
This year, we are in 2019, and it is already 25 years since Agrawal wrote his seminal papers on frequent itemset mining and association rule mining in 1994. Since then, there has been thousands of papers published on this topic, some about algorithm design, new pattern mining problems, and others about applications in a multitude of fields. And there is still many research issues to work on!
After all these years, it is a good time to look back at what has been achieved to get a new perspective. This is what I did recently with colleagues in a survey paper called “Frequent Itemset Mining: a 25 Years Review“. If you are interested by frequent pattern mining, I encourage you to read the paper, as it makes some interesting observations. For example, it is found that some ideas used in recent algorithms for mining patterns in big data can be traced back to some of the early algorithms. Here is a picture from the paper showing a timeline of key algorithms and events in frequent pattern mining:
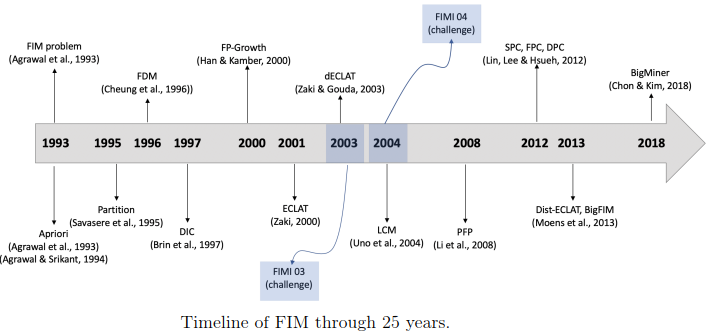
That is all I wanted to write for today!
—
Philippe Fournier-Viger is a professor of Computer Science and also the founder of the open-source data mining software SPMF, offering more than 150 data mining algorithms.


