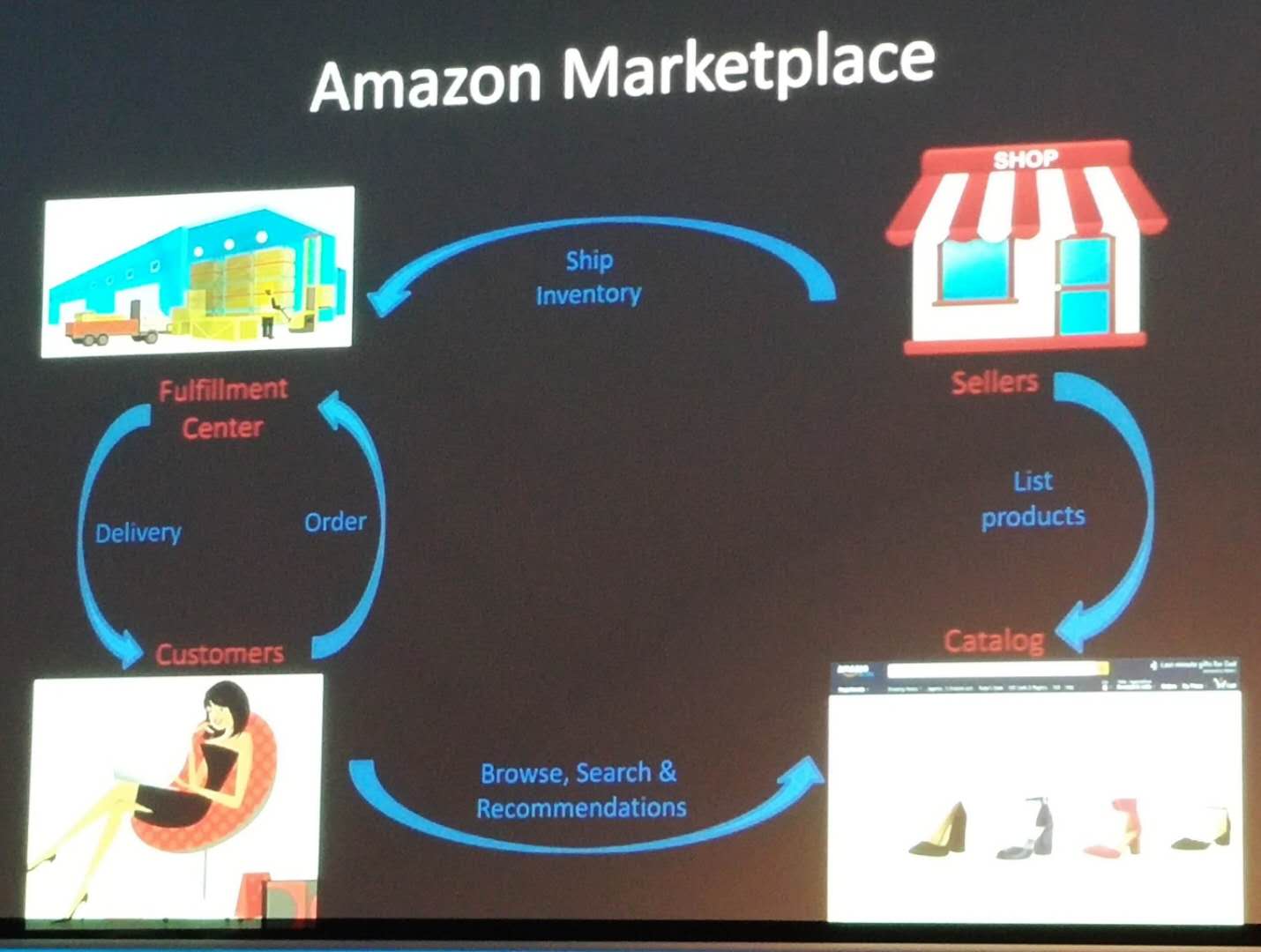
The speaker first gave an overview machine learning applications at Amazon. Then, he discussed question answering and product recommendation. Here is a slide showing the ecosystem of Amazon.
They use machine learning, to increase product selection, lower prices, reduce delivery times to improve customer experience, and maintaining customer trust. Here is an overview:
There is a lot of applications of Machine Learning at Amazon. A first application is product demand forecasting, which consists of predicting the demand of a product up to one year in the future.
For this problem, there is several problems to solve such as the cold start problem (having no data about new products), some products having seasonal patterns, and some products having demand spikes. Demand prediction is used by management to make orders of products, to make sure that products are in stock at least 90% of the time when a user wants to buy it.
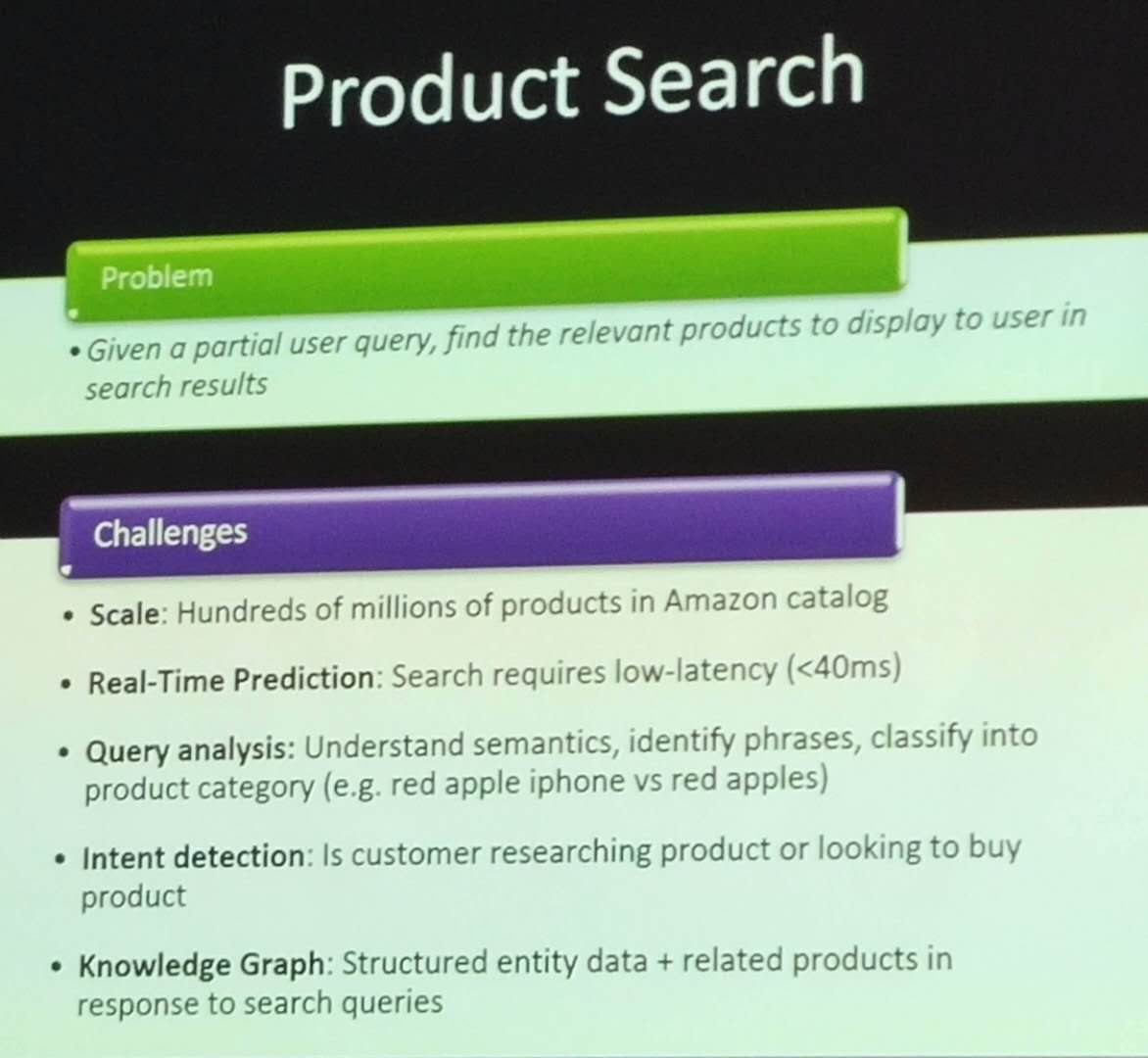
Another key application is product search. Given a query made by a user, the goal is to show relevant products to the user. Some of the challenges are shown below:
Another application is product classification, which given a product description provided by a seller, map it to the appropriate node in a taxonomy of products. Some of the challenges are as follows:
Another application is product matching, which consists of identifying duplicate products. The reason is that if the user sees several times the same products in the search results, it gives a bad user experience. Some of the challenges are:
Another application is information extractionfrom review. Many products receive thousands of reviews, which a user typically cannot read. Thus, Amazon is working on summarizing reviews, and generating product attribute ratings (ratings of specific features of products such as battery life and camera). Some of the challenges are to identify which attributes of products are relevant, identifying synonyms (sound vs audio), coping with reviews written in an informal way and linguistic style.
Another application is product recommendation, which consists of “recommending the right product to the right customer in the right place at the right time”.
Another application is the use of drones to deliver packages safely to homes in 30 minutes. This requires for example to avoid landing on a dog or child.
Another application is robotics to pick and transport products from shelves to packaging areas in Amazon warehouse, called “fullfillment centers”.
Another application is a visual search app, which let users take a picture of a product to find similar products on Amazon.
Another application is Alexa, which requires voice recognition.
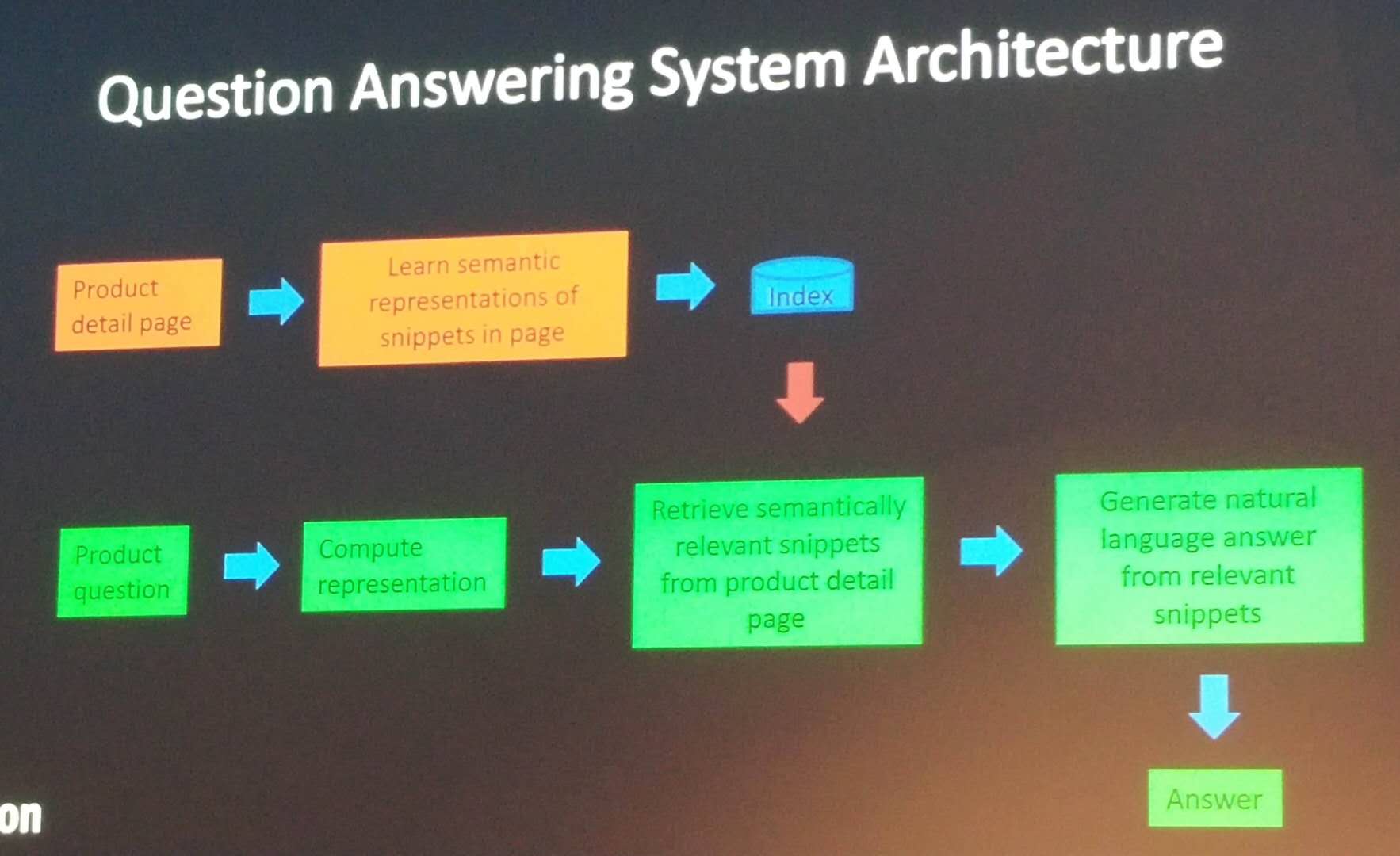
Another application is product question answering. On the Amazon website, users can ask question about products. A first type of questions is about product features such as: what is the weight of a phone? Some of these questions can be answered automatically by extracting the information from the product description or user reviews. Another type of question is about product comparison and compatibility with other products. Some of the challenges related to question answering are:
Here is a very high level overview of the question answering system architecture at Amazon. It relies on neural networks to match snippets of product description or reviews to user questions.
Another problem is product size recommendation to user. This is an important problem because if users make incorrect purchases, they will return the products, which is costly to handle. Some of the challenges are:
The conference banquet
The banquet was organized also at the Grand Hyatt hotel. It was a nice dinner with a performance done by some Australian aboriginal people. Then, it was followed by a brief talk by Christos Faloutsos, and the announcement of several awards. Here is a few pictures.
The performance:
The best paper awards:
Last day
On the last day, there was another keynote, and also results from the PAKDD data competition, as well as more paper presentation
The lack of proceedings
A problem was that the proceedings of PAKDD2018 were not offered to the attendees, neither as a book or a USB drive.During the opening ceremony, it was said that it was a decision of the organizers to only put the PDF of camera-ready articles on the PAKDD2018 website. Moreover, they announced that they ordered 30 copies of the proceedings (books) that would be available for free before the end of the conference. Thus, I talked with the registration desk to make sure that I would get my copy of the proceedings before the end of the conference. They told me to send an e-mail to the publication chairs, which I did. But at the end of the conference, the registration desk told me that the books would just not arrive.
So I left Australia. Then, on the 14th June, about 8 days after the conference, the publication chairs sent me an e-mail to tell me that they would receive the books in about two more weeks, thus almost one month after the conference. Moreover, they would not ship the books. Thus, if we want to have the book, we would have to go back to Melbourne to pick it up.
Conclusion
This year, PAKDD was quite interesting. Generally, the conference was well-organized and I was able to talk with many other researchers from various universities and also the industry. The only issue was that the proceedings were not available at the conference. But overall, this is still a small issue. Looking forward to PAKDD 2019in Macau next year!
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.
This week I have attended the ChinaInternational Big Data IndustryExpo 2018 in Guiyang, China. I will describe this event and some of the key things that I have observed so far.
What is the China International Big Data Industry Expo?
It is an international event targeted toward the industry and focused on big data, which is aimed at an international audience and held every year in Guiyang, China (capital of Guizhou province, in the south of China). This conference is a major conference in China. It is in fact supported at the national level event by the Chinese government. Hence, it is a very large scale event. It was in fact, announced everywhere in the city from the airport to public park signs and banners on buildings.
The conference has many activities organized from the 24th May to 29th May, such as more than 50 forums on various topics related to big data, competitions, and also a large exhibition consisting of many booths that can be visited by the public. At the exhibition both national and international companies were present. Moreover, more than 350 executives from companies were said to have attended the conference, including some very famous people such as Jack Ma, the leader of Alibaba, and several government officials.
The theme of the conference this year was: big data makes a smarter world, or in other words, how big data can improve the life of people.
The opening ceremony
The opening ceremony was on the 26th. First, the Vice Chairman of the National People’s Congress of China (Wang Chen) talked for several minutes. From my notes, he mentioned that big data is an historic opportunity for China. He also mentioned the importance of protecting personal data in the era of big data, and that in the next years, the biggest amount of data in the world will be in China due to its large population.
It was also mentioned that the leader of China (Xi Jinping) sent a letter to congratulate the conference. The letter mentioned the importance of encouraging the big data industry and development to improve people’s lives, and create a leadership in China for internet technologies.
Then, the Chairman of the Standing Committee of Guizhou (Sun Zhigang) also talked. He mentioned that more than 350 executives attended the conference, and 546 guests, including people from many countries. He also suggested that convergence and integration are key for the development of technology, and mentioned topics such as using big data for poverty alleviation, integration in healthcare, and e-governance (how to handle government affairs on the internet and make government services more accessible to people). It was also mentioned that it is important to crack down on illicit, unfair competition and fraud to ensure the good development of cyberspace, and that favorable policies and platform must be provided to support the digital economy.
The Vice Minister of Industry and Information Technology of China (Chen Zhaoxiong) then also addressed the audience. He mentioned that many fields are revolutionized by big data technology, the importance of data interconnectivity, new applications and models, data governance and security, enhancing the laws related to big data, ensuring that personal privacy is respected, allowing smaller players to access data from larger players, and encouraging international collaboration.
Then, the Vice Minister of the Cyberspace Administration of China (Yang Xiaowei) explained that we must seize the opportunity of big data, and that big data is a driver of economic development. Besides, e-governance is important in China to enhance people access to government services and further increase living standards. Also, it was mentioned that big data can play an important role in healthcare, education and social insurance, and that data security is important.
Then, a few more guests also talked, including Prince Andrew, the Duke of York.
The forums
A number of forums are also held during the conference on various topics such as blockchain, sino-UK collaborations, and how big data can revolutionize the manufacturing industry. Some of them were in Chinese. Some of them had simultaneous translation in English, and some were conducted in English. At some times, there was up to 10 events in parallel. Thus, there was something for everyone.
The big data exhibition
The exhibition consisted of about 400 booths and visiting it is a great opportunity to see what is happening in the big data industry and discuss with companies. I have visited it for two days to take the time to discuss with many companies, and it was worth it. Below I show some pictures with some further comments.
There was a lot of people after the opening ceremony
The Apache booth
A prototype self-service supermarket using various technology such as face recognition and mobile payment.
A bike simulator, among various other games such as virtual reality.
Various robotic toys and robots were also on display, as well as self-driving cars.
Some systems were presented to integrate and visualize data coming from multiple sources
Several innovative products such as an interactive table
A drone for spatial mapping
Several machines were also presented for offering services to customers such as buying products or obtaining services.
Facial recognition was also a popular topic, used in many demos, due to the recent innovations in that area.
Data visualization from multiple sources
A machine dedicated for checking the health of eyes
More robots!
The booth of Jing Dong, one of the largest online retailer in China
Jing Dong is also researching the use of drones for delivery, and how to manage wharehouse more efficiently using robots (not shown).
The booth of Alibaba, another major company in China and abroad
The booth of Facebook
The booth of Foxconn, a big Chinese company The booth of Tencent, another major Chinese company
Some of the many other companies who participated to the event
Social activities
Several social activities were also organized for the guests of the conference. In particular, there was a symphony concert on 26th May, held in a park that was very beautiful. As a special guest, I was seated in the second row.
I also attended a cocktail for guests before the show.About the organization
The conference was very well organized. As a national level conference, it was clear that major resources were put to support this conference from all levels of the government. Many streets had been closed, and from what I have heard, even several days of holidays were given to workers to reduce the number of people in the city so that less cars would be on the roads, to ease transportation for people attending the conference. There was also a lot of security guards deployed in the streets around the conference to ensure high standards of security and safety for the event.
It was thus clear that the Government of China is putting major investments to support the development of the big data industry, which is very nice to see and exciting.
Why was the conference held in Guiyang? Although this city is not big in terms of population by Chinese standards (about 4 million people), in recent years, a major effort has been done to transform this city into a big data leader. In particular, it is a very popular city for data centers. Several major companies like Apple have data centers in that city.
Conclusion
As a conclusion, it is the first time that I have attended this conference, and I am glad to have accepted the invitation. The organization was well-done and there was a lot of opportunities to connect with people from the industry and see the most recent applications of big data. If I have time, I would definitely consider attending this conference again in the future. Hope you have enjoyed reading😉 If you want to read more, there are many other articles on this blog. and you can also follow this blog on Twitter @philfv .
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.
In this blog post, I will talk about the vision of the Semantic Web that was proposed in the years 2000s, and why it failed. Then, I will talk about how it has been replaced today by the use of data mining and machine learning techniques.
What is the Semantic Web?
The concept of Semantic Web was proposed as an improved version of the World Wide Web. The goal was to create a Web where intelligent agents would be able to understand the content of webpages to provides useful services to humans or interact with other intelligent agents.
To achieve this goal, there was however a big challenge. It is that most of the data on the Web is unstructured, as text. Thus, it was considered difficult to design software that can understand and process this data to do some meaningful tasks.
Hence, a vision of the Semantic Web that was proposed in the years 2000s was to use various languages to add metadata to webpages that would then allow machines to understand the content of webpages and do reasoning on this content.
Several languages were designed such as RDF, OWL-Lite,OWL-DL, OWL-FULL and also some query languages like SparQL. The knowledge described using these languages is called ontologies. The idea of an ontology is to describe various concepts occurring in a document at a very high level such as car, truck, and computer, and then to link these concepts to various webpages or resources. Then, based on these ontologies, a software program could use reasoning engines to reason about the knowledge in webpage and perform various tasks based on this knowledge such as finding all car dealers in a city that sell second-hand blue cars.
The fundamental problems of the Semantic Web
So what was wrong with this vision of the Semantic Web? Many things:
The languages for encoding metadata were too complex. Moreover, encoding metadata was time-consuming and prone to errors. The proposed languages for adding metadata to webpages and resources were difficult to use. Despite the availability of some authoring tools, describing knowledge was not easy. I have learned to use OWL and RDF during my studies, and it was complicated as OWL is based on formal logics. Thus, learning OWL required a training and it is very easy to use the language in a wrong way if we don’t understand the semantics of the provided operators. It was thus wrong to think that such a complicated language could be used at a large scale on the Web. Also because such languages are complicated, they are prone to errors.
The reasoning engines based on logics were slow and could not scale to the size of the Web. Languages like OWL are based on logic, and in particular description logics. Why? The idea was that it would allow to use inference engines to do logical reasoning on the knowledge found in the webpages. However, most of these inference engines are very slow. In my master thesis in the years 2000s, reasoning on an OWL file with a few hundred concepts using the state-of-the-art inference engines was already slow. It could clearly not scale to the size of the Web with billions of webpages.
Languages were very restrictive. Another problems is that since some of these languages were based on logics, they were very restrictive. To describe some very simple knowledge it would work fine. But to describe something complicated, it was actually very hard to model something properly. And many times the language would not just not allow to describe something.
Metadata are not neutral, and can be easily tweaked to “game” the system. The concept of adding metadata to describe objects can work in a controlled environment such as to describing books in a library. However, on the Web, bad people can try to game the system by writing incorrect metadata. For example, a website could write incorrect metadata to achieve a higher ranking in search engines. Based on this, it is clear that adding metadata to webpages cannot work. This is actually the reason why most search engines today do not rely much on metadata to index documents.
Metadata is quickly obsolete and need to be always updated.
Metadata intereporability betwen many websites or institutions is hard. The whole idea of describing webpages using some common concepts to allow reasoning may sound great. But a major problem is that various websites would then have to agree to use the same concepts to describe their webpage, which is very hard to achieve. In real-life, what would instead happen is that a lot of people would describe their webpages in inconsistent way, and the intelligent agents would not be able to reason with these webpages as a whole
Because of these reasons, the concept of Semantic Web was never achieved as in that vision (by describing webpages with metadata and using inference engines based on logics).
What has replaced that vision of the Semantic Web?
In the last decades, we have seen the emergence of data mining (also called big data, data science) and machine learning. Using data mining techniques, it is now possible to directly extract knowledge from text. In other words, it has become largely unnecessary to write metadata and knowledge by hand using complicated authoring tools and languages.
Moreover, using predictive data mining and machine learningtechniques, it has become possible to automatically do complex tasks with text documents without having to even extract knowledge from these documents. For example, there is no need to specify an ontology or metadata about a document to be able to translate it from one language to another (although it requires some training data about other documents). Thus, the focus as shifted from reasoning with logics to use machine learning and data mining techniques.
It has to be said though that the languages and tools that were developed for the SemanticWeb have some success but a much smaller scale than the Web. For example, it has been used internally by some companies. Research about logics, ontologies and related concepts is also active, and there are various applications of those concepts, and challenges that remains to be studied. But the main point of this post is that the vision that this would be used at the scale of the Web to create the Semantic Web did not happen. However, some of these technologies can be useful at a smaller scale (e.g. reasoning about books at the library).
So this is all I wanted to discuss for today. Hope this has been interesting 😉 If you want to read more, there are many other articles on this blog. and you can also follow this blog on Twitter @philfv .
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.