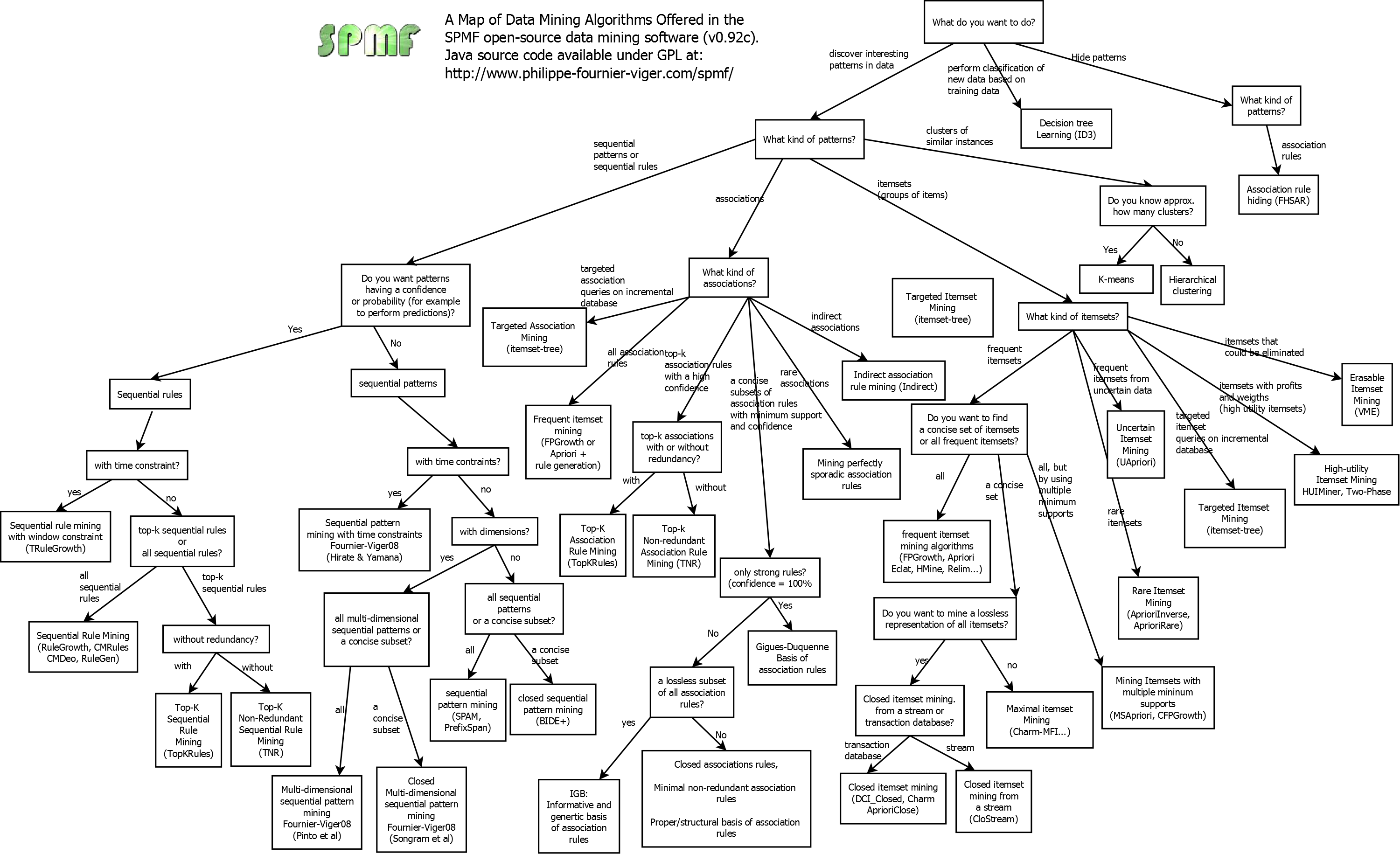
Hi, today, I will discuss how to compare data mining algorithms. This is an important question for data mining researchers who want to evaluate which algorithm is “better” in general or for a given situation. This question is also important for researchers who are writing articles proposing new data mining algorithms and want to convince the reader that their algorithms deserve to be published and used. We can characterize and compare data mining algorithms from several different angles. I will describe them thereafter.
What is the input and output? For some problems there exists several algorithms. However, some of them have slightly different input and this can make the problem much harder to solve. Often, a person who want to choose a data mining algorithm will look at the most popular algorithms such as ID3, Apriori, etc. But several persons will not try to search for less popular algorithms that could better fit their need. For example, for the problem of association rule mining, the classic algorithm is Apriori. However, there exists probably hundreds of variations that can be more appropriate for a given situation such as discovering associations with weights, fuzzy associations, indirect associations and rare associations.
Which data structures are used ? The data structure that are used will often have a great impact on the performance of data mining algorithms in terms of execution time and memory. For example, some algorithms will use less common data structures such as bitsets, KD-trees and heaps.
What is the problem-solving strategy? There are many way to describe the strategy used by an algorithm for finding a solution such as: Is it a depth-first search algorithm? a breadth-first search algorithm? a recursive algorithm? an iterative algorithm? is it a brute force algorithm? an exhaustive algorithm? a divided-and-conquer algorithm? a greedy algorithm? a linear programming algorithm? etc. Moreover,
Does the algorithm belong to a well-known class of algorithms? For example, there exists several well-known classes of algorithms for solving problems such as genetic algorithms, quantum algorithms, neural networks and particle swarm optimizations based techniques.
The algorithm is an approximate algorithm or an exact algorithm? An approximate algorithm is an algorithm that will not always guarantee to return the correct answer. An exact algorithm always return the correct answer.
Is it a randomized algorithm ? Does the algorithm uses a random generator? Is it possible that the algorithms will return different results if it is run twice on the same data?
Is it an interactive, incremental, or a batch algorithm? A “batch algorithm” is an algorithm that takes as input some data, will perform some processing and will output some data. An incremental algorithm is an algorithm that will not need to recompute the output from zero, if new data arrives. An interactive algorithm is an algorithm where the user can influence the processing of the algorithm, while the algorithm is working.
How is the performance? Ideally, one should compare the performance of an algorithm with at least another algorithm for the same problem, if there exists one. To make a good performance comparison, it is important to make a detailed performance analysis. First, we need to determine what will be measured. This depends on what kind of algorithms we are evaluating. In general, it is interesting to measure the maximal memory usage and the execution time of an algorithm. For other algorithms such as classification algorithms, one will also take other measurements such as the accuracy or recall, for example. Another important decision is what kind of data should be used to evaluate the algorithms. To compare the performance of algorithms, more than one datasets should be used. Ideally, one should use datasets having various characteristics. For example, to evaluate frequent itemset mining algorithms, it is important to use sparse and dense datasets, because some algorithms will perform very well on dense datasets but not so well on sparse datasets. Is is also preferable to use real datasets instead of synthetic datasets. Another thing that one may want to evaluate is the scalability of the algorithms. This means to measure how algorithms behave in terms of speed/memory/accuracy when the datasets becomes larger. To assess the scalability of algorithms, some researchers will use a dataset generator that can generate random datasets of various sizes and having various characteristics.
What is the complexity? One can make a more or less detailed complexity analysis of an algorithm to assess its general performance. It can help gain insights on what is the cost of using the algorithm. However, one should also perform experiments on real data to asses the performance. A reason for not just doing a complexity analysis, is that the performance of many algorithms will vary depending on the data.
The algorithm is easy to implement? One important aspect that can make an algorithm more popular is if it is easy to implement or easy to understand. I have often observed that some algorithms are more popular than others simply because they are easier to implement although there exists more efficient algorithms that are more difficult to implement. Also, if there exist open-source implementations of the algorithms, it can also be a reason why an algorithm is preferred.
Does the algorithms terminate in a finite amount of time ? For data mining algorithms, this is generally the case. However, some algorithms does not guarantee this.
The algorithm is a parallel algorithm? Or could it be easily transformed into a parallel algorithm that could be run on a distributed system or parallel system such as a multiprocessor computer or a cluster of computers? If an algorithm offers this possibility, it is an advantage for scalability.
What are the applications of the algorithm? One could also talk about what are the potential applications of an algorithm. Can it only be applied to a narrow domain? Or does it add a very general problems that can be found in many domains?
This is all for today. If you have some additional thoughts, please share them in the comment section. By the way, if you like this blog, you can subscribe to the RSS Feed or my Twitter account (https://twitter.com/philfv) to get notified about future blog posts. Also, if you want to support this blog, please tweet and share it!