
In this post, I will provide links to standard benchmark datasets that can be used for frequent subgraph mining. Moreover, I will provide a set of small graph datasets that can be used for debugging subgraph mining algorithms.
The format of graph datasets
A graph dataset is a text file which contains one or more graphs. A graph is defined by a few lines of text that follow the following format (used by the GSpan algorithm)
t # N This is the first line of a graph. It indicates that this is the N-th graph in the file
v M L This line defines the M-th vertex of the current graph, which has a label L
e P Q L This line defines an edge, which connects the P-th vertex with the Q-th vertex. This edge has the label L
Small datasets for debugging
Here are some small datasets that can be used for debugging frequent subgraph mining algorithms. Each dataset contains one or two graphs, which is enough for some small debugging tasks.
Content of the file:
t # 1 v 0 10 v 1 11 v 2 12 e 0 1 21 e 2 1 21
Visual representation:
(L10) ---L21--- (L11) ---- L21 ---- (L12) 0 1 2
Content of the file:
t # 1 v 0 10 v 1 11 v 2 10 v 3 10 e 0 1 21 e 2 1 21 e 1 3 21
Visual representation:
(L10) --- L21 --- (L11) --- L21 ---- (L10) 0 1 2 | | L21 | | (L10)3
Content of the file:
t # 1 v 0 10 v 1 10 v 2 10 e 0 1 20 e 1 2 20 e 2 0 20
Visual representation:
(L10)---- (L11) ---- (L10) 0 1 2
Content of the file:
t # 1 v 0 10 v 1 10 v 2 11 v 3 11 e 0 1 21 e 0 2 20 e 1 3 20 e 2 3 22 e 1 2 23
Visual representation:
(L10) ------- L20 ------ (L11) | / | | / | | / | L21 / | | L23 L22 | / | | / | | / | | / | (L10) ------ L20 -------- (L11)
Content of the file:
t # 1 v 0 10 v 1 10 v 2 11 v 3 11 e 0 2 20 e 1 3 20 e 1 2 20
Visual representation:
(10) -- 20 -- (11) -- 20 – (10) –-- 20 –---(11) 0 2 1 3
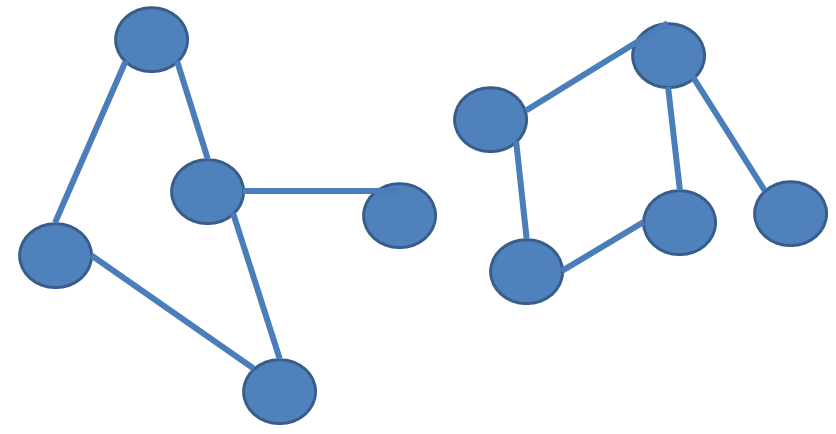
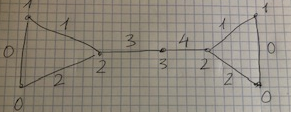
Content of the file:
t # 0
v 0 0
v 1 1
v 2 2
v 3 3
v 4 2
v 5 0
v 6 1
e 0 1 0
e 1 2 1
e 0 2 2
e 2 3 3
e 3 4 4
e 4 5 2
e 4 6 1
e 5 6 0
Visual representation:
Large datasets for subgraph mining
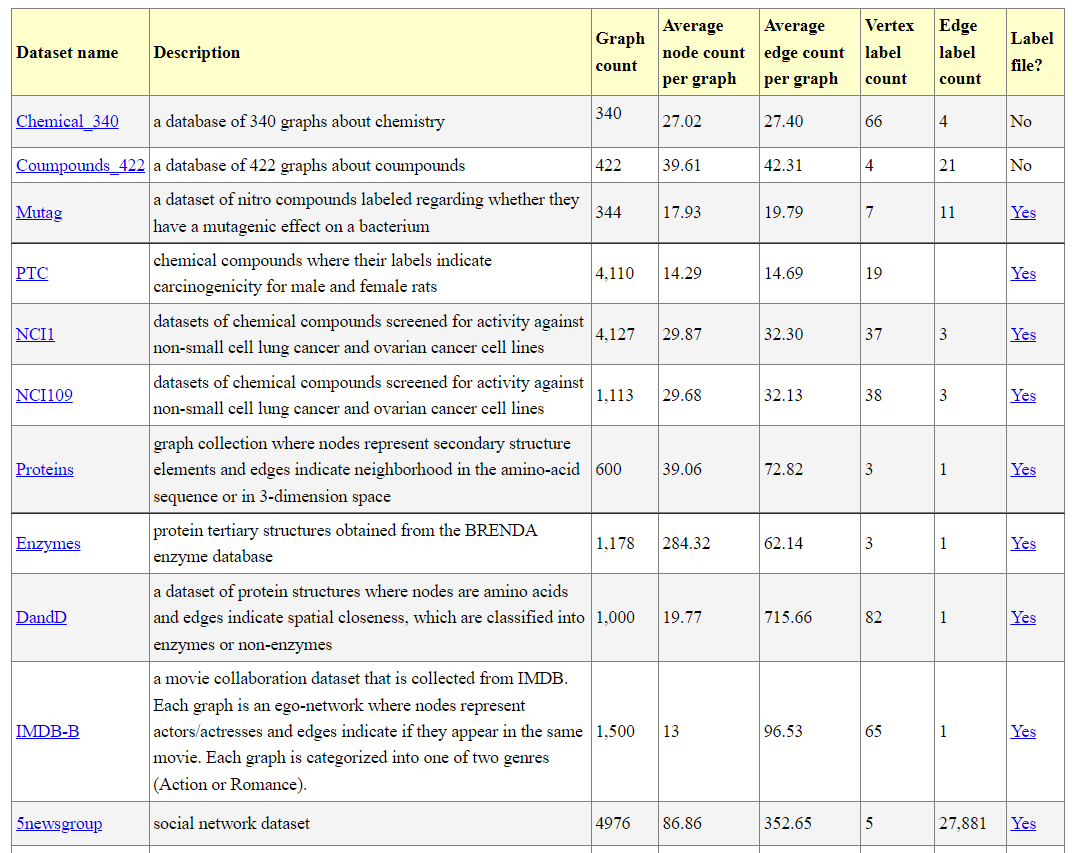
Moreover, here are about 15 large sugraph datasets that are used in frequent sub-graph mining available at this webpage:
SPMF Public Datasets (webpage)
Want to try frequent subgraph mining?
If you want to try frequent subgraph mining algorithms, some public fast Java open-source implementations of TKG for top-k frequent subgraph mining, cgSpan and gSpan are available in the SPMF data mining library.
Conclusion
In this blog post, I have share some helpful datasets. If you want to know more about subgraph mining you may read my short introduction to subgraph mining.
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 145 data mining algorithms.


