
Today, I will discuss the topic of accurately evaluating the memory usage of data mining algorithms in Java. I will share several problems that I have discovered with memory measurements in Java for data miners and strategies to avoid these problems and get accurate memory measurements.
In Java, there is an important challenge for making accurate memory measurement. It is that the programmer does not have the possibility to control the memory allocation. In Java, when a program does not hold references to an object anymore, there is no guarantee that the memory will be freed, immediately. This is because in Java, the Garbage Collector (GC) is responsible for freeing the memory and he generally use a lazy approach. In fact, during extensive CPU usage, I have often noticed that the GC waits until the maximum memory limit is reached before starting to free memory. Then, when the GC starts its work, it may considerably slow down the speed of your algorithm thus causing inaccurate execution time measurements. For example, consider the following charts.
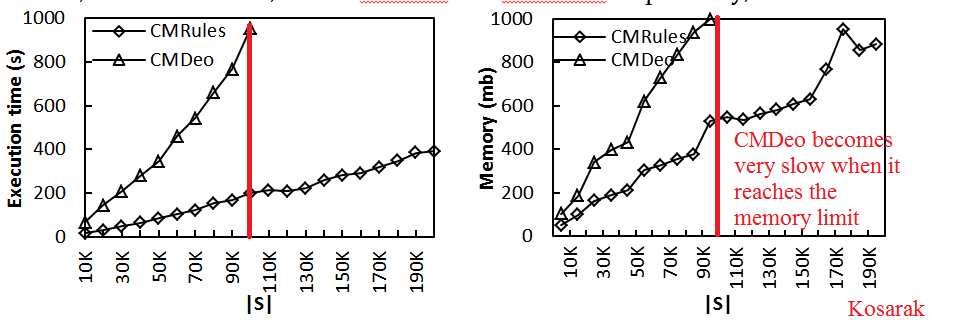
In these charts, I have compared the execution time (left) and memory usage (right) of two data mining algorithms named CMRules and CMDeo. When I have performed the experiment, I have noticed that as soon as CMDeo reached the 1 GB memory limit (red line), it suddenly became very slow because of garbage collection. This would create a large increase in execution time on the chart. Because this increase is not due to the algorithm itself but due to the GC, I decided to (1) not include memory measurements for |S| > 100K for CMDeo in the final chart and (2) to mention in the research article that it was because of the GC that no measurement is given. This problem would not happen with a programming language like C++ because the programmer can decide when the memory is freed (there is no GC).
To avoid the aforementioned problem, the lessons that I have learned is to either (1) add more memory to your computer (or increase the memory allocated to your Java Virtual Machine) or (2) choose an experiment where the maximum memory limit will not be reached to provide a fair comparison of the algorithms.
To increase the memory limit of the JVM (Java Virtual Machine), there is a command line parameter called -xmx that can work or not depending on your Java version. For example, if you want to launch a Jar file called spmf.jar with 1024 megabytes of RAM, you can do as follows.
java -Xmx1024m -jar spmf.jar
If you are running your algorithms from a development environment such as Eclipse, the XMX parameter can also be used:
- Go in the menu Run > Run Configurations > then select the class that you want to run.
- Go to the “Arguments” tab > Then paste the following text in the “VM Arguments” field: -Xmx1024${build_files}m
- Then press “Run“.
Now that I have discussed the main challenges of memory measurement in Java, I will explain how to measure the memory usage accurately in Java. There are a few ways to do it and it is important to understand when they are best used.
Method 1. The first way is to measure the memory at two different times and to subtract the measurements. This can be done as follows:
double startMemory = (Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory())
/ 1024d / 1024d;
.....
double endMemory = (Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory())
/ 1024d / 1024d
System.out.println(" memory :" + endMemory - startMemory);
This approach provides a very rough estimate of the memory usage. The reason is it does not measure the real amount of memory used at a given moment because of the GC. In some of my experiments, the amount of memory measured by this method even reached up to 10 times the amount of memory really used. However, when comparing algorithms, this method can still give a good idea of which algorithm has better memory usage. For this reason, I have used this method in a few research articles where the goal was to compare algorithms.
Method 2. The second method is designed to calculate the memory used by a Java object. For data miners, it can be used to assess the size of a data structure, rather than observing the memory usage of an algorithm over a period of time. For example, consider the FPGrowth algorithm. It uses a large data structure that is named the FPTree. Measuring the size of an FPTree accurately is very difficult with the first method, for the reason mention previously. A solution is to use Method 2, which is to serialize the data structure that you want to measure as a stream of bytes and then to measure the size of the stream of bytes. This method give a very close estimate of the real size of an object. This can be done as follows:
MyDataStructure myDataStructure = ....
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(myDataStructure);
oos.close()
System.out.println("size of data structure : " + baos.size() / 1024d / 1024d + " MB");;
With Method 2, I usually get some accurate measurements.For example, recently I wanted to estimate the size of a new data structure that I have developed for data mining. When I was using Method 1, I got a value close to 500 MB after the construction of the data structure. When I used Method 2, I got a much more reasonable value of 30 MB. Note that this value can still be a little bit off because some additional information can be added by Java when an object is serialized.
Method 3. There is an alternative to Method 2 that is reported to give a better estimate of the size of an object. It requires to use the Java instrumentation framework. The downside of this approach is that it requires to run an algorithm by using the command line with a Jar file that need to be created for this purpose, which is more complicated to do than the two first methods. This method can be with Java >= 1.5. For more information on this method, see this tutorial.
Other alternatives: There exists other alternatives such as using a memory profiler for observing in more details the behavior of a Java program in terms of memory usage. I will not discuss it in this blog post.
That is what I wanted to write for today. If you have additional thoughts, please share them in the comment section. If you like this blog, you can subscribe to the RSS Feed or my Twitter account (https://twitter.com/philfv) to get notified about future blog posts. Also, if you want to support this blog, please tweet and share it!
—
P. Fournier-Viger is the founder of the Java open-source data mining software SPMF, offering more than 50 data mining algorithms.



Pingback: How to optimize memory usage of data mining algorithms implemented in Java? (part 1) - The Data Mining & Research Blog