
This tutorial will explain how to analyze text documents to discover complex and hidden relationships between words. We will illustrate this with a Sherlock Holmes novel. Moreover we will explain how hidden patterns in text can be used to recognize the author of a text.
The Java open-source SPMF data mining library will be used in this tutorial. It is a library designed to discover patterns in various types of data, including sequences, which can also be used as a standalone software, and to discover patterns in other types of files. Handling text documents is a new feature of the most recent release of SPMF (v.2.01).
Obtaining a text document to analyze

The first step of this tutorial is to obtain a text document that we will analyze. A simple way of obtaining text documents is to go on the website of Project Gutenberg, which offers numerous public domain books. I have here chosen the novel “Sherlock Holmes: The Hound of the Baskervilles” by Arthur Conan Doyle. For the purpose of this tutorial, the book can be downloaded here as a single text file: SHERLOCK.text. Note that I have quickly edited the book to remove unnecessary information such as the table of content that are not relevant for our analysis. Moreover, I have renamed the file so that it has the extension “.text” so that SPMF recognize it as a text document.
Downloading and running the SPMF software
The first task that we will perform is to find the k most frequent sequences of words in the text. We will first download the SPMF software from the SPMF website by going to the download page. On that webpage, there is a lot of detailed instructions explaining how the software can be installed. But for the purpose of this tutorial, we will directly download spmf.jar, which is the version of the library that can be used as a standalone program with a user interface.
Now, assuming that you have Java installed on your computer, you can double-click on SPMF.jar to launch the software. This will open a window like this:
Discovering hidden patterns in the text document
Now, we will use the software to discover hidden patterns in the Sherlock Holmes novel. There are many algorithms that could be applied to find patterns. We will choose the TKS algorithm, which is an algorithm for finding the k most frequent subsequences in a set of sequences. In our case, a sequence is a sentence. Thus, we will find the k most frequent sequences of words in the novel. Technically, this type of patterns is called skip-grams. Discovering the most frequent skip-grams is done as follows.
A) Finding the K most frequent sequences of words (skip-grams)
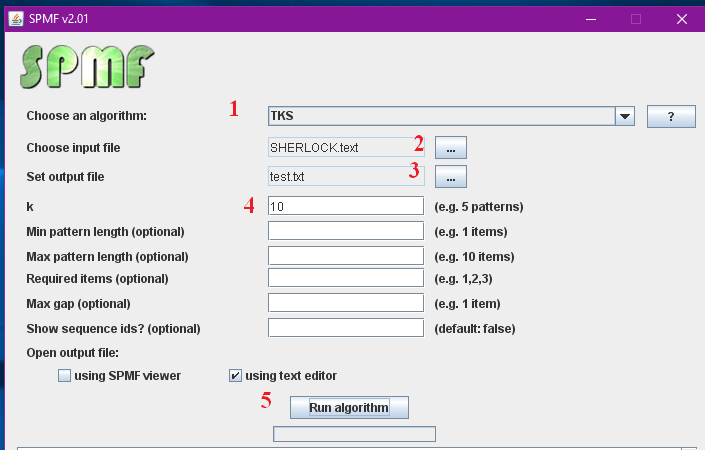
- We will choose the TKS algorithm
- We will choose the file SHERLOCK.text as input file
- We will enter the name test.txt as output file for storing the result
- We will set the parameter k of this algorithm to 10 to find the 10 most frequent sequences of words.
- We will click the “Run algorithm” button.
The result is a text file containing the 10 most frequent patterns

The first line for example indicates that the word “the” is followed by “of” in 762 sentences from the novel. The second line indicates that the word “in” appears in 773 sentences from the novel. The third line indicates that the word “the” is followed by “the” in 869 sentences from the novel. And so on. Thus we will next change the parameters to find consecutive sequences of words
B) Finding the K most frequent consecutive sequences of words (ngrams)
The above patterns were not so interesting because most of these patterns are very short. To find more interesting patterns, we will set a minimum pattern length for the patterns found to 4. Moreover, another problem is that some patterns such as “the the” contains gaps between words. Thus we will also specify that we do not want gaps between words by setting the max gap constraint to 1. Moreover, we will increase the number of patterns to 25. This is done as follows:
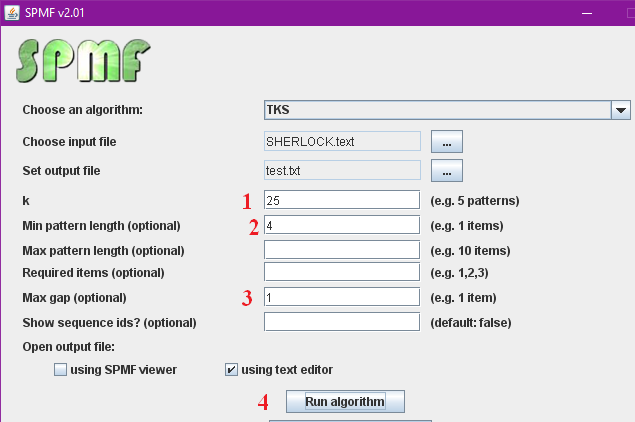
- We set the number of patterns t0 25
- We set the minimum length of patterns to 4 words
- We require that there is no gap between words (max gap = 1)
- We will click the “Run algorithm” button.
The result is the following patterns:

Now this is much more interesting. It shows some sequences of words that the author of Sherlock Holmes tends to use repeatedly. The most frequent 4-word sequences is “in front of us” which appears 13 times in this story.
It would be possible to further adjust the parameters to find other types of patterns. For example, using SPMF, it is also possible to find all patterns having a frequency higher than a threshold. This can be done for example with the CM-SPAM algorithm. Let’s try this
C) Finding all sequences of words appearing frequently
We will use the CM-SPAM algorithm to find all patterns of at least 2 words that appear in at least 1 % of the sentences in the text. This is done as follows:
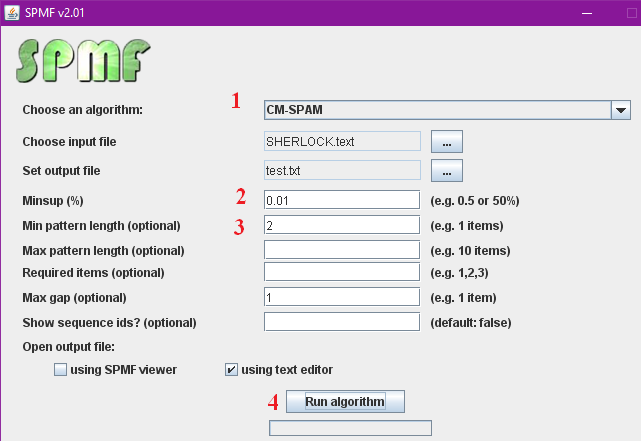
- We choose the CM-SPAM algorithm
- We set the minimum frequency to 1 % of the sentences in the text
- We require that patterns contain at least two words
- We will click the “Run algorithm” button.
The result is 113 patterns. Here is a few of them:

Here there are some quite interesting patterns. For example, we can see that “Sherlock Holmes” is a frequent pattern appearing 31 times in the text, and that “sir Charles” is actually more frequent than “Sherlock Holmes”. Other patterns are also interesting and give some insights about the writing habits of the author of this novel.
Now let’s try another type of patterns.
D) Finding sequential rules between words
We will now try to find sequential rules. A sequential rule X-> Y is sequential relationship between two unordered sets of words appearing in the same sentence. For example, we can apply the ERMiner algorithm to discover sequential rules between words and see what kind of results can be obtained. This is done as follows.
- We choose the ERMiner algorithm
- We set the minimum frequency to 1 % of the sentences in the text
- We require that rules have a confidence of at least 80% (a rule X->Y has a confidence of 80% if the unordered set of words X is followed by the unordered set of words Y at least 80% of the times when X appears in a sentence)
- We will click the “Run algorithm” button.
The result is a set of three rules.

The first rule indicates that every time that 96 % of the time, when “Sherlock” appears in a sentence, it is followed by “Holmes” and that “Sherlock Holmes” appeared totally 31 times in the text.
For this example, I have chosen the parameters to not obtain too many rules. But it is possible to change the parameters to obtain more rules for example by changing the minimum confidence requirement.
Applications of discovering patterns in texts
Here we have shown how various types of patterns can be easily extracted from text files using the SPMF software. The goal was to give an overview of some types of patterns that can be extracted. There are also other algorithms offered in SPMF, which could be used to find other types of patterns.
Now let’s talk about the applications of finding patterns in text. One popular application is called “authorship attribution“. It consists of extracting patterns from a text to try to learn about the writing style of an author. Then the patterns can be used to automatically guess the author of an anonymous text.

For example, if we have a set of texts written by various authors, it is possible to extract the most frequent patterns in each text to build a signature representing each author’s writing style. Then, to guess the author of an anonymous text, we can compare the patterns found in the anonymous text with the signatures of each author to find the most similar signature. Several papers have been published on this topic. Besides using words for authorship attribution, it is also possible to analyze the Part-of-speech tags in a text. This requires to first transform a text into sequences of part-of-speeches. I will not show how to do this in this tutorial. But it is the topic of a few papers that I have recently published with my student. We have also done this with the SPMF software. If you are curious and want to know more about this, you may look at my following paper:
Pokou J. M., Fournier-Viger, P., Moghrabi, C. (2016). Authorship Attribution Using Small Sets of Frequent Part-of-Speech Skip-grams. Proc. 29th Intern. Florida Artificial Intelligence Research Society Conference (FLAIRS 29), AAAI Press, pp. 86-91.
There are also other possible applications of finding patterns in text such as plagiarism detection.
Conclusion
In this blog post, I have shown how open-source software can be used to easily find patterns in text. The SPMF library can be used as a standalone program or can be called from other Java program. It offers many algorithms with several parameters to find various types of patterns. I hope that you have enjoyed this tutorial. If you have any comments, please leave them below.
==
Philippe Fournier-Viger is a full professor and also the founder of the open-source data mining software SPMF, offering more than 110 data mining algorithms. If you like this blog, you can tweet about it and/or subscribe to my twitter account @philfv to get notified about new posts.




Dear Sir,
Thank you for the post. I’m Abhijith Athreya, a prospective graduate student. I’m intending to apply for Fall 2017. I’ve 6 years of experience in IT industry. I’m interested in data mining. I’ve received many awards in my organization for considerable contributions towards the same. I’ve a GRE score of 328 and TOEFL of 111.
The SPMF Library doesn’t run on my Machine. Is there a Minimum Java version required?
Thank you
Hi,
If you are applying for my university (HIT Shenzhen), you may contact the university to ask about the requirements for being accepted. It is a great university. One of the top ten in China. If you come here, you will certainly enjoy it.
Yes, to run the library you need Java 1.8. Most of the code is written in Java 1.6. But a few classes requires 1.8, so it is better to just update Java to the latest version on your machine. Then, it should run well.
Best regards,
Dear Mr Fournier-Viger,
Just wondering, if one has investigate the speed up in association rule mining (ie Utility) using GPU parallel framework or at least if parallelization of the mining algorithms would be possible ?
I remember having seen that some papers have been published recently about using GPU in association rule mining, but I did not read the paper(s). You may be able to find it perhaps on Google Scholar.
By the way, many pattern mining algorithm for association rule mining and itemset mining are easily parallelizable. The reason is that many of them use a depth-first search. Thus each branch of the search space could be easily explored by a different thread or on a different computer on a parallel system.
There are many parallel algorithms that have been proposed for itemsets and pattern mining on multicore, multi-thread or big data framework.
Dear Mr Fournier-Viger,
I’m Catherine Vargas, a student of Carlos III of Madrid University.
I just wondering If it’s posible analyze text in spanish with this library.
Regards
Good evening,
Yes, the library can be used with text in any language, as long as words are separated by space and there is some punctuations like “. , ? … ” between sentences. So it works with English and it should work with other latin languages like French, Spanish, and Italian.
Best regards,
Pingback: An Introduction to Sequential Pattern Mining | The Data Mining Blog
Fantastic tutorial on text mining using the Sherlock Holmes novel! The step-by-step guide, coupled with the Java open-source SPMF library, makes it easy to understand complex relationships between words. Discovering hidden patterns was made simple, thanks to clear instructions and screenshots. A great resource for anyone interested in delving into text analysis. Kudos!