
Today, I will share the good news that I have participated as co-author in a paper proposing a new algorithm for high utility itemset mining called HAMM that is very efficient, and outperforms the state-of-the-art algorithm. This is not an easy feat as there has been many algorithms for this problem since more than a decade. The algorithm will appear in an upcoming issue of the IEEE TKDE journal (one of the top journals in data mining).
What is especially interesting about this new HAMM algorithm is that it is inspired by FP-Growth but runs in a single phase unlike the previous FP-Growth based algorithms for utility mining such as UP-Growth and IHUP. Besides, it is combined with the concept of utility vectors and novel strategies are developed in HAMM
Currently, the paper is accepted but not published yet in a regular issue of TKDE, thus I will wait for the final version to be ready before sharing.
However stay tuned! And here is the citation for this new paper:
J. -F. Qu, P. Fournier-Viger, M. Liu, B. Hang and C. Hu, “Mining High Utility Itemsets Using Prefix Trees and Utility Vectors,” in IEEE Transactions on Knowledge and Data Engineering, doi: 10.1109/TKDE.2023.3256126.
And the webpage of TKDE where the paper is located: https://ieeexplore.ieee.org/document/10068302

The performance results are excellent compared to many of the most recent high utility itemset mining algorithms. Here are a few figures from the paper:
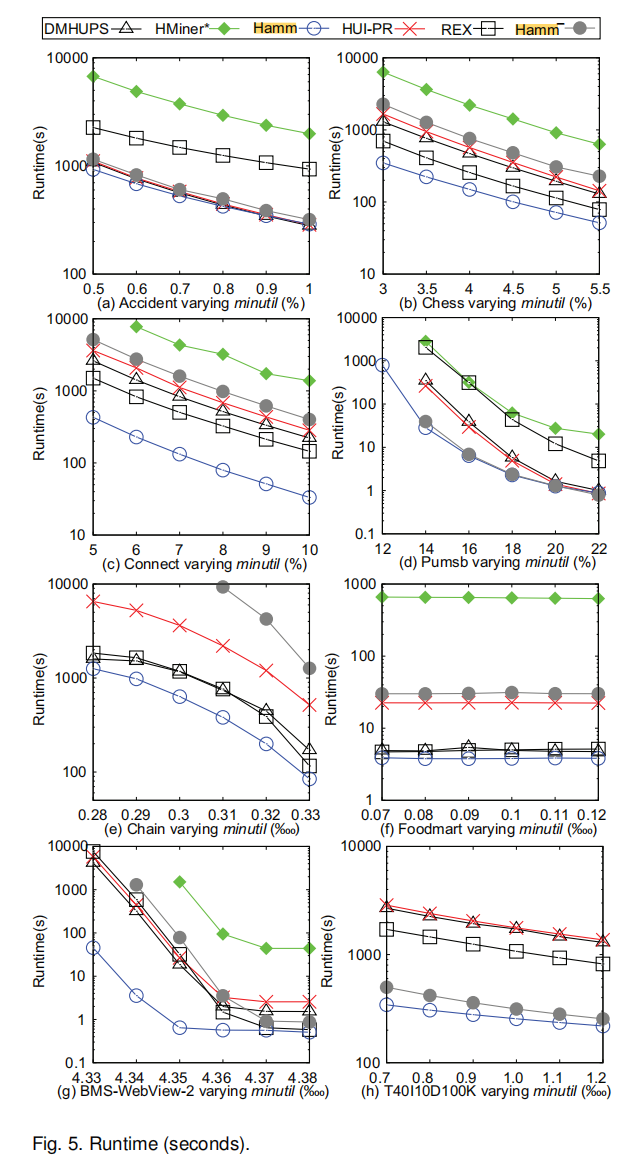
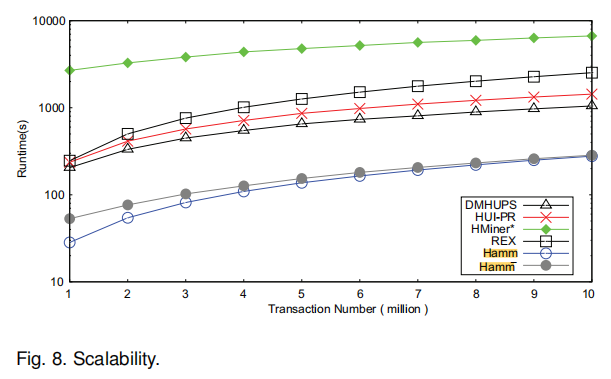
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 250 data mining algorithms.




Hello, when will the algorithm source code of this paper be updated to SPMF? I am very interested in this paper and want to study in depth. Thanks
Good afternoon,
Thanks for reading the blog and for your interest.
Currently, there is no short-term plan to include this paper in SPMF because it was implemented in C++ (by the main author), so I do not have a Java version. However, if someone converts it to Java, I would like to add it to SPMF. I think this paper has some great idea that could be used in several other high utility itemset mining problem variations. If you are interested by the code in C++, you could contact the first author. Jun-Feng Qu to ask if he can share the C++ code. By the way, I think you are also from China, just like me. If you want to reach me by Wechat, my id is: philfv.
Best regards,
Philippe