
In this short blog post, I will talk about some serious issues that have been raised about many studies on anomaly detection for time series. More precisely, it was recently shown that a lot of papers on anomaly detection for time series have results that should not be trusted due in part to factors such as trivial benchmark datasets and measures for evaluating the performance of models that are not suitable. Two research groups have highlighted these serious problems.
(1) Keynote talk “Why we should not believe 95% of papers on Time Series Anomaly Detection” by Eamon Keogh
The very well-known time series researcher Eamon Keogh recently gave a keynote talk where he argued that most anomaly detection papers’ results should not be trusted. The slides of his presentations can be found here. Besides, there is a video on Youtube of his talk that you can find. Basically, it was observed that:
- Several experiments cannot be reproduced because datasets are private.
- For public datasets used in time series anomaly detection, many are deeply flawed. They contain few anomalies and anomalies are often mislabeled. Thus, predicting the mislabeled anomalies can indicate overfitting rather than good performance.
- Many benchmark datasets are trivial. It was estimated that maybe 90% of benchmark datasets can be solved with one line of code or decades old method. This means that many of the complex deep learning models are completely unecessary on such datasets as a single line of code has the same or better performance. Here is a slide that illustrates this problem:
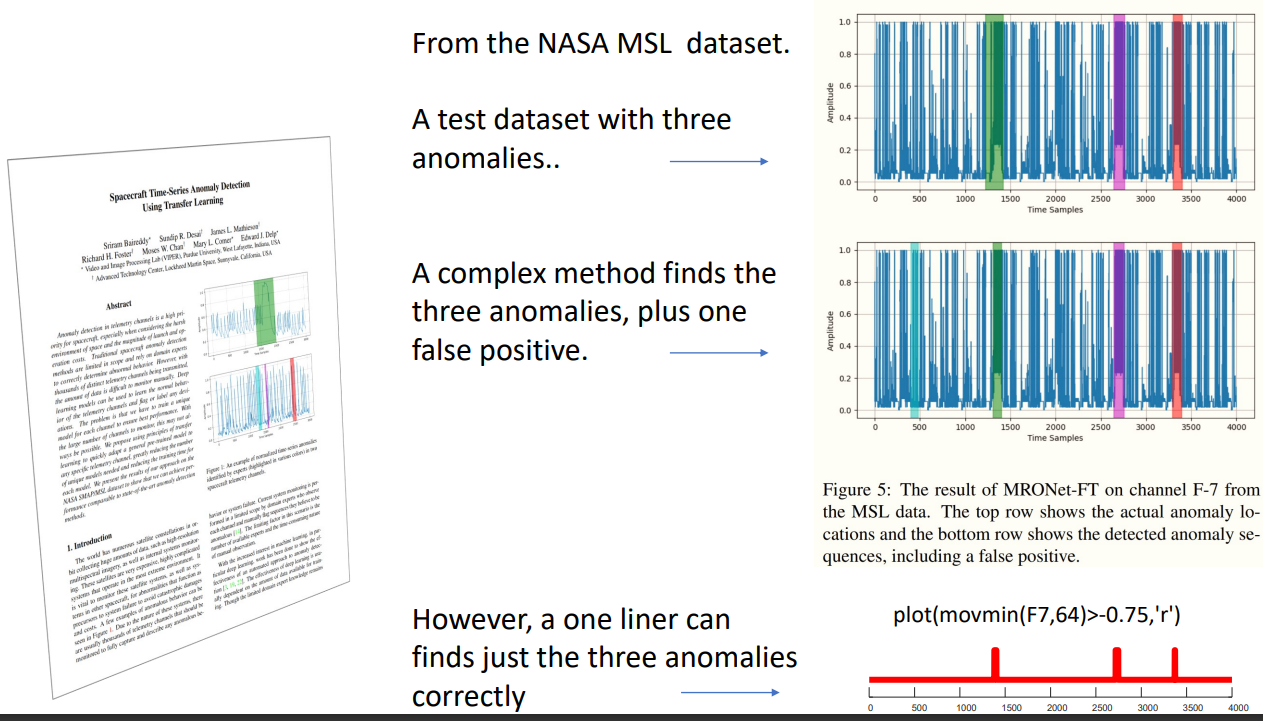
Based on these observations and others, Keogh et al. proposed a new set of benchmark datasets for anomaly detection. I recommend to watch this talk on Youtube if you have time. It is really insighful, and show deep problems with anomaly detection research for time series.
(2) Paper from AAAI 2022
There is also a recent paper published at AAAI 2022 that makes similar observations. The paper is called “Towards a Rigorous Evaluation of Time-series Anomaly Detection”. Link: 2109.05257.pdf (arxiv.org).
The authors basically show that a common measure called PA used for time series anomaly detection can lead to greatly overestimating the performance of anomaly detection models. The authors did an experiment where they compared the performance of several state-of-the-art deep learning models for anomaly detection with three trivial models: (case 1) random anomly scores, (case 2) a model that gives the input data as anomaly scores, and (case 3) scores produced by a randomized model. Then, they found that in several cases, these three trivial models were performing better than the state-of-the-art deep learning models. Here is a picture of that result table (more details in the paper):
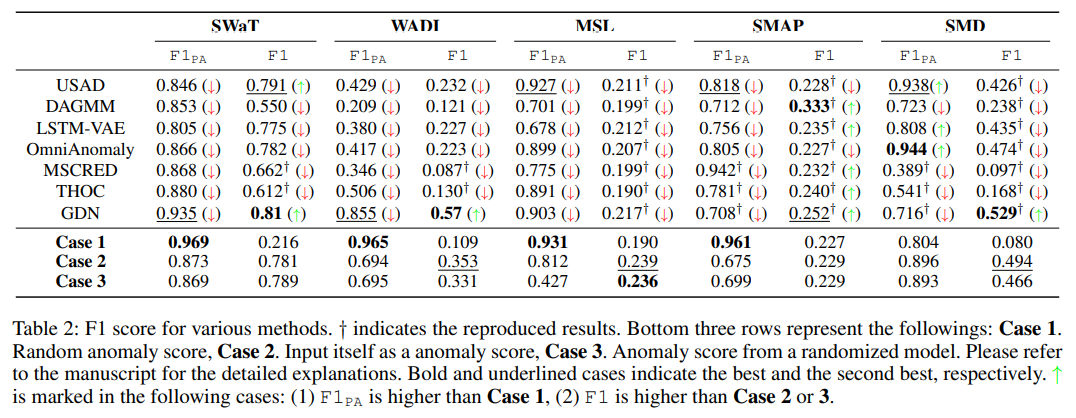
These results are quite shocking… It means that results of several papers cannot be really trusted.
In the paper, the authors proposed a solution that is to use an alternative metric to evaluate models.
Conclusion
The above observation about the state of research on time series anomaly detection gives a bad look on several studies in that area. It shows that many studies are flawed and that models are poorly evaluated. I do not work on this topic but I think it is interesting and it can remind all researchers to be very careful about how to evaluate their models to not fall in a similar trap.
This is just a short overview. Hope that this is interesting!
—
Philippe Fournier-Viger is a full professor working in China and founder of the SPMF open source data mining software.



