This week, it is the IEA AIE 2021 conference (34th Intern. Conf. on Industrial, Engineering & Other Applications of Applied Intelligent Systems), which is held from 26th to 28th June 2021. This year, the conference is held online due to the COVID pandemic situation around the world.

In this blog post, I will give an overview of the conference.
About IEA AIE 2021
The IEA AIE conference is a conference that focuses on artificial intelligence and its applications. I have attended this conference several times over the year. I have written some blog posts also about IEA AIE 2016, IEA AIE 2018, IEA AIE 2019 and IEA AIE 2020.
This year, there has been 145 papers submitted. From this, 87 papers were accepted as full papers, and 19 as short papers.
Special sessions
This year, there was eight special sessions organized at IEA AIE on some emerging topics. A special session is a special track for submitting papers, organized by some guest researchers. All accepted papers from special sessions are published in the same proceedings as regular papers.
- Special Session on Data Stream Mining: Algorithms and Applications
- (DSMAA2021)
- Special Session on Intelligent Knowledge Engineering in Decision Making Systems
- (IKEDS2021)
- Special Session on Knowledge Graphs in Digitalization Era (KGDE2021)
- Special Session on Spatiotemporal Big Data Analytics (SBDA2021)
- Special Session on Big Data and Intelligence Fusion Analytics (BDIFA2021)
- Special Session on AI in Healthcare (AIH2021)
- Special Session on Intelligent Systems and e-Applications (iSeA2021)
- Special Session on Collective Intelligence in Social Media (CISM2021).
Opening ceremony
On the first day, there was the opening ceremony. It was announced that IEA AIE 2022 will be held in Japan next year.
Keynote speakers
There was two keynote speakers: (1) Prof. Vincent Tseng from National Yang Ming Chiao Tung University, (2) Prof. Francisco Herrera from University of Granada.
Paper presentations
I have attended several paper presentations through the conference. There was some high quality papers on various topics related to artificial intelligence. There was four rooms with paper presentations. Here is a screenshot of one of the rooms:
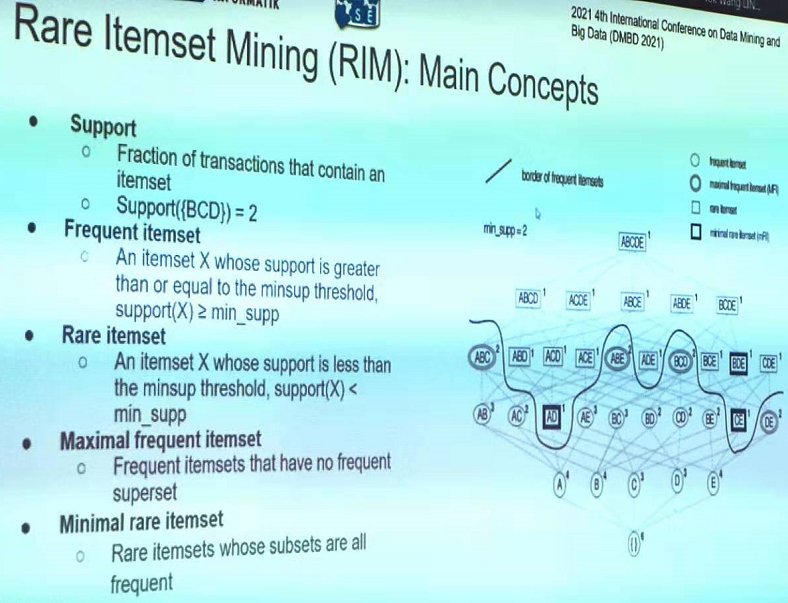
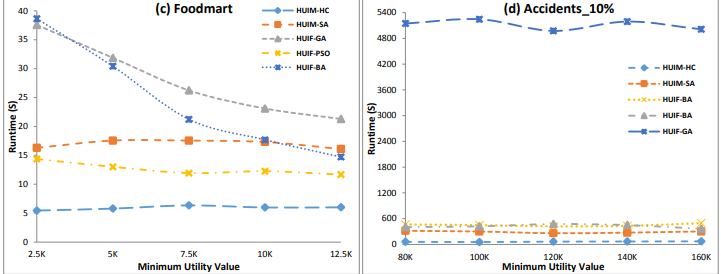
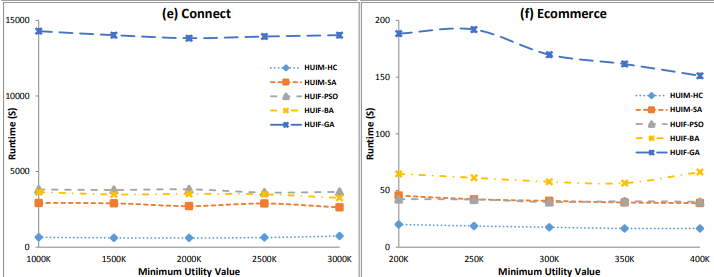
In particular, this year, there was six papers on pattern mining topics such as high utility pattern mining, sequential pattern mining and periodic pattern mining:
- Oualid Ouarem, Farid Nouioua, Philippe Fournier-Viger: Mining Episode Rules from Event Sequences Under Non-overlapping Frequency. 73-85
Comment: This paper presents a novel algorithm for episode rule mining called NONEPI. The idea is to find rules using the non-overlapping frequency in a sequence of events. - Sumalatha Saleti, Jaya Lakshmi Tangirala, Thirumalaisamy Ragunathan: Distributed Mining of High Utility Time Interval Sequential Patterns with Multiple Minimum Utility Thresholds. 86-97
Comment: This paper presents a new algorithm DHUTISP-MMU for mining high utility time interval sequential patterns with multiple minimum utility thresholds. A key idea in this paper is to add information about the time intervals between items of sequential patterns. Besides, the algorithm is distributed. - Xiangyu Liu, Xinzheng Niu, Jieliang Kuang, Shenghan Yang, Pengpeng Liu: Fast Mining of Top-k Frequent Balanced Association Rules. 3-14
Comment: This paper presents an algorithm named TFBRM for mining the top-k balanced association rules. There has been a few algorithms for top-k association rule mining in the bast. But here a novelty is to combine support, kulczynski (kulc) and imbalance ratio (IR) as measures to find balanced rules. - Penugonda Ravikumar, Likhitha Palla, Rage Uday Kiran, Yutaka Watanobe, Koji Zettsu: Towards Efficient Discovery of Periodic-Frequent Patterns in Columnar Temporal Databases. 28-40
Comment: This paper presents an Eclat-based algorithm for periodic pattern mining called PF-Eclat. From the presentation it seems to me that this algorithm is very similar to the PFPM algorithm (2016) that I proposed 5 years ago. The difference seems to be that the vertical representation is a list of timestamps instead of list of TIDs, and it has two less constraints. That is the user can only use maxPer and minSup(minAvg) as constraints but PFPM also offers two more constraints: minPer and maxAvg. By the way, there exists also another Eclat based algorithm for a similar task (mining top-k periodic frequent patterns) called MTKPP (2009). - Sai Chithra Bommisetty, Penugonda Ravikumar, Rage Uday Kiran, Minh-Son Dao, Koji Zettsu: Discovering Spatial High Utility Itemsets in High-Dimensional Spatiotemporal Databases. 53-65
- Tzung-Pei Hong, Meng-Ping Ku, Hsiu-Wei Chiu, Wei-Ming Huang, Shu-Min Li, Jerry Chun-Wei Lin: A Single-Stage Tree-Structure-Based Approach to Determine Fuzzy Average-Utility Itemsets. 66-72
Comment: This paper is about fuzzy high utility itemset mining. A novel algorithm is presented. A difference also with previous paper is the use of the average utility function in fuzzy high utility itemset mining.
Next year
The IEA AIE 2022 conference will be held in Kitakyushu, Japan.

Conclusion
This was a good conference. I have attended several presentations and had a chance to discuss with some interesting researchers. Looking forward to the IEA AIE 2022 conference.
Philippe Fournier-Viger is a full professor working in China and founder of the SPMF open source data mining software.