
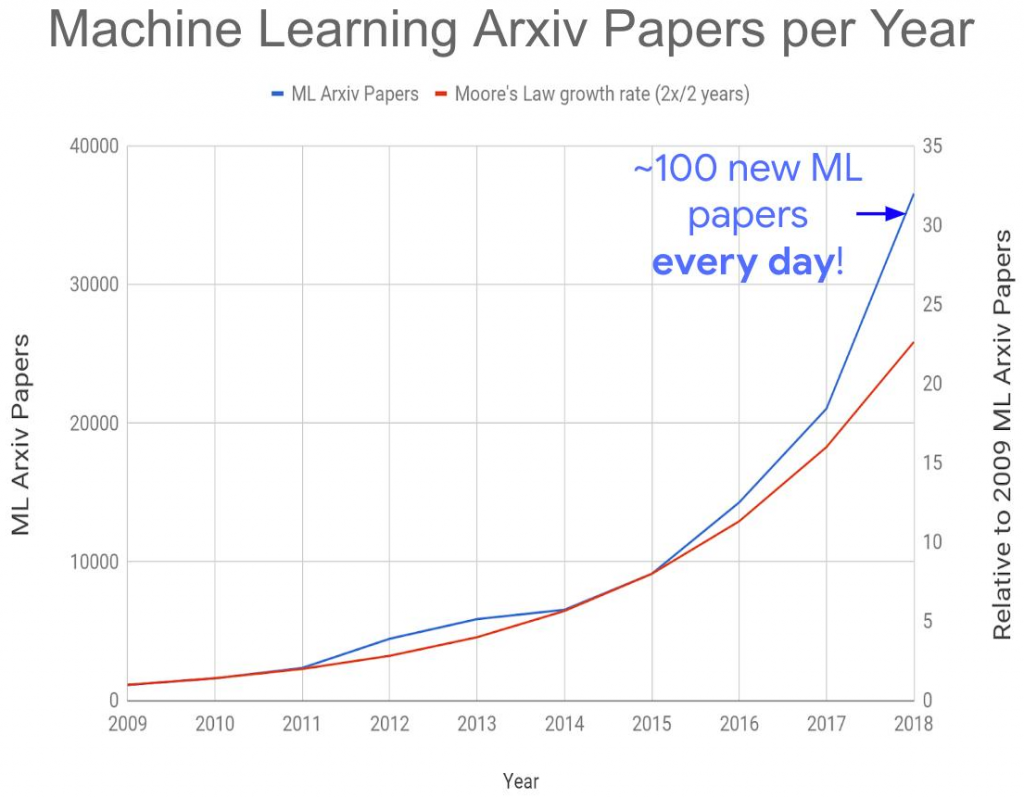
A few days ago, I have read a post on LinkedIn showing that the number of Machine Learning (ML) papers has been increasing very quickly over the last few years to about 100 ML papers per day (on Arxiv, a popular public repository of research papers).
Jeff Dean, David Patterson, and Cliff Young
That is about 33,000 papers per year. This shows the excitement about the new advances in that field in particular with respect to deep learning that has lead to obtaining good results for various applications. Some people on LinkedIn wondered if there are too many ML papers and how they could keep up with advances in that field.
I will make a few comments about this.
- First, in general in computer science, the papers that present a major innovation or breakthrough are few. There is always a lot of papers that make incremental advances by simply reusing ideas with some small modifications, or that just focus on applications rather than on fundamental problems. In fact, generally, few papers are highly cited while many paper receive few citations. Thus, although there may be a great increase in ML papers, one can ignore a huge amount of low quality papers. It is thus important to learn some strategies to detect low quality papers such as looking at the reputation of conferences and journals where papers are published and other criteria such as paper citation count.
- Second, the large increase of ML papers result in a huge demand to review ML papers but a problem is that there is perhaps not enough experts to read those. I can share some story related to that. Recently, I have been invited to join the program committee of a good neural network conference. Honesty, I was surprised because I have never published there, and I have never made any significant contributions in that field. I have used neural networks as a tool with other techniques in an applied paper about 4 years ago but that is all, and it should not count. Thus, I tend to think that there is not enough expert reviewers and they may have invited many such as me because I work on data mining, which is related. I also noticed an increase in the number of invitation to review ML papers for journals in my mailbox. But honestly, I rarely accept these invitations because it is not much related to my research. If there is not enough reviewers though, this may just be a temporary problem.
- Third, due to the increasing number of papers, some conferences on related or overlapping topics such as database or data mining start to receive many ML papers. There is generally no problem about that. But in some cases, these papers are inadequate for the topic of the conference. For example, this year, a conference that I will not name relates to databases, clearly mentioned to reviewers that if a paper is on ML and they do not understand the content or it doesn’t seem interesting to the target audience, then to not recommend these ML papers for acceptance. As always, it is important to choose a relevant conference when submitting a conference paper (for papers on any topics).
- Fourth, ML has currently a lot of hype because of some excellent results obtained for applications such a computer vision and translation. Should there be so many researchers working in that area? I do not have the answer but it is a question that is worthy to be asked. For example, I know that in some university, more than 50% of graduate students are now working on deep learning. But it remains that deep learning cannot solve all the problems of computer science, and many other research areas still have complex challenges to address. Also there is always some trends in research that come and goes every few years. For example, a technique like SVM was quite popular 10 years ago but now is less than deep learning. Neural networks have also had cycles of popularity over the last forty years. As an individual, it can be good to somewhat follow the trends to take advantage of opportunities, or at least be aware of them.
Conclusion
In this short blog post, I have just shared a few comments and observations related to the ML trend. If you have other comments, please share them in the comments section below. I will be happy to read them.
—
Philippe Fournier-Viger is a full professor working in China and founder of the SPMF open source data mining software.




The figure is from:
A New Golden Age in Computer Architecture: Empowering the Machine-Learning Revolution
Jeff Dean, David Patterson, and Cliff Young
Thanks for pointing this out! I will update the post.