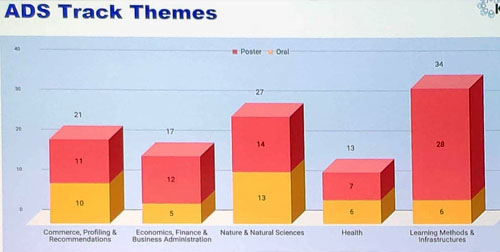
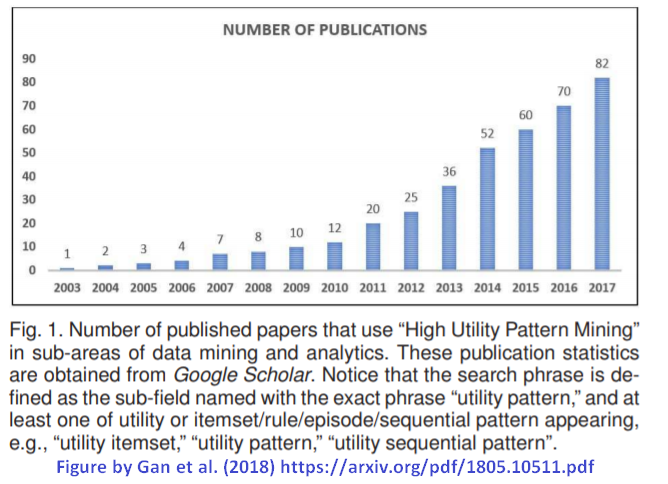
In this blog post, I will answer the question: Why doing a Ph.D.? This is an important question for several students that are doing a bachelor or master degree,. Taking a good decision is important as doing a Ph.D requires several years of work. But at the same time, obtaining a Ph.D. can be very rewarding. In this blog post, I will first briefly explain what is the goal of doing a PhD., and then discuss the reasons for doing it and for NOT it.
What is the goal of doing a Ph.D.?
Put in a simple way, the goal of doing a Ph.D. is to learn how to do research. At the end of a Ph.D. one should be able to independently do research, and work as a researcher. Moreover, during the Ph.D., one should make some novel and significant contributions to research in his fields.
What are the reasons for doing a Ph.D?
Some of the main reasons are:
- Becoming an expert in a field. By doing a Ph.D. one may become an expert on a specific topic, and work with other experts in that field with state-of-the-art equipment on state-of-the-art problems. If you like learning, just like me, this is very satisfying.
- Contribute to the advancement of knowledge. By doing research, one can contribute to the advancement of knowledge in a specific field. For example, one can make new discoveries that are useful to other people.
- Work on something that you like. When doing a Ph.D. one can actually choose to to work on something that he like for a few years. This is something that is not always possible when working in a company.
- Self-achievement. One can see the Ph.D. as a challenge. One of the reasons why I decided to do a Ph.D. is to test myself to see if I could do it.
- It is a requirements for some jobs. Although not many jobs requires a Ph.D., some jobs like researcher and university professor requires to have a Ph.D. If one wants to do such jobs, he definitely needs to get a Ph.D. Working as a researcher can be very motivating as it requires to use problem-solving skills everyday.
- Money (in the long term). A Ph.D. actually does not guarantee earning more money than someone who does not have a Ph.D. But in many cases having a Ph.D. can lead to a good salary, especially if one studies in science, technology and engineering.
- The title? You can call yourself a “doctor”. 😉 I am just kidding. It is nice to have that title. But one should NOT see this as a reason for doing a Ph.D.
- Spending a few more years as a student. Although being a student should not be a reason for doing a Ph.D., many Ph.D. students enjoy the freedom that Ph.D. students have. As a student, there is often more freedom than when working in a company. Thus living as a student for a few more years to do a Ph.D. can be positive.
- Travelling. Graduate studies are a good opportunity for travelling such as to attend international conferences to present your work, or even in some cases to study abroad.
What are the reasons for NOT doing a Ph.D.?
Some of the main reasons for not doing a Ph.Ds are:
- Time! Doing a Ph.D. requires to spend typically at least 3 years of your life to work on a specific project. For me, that was never an issue, but some people may worry about this. Besides, the end of the Ph.D typically depends on how fast one can complete the project. Some people who are not good at research or are working part-time may spend 4 or 5 years.
- Money (in the short term). It depends on the country, but it is a possible that a Ph.D. student does not earn a great amount of money during his studies. This means to live with a small amount of money for a few more years, perhaps. Some people do not like to live like students, while some other people enjoy the student life.
- Money (in the long term). Although some jobs that require a Ph.D. are very well paid, there exists some jobs that do not require a Ph.D. and can be paid better. Thus, one should not just think about money when deciding to do a Ph.D.
- Some jobs do not require a Ph.D. Although getting a Ph.D. can help someone acquire many skills especially about research and writing, some people who have a Ph.D. may actually end up doing some jobs that do not require a Ph.D.
- Pressures from others. One should not do a Ph.D. if it is only because of the pressures of parents or family. One should really be interested in doing the Ph.D. for himself.
- It requires at lot of work. Obtaining a Ph.D. requires a few years of hard work. Some people can easily cope with this, while others do not like to work hard. Working for a few years on a project can at times be hard, and some people do not feel motivated. However, if you like research like me, it is actually very motivating.
Conclusion
In this blog post, I have discussed the main reasons for doing a Ph.D. If you think about other reasons or want to share your opinion about this topic, please post in the comments below. Also, you may be interested to read my related post about: what it takes to do a good Ph.D?
==
Philippe Fournier-Viger is a full professor and the founder of the open-source data mining software SPMF, offering more than 140 data mining algorithms. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.