If you are not familiar with FP-trees, the FP-tree is a data structure used in the field of data mining by the classical FP-Growth algorithm to discover frequent itemsets. The FP-tree is a type of prefix-tree (trie) structure, in which transactions are inserted.
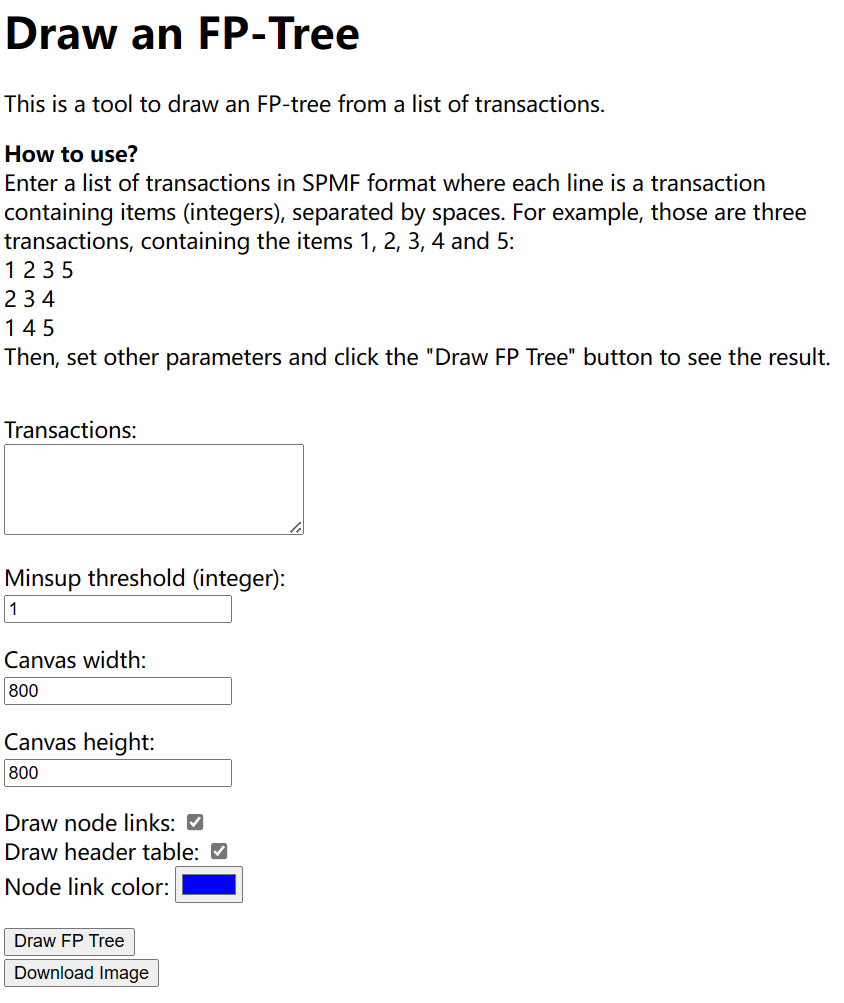
The new webpage allows drawing FP-treesby entering a set of transactions in a text area, choosing a minimum support threshold and then clicking a button to draw the tree. There are also some other options to customize the result such as some checkboxes to decide whether to draw the header table and node links of the fp-tree or not.
Now, let met me show you the user interface of this tool:
The interface is very straightforward. To use this tool, we must first input a set of transactions using the SPMF format. Thus, we must write one transaction per line, where each transactions is a list of integers (items) separated by spaces. For example, lets say that I enter the following three transactions:
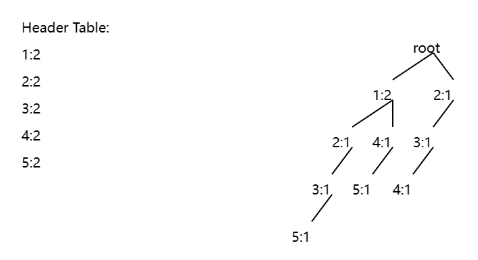
1 2 3 5 2 3 4 1 4 5
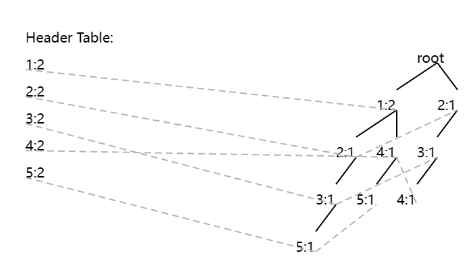
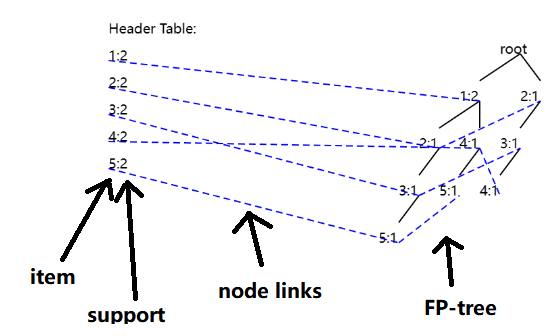
and set minsup = 1 transaction, and then if I click the “Draw FP-Tree” button, the result is:
The meaning is as follows:
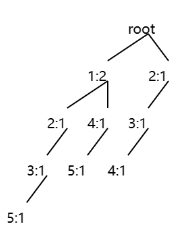
This type of picture displays the header table, node-links and fp-tree. The webpage also provides the option of only drawing the tree:
Or just drawing the tree and header table:
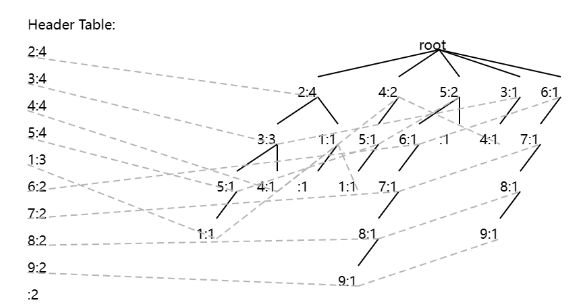
Let me now show you are more complex example, for another set of transactions:
If I set minsup = 1 transaction, the following fp-tree is drawn:
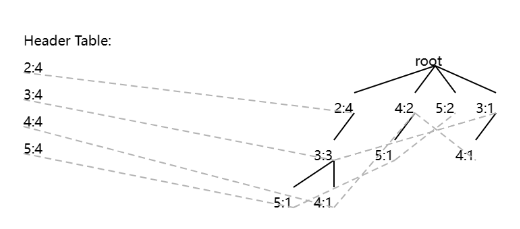
Then, if we raise the minsup threshold to 3 transactions, a smaller fp-tree is obtained:
And if we increase to minsup = 4 transactions, we obtain this fp-tree:
If you want to see more possibility, you can try it! And if you find some bugs, you may send me an e-mail to let me know. It is possible that there is still some bugs for some special cases.
Conclusion
In this blog post, I have introduced a new tool for drawing FP-trees using HTML5 and Javascript. Hope that it is interesting. Contrarily to some other tools for drawing FP-trees, this tool not only draw the tree but also the header table and node-links.
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 250 data mining algorithms.
Today, I will share the good news that I have participated as co-author in a paper proposing a new algorithm for high utility itemset mining called HAMM that is very efficient, and outperforms the state-of-the-art algorithm. This is not an easy feat as there has been many algorithms for this problem since more than a decade. The algorithm will appear in an upcoming issue of the IEEE TKDE journal (one of the top journals in data mining).
What is especially interesting about this new HAMM algorithm is that it is inspired by FP-Growth but runs in a single phase unlike the previous FP-Growth based algorithms for utility mining such as UP-Growth and IHUP. Besides, it is combined with the concept of utility vectors and novel strategies are developed in HAMM
Currently, the paper is accepted but not published yet in a regular issue of TKDE, thus I will wait for the final version to be ready before sharing.
However stay tuned! And here is the citation for this new paper:
J. -F. Qu, P. Fournier-Viger, M. Liu, B. Hang and C. Hu, “Mining High Utility Itemsets Using Prefix Trees and Utility Vectors,” in IEEE Transactions on Knowledge and Data Engineering, doi: 10.1109/TKDE.2023.3256126.
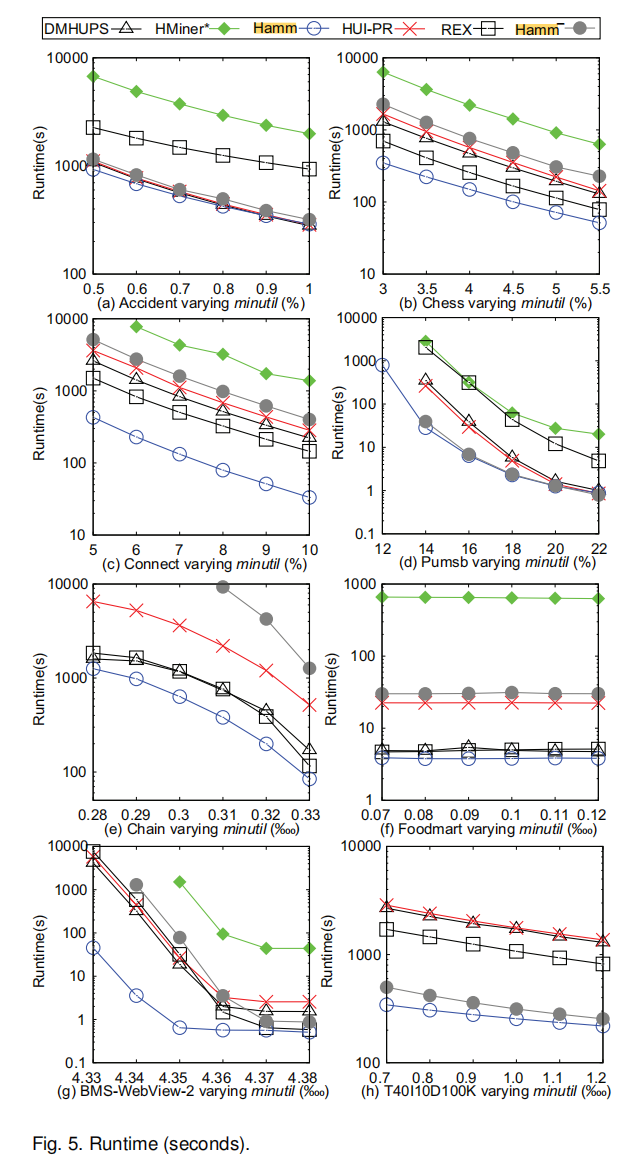
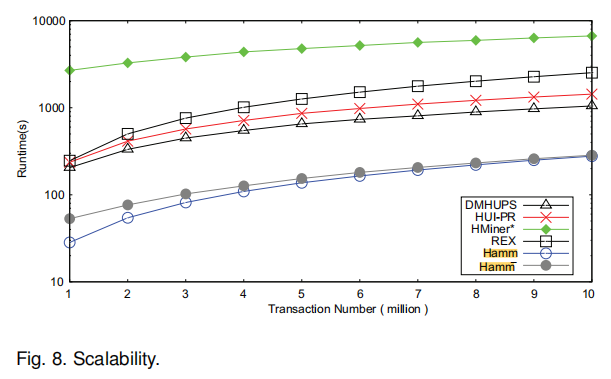
The performance results are excellent compared to many of the most recent high utility itemset mining algorithms. Here are a few figures from the paper:
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 250 data mining algorithms.
I have added two new webpages offering tools to count the frequency of each word and ngrams (consecutive sequences of words) in a text document. These webpages can be found here:
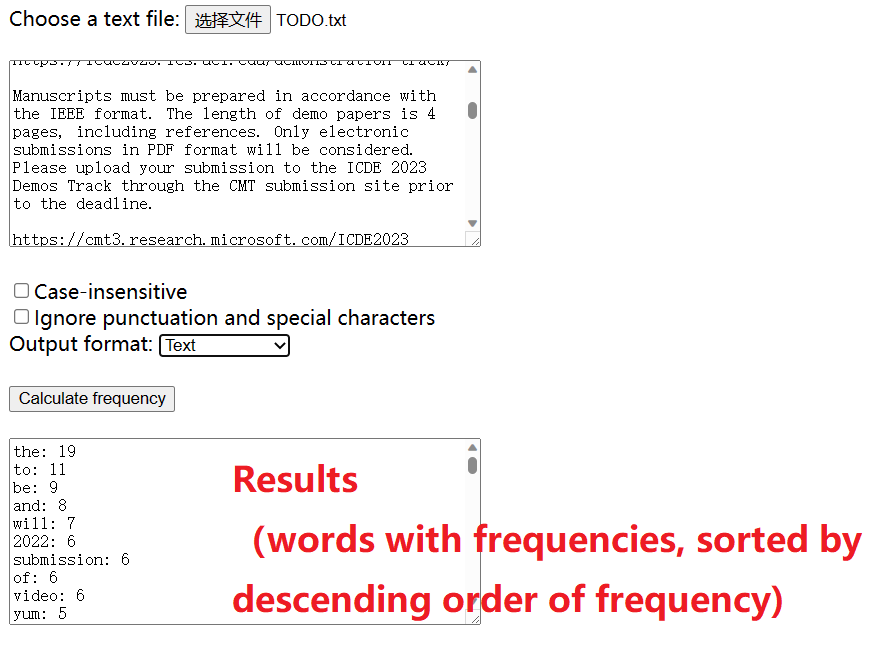
First, let me show you the Word Frequency Counter so that you know what it can do. The user interface is very user-friendly and simple. It is shown below:
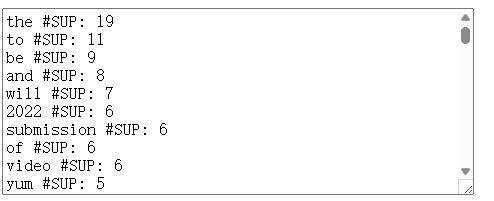
To use the tool, we must first select a file to upload, and then select some options such as to ignore case and puncutations. We can also choose the type of output format such as the CSV format, tab-separated format, and SPMF format. Then we must click the “calculate frequency button” to run the program. For instance, lets say that I try with a small text file from my computer called TODO.txt. The results look like this:
We can see the words with their frequencies, sorted by descending order of frequency. In this case, I chose the default output format. But other output format are offered:
If I choose CSV format, the results look like this:
If I choose the Tab-separated format, the results look like this:
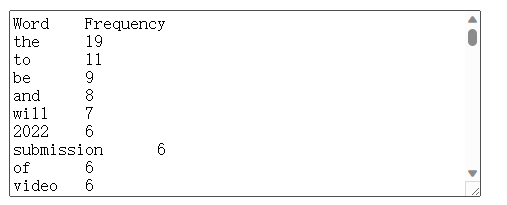
And if I choose the SPMF format, the results look like this:
The Ngram Frequency Counter
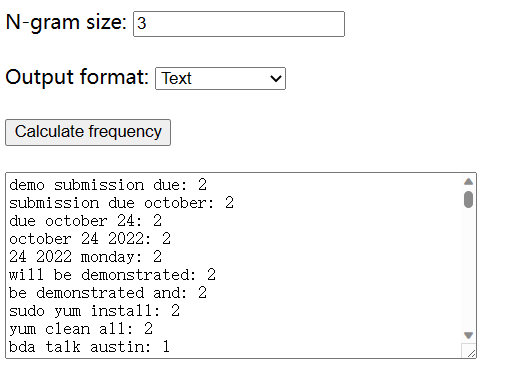
Now let me show you the Ngram Frequency Counter. The user interface is very similar, except that we have an additional parameter which is the ngram size. For example, if we set the ngram size to 3, the tool will count the frequency of all sequences of 3 words (that are consecutive in a text document).
Let me show you an example, with the same example text file and an n-gram size of 3:
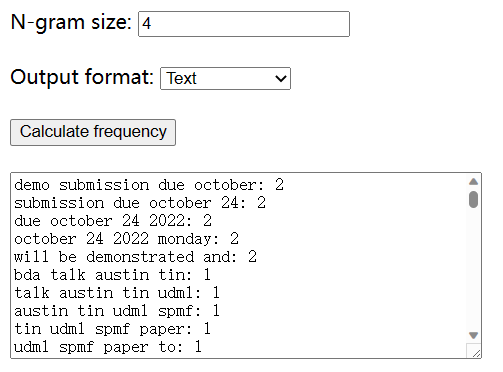
Now, let’s say that I change the ngram size to 4, here is the result:
As for the other tools, we can also change the output format.
Conclusion
This was just a short blog post to show you two new tools offered on my website, namely the Word Frequency Counter and the Ngram Frequency Counter. Those tools are simple and implemented in HTML5 + javascript.
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 250 data mining algorithms.
In the last decades, many data mining algorithms were developed to find interesting patterns in data (pattern mining). In particular, a lot of studies have been done about discovering frequent patterns (patterns that appear frequently) in a data. A classic example of this type of problem is frequent itemset mining, which aims at finding sets of values that frequently appear together in a database. This data mining task has many applications. For instance, it can be used to find all the itemsets (sets of products) that customers buy frequently in a database of customer transactions.Though discovering frequent patterns in data has many applications, there is an underlying assumption that patterns that frequently appear in data are important. But in real-life that is not always the case. For example, by analyzing data from a store, we may find that people very frequently buy bread and milk together but this pattern may not be interesting because it is very common, and thus it is not surprising at all that customers buy these products together.
Thus, in some cases, it is interesting to search for patterns in data that are rare. Finding rare patterns has thus drawn the interest of many researchers. It has for example applications such as to study rare diseases, rare occurrences of network failures, and suspicious behavior.In this blog post, I will thus talk about the problem of finding patterns in data that are infrequent (rare), which is known as the problem of rare itemset mining.
Some important definitions
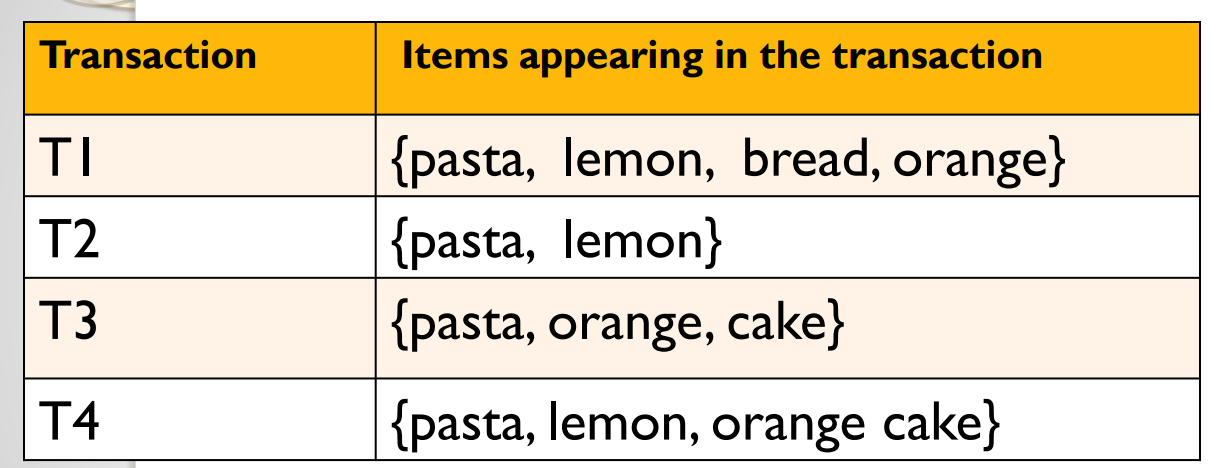
To explain what is rare itemset mining, let me first introduce some definitions. To make it easy to understand, I will explain using the example of analyzing shopping data. But rare itemset mining is not limited to this application. Let take for example the table below, which shows a database of customer transactions made in a store by different customers:
This database contains four transactions called T1, T2, T3 and T4, corresponding to four customers. The first transaction (T1) indicates that a customer has bought pasta, lemon, bread and orange. The second transaction (T2) indicates that a customer has bought pasta and lemon together. Transaction T3 indicates that a customer bought pasta, orange and cake, while transaction T4 indicates that someone bought pasta, lemon, orange with cake.
If we have such data, we can apply pattern mining algorithms to discover interesting pattern in it. Several algorithms are available for this. The traditional task is to find the frequent itemset mining, that is all the sets of items (itemsets) that appear more than minsup times in a database, where minsup is a threshold set by the user. For example, if the user set minsup = 2, then the goal of frequent itemset mining is to find all sets of items that have been purchased at least twice by customers. For instance, in the above database, the frequent itemsets are the following:
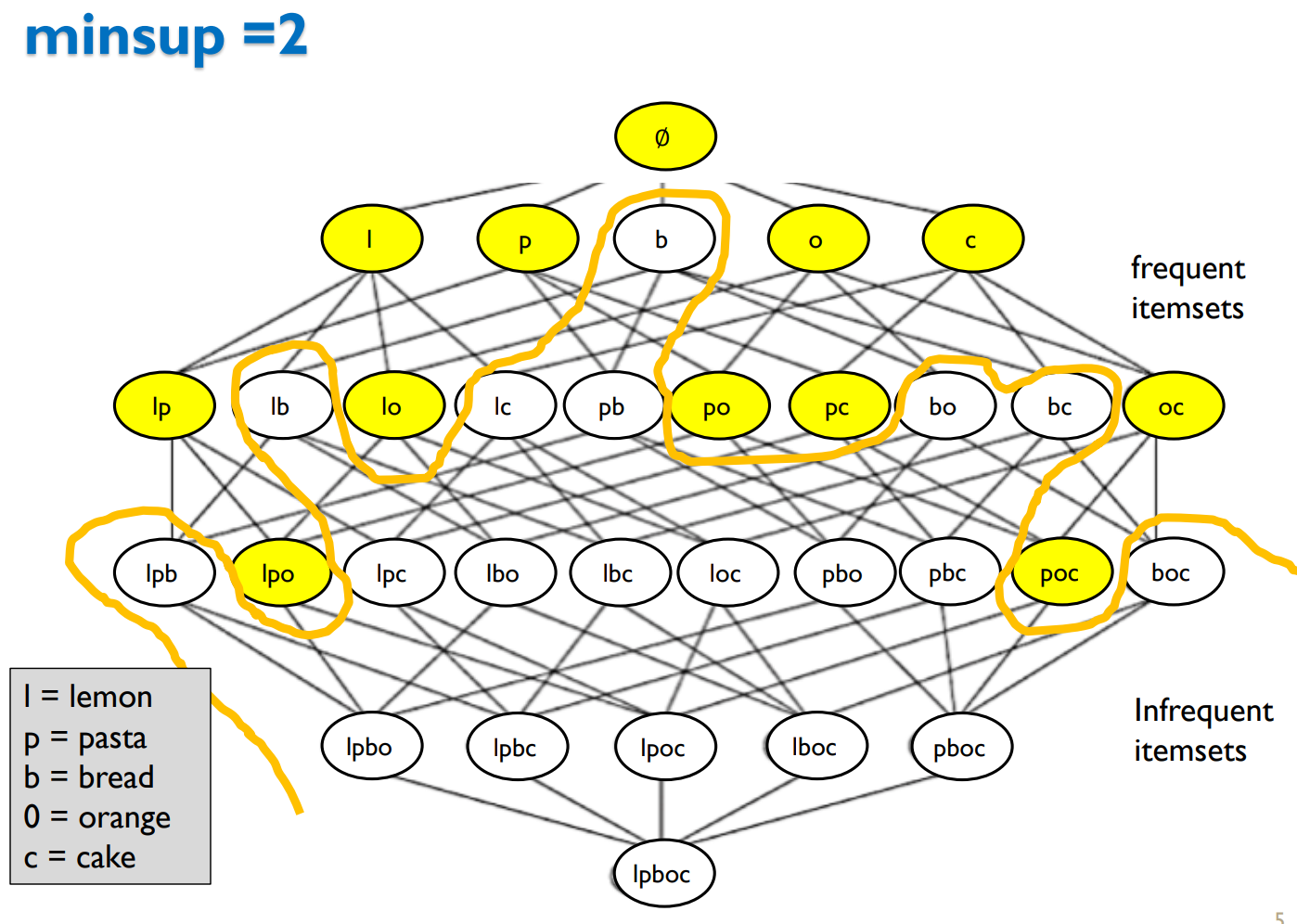
For instance, {lemon} is said to be a frequent itemset because it appears at least twice in the database above. In fact, lemon actually appear three times (in transactions, T1, T2 and T4). Another example is the itemset {pasta, cake}, which is said to be frequent because it appears in two transactions (T3 and T4). Generally, if an itemset appears in X transactions, we say that an itemset has a support of X transactions. For instance, we say that the itemset {lemon} has a support of 3 and the itemset {pasta, cake} has a support of 2. If we want to visualize the frequent itemsets and all the possible itemsets, we can draw a picture called a Hasse Diagram, shown below:
In this picture, we have all the possible itemsets (combinations of items) that customers could buy together. To make the picture easier to read, we use the letters l, p, b, o, c to represents the items lemon, pasta, bread, orange, and cake, respectively. So for example, the notation “poc” means to buy pasta, orange and cake together. In the picture, the frequent itemsets are colored in yellow, while the infrequent itemsets are colored in white. And there is an edge between two itemsets if one is included in the other and the other has one more item. For example, there is an edge from “po” to “poc” because “po” is included in “poc” and “poc” has one more item. Totally, if we have five items such as in this case, there is a total of 2^5 = 32 possible itemsets, as depicted in this picture. The itemset on top of this picture is the empty set, while the one at the bottom is “lpboc”, which means to buy all the five items together.The problem of frequent itemset mining thus aims at finding values that appear frequently together (the yellow itemsets0. But what if we want to find the itemsets that are rare instead of frequent? To do this, we first need to define what we mean by rare itemset. There are a few definitions. I will give a brief overview.
Definition 1: the infrequent itemsets
The most intuitive definition of what is a rare itemset is that it is an itemset that is not frequent. Thus, we can say that a rare itemset is an itemset that has a support that is less than the minsup threshold set by the user. Formally, we can write that an itemset X is infrequent if sup(X) < minsup, where sup(X) represents the support of X.
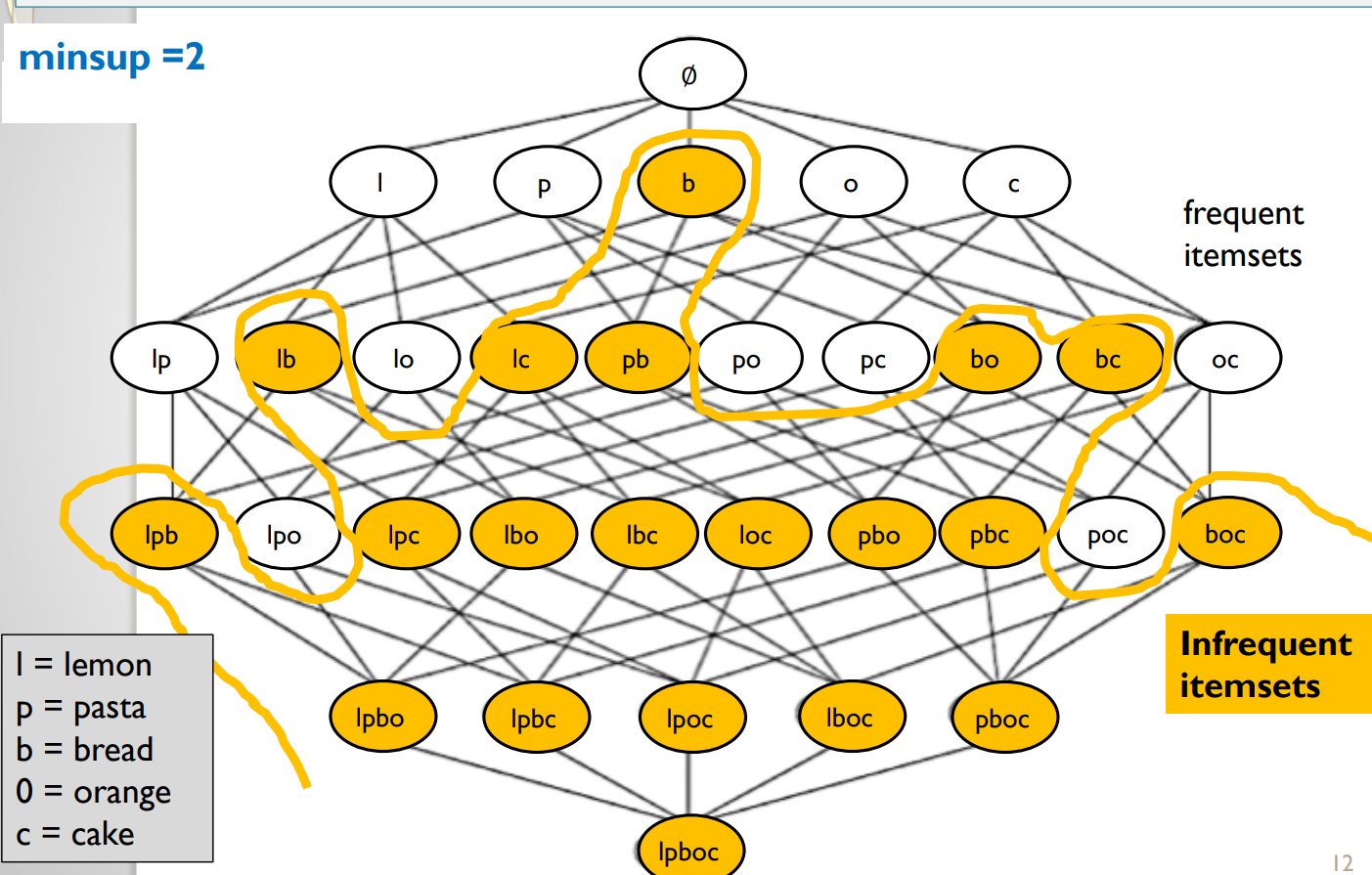
For example, if minsup = 2, the infrequent itemsets are illustrated in orange color in the picture below:
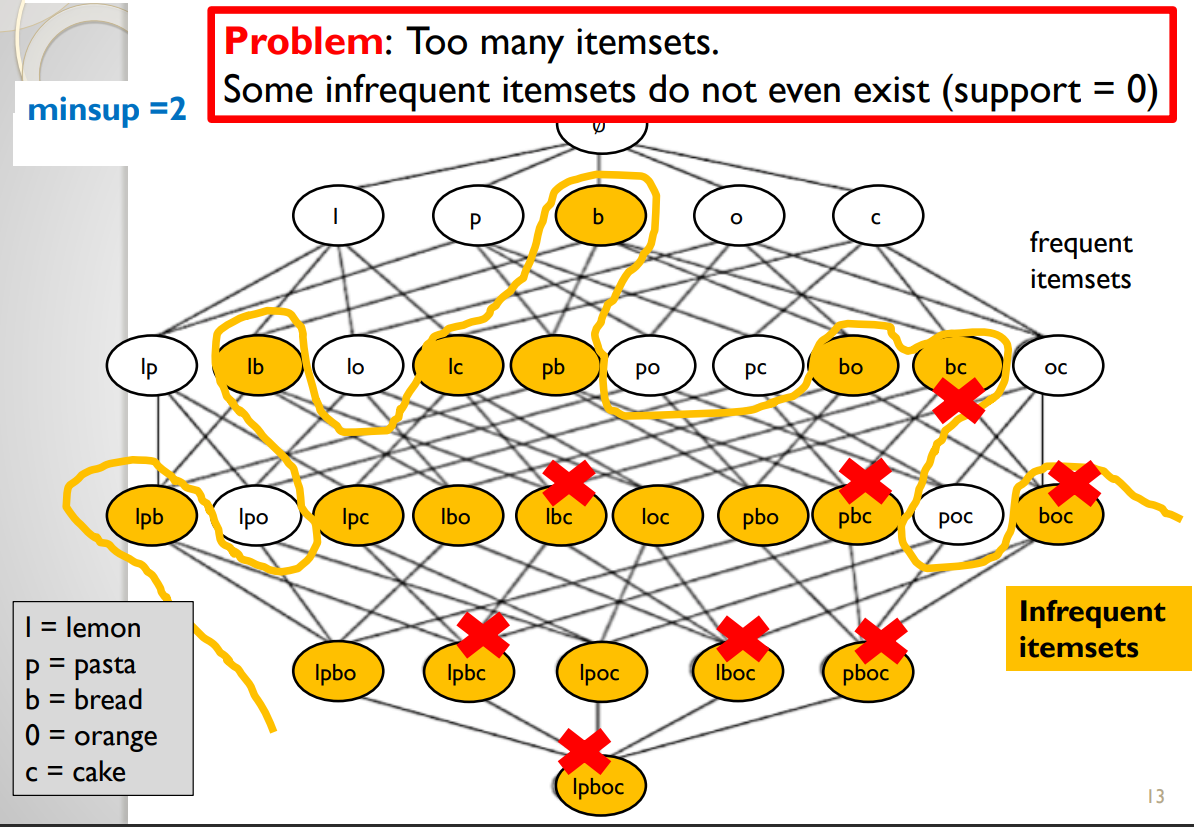
All these itemsets are infrequent because their support is less than 2. For example the itemset “bo” (bread and orange) has a support of 1, while “bc” (bread and cake) has a support of 0.Is this a good definition? No, because there are just too many infrequent itemsets. And in fact, it can be observed that many of them never appear in the database. For example, “pboc” (pasta, bread, orange and cake) is an infrequent pattern, but it has a support of zero because no customer has bought these items together. It is obviously uninteresting to find such patterns that have a support of zero. Itemsets having a support of zero are illustrated with a X in the picture below:
Thus, we may try to find a better definition of what is a rare itemset so that we will not find too many rare itemsets.
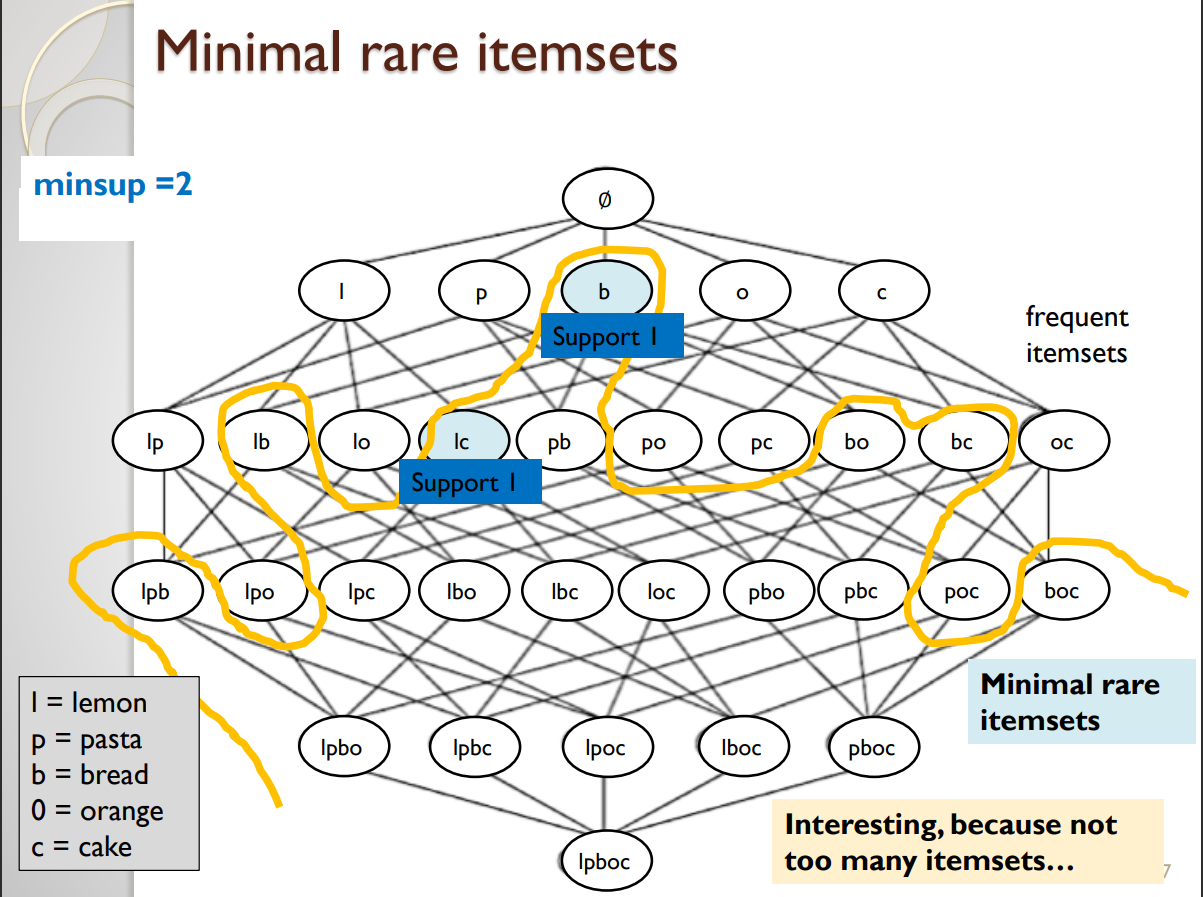
Definition 2: minimal rare itemsets
An alternative definition of what is a rare itemsets was proposed. An itemset X is said to be a minimal rare itemset if sup(X) <= minsup and all (proper) subsets of X are frequent itemsets. To make this easier to understand, I have illustrated the minimal rare itemsets on the picture below for minsup = 2 for the same example.
Here we can see that there are only two minimal rare itemsets, which are “lc” and “b”. “lc” is a minimal rare itemset because its support is less than 2, and all its subsets (“l” and “c”) are frequent. And “b” is a minimal rare itemset its suport is less than 2 and all its subsets are frequent (in this case, the only subset of “b” is the empty set, which is always frequent by definition).
Thus, if we find only the minimal rare itemsets, we may find a small set of itemsets that are almost frequent.
The first algorithm that was proposed to find minimal rare itemsets is AprioriRare by Szathmary & al (2007) in this paper:
An efficient open-source implementation of AprioriRare can be found in the SPMF software.
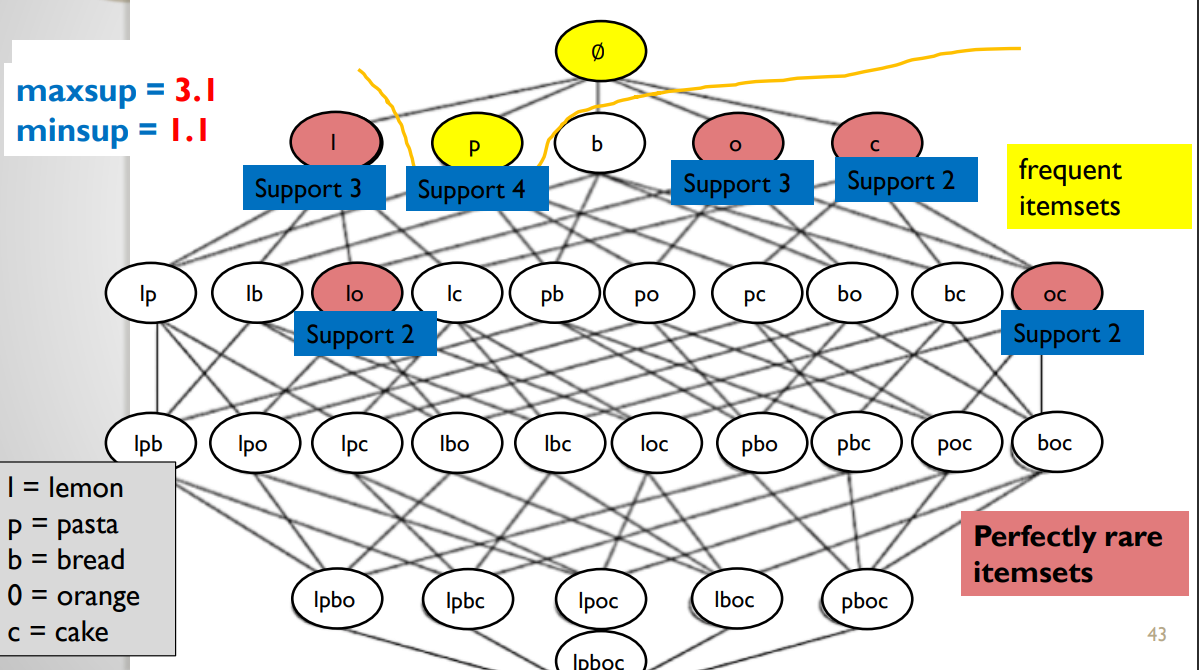
Definition 3: perfectly rare itemsets
Another definition of what is a rare itemset was proposed by Koh et al. (PAKDD 2005). They define the concept of perfectly rare itemset as follows:
In that definition, the key idea is to use two threshold minsup and maxsup. Then, the aim is to find all itemsets that have a support no less than minsup and contain items with a support less than maxsup.
To show and example, of the type of results that this provides, here is the perfectly rare itemsets for minsup = 1 and maxsup = 1.9 for the same example:
And if we change the parameters a little bit, here is the result:
The first algorithm for mining perfectly rare itemset is AprioriInverse by Koh et al. in this paper:
Yun Sing Koh, Nathan Rountree: Finding Sporadic Rules Using AprioriInverse. PAKDD 2005: 97-106
An open-source implementation of AprioriInverse can be found in the SPMF software.
Other extensions
There also exist other extensions and variations of the problem of rare itemset mining besides what I have covered in this blog post. My aim was to give a brief overview.
Software for rare itemset mining
If you want to try rare itemset mining, you can check the SPMF software, as I have mentioned above. It provides over 250 algorithms for various pattern mining tasks, including several algorithms for rare pattern mining. SPMF is written in Java but can be called from various languages and use also as a standalone application.
In this blog post, I have explained briefly what is rare itemset mining, that is how to find infrequent patterns in data. I mainly explained the different problem definitions but did not go into details about how the algorithms work to keep the blog post short. Hope you have enjoyed this. If you have any questions or feedback, please leave a comment below. Thank you for reading!
By the way, if you are new to itemset mining, you might be interested to check these two survey papers that give a good introduction to the topic:
Fournier-Viger, P., Lin, J. C.-W., Vo, B, Chi, T.T., Zhang, J., Le, H. B. (2017). A Survey of Itemset Mining. WIREs Data Mining and Knowledge Discovery, Wiley, e1207 doi: 10.1002/widm.1207, 18 pages.
Luna, J. M., Fournier-Viger, P., Ventura, S. (2019). Frequent Itemset Mining: a 25 Years Review. WIREs Data Mining and Knowledge Discovery, Wiley, 9(6):e1329. DOI: 10.1002/widm.1329
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 250 data mining alg
Hi all, this is to let you know that I have developed a free pattern mining course that you can watch online. The course is designed to introduce students or researchers to the different topics of pattern mining and explain the key algorithms and key concepts. I
The course can be watched online as video lectures and contains PPT slides, exercises and you can also use the SPMF software to try all algorithms that are discussed in the course, and see the source code.
The course is provided for free to share education on this topic with everyone 😉 But note that this course is in BETA because I will keep adding more content to cover more topics in the next months. Currently, the list of topics already covered are:
Hope you will enjoy this free course. If you have any feedback for improvement, you can send me an e-mail or leave a comment at the bottom of this page. I will be pleased to read your comments.
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 250 data mining algorithms.
In data mining, an itemset is a collection of items that occur together in a transactional dataset. For example, if we have a dataset of customer purchases, an itemset could be {bread, cake, orange}, meaning that these three items were bought together by several customers.
Afrequent itemset is an itemset that occurs at least a certain number of times (or percentage) in the dataset. This number or percentage is called the minimum support threshold and it is usually specified by the user (but could be set automatically). For example, if we set the minimum support threshold to 3, then {bread, milk, eggs} is a frequent itemset if it occurs in 3 or more transactions in the dataset.
A maximal frequent itemset is a frequent itemset for which none of its immediate supersets are frequent. An immediate superset of an itemset is an itemset that contains one more item than the original itemset. For example, {bread, cake, orange, pasta} is an immediate superset of {break, cake, orange}. A maximal frequent itemset is thus a frequent itemset that cannot be extended with any other item without losing its frequency.
To illustrate this concept, consider the following example:
Transaction ID
Items
1
A B C D
2
A B D
3
A C D
4
B C D
Assume that the minimum support threshold is 50%, meaning that an itemset must occur in at least 2 transactions to be frequent (since this datasets has four transactions). The following table shows all the possible itemsets and their support counts (number of transactions in which they occur):
Itemset
Support count (how many times an itemset appears in the database)
A
3
B
3
C
3
D
3
AB
2
AC
2
AD
3
BC
2
BD
3
CD
3
ABC
1
ABD
2
ACD
2
BCD
2
ABCD
1
Based on the minimum support threshold, the frequent itemsets are A, B, C, D, AB, AC, AD, BC, BD, CD, ABD, ACD, and BCD. Out of these 13 frequent itemsets, only three are identified as maximal frequent: ABD, ACD and BCD. This is because none of their immediate supersets (ABCD) are frequent. The remaining frequent itemsets are not maximal frequent because they all have at least one immediate superset that is frequent. For example, B is not maximal frequent because AB, BC and BD are all frequent.
Why are maximal frequent itemsets useful?
Maximal frequent itemsets provide a compact representation of all the frequent itemsets for a given dataset and minimum support threshold. This is because every frequent itemset is a subset of some maximal frequent itemset. For example, in the above example, all the frequent itemsets are subsets of either ABD, ACD or BCD. Therefore, by knowing ABD, ACD and BCD and their support count, we can derive all the other frequent itemsets but we many not know their exact support count.
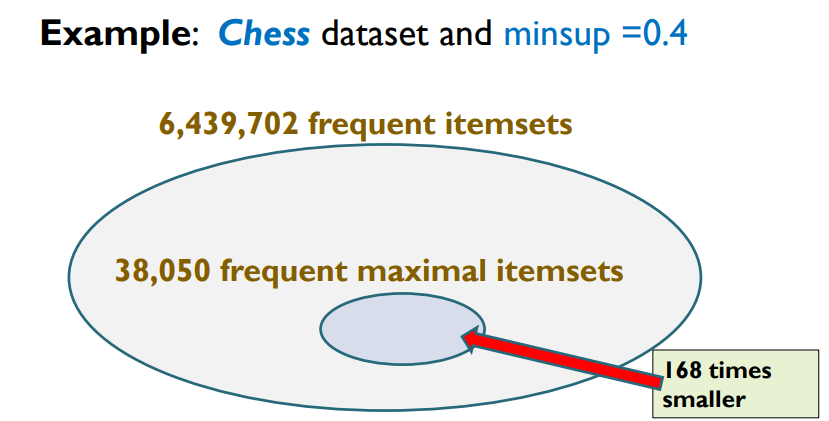
It is useful to discover maximal frequent itemsets because it gives a summary of all frequent itemsets to the user. Also discovering maximal frequent itemsets can be faster and require less memory and storage space than finding all the frequent itemsets. I will give an example of a real benchmark dataset called Chess to show how compact the maximal itemsets can be. If we set minsup = 40% on Chess, we get about 6 millions frequent itemsets but only 38,050 maximal frequent itemsets.
Note that besides maximal itemsets there also exists other compact representations of frequent itemsets such as closed itemsets and generator itemsets.
How to find maximal frequent itemsets?
There are several algorithms for finding maximal frequent itemsets from a transactional dataset. They are generally variations of the popular frequent itemset mining algorithm such as FPGrowth, Eclat and Apriori.
One of the most efficient algorithm for maximal itemset is FPMax, which is based on the FP-Growth algorithm. It uses a compact data structure called FP-tree. FPMax builds an FP-tree from the dataset and then mines it recursively by generating conditional FP-trees for each item. It uses several pruning strategies to avoid generating non-maximal frequent itemsets and reduce the size of the conditional FP-trees.
Some other notable algorithms for maximal itemset mining are MAFIA, LCM_MAX and GENMAX.
Source code and datasets
If you want to try discovering frequent itemsets, closed itemsets, maximal itemsets and generator, you can check the SPMF data mining software, which is implemented in Java and can be called from other popular programming languages as well. It is highly efficient an open-source, with many examples and datasets.
Video
If you are interested to learn more about this topic, you can also watch a 50 minute video lecture where I explain in more details what are maximal itemsets, closed itemsets and generator itemsets. This video is part of my free pattern mining course, and you can watch from my website here: Maximal, Closed and Generator itemsets or from my youtube channel here
Conclusion
In this blog post, I have explained briefly what is a maximal itemset, why it is useful, and talked about some algorithms for this problem. Hope that you have enjoyed this post!
By the way, if you are new to itemset mining, you might also be interested to check these two survey papers that give a good introduction to the topic:
Fournier-Viger, P., Lin, J. C.-W., Vo, B, Chi, T.T., Zhang, J., Le, H. B. (2017). A Survey of Itemset Mining. WIREs Data Mining and Knowledge Discovery, Wiley, e1207 doi: 10.1002/widm.1207, 18 pages.
Luna, J. M., Fournier-Viger, P., Ventura, S. (2019). Frequent Itemset Mining: a 25 Years Review. WIREs Data Mining and Knowledge Discovery, Wiley, 9(6):e1329. DOI: 10.1002/widm.1329
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 250 data mining algorithms.
Today, I present a glossary of key terms usedin high utility itemset mining. This glossary will be useful to researchers and practitioners working on this important subtopic of pattern mining. By the way, if you are new to this research area, you may find it useful to first read the survey paper that I wrote on this topic, or to watch my video lectures on this topic on my Youtube Channel. Also, you may want to check out the list of key research papers on high utility itemset mining that I made, which can also be useful to get started on this topic or to discover some topics.
Closed high utility itemset: A high utility itemset that has no superset with the same utility. For example, if {bread, milk} and {bread, milk, cheese} have the same utility, then {bread, milk} is not closed but {bread, milk, cheese} is closed. The first algorithm for this problem is CHUD. Then, many more algorithms were developed to improve the performance.
Correlated high utility itemset: A correlated high utility itemset is a set of items that not only yield a high utility but is also highly correlated. Various measures of correlations can be used such as the bond, and all-confidence.
Cost-effective pattern mining: A variation of the high utility itemset mining task where the goal is to find itemsets that have a high utility but a low cost.
Cross-level high utility itemset: This is variant of the high utility itemset mining problem where items have categories such as “electronic products” or “food”. Then, the goal is to find itemsets that have a high utility but which may contain categories. The first algorithm for the general problem of cross-level high utility itemset is CLH-Miner. Another is TKC.
External utility: A measure of the importance of each item. It is usually given by the user or domain expert. For example, in the context of a shopping database, the external utility may represent the profit that is generated by each item (e.g. each apple yield a 1$ profit, while each orange yield a 2$ profit)
Frequent itemset mining (FIM): A data mining task that finds all sets of items that appear in at least a minimum number of transactions in a transaction database. It is a special case of high utility itemset mining.
High-utility association rule mining: A data mining task that extends HUIM by finding association rules that have a high confidence and a high utility value. An association rule is an implication of the form X -> Y, where X and Y are itemsets.
High average-utility itemset: An itemset whose average-utility is no less than a minimum average-utility threshold set by the user. The average-utility of an itemset is its utility divided by its size (number of items).
High-utility and diverse itemset mining: A data mining task that extends HUIM by incorporating a notion of diversity to find patterns that cover different categories of items. The diversity of an itemset is defined as the number of distinct categories covered by its items divided by the total number of categories.
High-utility episode mining: A data mining task that extends HUIM by finding episodes that have a high utility value. An episode is a partially ordered set of events that frequently occur together in an event sequence. An event sequence is a sequence of events, where each event has a type and a timestamp. Several algorithms have been proposed for this task such as UP-SPAN and HUE-SPAN.
High-utility graph pattern mining: A data mining task that extends HUIM by finding graph patterns that have a high utility value. A graph pattern is a subgraph that frequently appears in a graph database. A graph database is a database where each transaction is a graph, which is a set of nodes and edges. A representative algorithm for this problem is UGMINE.
High-utility itemset embedding: Some algorithms like HUI2Vec have been designed to use high utility itemsets to create embeddings of transaction databases. This is a recent topic.
High utility quantitative itemset mining: A data mining task that extends HUIM to find high utility itemsets with additional information about the quantities that are usually purchased for each itemset. This is a harder problem. There exist various algorithms for this problem such as FHUQI-Miner, HUQI-Miner and VHUQI.
High utility itemset: An itemset whose utility is no less than a minimum utility threshold set by the user. For example, if the minimum utility threshold is 10, then {bread, milk} is a high utility itemset if its utility is 10 or more
High utility itemset mining (HUIM): A data mining task where the goal is to finds sets of values (itemsets) in a transaction database that have a high importance, and where the importance is measured by a utility function. The typical application of HUIM is to find the sets of products that are purchased together and yield a high profit in transactions made by customers. But also many other applications exist. There exists many algorithms such as HAMM, REX, UP-Growth, EFIM, HUI-Miner, FHM, ULB-Miner, Two-Phase and others.
High-utility rare itemset mining: A data mining task that combines HUIM and rare itemset mining. It aims to find itemsets that have a high utility value but a low support value in a transaction database. It can be useful for finding profitable but infrequent patterns.
High-utility sequential pattern mining: A data mining task that extends HUIM by finding sequential patterns that have a high utility value. A sequential pattern is an ordered list of itemsets that frequently appear in a sequence database. A sequence database is a database where each transaction is associated with a timestamp or an order. A survey of high utility sequential pattern mining is here.
High utility sequential rule mining: A problem where the goal is to find temporal rules that have a high utility and indicate that if someone buy something, they will buy something else after. The first algorithm for mining high utility sequential rules is HUSRM.
Internal utility: A measure of the quantity of an item in a transaction (record). For instance, in the case of analyzing shopping data, the internal utility in a customer transaction is the quantities of items. Thus, a transaction may indicate, for example, that a customer has bought 4 apples, and 3 breads, and the internal utility of apple and bread in that transaction is 4 and 3, respectively.
Itemset: A set of items. For example, {bread, milk} is an itemset containing two items.
Local high utility itemset: A high utility itemset that is found in a database where transactions have timestamps. More precisely a local high utility itemset is an itemset that has a high utility in a time interval but not necessarily in the whole database. For example, some products may only yield a high profit during the summer in a store. LHUI-Miner is the first algorithm for this problem. A variation is also peak high utility itemset mining, described in the same paper.
Maximal high utility itemset: A high utility itemset that has no superset that is also a high utility itemset. For example, if {bread, milk} is a high utility itemset but {bread, milk, cheese} is not, then {bread, milk} is maximal. The first algorithm for this problem is CHUI-Miner(max).
Minimal High Utility Itemsets. A minimal high utility itemset is an itemset that is not a superset of another high utility itemsets. The first algorithm for this problem is MinFHM.
One-phase HUIM algorithm: A HUIM algorithm that can mine high utility itemsets without generating candidates. Several algorithms of this type such as HUI-Miner and FHM rely on the utility-list structure to efficiently calculate the utility of itemsets and prune the search space.
Pattern-growth algorithm: An algorithm that uses a divide-and-conquer strategy to find high utility itemsets. It recursively constructs conditional databases to explore the search space by performing a database projection operation. Some algorithms of this type are IHUP, UP-Growth, EFIM, HAMM and REX.
Periodic high utility itemset: An itemset that periodically appears over time and has a high utility. For example, a customer that buy cheese and bread every week. The first algorithm for this problem is PHM.
Pruning strategy: A technique that reduces the search space by removing unpromising items or itemsets from consideration. The goal of using pruning strategy in an algorithm is to improve performance (solve the problem more quickly or using less memory).
Quantitative database: A transaction database where each item has a quantity and an external utility value. The quantity of an item represents how many units of that item are present in a transaction. The external utility of an item represents the amount of profit yield by the sale of one unit of that item.
Stable high utility itemset: An itemset that has a utility that remains more or less stable over time. See the paper by Acquah Hackman for more details.
Support: The number of transactions that contain an itemset. For example, the support of {bread, milk} is 3 if it appears in three transactions1.
Top-K high utility itemset mining: A variant of HUIM that finds the K most profitable itemsets in a database without requiring the user to set a minimum utility threshold. There are many algorithms for this problem. The first one is TKU. Then, more efficient algorithms were proposed such as TKO.
Transaction. A transaction is a set of items bought by a customer. More generally, it can also be viewed as a database record containing some values.
Transaction database: A database containing a set of transactions made by customers.
Transaction utility (TU): The sum of the utilities of all items in a transaction. For example, the TU of a transaction where bread and milk are bought with quantities 5 and 2 respectively and profit units 0.5 and 1 respectively is (5 x 0.5) + (2 x 1) = 4.5.
Transaction-weighted utilization (TWU): An upper bound on the utility that can be used to reduce the search space for high utility itemset mining. There exists several upper bounds. The TWU is not the tightest upper bound but it is the most popular and has been used by many algorithms.
Two-phase HUIM algorithm: A HUIM algorithm that consists of two phases. In the first phase, it generates candidates by applying some pruning strategies based on some upper bounds on the utility. In the second phase, it scans the database again to calculate the exact utility of each candidate and filter out those that are not high utility. Some popular two-phase algorithms are Two-Phase, IHUP and UP-Growth.
Utility: A measure of importance or profit of an item or an itemset. It is typically calculated by multiplying the quantity and the external utility of an item in a transaction. But other utility functions could also be used.
Utility-list: A data structure that stores the utility information of an itemset in a compact way. It consists of a list of tuples, each containing the transaction identifier, the utility of the itemset in that transaction, and the remaining utility of the items after that itemset in that transaction. It is used by many algorithms such as HUI-Miner, FHM, ULB-Miner and many others.
Utility threshold: A user-defined parameter that specifies the minimum utility value for an itemset to be considered as high utility. It can be either absolute or relative. An absolute utility threshold is a fixed value, while a relative utility threshold is a percentage of the total utility of the database.
Hope that this is useful. If you think that I should add more definitions, you may suggest some in the comment section below!
If you want to try high utility itemset mining, you can also check the SPMF open-source software, which offers the most complete collection of such algorithms, and also provides datasets and other resources for carrying research on this topic.
— Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 120 data mining algorithms.
Today, I will talk about what to do when a paper is rejected from a journal, and more specifically if it is possible to appeal the editor’s decision, and then what are the chance of success?
Generally, if a researcher sends papers to journals, it will sooner or later happen that some papers will be rejected. And sometimes it seems that the decision was unfair for various reasons. For instance, it may seem that reviewers have not understood the content of the paper or have been overly critical. Thus, several researchers will feel angry, disappointed, frustrated and think that the process was unfair. Sometimes it may be justified, but sometimes not.
Thus, what should a researcher do? A possibility is to try to argue with the editor or appeal the decision. The other possibility is to move on, fix the problems with the paper and submit it to another journal.
In my experience, trying to appeal the editor decision has a very low chance of success unless there was clearly some serious wrongdoing such as a reviewer submitting the review for the wrong paper. But in general, still different journals have different policies and procedures for handling appeals. I will now talk about this in more details.
When to appeal a journal rejection?
First of all, it is important to carefully read the rejection letter and the reviewers’ comments. If the rejection is based on factual errors, misunderstandings, or misinterpretations of your work, you may have grounds for an appeal. However, if the rejection is based on subjective opinions, preferences, or criticisms that are not constructive or specific, you may have little chance of success.
You should also consider the type and severity of the rejection. Some journals may reject your manuscript outright, without offering any possibility of resubmission or revision. But others may reject your manuscript but allow you to make substantial changes and improvements and then to resubmit. In these cases, an appeal may not be appropriate or necessary.
How to appeal a journal rejection?
As I said previously, I personally think that appeals have a low chance of success unless there is some serious issue with the reviewing process. But if you decide to appeal a journal rejection, you should follow these steps:
Determine the appeal protocol (if there is one). Some journals provide an appeal process on their website. If no process is given (more likely), find the email of the editor-in-chief on the journal website and explain your situation. Generally, the editor is very busy so try to explain everything in a single e-mail.
Always be respectful towards the editor, reviewers and other persons involved. Courtesy, humility and calm go a long way in winning a re-review. Do not be rude, aggressive, defensive, or emotional in your appeal letter. Acknowledge the editor’s and reviewers’ efforts and expertise, and thank them for their feedback.
Construct your argument clearly around why you believe the appeal is justified. Provide evidence and references to support your claims. Address each point of criticism or concern raised by the reviewers, and explain why you disagree or how you have resolved it. Be concise and specific, and avoid repeating yourself or making irrelevant comments.
What to expect from an appeal?
Keep in mind that appeals are rarely successful. Your appeal must be a simple and concise rational argument based on facts over emotions.
If your appeal is accepted, you may receive a positive response from the editor-in-chief or a senior editor who will agree to reconsider your manuscript or send it to new reviewers. However, this does not guarantee acceptance; your manuscript will still undergo another round of peer review and editorial evaluation.
If your appeal is rejected, you may receive a negative response from the editor-in-chief or a senior editor who will uphold the original decision and explain why your appeal was not convincing or valid. In this case, you should respect their final verdict and move on.
When to submit your manuscript to another journal
If your appeal is unsuccessful or not possible at all, you should look for another journal that is suitable for your manuscript. Before submitting, check the scope, aims, and requirements of the new journal. Make sure that your manuscript matches the journal’s focus and expectations, and that you follow the journal’s guidelines for authors. Also try to fix the problems in your papers that reviewers have mentioned in their reviews.
Conclusion
Receiving a rejection from a journal can be discouraging and seem unfair. Generally, you can either appeal the decision or submit your manuscript to another journal. In either case, you should be respectful in your communication with the journal. Remember that rejection is part of the process, and that it can help you improve your manuscript and increase your chances of success in the future.
Today, I will briefly explain what is a generator itemset. I will give some example and explain why generator itemsets are interesting and useful for some applications. I will also mention that efficient implementations can be found in the SPMF data mining library (which I am the founder).
What is a generator itemset?
In data mining, a popular task is frequent itemset mining. It consists of finding frequent itemsets in a database. A frequent itemset is a set of values that frequently appear together in records of a database. The classical application of itemset mining is to analyze transaction databases to study the behavior of customers in a store. In that context, each record is a customer transaction, and the goal is to find sets of products bought together by at least minsup customers where minsup is a threshold set by the user.
For example, consider the following transaction database containing five transactions:
Transaction 1 | A, B, C, D Transaction 2 | A, B, C, D Transaction 3 | A, C Transaction 4 | B, C Transaction 5 | A
where A, B, C, D represent the purchase of Apple, Bread, Cake, and Dates respectively. The support of an itemset is the number of transactions that contain it. For instance, the support of {A} is 4, the support of {B} is 3, and the support of {A, B} is 2. A frequent itemset is an itemset whose support is greater than or equal to a minimum support threshold. Let’s assume that the minimum support is 2. Then, the frequent itemsets are:
Among these frequent itemsets, some are generators and some are not. A (frequent) generator itemset is a frequent itemset that does not have any subset with the same support. For example, {A,B,C,D} is not a generator because it has a subset {A} with the same support (2). However, {A, B} is a generator because none of its subsets ({A}, {B}) has the same support (2). The generator itemsets in this example are:
{A} support : 4 {B} support: 3 {C} support : 4 {D} suport : 2 {A, B} support : 2 {A, C} support : 3
As it can be observed, frequent generator itemsets are a subset of all frequent itemsets.
Why are generator itemsets useful?
Generator itemsets (also called key itemsets) are useful for several reasons. First, they can be used to recover all the frequent itemsets by applying a closure operator. The closure operator takes a generator itemset and adds all the items that appear in every transaction containing that generator. For example, the closure of {A, B} is {A, B, C,D} because {A, B} appears in transactions 1 and 2, and both transactions also contain C and D. By applying the closure operator to all the generators, we can recover all the frequent itemsets.
Second, generator itemsets can help us understand the structure of the data. Generator itemsets represents the smallest sets of values that are common to some sets of transactions. In the context of shopping, it means that smallest sets of products that are common to some groups of customers. Generators are also often used for classification because they allow to extract the smallest sets of features that describe groups of instances (transactions).
Third, discovering generator itemsets can reduce the number of itemsets that are discovered. By mining generator itemsets instead of all frequent itemsets, we can find only the smallest itemsets that have a given support, which is more concise and can be more meaningful。
How to mine generator itemsets?
There are several algorithms that can be used to mine generator itemsets from a transactional database. One of them is Pascal, which is based on the Apriori algorithm. Pascal works by generating candidate itemsets of increasing size and checking their support in the database. However, unlike Apriori, Pascal only generates candidates that are generators or potential generators. The key property used by Pascal to reduce the search space is that if an itemset is not a generator than all its supersets are also not generators.
Efficient implementations of algorithms
If you want to try discovering generator itemsets and other kinds of patterns, the SPMF open-source library more than a hundred algorithms for mining itemsets and other patterns, including generator itemsets, frequent itemsets, and closed itemsets. SPMF is easy to use and provides a graphical user interface and a command line interface.
To use SPMF to mine generator itemsets from a transactional database, we need to follow these steps:
Download and install SPMF from https://www.philippe-fournier-viger.com/spmf/
Prepare an input file in the SPMF format (a text file where each line represents a transaction and items are separated by spaces)
Choose an algorithm for mining generator itemsets (such as Pascal and DefMe) and set the parameters (the minimum support threshold).
Run the algorithm and open the output text file.
For more details and examples on how to use SPMF to mine generator itemsets or other patterns from data, please refer to the documentation and tutorials on https://www.philippe-fournier-viger.com/spmf/
Have you ever wondered how to find patterns in data that are not only frequent but also profitable and cost-effective? For example, if you are an online retailer, you may want to know what products are often bought together by customers and generate high profits but require low costs (such as shipping fees or discounts). Or if you are an educator, you may want to know what learning activities are frequently performed by students and result in high grades but require low efforts (such as time or resources).
In this blog post, I will briefly introduce a new problem called low-cost high utility itemset mining (LCHUIM), which aims to find such patterns. LCHUIM is a generalization of the well-known problem of high utility itemset mining (HUIM), which focuses on finding patterns that have high utilities (benefits) according to a user-defined utility function. However, HUIM ignores the cost associated with these patterns, such as time, money or other resources that are consumed. The novel problem of LCHUIM addresses this limitation by considering both the utility and the cost of patterns.
To be more precise, a low-cost high utility itemset is an itemset (a set of values) that must satisfy three criteria:
Its average utility must be no less than a min_utility threshold set by the user.
Its average cost must be no greater than a max_cost threshold set by the user.
Its support (occurrence frequency) must be no less than a minsup threshold set by the user.
For example, suppose we have a transaction database that contains information about customers’ purchases and their profits and costs. A possible low-cost high utility itemset could be {bread, cheese}, which means that customers often buy bread and cheese together, and this combination generates high profits but requires low costs.
Finding low-cost high utility itemsets can reveal interesting insights for various domains and applications. For instance, online retailers could use LCHUIM to design effective marketing strategies or recommend products to customers. Educators can use LCHUIM to analyze students’ learning behaviors and provide personalized feedback or guidance.
To solve the problem of LCHUIM, an algorithm named LCIM (Low Cost Itemset Miner) was proposed. The algorithm uses a novel lower bound on the average cost called Average Cost Bound (ACB) to reduce the search space of possible patterns. The algorithm also employs several techniques such as prefix-based partitioning, depth-first search and subtree pruning to speed up the mining process.
The LCIM algorithm was published in this paper:
Nawaz, M. S., Fournier-Viger, P., Alhusaini, N., He, Y., Wu, Y. and Bhattacharya, D. (2022). LCIM: Mining Low Cost High Utility Itemsets . Proc. of the 15th Multi-disciplinary International Conference on Artificial Intelligence (MIWAI 2022), pp. 73-85, Springer LNAI [ppt]. [source code and data]
The code and dataset of LCIM can be found in the SPMF open-source data mining library at: http://philippe-fournier-viger.com/spmf/ SPMF is an efficient open-source data mining library that contains more than 250 algorithms for various pattern mining tasks such as frequent itemset mining, sequential pattern mining, association rule mining and many more.
By the way, the concept of finding cost-effective patterns was also studied for the case of discovering sequential patterns with some algorithms called CorCEPB, CEPN, and CEPB (see this other blog post for more details).
I hope you enjoyed this short blog post and learned something new about low-cost high utility itemset mining. If you have any questions or comments, feel free to leave them below. Thank you for reading!