This is a short blog post to let you know that the deadline for submitting your papers to the UDML 2024 workshop at the PAKDD 2024 conference has been extended to the 7th February.
Today, I discovered an interesting function of DBLP which is to draw your social network as a graph (assuming that you have a DBLP page). To use that feature, it is simple. Open your DBLP webpage, and then click here at the bottom of the page:
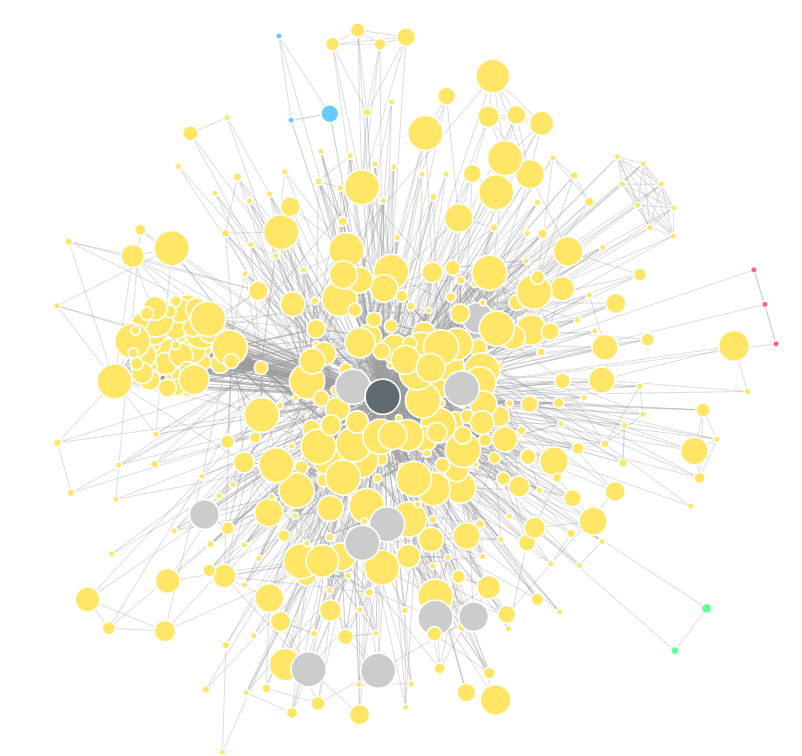
Then, your social network will be displayed (it can take a little while). For example, this is mine:
What is interesting is that it shows not only the direct co-authorship links, but also some transitive links thus highlighting some potential connections that one could create through his current network.
In the above picture, the graph is quite dense since I have 390 co-authors on DBLP.
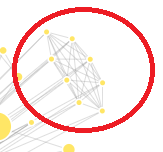
By observing this graph, we can also see some strange structures like this one:
This structure seems too perfect (all the authors are connected between themselves). Thus, I have investigated why. The reason is simple. It is a paper that I participated in, where there was 8 authors and most of them were not from computer science. Thus, most of the authors on that paper had only one paper on DBLP, which was the same.
There is also a dense cluster here:
which is mostly European researchers.
I just wanted to share this interesting function with you in this blog post, as I have discovered it today (but it might have been available for a while!).
I am pleased to announce today that my collaborators and I have published a new survey paper about episode mining to give an introduction to this nice and interesting subfield of pattern mining. To our knowledge this is the most complete and up-to-date survey paper on this topic.
What is Episode mining? Put simply, it is about analyzing a long sequence of events with timestamps to discover interesting patterns in it such as that some events often appear before other events within some interval of times. This has many applications in real-life such as analyzing relationships between alarms in computer networks.
Ouarem, O., Nouioua, F., Fournier-Viger, P. (2023). A Survey of Episode Mining. WIREs Data Mining and Knowledge Discovery, Wiley, to appear.
I hope that you will enjoy this new survey! — Philippe Fournier-Viger is a distinguished professor working in China and founder of the SPMF open source data mining software.
Today, I will explain how to write the answer to reviewers for an academic journal using Latex. The advantage of using Latex instead of a software like Microsoft Word to write answers to reviewers is that it allows using all the features of LaTeX such packages for managing references, figures, and tables.
Since the LaTeX code that I will explain is very simple, let me first show you the result that we want to achieve. It will be a document where we can display the comments and corresponding answers for each reviewer. The result that we will achieve is a neat document that will look like this:
To do something like this, we will create two new LaTeX environments to display comments and solutions (answers), respectively. To draw the box around each comment, we will use a package called mdframed.
The code of the above document will then look like this:
\documentclass{article}
\usepackage{graphicx}
\usepackage{verbatim}
\usepackage[margin=1in]{geometry}
\usepackage{xcolor}
\usepackage{mdframed}
\newenvironment{Comment}[2][Comment]
{ \begin{mdframed}[backgroundcolor=gray!20]
\textbf{#1 #2} \\}
{ \end{mdframed}}
\newenvironment{solution}
{\textit{Answer:} }
{}
\begin{document}
\title{The title of the papers}
\author{\normalsize Author1 and Author2 and Author3}
\date{}
\maketitle
We thank the editor for handling the manuscript, and the reviewers for the valuable comments. In this revision, modifications are in {\color{blue}blue} color. Below we give a point-by-point summary of how each issue raised by the reviewers has been addressed.
\section{Reviewer \#1}\begin{Comment}{1: Main concern}
The manuscript is very long.
\end{Comment}\begin{solution}
Thanks. We have made it shorter.
\end{solution}\begin{Comment}{3: Minor concern}
There are many grammar errors.
\end{Comment}\begin{solution}
Thanks. We have carefully proofread the paper.
\end{solution}
\bibliographystyle{plain}
\bibliography{mybib.bib}
\end{document}
Now let me explain the code. If you are familiar with LaTeX, you will see that this code is very simple. This code :
defines two new environments for comments and solutions, respectively. Then, it is followed by code to display the title of the paper, show the author names and creates a section for each reviewer using the \section command. Then, the comment and solution environments are used to display comments and answers.
Conclusion
This was just a short blog post to show how to write answers to reviewers using LaTeX. The above template was provided by some collaborator, and I am not sure about where it originally came from. If someone knows, I could add the credit to the original author to this blog post.
This is the end of this blog post about writing a response to reviewers using LaTeX. I hope this blog post has been helpful and informative. If you have any questions or comments, please leave a comment below. Thank you for reading, and happy LaTeXing! 😊
In this blog post, I will show how to add a script (commands) to TexWorks for adding a color to your Latex document. This is easy and can be used also for other types of commands.
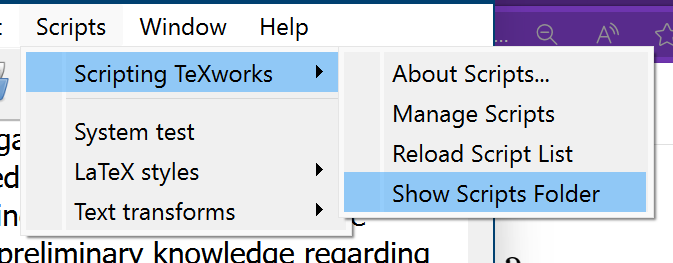
1) In TexWorks, go to the menu Scripts and then choose Show Scripts Folder:
This will open the folder containing the scripts.
2) Open the subfolder Latex styles as we will add our new script to this folder:
3) Make a copy of the file toogleBold.js and call it toogleRed.js:
4) Edit the file toogleRed.js as follows and save it:
// TeXworksScript
// Title: Toggle Red
// Shortcut: Ctrl+Shift+G
// Description: Encloses the current selection in \textcolor{red}{}
// Author: based on toogleBold by Jonathan Kew
// Version: 0.3
// Date: 2010-01-09
// Script-Type: standalone
// Context: TeXDocument
function addOrRemove(prefix, suffix) {
var txt = TW.target.selection;
var len = txt.length;
var wrapped = prefix + txt + suffix;
var pos = TW.target.selectionStart;
if (pos >= prefix.length) {
TW.target.selectRange(pos - prefix.length, wrapped.length);
if (TW.target.selection === wrapped) {
TW.target.insertText(txt);
TW.target.selectRange(pos - prefix.length, len);
return;
}
TW.target.selectRange(pos, len);
}
TW.target.insertText(wrapped);
TW.target.selectRange(pos + prefix.length, len);
return;
}
addOrRemove("\\textcolor{red}{", "}");
Here, what I have done is to make a new command that will automatically add \textcolor{red}{} arround some selected text when the user presses CTRL+SHIFT+G.
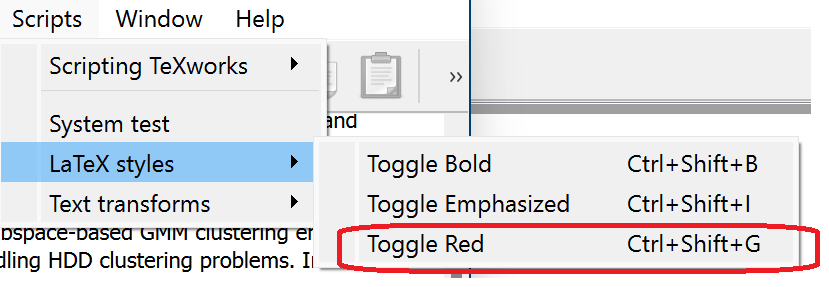
5) Go back to TexWorks, and reload the script list using the menu “Reload script list”:
Then, the new command will appear in the menu Latex Styles:
6) Then, you can try it by selecting some text in a latex document and then pressing CTRL+Shift+G:
That’s all!
And of course, to compile the LaTeX document, I assume that you are using the color package.
It is very convenient to make scripts for new commands in TexWorks!
And, If you want to do the same for the blue color, we could make another script like this:
// TeXworksScript
// Title: Toggle Blue
// Shortcut: Ctrl+Shift+D
// Description: Encloses the current selection in \textcolor{blue}{}
// Author: based on toogleBold by Jonathan Kew
// Version: 0.3
// Date: 2010-01-09
// Script-Type: standalone
// Context: TeXDocument
function addOrRemove(prefix, suffix) {
var txt = TW.target.selection;
var len = txt.length;
var wrapped = prefix + txt + suffix;
var pos = TW.target.selectionStart;
if (pos >= prefix.length) {
TW.target.selectRange(pos - prefix.length, wrapped.length);
if (TW.target.selection === wrapped) {
TW.target.insertText(txt);
TW.target.selectRange(pos - prefix.length, len);
return;
}
TW.target.selectRange(pos, len);
}
TW.target.insertText(wrapped);
TW.target.selectRange(pos + prefix.length, len);
return;
}
addOrRemove("\\textcolor{blue}{", "}");
Today, I want to show you a new interactive demo of the KNN (K-Nearest Neighbors) algorithm that I have added to my website. It is designed to be used for teaching purpose to illustrate how the K-Nearest Neighbors algorithm works.
In the section 1 of the webpage, you can enter some data that is a list of records or instances to be used by KNN to make predictions. The first line is the list of attributes. Then, each following line is a record, wich is a list of values separated by single spaces. The values can be categorical or numerical.
Then, the value of K can be selected in section 2 of the webpage. For the purpose of teaching, values of K are restricted to be between 1 to 100.
Then, you can provide an instance to classify in section 3 of the webpage. The instance to classify is a list of attribute values but one of them must be replaced by ? meaning that we want to predict this attribute value using KNN.
Finally, by clicking Run KNN button, the result are displayed like this:
It indicates the K most similar instances, the calculated distances between those instances and the instance, and the predicted attribute value.
It is possible to run the demo with different values of K and different data to observe the result, which can be good for learning.
Conclusion
This tool is for teaching purpose. If you want to try a more efficient implementation in Java, you could try the one from the SPMF data mining software, which is free and open source.
The K-Means demo, first let you enter a list of 2 dimensional data points in the range of [0,10] or to generate 100 random data points:
Then the user can choose the value of K, adjusts other settings, and run the K-Means algorithm.
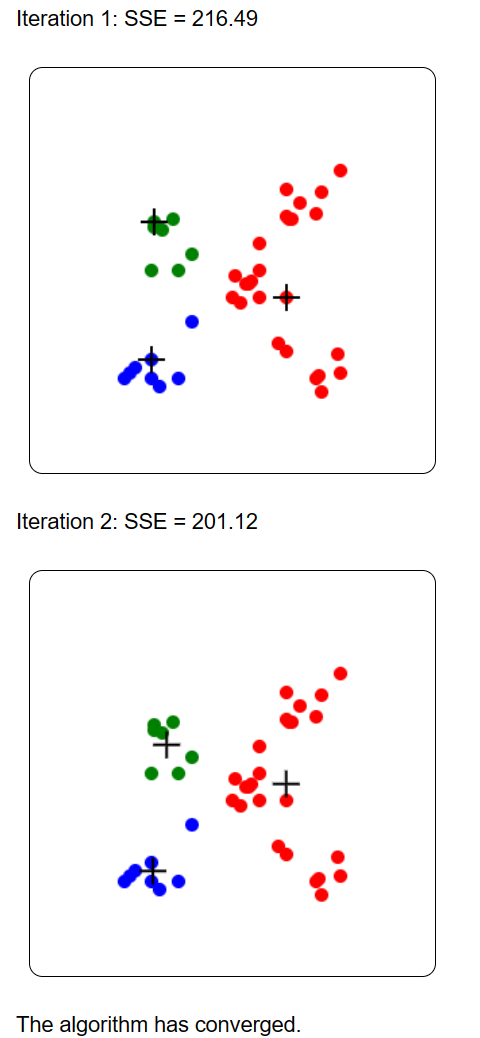
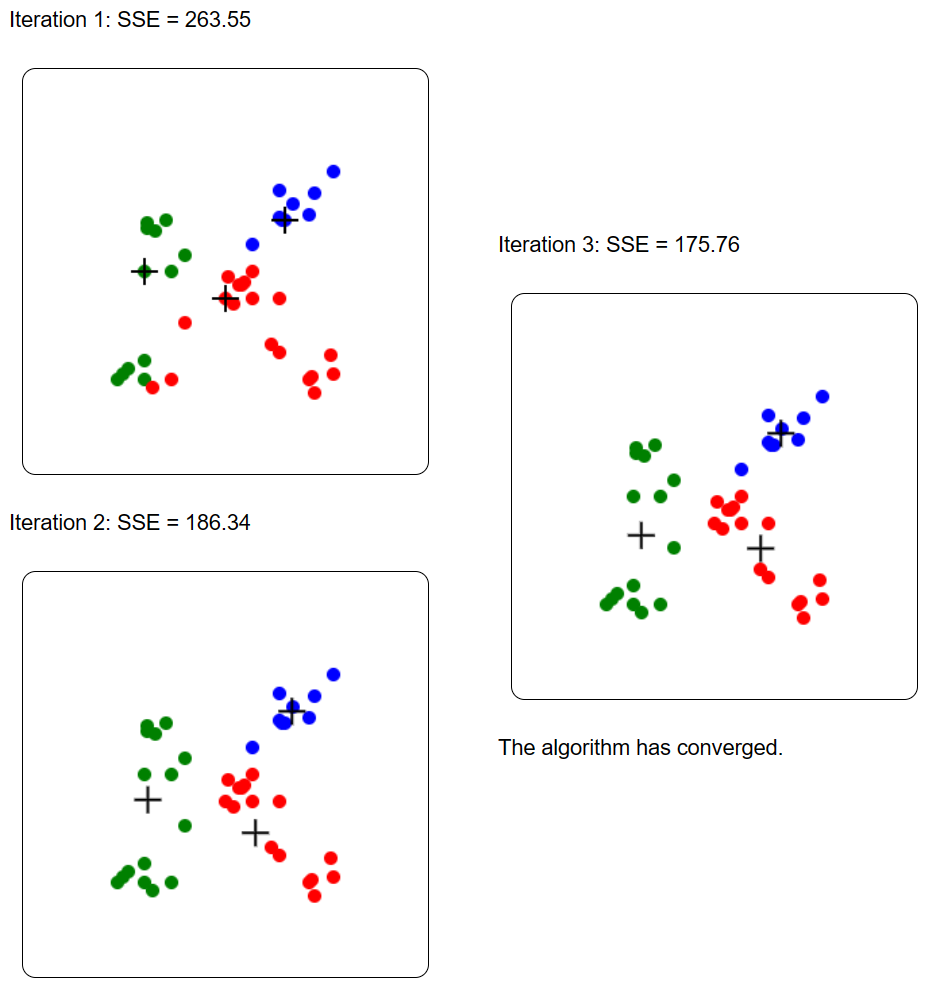
The result is then displayed for each iteration, step by step. Each cluster is represented by a different color. The SSE (Sum of Squared Error) is displayed, and the centroids of clusters are illustrated by the + symbol. For example, this is the result on the provided example dataset:
Because K-Means is a randomized algorithm, if we run it again the result may be different:
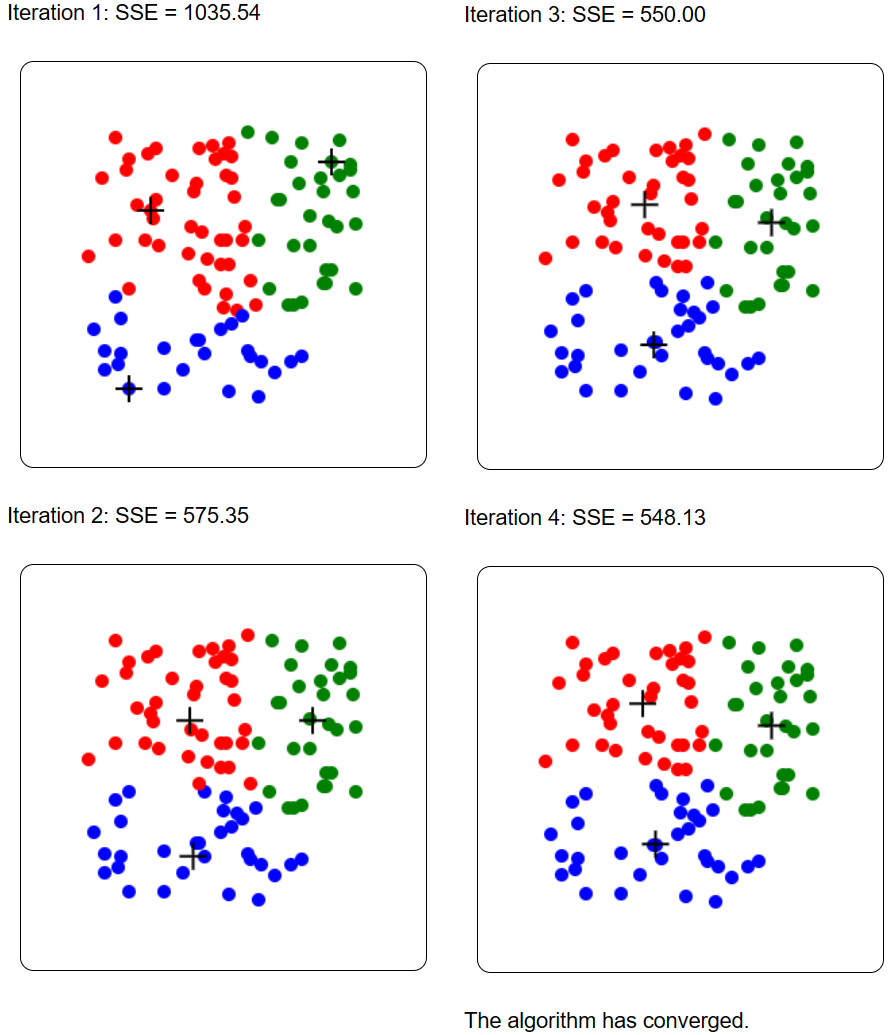
Now, let me show you the feature of generating random points. If I click the button for generating a random dataset and run K-Means, the result may look like this:
And again, because K-Means is randomized, I may execute it again on the same random dataset and get a different result:
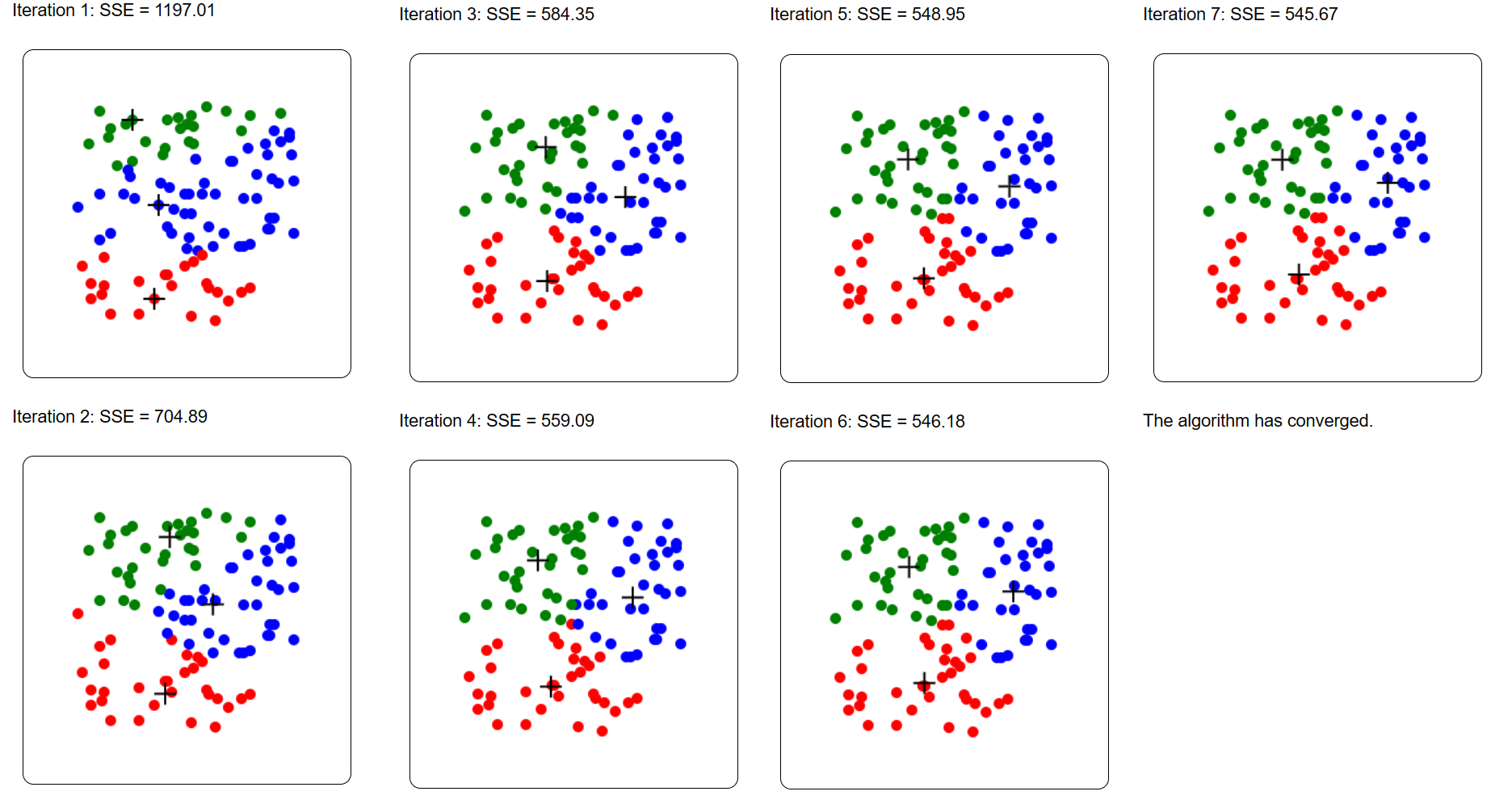
I think that this simple tool can be useful for illustrating how the K-Means algorithm works to students. You may try it. It is simple to use and allows to visualize the result and clustering process. Hope that it will be useful! — Philippe Fournier-Viger is a distinguished professor working in China and founder of the SPMF open source data mining software.
Hi all, I just write a quick message to say that I did not write on the blog recently due to my very busy schedule recently. However, everything is going well. I will be back on the blog with more content soon, and I will start to add more videos to the YouTube channel soon. Also, I am working on the next version of SPMF. 😉
Today, I will talk about the MDLM 2023 conference (International Conference on Machine Learning and Data Mining). Several years ago, I have attended MLDM 2016 (report here) because at that time it was published by Springer. But I was unhappy that the MLDM conference was advertised as being held in New York, while it was finally held in a small hotel 40 minutes away in another city called Newark, close to nothing. And that conference was really expensive at around 650 euros… I have thus never attended that conference again, but I have observed that during the following years, that conference was still advertised as being in New York, while being held in that same hotel in Newark every year (see my blog post about MLDM 2019). Thus, I never submitted a paper again to that conference, and I also observed that it is not published by Springer anymore (it might be because of that). This for me is another reason to not publish there anymore.
Why I talk about MDLM 2023? Because, this year I received a comment on my blog reporting that the conference was not even held and that people went to Newark and found that there was no conference at all! Here is the comment that report this:
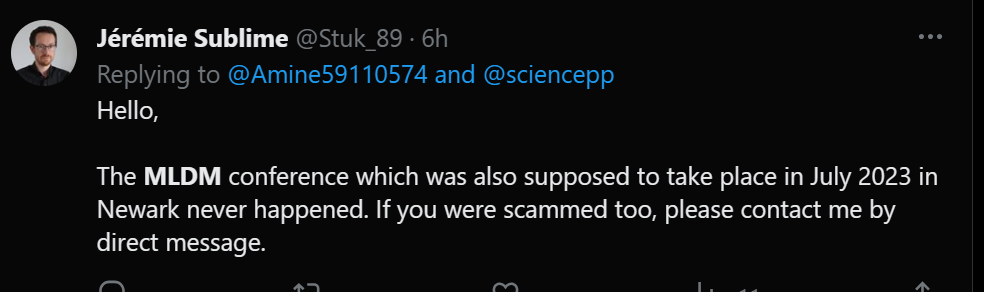
And a related tweet:
I did not verify whether this comment is true, but I believe that it is, given that this MLDM conference has repeatedly mislead people about the location of the conference.
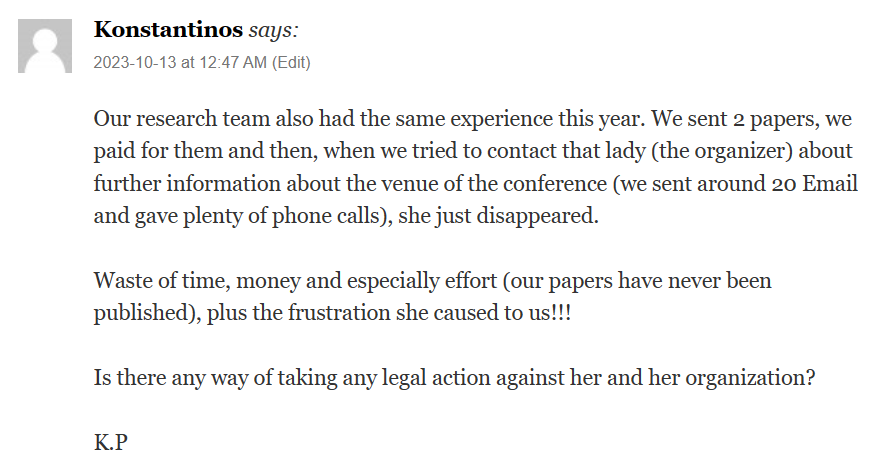
Update 2023-10: And here is another comment that I just received on this blog that also had a similar bad experience with MLDM 2023:
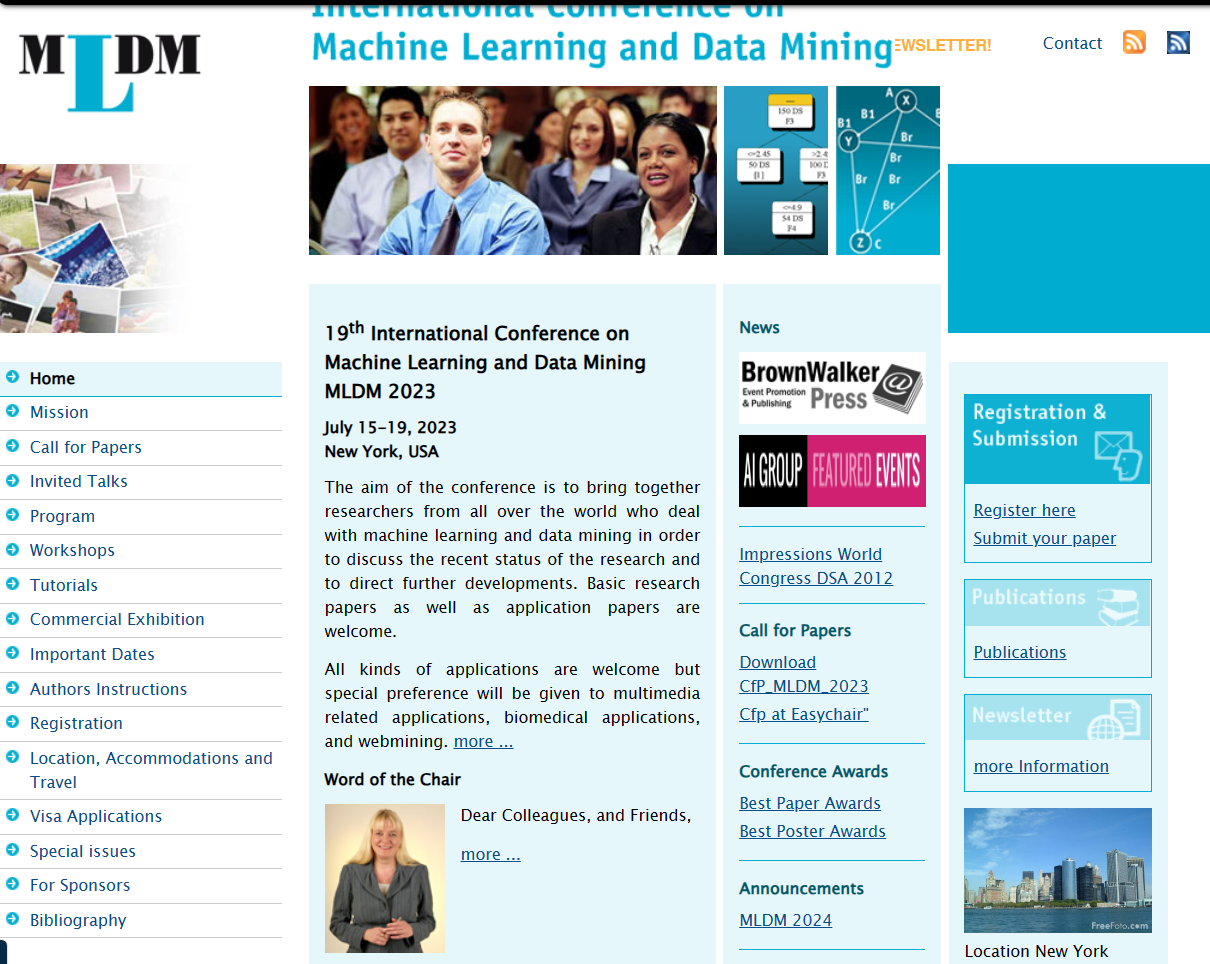
By looking at the Internet Wayback Archive, I can see that the conference website of MLDM 2023 still advertised the conference as being in New York:
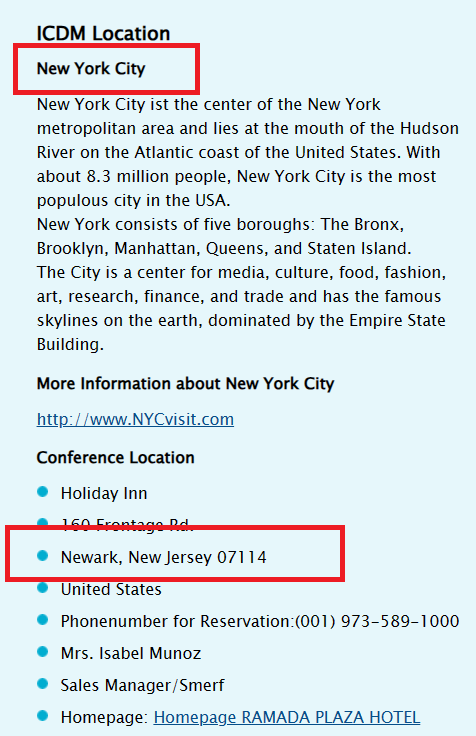
But when we click on “Location”, as usual, we find that it is not in New York city but instead in the city of Newark:
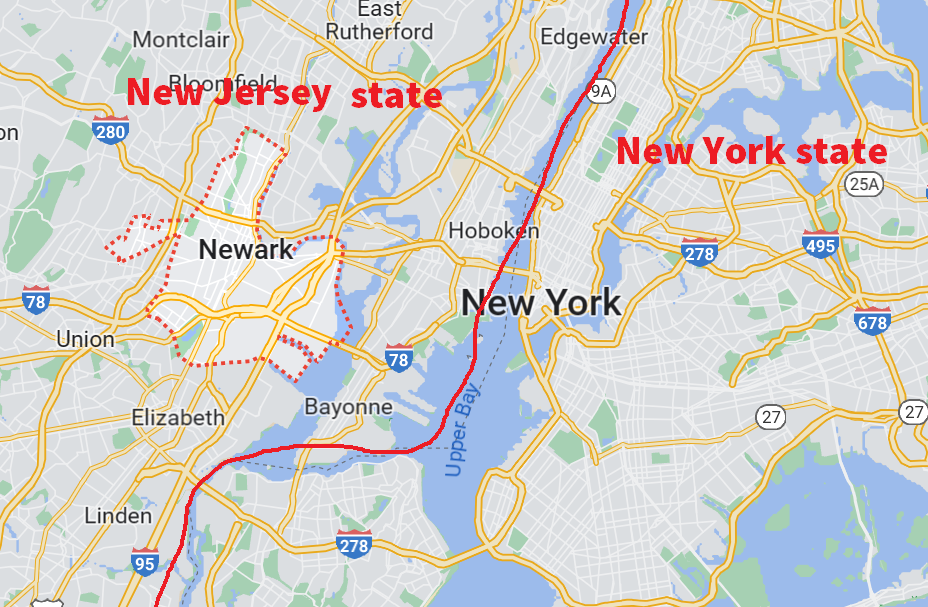
For those who are not familiar with the map of US, Newark and New York are two cities from two different states:
Thus, these two cities should not be confused!
This blog post is just to give an update about this MLDM conference.
If you have any information about this MLDM 2023 conference and whether it was really held or not or have any other interesting experience to share, please leave a comment below.