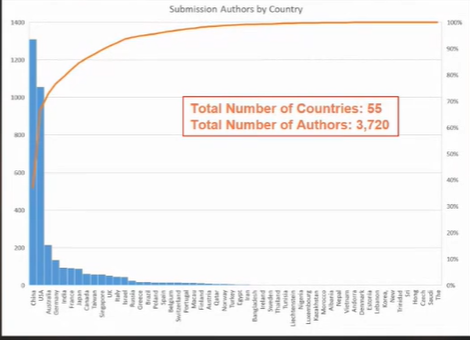
In this blog post, I will talk briefly about how tweets collected on Twitter can be analyzed to understand the public opinion about COVID-19. This is based on the below research paper, that I have recently participated to:
Noor, S., Guo, Y., Shah, S. H. H., Fournier-Viger, P., Nawaz, M. S. (2020). Analysis of Public Reaction to the Novel Coronavirus (COVID-19) Outbreak on Twitter. Kybernetes, Emerald Publishing, to appear. |
I will give an overview of the above paper. For more details, you can click on the above link to see the whole research paper.
Why analyzing Tweets? There has been a lot of research about analyzing tweets in the past such as to detect the sentiment and feelings of people on different topics, or even to detect fake news and bots among other things. The interest of analyzing Twitter data is that Twitter is used by millions of people and that tweets are posted in real-time. Thus, tweets can be used to analyze what people are saying about a topic such as the coronavirus.
How can we understand public opinion about COVID-19 on Twitter? In the above research paper, we applied the following methodology. We have first collected thousands of tweets in English about COVID-19 during the first months of the pandemic. Then we applied some clustering algorithms to discover the main themes that were talked about on Twitter related to COVID-19. Moreover, we applied sequential pattern mining algorithms to find frequent words patterns in Tweets.
What have we discovered? We have found several interesting things. For the cluster analysis, we found seven main clusters of tweets that indicate some main themes discussed by Twitter users:
- Cluster 1 (green): public sentiments about COVID-19 in the USA.
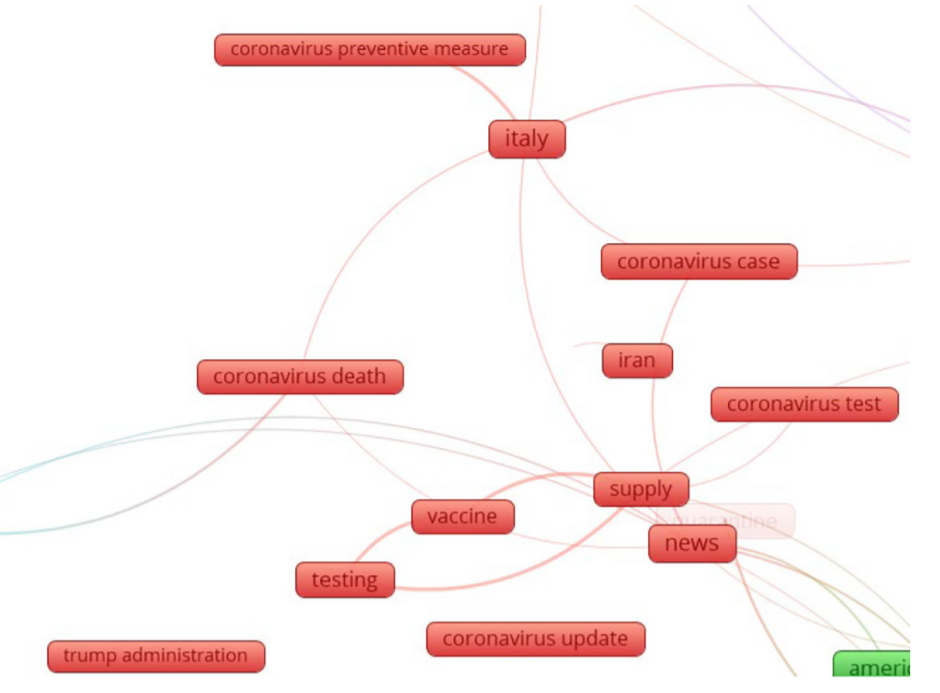
- Cluster 2 (red): public sentiments about COVID-19 in Italy and Iran and a
- vaccine,
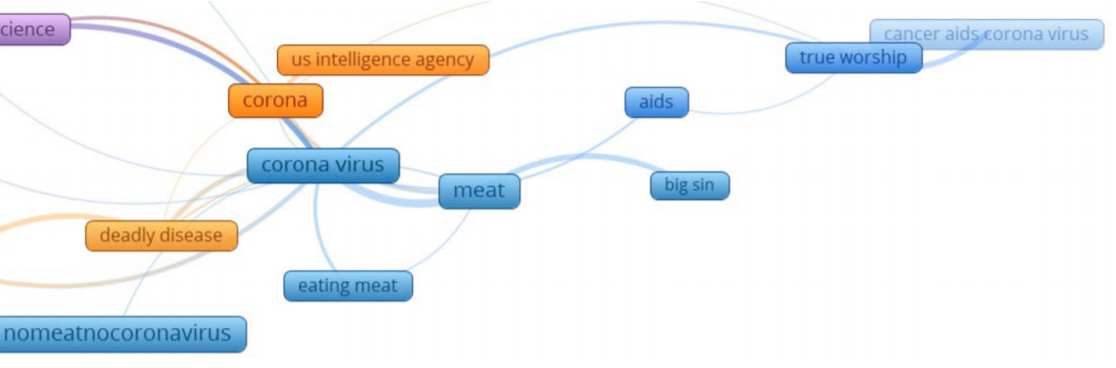
- Cluster 3 (purple): public sentiments about doomsday and science credibility.
- Cluster 4 (blue): public sentiments about COVID-19 in India.
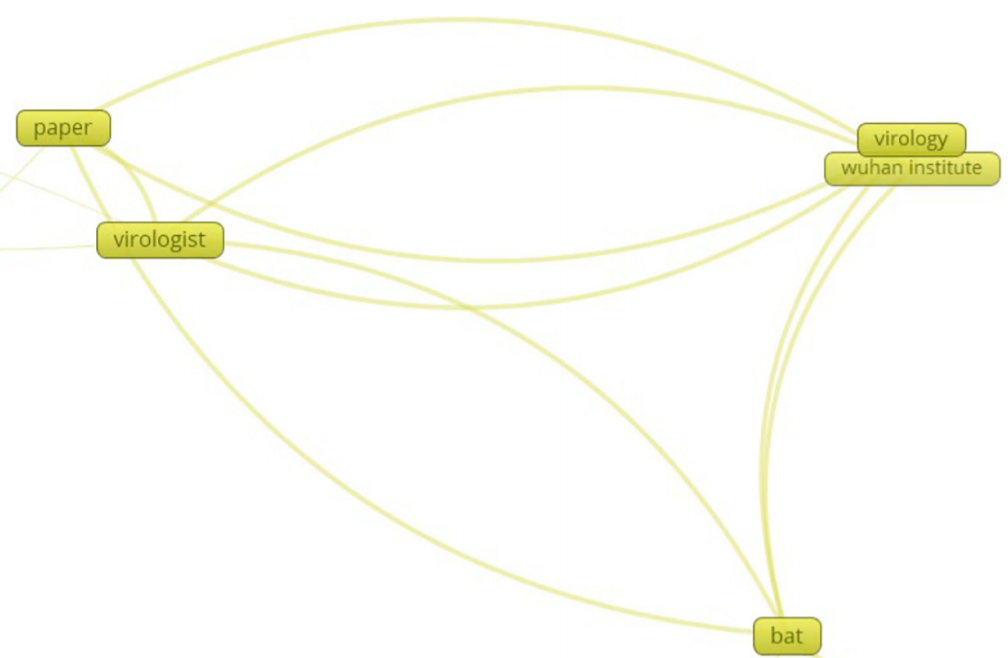
- Cluster 5 (yellow): public sentiments about COVID-19’s emergence.
- Cluster 6 (light blue): public sentiments about COVID-19 in the Philippines.
- Cluster 7 (orange): Public sentiments about COVID-19 US Intelligence Report.
For example, this is the cluster 1:
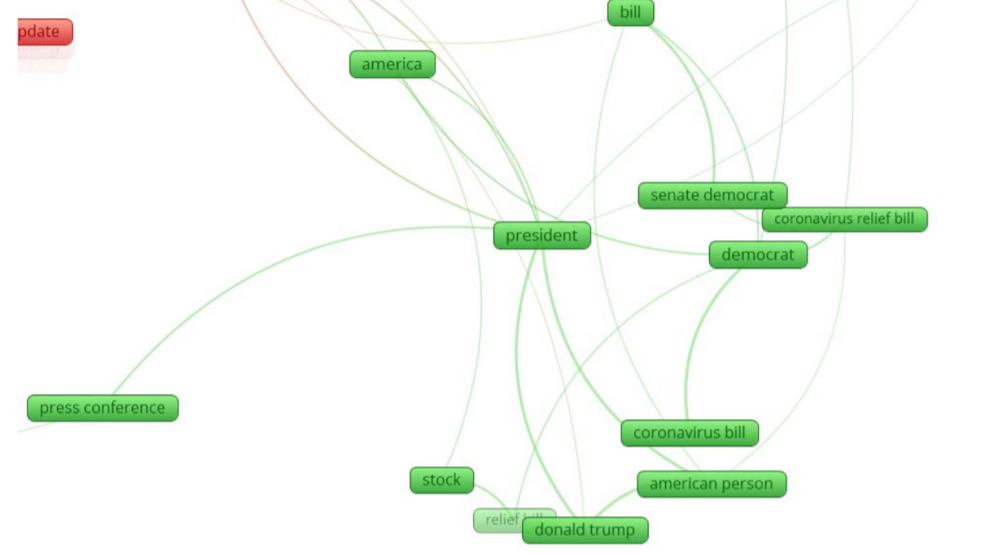
And this is the cluster 2:
Cluster 3:
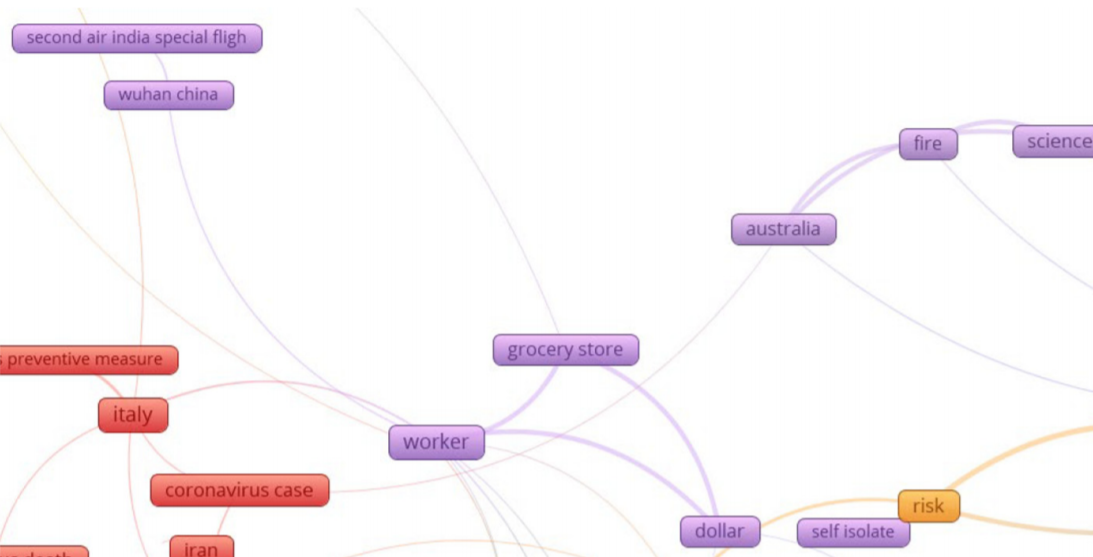
Some part of cluster 4:
Some part of cluster 5:
Some part of cluster 6:
We also found several patterns related for example to “Coronavirus, testing, lockdown”. Here is for example, some of the most frequent words:

More results are presented in the paper.
The above results represent what the sampled tweets have been talking about on Twitter in English from January to March 2020, related to COVID-19.
Conclusion
In this blog post, I have just given a very brief overview of what can be learnt from Tweets related to public opinion. For more details, please check the above paper! There is also obviously some limitations to that study such that Tweets were not geolocalized and that only the English language was used. If you have any comments you may post in the comment section below. Hope this has been interesting.
—
Philippe Fournier-Viger is a full professor working in China and founder of the SPMF open source data mining software.